Monte Carlo Experiments and a Few Observations on Bayesian Quantile Regression ()
1. Introduction
Quantile regression, as first described in Koenker and Bassett (Koenker & Bassett, 1978) , is a powerful statistical tool that allows researchers to examine the influence of covariates across different points of the conditional outcome distribution. The quantile regression estimator is produced by minimizing a sum of potentially asymmetric absolute deviations of the form:
(1)
where
is the so-called “check function,” defined as
While quantile regression has a long and rich history in the frequentist literature, Bayesian approaches to quantile regression are more recent and, arguably, fewer in comparison. Yu and Moyeed (Yu & Moyeed, 2001) , however, provide a likelihood-based interpretation of quantile regression that gives rise to a Bayesian solution. They note that if one assumes the errors of a regression model follow an asymmetric Laplace distribution, then a posterior kernel is produced that is coincident with the check function defining the quantile regression estimator.
Specifically, consider a regression problem of the form:1
where
follows an asymmetric Laplace distribution
yielding the likelihood function:
(2)
Given the likelihood in (2), Yu and Moyeed (Yu & Moyeed, 2001) establish propriety of the posterior under an improper uniform prior for
and provide several applications and experiments. Kozumi and Kobayashi (Kozumi & Kobayashi, 2011) describe an alternate approach to the Metropolis-Hastings based scheme of Yu and Moyeed (Yu & Moyeed, 2001) that is computationally appealing.2 They exploit an additive mixture representation of the asymmetric Laplace distribution that admits a standard Gibbs sampling-based solution for Bayesian quantile regression. Specifically, Kozumi and Kobayashi (Kozumi & Kobayashi, 2011) note that the model can be equivalently expressed as
(3)
with
Furthermore, the
are iid exponential variates:
This particular mixture formulation is quite useful since (a) conditioned on
, the model is a Gaussian linear model, and thus a Gibbs implementation is relatively easy to conduct and (b) when marginalizing (3) over
, the asymmetric Laplace distribution is produced as the sampling model. Thus, one can employ a data-augmented Gibbs sampling algorithm to recover the quantile function
. Applications and extensions of this methodology can be found in, e.g., (Alhamzawi, 2016; Rahman, 2016; Alhamzawi & Ali, 2018; Mostafaei et al., 2019; Xu & Chen, 2019; Bresson et al., 2021; Kedia et al., 2023; Zhao & Xu, 2023) , among many others.
An issue that merits further investigation—an investigation we conduct briefly in section 3—is the following: Simulation-based recipes for Bayesian posterior inference, such as the Gibbs sampler of Kozumi and Kobayashi (Kozumi & Kobayashi, 2011) , generate a series of draws which converge to the desired target distribution,
or
. These draws can then be used to calculate various features of that posterior or to plot its entire distribution. The sample average of those post-convergence draws—an estimate of the posterior mean—is commonly, if not exclusively, used as a point estimate of
. However, the motivation for the asymmetric Laplace “working” likelihood, or its expanded representation in (3), is that the posterior mode (under a flat prior) coincides with the minimizer of the check function in (1). To the extent that the posterior distribution for the model parameters is asymmetric, the mode and mean can depart significantly.
In the following sections of this paper, we offer several observations and contributions. We first derive the exact posterior distribution of the location parameter of an asymmetric Laplace distribution in an environment free of covariates. We do so while allowing a scale parameter to enter the asymmetric Laplace likelihood and while employing an inverse gamma prior for that scale parameter. This setting is then used to perform a series of generated data experiments, those designed to characterize the sampling distributions of the posterior mean and posterior mode under various sample sizes. Although the posterior mean is commonly reported as a point estimate in applied work of this type, under flat priors the posterior mode is formally coincident with the desired quantile. The mode, however, is often prohibitively difficult to calculate in high-dimensional settings, while an estimate of the mean is almost immediately available given a set of draws from the posterior distribution. Our experiments are intended to shed light on the performance of the widely-used posterior mean and how its use may suffer (if at all) relative to the mode, as both features of the posterior distribution can be easily calculated in our simplified univariate setting.
2. An Intercept-Only Model
Suppose our object of interest is the pth quantile,
, and denote the associated parameter as
. Employing the flat improper prior for
:
and the following prior for the Laplace scale parameter:
, where IG denotes an inverse gamma distribution,3 we obtain the following joint posterior under the asymmetric Laplace likelihood:
(4)
In (4), n denotes the number of observations,
is our data, and
denotes the sample mean. Integrating
out of the equation above, we obtain
(5)
With a bit of additional work, we can determine the normalizing constant of (5) and thus provide an exact analytical expression of the marginal posterior distribution
. To this end, let
denote the jth order statistic of the sample data
, and for simplicity assume there are no ties so that
. In addition, define
and, for
,
Finally, letting
we have
(6)
As noted by Chan et al. (Chan et al., 2019) , pages 315-317, the mode of the posterior equals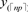 , with “
, with “ ” denoting the traditional ceiling operator. Interestingly, when np is an integer, the posterior mode is not unique, and the posterior distribution has a flat ridge around the pth quantile of the sample data.4 To see this we note, again for integer-valued np:
” denoting the traditional ceiling operator. Interestingly, when np is an integer, the posterior mode is not unique, and the posterior distribution has a flat ridge around the pth quantile of the sample data.4 To see this we note, again for integer-valued np:
Therefore, from (6),
Likewise,
so that
Identical reasoning can be used to establish that the posterior distribution
is flat and reaches a maximum over the interval
when np is an integer.
Figure 1 offers some very brief graphical support of this result, plotting
when
,
,
, and for three different iid samples
![]()
Figure 1. Plots of
with
,
.
from a
distribution with
(upper panel),
(lower left) and
(lower right). For the
case,
, and thus the posterior reaches a constant peak over
.
3. Generated Data Experiments
In this section, we perform a series of generated data experiments. We do so noting that when a posterior simulator is applied to generate draws from (6) or its generalization when including covariates, the mean is reported as a point estimate while the mode technically coincides with the desired quantile. We hope these experiments may shed light on whether or not use of the mean will lead us astray, and how far we might veer off course when doing so.
To sidestep issues surrounding the potential non-uniqueness of the mode we focus on cases where np is not an integer. We also focus on performance in small samples and consider cases where
, fixing
throughout. For each sample size, we consider 5 different designs: (a)
, (b)
, (c)
, (d)
and (e)
, corresponding to standard normal, uniform, exponential (with mean 1/2), standardized Student-t (with 5 degrees of freedom) and two-component normal mixture cases, respectively. Within each sample size/design cell, we generate 500,000 data sets, each time calculating the posterior mode and using (6) to calculate the posterior mean.5 To assess how well the means and modes perform, we calculate each estimator’s average percentage error, defined as
and also calculate the sampling probabilities that the posterior mean and mode lie within a given threshold of the quantile:
where
is either the posterior mean or posterior mode from the mth experiment,
whose value changes in each of our 5 designs,
and
is the true 0.1 quantile for the given design.
Several interesting patterns emerge from Table 1. First and not surprisingly, estimates become more accurate (in the sense that average percentage errors tend to zero) as the sample size increases. For example, the average percentage error of the posterior mode in the Gaussian sampling experiment falls from 0.17 to 0.09 to 0.01 for
and 151 (respectively). Second, posterior mean estimates tend to understate the quantile, as suggested by the signs of the average percentage errors, while posterior modes consistently overstate the quantile. Finally, and perhaps surprisingly, posterior means tend to have smaller average
![]()
Table 1. Performances of posterior mean and posterior mode across different sampling experiments.
percentage errors than modes, despite their lack of formal connection to the quantile. This preference also exists under our second metric which calculates the (sampling) percentages that the posterior mean and posterior mode will fall within
of the true quantile. For this second metric, improvement is always seen for the posterior mode as the sample size grows, while the performance of the posterior mean sometimes degrades as the sample size increases.
Figure 2 provides some additional information about these experiments for the uniform and exponential cases as selected examples, each for
. The figure reveals: (a) the (sampling) average of the posterior distribution of
places considerable mass over negative values, even though the quantiles must clearly be positive in both the uniform and exponential examples. This underscores the use of the asymmetric Laplace distribution as only an approximate or working likelihood, to be used for the narrow purpose of recovering the quantile,6 and (b) the posterior mean often yields a negative point estimate of the quantile which, for these sampling models, we know cannot be the case. This never occurs when using the posterior mode, of course, which equals
in these examples.
![]()
Figure 2. Results from uniform and exponential sampling experiments,
.
The overall preference for the mean relative to the mode, according to our two metrics considered, stems from the fact that the posterior mode’s sampling distribution places more mass over relatively large positive deviations from the true quantile. This preference, however, remains sensitive to the metric employed. The mode of the sampling distribution of the posterior mode, for example, is much closer to the true quantile than the comparable mode of the posterior mean: Those modes for the {posterior mean, posterior mode (and actual quantile)} are {−0.106, 0.046, (0.053)} and {−0.08, 0.12, (0.1)} for the exponential and uniform cases, respectively. Furthermore, when samples are very small, the posterior mean sometimes provides a point estimate that we are certain is wrong, as it lies outside of the support of the random variable. In terms of our two commonly-used measures of average performance, the posterior mean is certainly comparable to, if not preferred over, the posterior mode, despite the latter’s formal connection with the desired quantile.
4. Conclusion
This note investigated a few issues surrounding Bayesian quantile regression. First, under commonly-used priors, we analytically derived the exact posterior distribution of the location parameter in an asymmetric Laplace likelihood, a likelihood that is often used for Bayesian quantile regression. We documented the non-uniqueness of the mode of that distribution in certain cases. Second, we performed a series of generated data experiments to investigate how well the posterior mean performs in recovering the quantile, even when the quantile itself is coincident with the mode rather than the mean. Although the posterior mean can sometimes produce estimates that are known to be wrong, in terms of certain measures of average performance, the posterior mean compares similarly to—and perhaps favorably to—the posterior mode. Finally, additional work can be conducted to investigate these issues in cases beyond the univariate example considered here, where the quantile functions are also covariate-dependent.
NOTES
1We consider the more general asymmetric Laplace distribution with scale parameter σ here, although σ could be fixed at one (or another value) if desired (see, e.g., Yang et al. (Yang et al., 2016) ).
2Khare and Hobert (Khare & Hobert, 2012) also establish geometric ergodicity of this Gibbs algorithm.
3We parameterize the inverse gamma distribution such that
. See, for example, Chan et al. (Chan et al., 2019) , page 442, for further discussion.
4This point is certainly not new but may be underappreciated. See, for example, Yang et al. (Yang et al., 2016) for a related discussion.
5In these experiments, we set
and
. Similar results emerged, however, when fixing
and instead evaluating the posterior in (4) at this restriction.
6See, e.g., Yang et al. (Yang et al., 2016) for additional discussion.