New Methods to Calculate Water Saturation in Shale and Tight Gas Reservoirs ()
1. Introduction
The reservoir characterization is a fundamental task for the determination of future reservoir performance. A large number of errors may enter the calculations associated with a future prediction of reservoir performance if there is no accurate and appropriate reservoir characterization which can cause the lose of the important values of reserves estimations and hydrocarbon production, etc. [1]. In particular, the water saturation has significant effects on shale reservoir performance [2] [3]. Accurate estimation of water saturation is accounted as one of the most challenging computations associated with petrophysical properties. In reservoir characterization, the determination of water saturation is a key step for the prediction of future reservoir performance in terms of production. Furthermore, the value of water saturation is needed in calculations related to the original oil and gas place so that the difference in water saturation calculated may lead to considerable differences in these volumes. The importance of water saturation has become more apparent when the reservoirs refer to rocks with low porosity and permeability such as shale and tight formations. As a result, the shales make up a large proportion of the rocks with many challenges and complexities. The availability of detrital clay minerals in pores, reservoir heterogeneities in the directions vertically and laterally, considerable formation thickness, over-pressures condition, the existence of free water zone independently, and the intercalation and co-existence of source rocks with reservoir rocks could be accounted as main differences between the shale tight and conventional reservoirs [4].
Over the years, many attempts have been carried out for accurate calculation of formation water saturations. Furthermore, there are few studies to estimate water saturation of shale and tight reservoirs. Fertl and Hammack [5] conducted a comparative study of the different methods to calculate water saturation of shaly sandstone reservoirs utilizing the actual field data. The comparative analysis conducted by them indicated the practical applications of these different techniques to the interpretation of shaly pay sands.
Al-Blushi et al. [6] proposed some predictive models to calculate water saturation based on log data. They used artificial neural network (ANN) methodology to develop their model for two Middle Eastern sandstone reservoirs. The results indicated that the model developed based on ANN strategy is capable to predict water saturation of Middle Eastern reservoirs studied. Kenari and Mashohor [7] used machine learning approach to propose an intelligent model for the prediction of water saturations. To this end, they used well log data from un-cored well. The results revealed that the intelligent method employed is accurate and rapid for the prediction of water saturation. Amiri et al. [8] developed an ANN model to estimate water saturation in tight and shale gas reservoir. They also used the imperialist competitive algorithm as optimization methodology to couple with the ANN algorithm. The results demonstrated that the model developed based on the neural network and imperialist competitive algorithms outperform the conventional method compared in their study.
As a result, the previously published models available in the literature fail to cover a wide range of petrophysical properties to estimate water saturation. Furthermore, the literature models have not been proposed on the basis of large numbers of water saturation data points. As a result, the prediction of water saturation by the literature models requires time-consuming calculations, reading graphs, optimization of the coefficients, etc. Therefore, the development of simple-to-use predictive models as well as empirically derived methods is needed. In this study, a large and extensive data bank is used, including more than four thousands petrophysical data points for the development of a reliable artificially intelligent based model which is based on the least square support vector machine (LSSVM) and an empirically derived method using gene expression programming (GEP) algorithm. Additionally, the most important error parameters are calculated to visualize the accuracy of the models proposed in this study as well as graphical error analysis including scatter diagram and contour map.
2. Database
A literature survey on the previously published researches demonstrated that true formation resistivity (Rt), porosity induced by neutron log (PHID), porosity induced by density log (PHIN), effective prosity from density log (PHIDE), effective prosity from neutron log (PHINE), effective porosity induced by density and neutron logs (PHIDNE), effective porosity (PHIE), total porosity (PHIX), bulk density (RHOB), photoelectic (PE), and volume of shale from gamma ray (Vsh) are known as the most effective parameters for the calculation of water saturation (Sw) [6] [7] [8] [9] [10]. Therefore, a large and comprehensive data bank including the petrophysical properties noted above is provided in this study in order to develop reliable models for accurate estimation of water saturation of shale and tight gas reservoirs. To this end, the core and well log data [8] from 12 wells of Mesaverde group tight reservoir located in the largest Western US has been applied for the model development. More than 4000 data points has been considered from one of the tight gas sand basins in this study. These data show that Sw does not have a strongly linear relationship with individual parameter: PHIE, Vsh, Rt, PHIN, PHIDE, PHIDNE. Therefore, all of the paramters are correlated with collectively. The petrophysical properties which have the highest effects on the water saturation data available in the data bank are considered as input parameters for the model development. Table 1 summarizes the ranges of the most effective petrophysical properties as well as water saturation data available in the data bank provided.
![]()
Table 1. Ranges of data used for the prediction of water saturation data of shale and tight reservoirs using the models developed in this study.
3. Development of Models
3.1. Least Squares Support Vector Machine Model
Least squares support vector machines are least squares forms of support vector machines (SVM), which are a set of associated supervised learning methods that investigate data and identify patterns, and that are used for sorting and regression analysis offered by Suykens et al. [11] [12] [13]. In LS-SVM a linear approximation is prepared in kernel induced feature space. By considering a data set
, with input data
and output data
, the regression model can be established as follows [13] [14] [15] :
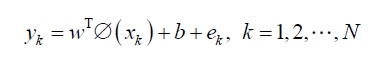 (1)
(1)
In these equations w characterizes the linear regression (regression weight), T is symbolic of the transpose matrix, e is training items regression error, b is the model linear regression intercept, and shows the feature map. The cost function of LSSVM algorithm, QLSSVM is calculated below [12] [13] [14].
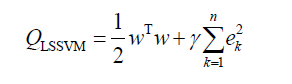 (2)
(2)
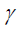 is the relative weight of the regression errors summation compared to the regression weight. By assistance of Lagrange function, the regression weight normally is showed as follows [16] [17].
is the relative weight of the regression errors summation compared to the regression weight. By assistance of Lagrange function, the regression weight normally is showed as follows [16] [17].
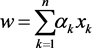 (3)
(3)
In which 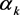 is defined as.
is defined as.
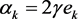 (4)
(4)
With the assumption of linear regression between independent and dependent LSSVM variables, Equation (1) can be re-written as [14] [16].
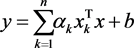 (5)
(5)
With the subsequent equation the Lagrange multipliers, 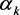 can be considered as [12] [13] [17].
can be considered as [12] [13] [17].
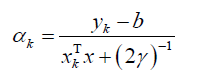 (6)
(6)
By means of Kernel function the first linear regression equation will be changed into a nonlinear form [15] [16] [17].
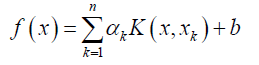 (7)
(7)
In the above equation, 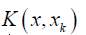 represents the Kernel function, made by inner product of the vectors
represents the Kernel function, made by inner product of the vectors 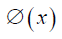 and
and 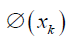 [13] [16].
[13] [16].
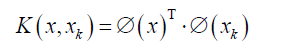 (8)
(8)
Radial basis function (RBF) is the utmost used relation for calculating the Kernel function [14] [17].
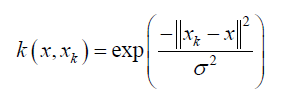 (9)
(9)
Here 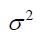 is a decision variable. Its optimisation is controlled by an external procedure during model’s internal computations. The mean square error (MSE) definition for the LSSVM can be defined as follows [16] [17].
is a decision variable. Its optimisation is controlled by an external procedure during model’s internal computations. The mean square error (MSE) definition for the LSSVM can be defined as follows [16] [17].
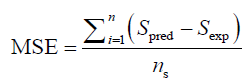 (10)
(10)
where S is the water saturation, pred. and exp. stand for the predicted, and experimental or actual data, respectively, and ns is the initial population number [16] [17].
3.2. Gene Expression Programming
Ferreira [18] developed an intelligent evolutionary algorithm called gene expression programing (GEP) which is able to construct symbolic models mathematically. In GEP approach, control parameters, function set, fitness function, terminal set, and termination condition are recognized as the key components [19]. Those parse trees are known as expression trees (ETs) for the GEP algorithm [20]. Hence, the nature of gene expression programming authorities the evolution of more complex programs composed of various substructures or subprograms so-called GEP genes. For illustrating the mathematical performance of the GEP methodology in developing symbolic models, a simple GEP-based equation counting a chromosome composed of two genes connected together by a multiplication fitness function is expressed as follows:
(11)
where u, v, f and l express the input variables for estimating the target variable (water saturation), and ÷, × and + stand for the fitness functions.
3.3. Model Development
For developing predictive models to estimate the water saturation data using two modelling strategies viz. the LSSVM and GEP algorithms, the same input variables including PHIE, Vsh, GR, Rt, PHIN, PHIDE, PHIDNE have been considered. The database gathered should be randomly divided into two sub-sets. The first sub-set is called “Training” and the second is “Test” set which have been applied to develop models and check the prediction performance, respectively. Around 80 % of the entire data is assigned to the training set, and the rest is allocated to the test set. In this study, two important statistics error parameters have been used through a comprehensive error analysis in order to visualize the accuracy and performance capability of the developed models for the water saturation prediction. The statistical error parameters implemented in this study are squared correlation coefficient and average absolute relative deviation (AARD) as follows:
![]() (12)
(12)
![]() (13)
(13)
In the first stage, the LSSVM algorithm was coupled with an optimization strategy known as coupled simulated annealing (CSA) [21] [22] [23] for obtaining the optimum values of the LSSVM parameters (γ and σ2). As a result, the values tuned by the CSA technique for the LSSVM model in order to estimate the water saturation data are σ2 = 1.4181 and γ = 328.2432. To propose a new empirically derived equation based on the GEP algorithm, three genes with 30 chromosomes are applied as a starting condition. Additionally, the AARD is considered as the accuracy function so that the optimal form of the newly developed model has the lowest AARD. Furthermore, a function set including power, cube root, ×, ÷, - and + is selected during applying the GEP methodology. The final model obtained by the GEP algorithm developed in this study is a simple-to-use equation with lowest possible coefficients as follows:
![]() (14)
(14)
![]() (15)
(15)
![]() (16)
(16)
![]() (17)
(17)
where Sw denotes the water saturation, PHIDNE stands for the effective porosity induced by density and neutron logs, PHIDE indicates the effective porosity from density log, PHIN shows the porosity induced from neutron zoned, PHIE is the effective porosity, Vsh expresses the volume of shale from gamma ray, and finally Rt stands for the true formation resistivity.
As a result, the optimal condition to apply the equations above is the range of the petrophysical properties used which have previously been summarized in Table 1. Furthermore, another important condition to develop the equations above is that some input parameters i.e. Vsh, PHIDE, PHIDNE, PHIE have a minimum value of zero and should not be in the denominator individually. Therefore, this condition is considered to develop the equations presented above. Although the equation proposed in this study is also applicable for calculating water saturation of conventional reservoirs, the equations proposed in this study have been developed based on the data from shale and tight reservoirs.
4. Results and Discussion
The error parameters calculated for the LSSVM model and the new method (Equation (14)) are AARD= 3% and R-squared= 0.96, and AARD= 10.6 and R-squared = 0.77. Table 2 also summarizes some calculated water saturation data by the predictive models developed in this study based on the LSSVM and GEP algorithms as well as the absolute relative deviation (ARD) for each data point studied. The results obtained indicate that the water saturation values characterized by the GEP and LSSVM models are in satisfactory agreement with the actual data. For further comparison of the performance of the models developed in this study graphically, scatter diagrams (crossplot) of the data predicted versus actual data of water saturation are sketched. Figure 1 and Figure 2 illustrate the output values obtained from the LSSVM model and the newly proposed equation against the actual data of water saturation, respectively. As is shown clearly in the Figure 1 and Figure 2, the data corresponding to the developed models are almost around the unit slope line (Y = X), revealing there is acceptable agreement between the models predictions and the actual data of data of water saturation.
![]()
Table 2. The water saturation data calculated by the models developed in this study at the different petrophysical properties.
![]()
Figure 1. Graphical comparison (crossplot) between the results obtained by the LSSVM model developed in this study and the actual data of Sw.
![]()
Figure 2. Graphical comparison (crossplot) between the results obtained by the new method proposed in this study and the actual data of Sw.
Figure 3 and Figure 4 reveal the absolute relative deviation contours of the water saturation predicted by the LSSVM model and the newly proposed equation, respectively. It is evident from the figures that the models developed in this study are able to predict water saturations of shale and tight reservoir in the dataset range particularly two important parameters of true resistivity and effective porosity induced by density and neutron logs. However, the model developed in the current study could not predict the water saturation with high accuracy in the PHIDNE range of 0.1 - 0.3, and Rt range of 0 - 100. From the results obtained, it could be concluded that the methods proposed in this study (the LSSVM and GEP) can be reliable alternatives for the previously published models available in the literature as they may fail to cover a wide range of petrophysical properties to estimate water saturation, and also require time-consuming calculations, reading graphs, optimization of the coefficients, etc. As a result, the accuracy and future applicability are two main advantages of the models developed in this study. The LSSVM model could predict the water saturation data with higher accuracy than the new equation proposed. On the other hand, the equation proposed based on the GEP algorithm is more simple-to-use so that it can be used for future calculations and soft wares related to water saturation and reservoir characterization. Therefore, a combined application of both LSSVM and GEP algorithms is recommended in order to accurately predict water saturation of shale and tight reservoirs.
![]()
Figure 3. Absolute relative deviation (ARD) contour of water saturation data for the developed LSSVM model in the ranges of true resistivity and effective porosity induced by density and neutron logs.
![]()
Figure 4. Absolute relative deviation contour of water saturation data for the new proposed method in the ranges of true resistivity and effective porosity induced by density and neutron logs.
5. Conclusion
The current study aimed to propose reliable models for the prediction of water saturation of shale and tight gas reservoir. The modelling approaches implemented in this study were the gene expression programming, and least squares support vector machine. The results obtained in the current study indicated that the two methods developed in this study could be applied for the characterization water saturation of shale reservoirs. The R-squared error values of 0.96 and 0.77 (average absolute relative deviation (AARD) of 3% and 10.6%) were obtained for the LSSVM model and the newly proposed equation, respectively. As a result, the methods proposed by gene expression programming in this study is a capable alternative for the previously published models which require complex and time-consuming calculations.