1. Introduction
Variable selection has played a pivotal role in scientific and engineering applications, such as biochemical analysis [1] , bioinformatics [2] and text mining [3] , among other areas. A significant portion of existing variable selection methods are only applicable to linear parametric models. Despite the linearity and additivity assumption, variable selection in linear regression models has been popular since 1970, referring to Akaike information criterion (AIC; [4] ); Bayesian information criterion (BIC; [5] ) and Risk inflation criterion (RIC; [6] ).
Popular classical sparse-regression methods such as Least absolute shrinkage operator (LASSO [7] [8] ), and related penalization methods [9] [10] [11] [12] have gained popularity over the last decade due to their simplicity, computational scalability and efficiency in prediction when the underlying relation between the response and the predictors can be adequately described by parametric models. Bayesian methods [13] [14] [15] with sparsity inducing priors offer greater applicability beyond parametric models and are a convenient alternative when the underlying goal is in inference and uncertainty quantification. However, there is still a limited amount of literature which seriously considers relaxing the linearity assumption, particularly when the dimension of the predictors is high. Moreover, when the focus is on learning the interactions between the variables, parametric models are often restrictive since they require very many parameters to capture the higher-order interaction terms.
Smoothing based non-additive nonparametric regression methods [16] [17] [18] [19] can accommodate a wide range of relationships between predictors and response leading to excellent predictive performance. Such methods have been adapted for different methods of functional component selection with non- linear interaction terms: component selection and smoothing operator (COSSO; [20] ), sparse addictive model (SAMS; [21] ) and variable selection using adaptive nonlinear interaction structure in high dimensions (VANISH; [22] ). However, when the number of variables is large and their interaction network is complex, modeling each functional component is highly expensive.
Nonparametric variable selection based on kernel methods is increasingly becoming popular over the last few years. Liu et al. [23] provided a connection between the least square kernel machine (LKM) and the linear mixed models. Zou et al. [24] , Savitsky et al. [25] introduced Gaussian process with dimension- specific scalings for simultaneous variable selection and prediction. Yang et al. [26] argued that a single Gaussian process with variable bandwidths can achieve the optimal rate in estimation when the true number of covariates
. However, when the true number of covariates is relatively high, the suitability of using a single Gaussian process is questionable. Moreover, such an approach is not convenient to recover the interaction among variables. Fang et al. [27] used the nonnegative Garotte kernel to select variables and capture interaction. Though these methods can successfully perform variable selection and capture the interaction, non-additive nonparametric models are not sufficiently scalable when the dimension of the relevant predictors is even moderately high. [27] claimed that extensions to additive models may cause over-fitting issues in capturing the interaction between variables (i.e. capture more interacting variables than the ones which are influential).
To circumvent this bottleneck, Yang et al. [26] , Qamar and Tokdar [28] introduced the additive Gaussian process with sparsity inducing priors for both the number of components and variables within each component. The additive Gaussian process captures interactions among variables, can scale up to moderately high dimensions and are suitable for low sparse regression functions. However, the use of two component sparsity inducing prior forced them to develop a tedious Markov chain Monte Carlo algorithm to sample from the posterior distribution.
To overcome the computational challenge facing in Yang et al. [26] , Qamar and Tokdar [28] , we propose a novel method, called the additive Gaussian process with soft interactions. More specifically, we decompose the unknown regression function F into k components, such as
, for k hard shrinkage parameters
,
. Each component
is independent. Each of them is assigned to a Gaussian process prior. To induce sparsity within each Gaussian process, we introduce an additional level of soft shrinkage parameters. The combination of hard and soft shrinkage priors makes our approach very straightforward to implement and computationally efficient, while retaining all the advantages of the additive Gaussian process proposed by Qamar and Tokdar [28] . We propose a combination of Markov chain Monte Carlo (MCMC) and the Least Angle Regression algorithm (LARS) to select the Gaussian process components and variables within each component.
The rest of the paper is organized as follows. Section 2 presents the additive Gaussian process model. Section 3 describes the two-level regularization and the prior specifications. The posterior computation is detailed in Section 4 and the variable selection and interaction recovery approach are presented in Section 5. The simulation study results are presented in Section 6. A couple of real data examples are considered in Section 7. We conclude with a discussion in Section 8.
2. Additive Gaussian Process
For observed predictor-response pairs
, where
(i.e. n is the sample size and p is the dimension of the predictors), an additive nonparametric regression model can be expressed as
(1)
The regression function F in (1) is a sum of k regression functions, with the relative importance of each function controlled by the set of non-negative parameters
. Typically the unknown parameter
is assumed to be sparse to prevent F from over-fitting the data.
Gaussian process (GP) [29] provides a flexible prior for each of the component functions in
. GP defines a prior on the space of all continuous functions, denoted
for a fixed function
and a positive definite function c defined on
such that for any finite collection of points
, the distribution of
is multivariate Gaussian with mean
and variance-covariance matrix
. The choice of the covariance kernel is crucial to ensure the sample path realizations of the Gaussian process are appropriately smooth. A squared exponential covariance kernel
with an Gamma hyperprior assigned to the inverse-bandwidth parameter
ensures optimal estimation of an isotropic regression function [30] even when a single component function is used (
). When the dimension of the covariates is high, it is natural to assume that the underlying regression function is not isotropic. In that case, Bhattacharya et al. [31] showed that a single bandwidth parameter might be inadequate and dimension specific scalings with appropriate shrinkage priors are required to ensure that the posterior distribution can adapt to the unknown dimensionality. However, Yang et al. [26] showed that single Gaussian process might not be appropriate to capture interacting variables and also does not scale well with the true dimension of the predictor space. In that case, an additive Gaussian process is a more effective alternative which also leads to interaction recovery as a bi-product. In this article, we work with the additive representation in (1) with dimension specific scalings (inverse-bandwidth parameters)
along dimension j for the lth Gaussian process component,
and
.
We assume that the response vector
in (1) is centered and scaled. Let
with
(2)
In the next section, we discuss appropriate regularization on
and
. A shrinkage prior on the
facilitates the selection of variables within component l and allows adaptive local smoothing. An appropriate regularization on
allows F to adapt to the degree of additivity in the data without over-fitting.
3. Regularization
A full Bayesian specification will require placing prior distribution on both
and
. However, such a specification requires tedious posterior sampling algorithms to sample from the posterior distribution as seen in [28] . Moreover, it is difficult to identify the role of
and
since one can remove the effect of the lth component by either setting
to zero or by having
. This ambiguous representation causes mixing issues in a full-blown MCMC. To facilitate computation, we adopt a hybrid approach between frequentist and Bayesian to regularize
and
, respectively. The hybrid-algorithm is a combination of i) MCMC, to sample
conditional on
ii) and optimization to estimate
conditional on
. With this viewpoint, we propose the following regularization on
and
. With the parameter
, each component controls the selection of variables and interaction among them. In addition to
, the parameter
allows the model (1) to select significant components, which includes interested variables and interaction network. Together,
and
are the global-local shrinkage on F.
3.1. L1 Regularization for f
Conditional on
, (1) with
, and
. Hence we impose
regularization on
, which is as following
(3)
In the algorithm,
is updated using least absolute shrinkage and selection operator (LASSO) [7] [32] [33] . The
regularization enforces sparsity on
at each stage of the algorithm, thereby pruning the unnecessary Gaussian process components in F. The parameter
in (3) is selected using five fold cross validation.
3.2. Choice of k Components
The proposed model has the number of components, k, which determines how many components to fit the data and build the prediction. We propose using LASSO to choose k. First, we start with a large k value. As
is updated with the LASSO algorithm, the LASSO algorithm prunes unnecessary Gaussian process
. Therefore, the value of k is updated, which is equal to the number of components which are not pruned.
3.3. Global-local shrinkage for
The parameters
controls the effective number of variables within each component. For each l,
are assumed to be sparse. As opposed to the two component mixture prior on
in [28] , we enforce weak-sparsity using a global-local continuous shrinkage prior which potentially have substantial computational advantages over mixture priors. Many continuous shrinkage priors have been proposed recently [34] - [39] . These priors can be unified through a global-local (GL) scale mixture representation of [40] below,
(4)
for each fixed l, where
and
are densities on the positive real line. In (4),
controls global shrinkage towards the origin while the local parameters
allow local deviations in the degree of shrinkage for each predictor. Special cases include Bayesian lasso [34] , relevance vector machine [35] , normal-gamma mixtures [36] and the horseshoe [37] [38] among others. Motivated by the remarkable performance of horseshoe, we assume both
and
to be square-root of half-Cauchy distributions. Both
and
will be updated using the MCMC algorithm.
4. Hybrid Algorithm for Prediction, Selection and Interaction Recovery
In this section, we develop a fast algorithm which is a combination of
optimization and conditional MCMC to estimate the parameters
,
, and
for
and
. Conditional on
, (1) is linear in
and hence we resort to the least angle regression procedure [8] with five fold cross validation to estimate
. The computation of the lasso solutions is a quadratic programming problem, and can be tackled by standard numerical analysis algorithms.
The least angle regression procedure better approach which exploits the special structure of the lasso problem, and provides an efficient way to compute the solutions. Next, we describe the conditional MCMC to sample from
and
at a new point
conditional on the parameters
. For two collection of vectors
and
of size
and
respectively, denote by
the
matrix
. Let
and define
and
denote the corresponding matrices. For a random variable q, we denote by
the conditional distribution of q given the remaining random variables.
Observe that the algorithm does not necessarily produce samples which are approximately distributed as the true posterior distribution. The combination of optimization and conditional sampling is similar to stochastic EM [41] [42] which is employed to avoid computing costly integrals required to find maximum likelihood in latent variable models. Conditional on
, the MCMC algorithm to update
,
, and
is as following:
1) Compute the kernel
,
,
,
with the kernel formula
.
2) Compute
Compute the predictive mean
(5)
3) Compute the predictive variance
(6)
4) Sample
.
5) Compute the predictive
(7)
6) Update
by sampling from the following posterior distribution,
(8)
7) Update
by sampling from the following posterior distribution,
(9)
8) Update
by using the formula
.
9) Update the vector
with the LASSO estimation.
10) Update
by sampling
(10)
11) Update
and prune unnecessary
where
with the LASSO algorithm.
The MCMC algorithm above is illustrated with the following flow-chart.

In the MCMC algorithm above, the conditional distributions of
and
are not available in closed form. Therefore, we sample them using Metropolis- Hastings algorithm [43] . In this paper, we give the algorithm for updating
only, as the steps for
are similar. Assuming that the chain is currently at the iteration t, the Metropolis-Hastings algorithm to sample
independently for
proceeds as following:
1) Propose
.
2) Compute the Metropolis ratio:
(11)
3) Sample
. If
then
, else
.
The flowchart for the above Metropolis-Hastings algorithm is as following:
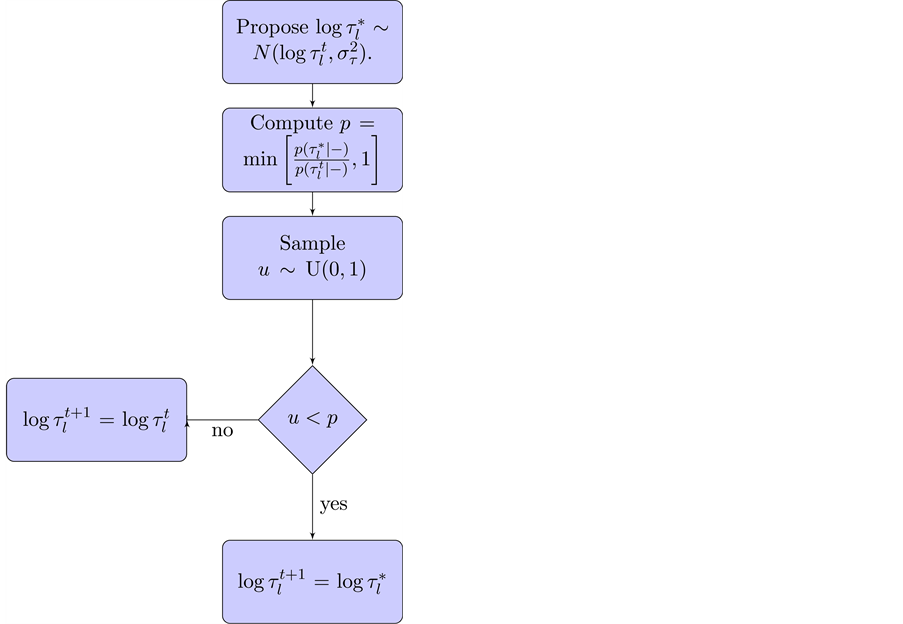
The proposal variance
is tuned to ensure that the acceptance probability is between 20% - 40%. We also propose a similar Metropolis-Hastings algorithm to sample from the conditional distribution of
.
5. Variable Selection and Interaction Recovery for Selected Variables
In this section, we first state a generic algorithm to select important variables based on the samples of the parameter vector
. This algorithm is independent of the prior for
and unlike other variable selection algorithms, it requires few tuning parameters making it suitable for practical purposes. The idea is based on finding the most probable set of variables in the median of the
samples. Since the distribution for the number of important variables is more stable and largely unaffected by the Metropolis-Hastings algorithm, we find the mode H of the distribution for the number of important variables. Then, we select the H largest coefficients from the posterior mean of
.
In this algorithm, we use k-means algorithm [44] [45] with
at each iteration to form two clusters, corresponding to signal and noise variables respectively. One cluster contains values concentrating around zero, corresponding to the noise variables. The other cluster contains values concentrating away from zeros, corresponding to the signals. At the tth iteration, the number of non-zero signals
is estimated by the smaller cluster size out of the two clusters. We take the mode over all the iterations to obtain the final estimate
for the number of non-zero signals i.e.
. The
largest entries of the posterior median of
are identified as the non-zero signals.
We run the algorithm for 5000 iterations with a burn-in of 2000 to ensure convergence. Based on the remaining iterates, we apply the algorithm to
for each component
to select important variables within each
for
. Using this approach, we select the important variables within each function. We define the inclusion score of a variable as the proportion of functions (out of k) which contains that variable. Next, we apply the algorithm to
and select the important functions. Let us denote by
the set of active functions, obtained from the LASSO algorithm as discussed in Section 3.2. The interaction score between a pair of selected variables is defined as the proportion of functions within
in which the selected pair appears together. Using these interaction scores, we can find the interaction between important variables with optimal number of active components. Observe that the inclusion and interaction scores are not a functional of the posterior distribution and is purely a property of the additive representation. Hence, we do not require the sampler to converge to the posterior distribution. As illustrated in Section 6, these inclusion and the interaction scores provide an excellent representation of a variable or an interaction being present or absent in the model. An illustratfor both variable selection and interaction will be displayed in Section 6.
6. Simulation Examples
In this section, we consider eight different simulation settings with 50 replicated datasets each and test the performance of our algorithm with respect to variable selection, interaction recovery, and prediction. To generate the simulated data, we draw
, and
, where
,
and
. Table 1 and Table 2 summary the result and signal to noise ratio (SNR) for the eight different datasets with different combinations of p and n for both non-interaction and interaction cases, respectively.
6.1. Variable Selection
We compute the Inclusion score for each variable in each simulated dataset, then provide the bar plots as in Figures 1-4 below.
![]()
Table 1. Non-interaction simulated datasets.
![]()
Table 2. Interaction simulated datasets.
![]()
Figure 1. Inclusion score for dataset 1. (a) Non-interaction Case; (b) Interaction Case.
![]()
Figure 2. Inclusion score for dataset 2. (a) Non-interaction Case; (b) Interaction Case.
![]()
Figure 3. Inclusion score for dataset 3. (a) Non-interaction Case; (b) Interaction Case.
![]()
Figure 4. Inclusion score for dataset 4. (a) Non-interaction Case; (b) Interaction Case.
From these histograms, we rank the Inclusion score value. Based on our ranking, we select a threshold value to identify the signal based on the top Inclusion score values. From our ranking, the selected threshold value is 0.1. The ranking of variables selection has been mentioned in Guyon and Elisseeff [46] , Forman [47] , Stoppiglia et al. [48] . The choice of the threshold variable based upon the data has been mentioned in Genuer et al. [49] . When we obtain selected variables, we compute the false positive rate (FPR), which is the proportion of true signals not detected by our algorithm, and false negative rate (FNR), which is the proportion of false signals detected by our algorithm. Both values are recorded in Table 3 to assess the quantitative performance of our algorithm.
Based on the results in Table 3, it is immediate that the algorithm is very successful in delivering accurate variable selection for both non-interaction and interaction cases.
6.2. Interaction Recovery
In order to capture the interaction network, we compute the probability of interaction between two variables by calculating the proportion of functions in which both the variables jointly appear. Since we are interested in capturing the interaction between selected variables, we plot interaction heat map for selected variables with their probability of interaction values, for each dataset for both the non-interaction and interaction cases.
Based on Figures 5-8, it is evident that the estimated interaction probabilities for the non-interacting variables are less than the corresponding number for interacting variables. With these heat map values, we plot the interaction
![]()
Table 3. The average false positive (FPR) and false negative (FNR) for replicated datasets.
![]()
Figure 5. Interaction heat map for dataset 1. (a) Non-interaction Case; (b) Interaction Case.
![]()
Figure 6. Interaction heat map for dataset 2. (a) Non-interaction Case; (b) Interaction Case.
![]()
Figure 7. Interaction heat map for dataset 3. (a) Non-interaction Case; (b) Interaction Case.
![]()
Figure 8. Interaction heat map for dataset 4. (a) Non-interaction Case; (b) Interaction Case.
network in Figure 9 & Figure 10 for selected variables.
Based on the interaction network in Figure 9 & Figure 10, we observe that edges for interaction cases are thicker than edges for non-interaction cases. In interaction cases, interacted variables are connected in the network, while every variables is connected in non-interaction cases. Therefore, our algorithm successfully captures the interaction network in all the datasets for selected variables according to the Inclusion score.
6.3. Predictive Performance
We randomly partition each dataset into training (50%) and test (50%) observations. We apply our algorithm on the training data and compare the performance on the test dataset. For the sake of brevity we plot the predicted vs. the observed test observations only for a few cases in Figure 11.
From Figure 11, the predicted observations and the true observations fall very closely along the
line demonstrating a good predictive performance. We compare our results with [27] . However, their additive model was not able to capture higher order interaction and thus have a poor predictive performance compared to our method.
![]()
Figure 9. Interaction network for dataset 1 and 2, respectively. (a) Non-interaction 1; (b) Interaction 1; (c) Non-interaction 2; (d) Interaction 2.
![]()
Figure 10. Interaction network for dataset 3 and 4, respectively. (a) Non-interaction 3; (b) Interaction 3; (c) Non-interaction 4; (d) Interaction 4]
![]()
Figure 11. Prediction versus Response for Simulated Data. (a) Prediction for Non- interaction 1; (b) Prediction for Non-interaction 3; (c) Prediction for Interaction 1; (d) Prediction for Interaction 3.
6.4. Comparison with BART
Bayesian Additive Regression Tree (BART; [50] ) is a state of the art method for variable selection in nonparametric regression problems. BART is a Bayesian “sum of tree” framework which fits and infers the data through an iterative back-fitting MCMC algorithm to generate samples from a posterior. Each tree in BART [50] is constrained by a regularization prior. Hence BART is similar to our method which also resorts to back-fitting MCMC to generate samples from a posterior.
Since BART is well-known to deliver excellent prediction results, its performance in terms of variable selection and interaction recovery in high- dimensional setting is worth investigating. In this section, we compare our method with BART in all the three aspects: variable selection, interaction recovery and predictive performance. For comparison, with BART, we used the same simulation settings as in Table 1 with all combinations of (n, p), where
and
.
We used 50 replicated datasets and compute average inclusion probabilities for each variable. Similar to §6.1, we ranked the Inclusion score, and chose the threshold value equal to 0.1 in order to find selected variables. Then, we computed the false positive and false negative rates for both algorithms as in Table 3. These values are recorded in Table 4.
In Table 4, the first column indicates which equations are used to generate the data with the respective p and n values in the second and third column for both non-interaction and interaction cases. For example, if the dataset is 1, the equations to generate the data is
and
for non-interaction and interaction case, respectively. NA value means that the algorithm cannot run at all for that particular combination of p and n values.
According to Table 4, BART performs similar to our algorithm when
and
. However, as p increases, BART fails to perform adequately while our algorithm still performs well even when p is larger than n. When p is twice
![]()
Table 4. Comparison between our algorithm and BART for variable selection.
as n, BART fails to run while our algorithm provides excellent results in variable selection. Overall, our algorithm performs significantly better than BART in terms of variable selection.
7. Real Data Analysis
In this section, we demonstrate the performance of our method in two real data sets. We use the Boston housing data and concrete slump test datasets obtained from UCI machine learning repository. Both data have been used extensively in the literature.
7.1. Boston Housing Data
In this section, we used the Boston housing data to compare the performance between BART and our algorithm. The Boston housing data [51] contains information collected by the United States Census Service on the median value of owner occupied homes in Boston, Massachusetts. The data has 506 number of instances with thirteen continuous variables and one binary variable. The data is split into 451 training and 51 test observations. The description for each variable is summarized in Table 5.
MEDV is chosen as the response and the remaining variables are included as predictors. We ran our algorithm for 5000 iterations and the prediction result for both algorithms is shown in Figure 12.
Although our algorithm has a comparable prediction error with BART, we argue below that we have a more convincing result in terms of variable selection. We displayed the Inclusion score barplot in Figure 13.
![]()
Table 5. Boston housing Dataset variable.
![]()
Figure 12. Prediction versus Response’s for Boston Housing Dataset. (a) Our Algorithm; (b) BART.
![]()
Figure 13. Inclusion score for the Boston Housing Dataset. (a) Our Algorithm; (b) BART.
Based on the histograms, we chose the threshold value equal to 0.1 for easily comparing BART and our algorithm. From the ranking and the chosen threshold value, BART only selected NOX and RM, while our algorithm selected CRIM, ZN, NOX, DIS, B and LSTAT. In order to compare the performance, we looked at Savitsky et al. [25] , which previously analyzed this dataset and selected variables RM, DIS and LSTAT. Clearly, the set of selected variables from our method has more common elements with that of Savitsky et al. [25] .
7.2. Concrete Slump Test
In this section we consider an engineering application to compare our algorithm against BART. The concrete slump test dataset records the test results of two executed tests on concrete to study its behavior [52] [53] .
The first test is the concrete-slump test, which measures concrete’s plasticity. Since concrete is a composite material with mixture of water, sand, rocks and cement, the first test determines whether the change in ingredients of concrete is consistent. The first test records the change in the slump height and the flow of water. If there is a change in a slump height, the flow must be adjusted to keep the ingredients in concrete homogeneous to satisfy the structure ingenuity. The second test is the “Compressive Strength Test”, which measures the capacity of a concrete to withstand axially directed pushing forces. The second test records the compressive pressure on the concrete.
The concrete slump test dataset has 103 instances. The data is split into 53 instances for training and 50 instances for testing. There are seven continuous input variables, which are seven ingredients to make concrete, and three outputs, which are slump height, flow height and compressive pressure. Here we only consider the slump height as the output. The description for each variable and output is summarized in Table 6.
The predictive performance is illustrated in Figure 14.
Similar to the Boston housing dataset, our algorithm performs closely to BART in prediction. Next, we investigated the performances in terms of variable selection. We plotted the bar-plot of the Inclusion score for each variable in Figure 15.
Yurugi et al. [54] determined that coarse aggregation has a significant impact on the plasticity of a concrete. Since the difference in slump’s height is to
![]()
Table 6. Concrete Slump Test dataset.
![]()
Figure 14. Prediction versus Response’s for Concrete Slump Test Dataset. (a) Our Algorithm; (b) BART.
![]()
Figure 15. Inclusion score for the Concrete Slump Test Dataset. (a) Our Algorithm; (b) BART.
measure the plasticity of a concrete, coarse aggregation is a critical variable in the concrete slump test. According to Figure 15, our algorithm selects coarse aggregation as the most important variable unlike BART, which clearly demonstrates the efficacy of our algorithm compared to BART.
7.3. Community and Crime Dataset
In this section we consider a dataset, which has more than 100 predictors to compare our algorithm against BART. Therefore, we chose the Community and Crime dataset. This dataset describes the socio-economic, law enforcement, and crime data in communities of the United States in 1995 [55] [56] .
In this data, there are about 124 predictors, 5 non-predictors, and 18 response values. The details for each response value can be found at University of California, Irvine (UCI) Machine Learning Database [57] . Since this data has missing values and non-predictors, we preprocessed the data before applying our algorithm and BART on it. After the preprocessing, the number of observations n goes from 2215 to 114 observations, and the number of predictors p becomes 123. Therefore, in this example, we have a case that the number of predictors p is larger than the number of observation n. We split the data into 79 instances for training and 35 instances for testing. We investigated both algorithms’ performance in variable selection. We plotted the histogram of the Inclusion score for each variable in Figure 16.
Since BART and our algorithm has different Inclusion score values, we cannot pick the threshold values to identify variables for comparison. Since our algorithm only selects 10 predictors, we decided to rank predictors in BART based on their Inclusion score. Then, we chose BART’s top 10 predictors with highest Inclusion score to compare with ours. Table 7 lists selected factors affecting violent crime rate based on our algorithm and BART.
According to Blumstein and Rosenfeld [58] , the crime trend in the United States is contributed by the following factors 1) Economic condition 2) Policing 3) Control of firearms 4) Drugs markets 5) Gangs 6) Socialization and social service 7) Incarceration percent 8) Demographic change. Our selected variables can be grouped into three categories based on above factors. The first category
![]()
Figure 16. Inclusion score for the Concrete Slump Test Dataset. (a) Our Algorithm; (b) BART.
![]()
Table 7. Selected variables between our algorithm and BART.
is economic condition: variables 1, 2, 5, 6, and 7. The second category is demographic change: variables 3 and 4. The third category is policing: variables 8, 9, and 10. Similarly, selected variables in BART can be grouped into three categories. The first category is economic condition: variables 3, 2, 5 and 8. The second category is demographic change: variables 1 and 7. The third category is socialization and social service: variable 6. Based on these grouping, one can see that our selected variables is more agreeable to the study of Blumstein and Rosenfeld [58] than BART.
8. Conclusion
In this paper, we propose a novel Bayesian nonparametric approach for variable selection and interaction recovery with excellent performance in selection and interaction recovery in both simulated and real datasets. Our method obviates the computation bottleneck in recent unpublished work [28] by proposing a simpler regularization involving a combination of hard and soft shrinkage parameters.
Although such sparse additive models are well known to adapt to the underlying true dimension of the covariates [26] , literature on consistent selection and interaction recovery in the context of nonparametric regression models is missing. As a future work, we propose to investigate consistency of the variable selection and interaction of our method.