Tree Automata for Extracting Consensus from Partial Replicas of a Structured Document ()
1. Introduction
A significant proportion of documents handled and/or exchanged by appli- cations has a regular structure defined by a grammatical model (DTD: Document Type Definition, schema [1] ): they are called structured documents. The ever- increasing power of communication networks in terms of throughput and security, as well as efficiency is concerned, has revolutionized the way of editing such documents. Indeed, to the classical model of an author, editing locally and autonomously his document, was added the (asynchronous) cooperative editing in which, several authors located on geographically distant sites, coordinate to edit asynchronously a same structured document (Figure 1): it is an asyn- chronous cooperative editing workflow.
In such editing workflows (Figure 2), the desynchronized editing phases in which each co-author edits on his site his copy of the document, alternate with the synchronization-redistribution phases in which the different contributions (local replicas) are merged (on a dedicated site) into a single document, which is then redistributed to the various co-authors for the continuation of the edition. This pattern is repeated until the document is completely edited.
In the literature, there are several cooperative editing systems offering, for some, a concurrent collaborative edition of the same document (Etherpad [2] , Google Docs [3] , Fidus Writer [4] , …), or on the other hand, a truly distributed and asynchronous edition (Wikis [5] [6] , Git [7] [8] , …) in which the co-authors work on replicas of the document; replication techniques as well as recon- ciliation strategies must then be addressed. If the collectively edited document is structured, it may in some cases be desirable for reasons of confidentiality, for example, a co-author has access only to certain information, meaning that he only has access to certain parts of the document belonging to certain given types (sorts1) of the document model. Thus, the replica 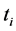 edited by co-author
edited by co-author
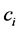 from the site i may be only a partial replica of the (global2) document t, obtained via a projection operation, which conveniently eliminates from global
from the site i may be only a partial replica of the (global2) document t, obtained via a projection operation, which conveniently eliminates from global
![]()
Figure 1. The desynchronized cooperative editing of partial replicas of a structured document.
![]()
Figure 2. An orchestration diagram of an asynchronous cooperative editing workflow.
document t parts which are not accessible to the co-author in question. We call “view” of a co-author, the set of sorts that he can access [9] . Figure 1 is an illustration of such a cooperative edition in which, the edition and the merging of the (global) document in conformity to the (global) model G of documents are perform on site 1; while on site 2 and 3, other co-authors perform the edition of the partial replicas in accordance with projected models of documents 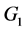 and
and 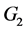 obtained from the global model G.
obtained from the global model G.
When asynchronous local editions are done on partial replicas, it can be assumed that each co-author has on his site a local document model guiding him in his edition. This local model can help to ensure that for any update 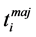 of a partial replica
of a partial replica 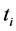 (conform to the considered (local) model), there is at least one document t conform to the global model so that
(conform to the considered (local) model), there is at least one document t conform to the global model so that 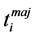 is a partial replica of t: for this purpose, the local model should be coherent towards the global one3. Thus,
is a partial replica of t: for this purpose, the local model should be coherent towards the global one3. Thus,
because of the asynchronism of the editing, the only inconsistencies that we can have when the synchronization time arrives are those from the concurrent edition of the same node4 (in the point of view of the global document) by several co-authors: the partial replicas concerned are said to be in conflict. This paper proposes an approach of detection and resolution of such conflicts by consensus during the synchronisation-redistribution phase, using a tree auto- maton said of consensus, to represent all documents that are the consensus of competing editions realised on the different partial replicas.
A structured document t is intentionally represented by a tree that possibly contains buds5 [9] (see Figure 3). Intuitively, synchronizing or merging consens-
ually the updates  of n partial replicas of a document t, consists in finding a document
of n partial replicas of a document t, consists in finding a document 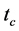 conform to the global model, integrating all the nodes of
conform to the global model, integrating all the nodes of 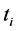 not in conflict and in which, all the conflicting nodes are replaced by buds. Consensus documents are therefore the largest prefixes without conflicts in merged documents. The algorithm of consensual merging presented in this paper is an adaptation of the fusion algorithm presented in [9] which does not handle conflicts. Technically, the process for obtaining the documents forming part of the consensus is: 1) for each update
not in conflict and in which, all the conflicting nodes are replaced by buds. Consensus documents are therefore the largest prefixes without conflicts in merged documents. The algorithm of consensual merging presented in this paper is an adaptation of the fusion algorithm presented in [9] which does not handle conflicts. Technically, the process for obtaining the documents forming part of the consensus is: 1) for each update 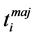 of a partial replica
of a partial replica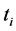 , we associate a tree automaton with exit states
, we associate a tree automaton with exit states 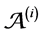 recognizing the trees (conform to the global model) for which
recognizing the trees (conform to the global model) for which 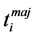 is a projection [9] . 2) The consensual automaton
is a projection [9] . 2) The consensual automaton 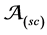 generating the consensus documents is obtained by perfor- ming a synchronous product of the automata
generating the consensus documents is obtained by perfor- ming a synchronous product of the automata 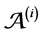 with a commutative and associative operator noted
with a commutative and associative operator noted ![]() that we define. It is such that:
that we define. It is such that:![]() . 3) It only remains to generate the set of trees (or those most representative) accepted by the automaton
. 3) It only remains to generate the set of trees (or those most representative) accepted by the automaton![]() , to obtain the consensus documents.
, to obtain the consensus documents.
In the subsequent sections, after the presentation (Section 2) of some concepts and definitions related to the cooperative editing and tree automata, we expose (Section 3) the construction process of the operator ![]() and a proof of cor- rection of the algorithm proposed for its implementation. The Section 4 is de- voted to the conclusion. In the appendices, we fully unfold the example intro- duced in Section 3 highlighting the major concepts outlined in this paper (Appendix A), as well as some screenshots of an asynchronous cooperative editor prototype operating in a distributed environment that we have developed for the experimental purposes of the algorithms described in this paper (Appendix B).
and a proof of cor- rection of the algorithm proposed for its implementation. The Section 4 is de- voted to the conclusion. In the appendices, we fully unfold the example intro- duced in Section 3 highlighting the major concepts outlined in this paper (Appendix A), as well as some screenshots of an asynchronous cooperative editor prototype operating in a distributed environment that we have developed for the experimental purposes of the algorithms described in this paper (Appendix B).
![]()
Figure 3. An intentional representation of a docu- ment containing buds.
2. Structured Cooperative Edition and Notion of Partial Replication
2.1. Structured Document, Edition and Conformity
In the XML6 community, the document model is typically specified using a
Document Type Definition (DTD) or a XML Schema [1] . It is shown that these DTD are equivalent to (regular) grammars with special characteristics called XML grammars [10] . The (context free) grammars are therefore a generalization of the DTD and on the basis of the studies they have undergone, mainly as formal models for the specification of programming languages, they provide an ideal framework for formal study of the transformations involved in XML technologies. That’s why we use them in our work as tools for specifying the structure of documents.
For certain treatments on trees (documents) it is necessary to designate precisely a particular node. Several indexing techniques exist, among them, the so-called Dynamic Level Numbering [11] based on identifiers with variable lengths inspired by the Dewey decimal classification (see Figure 4). According to this indexing system, a tree can be defined as follows:
Definition 2. A tree whose nodes are labelled in an alphabet ![]() is a partial map
is a partial map ![]() whose domain
whose domain ![]() is a prefix closed set such that, for all
is a prefix closed set such that, for all ![]() the set
the set ![]() is a not empty interval of integers
is a not empty interval of integers ![]() (
(![]() is the root label); the integer n is the arity of the node whose address is u.
is the root label); the integer n is the arity of the node whose address is u. ![]() is the value (label) of the node in t whose address is w. If
is the value (label) of the node in t whose address is w. If ![]() are trees and
are trees and![]() , we denote
, we denote ![]() the tree t of domain
the tree t of domain ![]() with
with ![]() and
and![]() .
.
Let t be a document and ![]() a grammar. t is a derivation tree for
a grammar. t is a derivation tree for
![]() if its root node is labelled by the axiom A of
if its root node is labelled by the axiom A of![]() , and if for all internal node
, and if for all internal node ![]() labelled by the sort
labelled by the sort![]() , and whose sons
, and whose sons![]() , are respectively labelled by the sorts
, are respectively labelled by the sorts![]() , there is one production
, there is one production ![]() such that,
such that, ![]() and
and![]() . It is also said in this case that t belongs to the language generated by
. It is also said in this case that t belongs to the language generated by ![]() from the symbol A and it is denoted
from the symbol A and it is denoted ![]() or
or![]() .
.
AST are used to show that a given tree labelled with grammatical symbols is an instance of a given grammar.
A structured document being edited is represented by a tree containing buds (or open nodes) which indicate in a tree, the only places where editions (i.e.
updates) are possible7. Buds are typed; a bud of sort X is a leaf node labelled by![]() : it can only be edited (i.e extended to a sub-tree) by using a X-production of the form
: it can only be edited (i.e extended to a sub-tree) by using a X-production of the form ![]() which have as effect, 1) the replacement of
which have as effect, 1) the replacement of ![]() labelled bud by a P labelled node and, 2) the creation of n buds labelled respectively by
labelled bud by a P labelled node and, 2) the creation of n buds labelled respectively by![]() . Thus, a structured document being edited and that have the grammar
. Thus, a structured document being edited and that have the grammar ![]() as model, is a derivation tree for the extended grammar
as model, is a derivation tree for the extended grammar ![]() obtained from
obtained from ![]() as follows: for all sort X, we not only add in the set
as follows: for all sort X, we not only add in the set ![]() of sorts a new sort
of sorts a new sort![]() , but we also add a new e-production
, but we also add a new e-production ![]() in the set
in the set ![]() of productions; so we have:
of productions; so we have: ![]() and
and![]() .
.
When we look at the productions of a grammar, we can notice that each sort is associated with a set of productions. From this point of view, therefore, we can consider a grammar as an application
![]() (1)
(1)
which associates to each sort a list of pairs formed by a production name and the list of sorts in the right hand side of this production. Such an observation suggests that a grammar can be interpreted as a (descending) tree automaton that can be used for recognition or for the generation of its instances.
Definition 4. A (descending) tree automaton defined on ![]() is a quadruplet
is a quadruplet ![]() of a set
of a set ![]() of symbols; its elements are the labels of the nodes of the trees to be generated (or recognized), a set Q of states, a particular state
of symbols; its elements are the labels of the nodes of the trees to be generated (or recognized), a set Q of states, a particular state ![]() called initial state, and a finite set
called initial state, and a finite set ![]() of transitions.
of transitions.
・ An element of R is denoted ![]() or in an equivalent way
or in an equivalent way![]() : intuitively,
: intuitively, ![]() is the list of states accessible from the q state by crossing a transition labelled
is the list of states accessible from the q state by crossing a transition labelled![]() .
.
・ If ![]() denotes the set of transitions associated to the state q, we denote
denotes the set of transitions associated to the state q, we denote
![]() the list that consists of pairs
the list that consists of pairs![]() . A transition of the form
. A transition of the form ![]() is called final tran- sition and a state possessing this transition is a final state.
is called final tran- sition and a state possessing this transition is a final state.
One can interpret a grammar ![]() as a (descending) tree auto- maton [13]
as a (descending) tree auto- maton [13] ![]() considering that: 1)
considering that: 1) ![]() is the type of labels of the nodes forming the tree to recognize. 2)
is the type of labels of the nodes forming the tree to recognize. 2) ![]() is the type of states and, 3)
is the type of states and, 3) ![]() is a transition of the automaton when the pair
is a transition of the automaton when the pair ![]() appears in the list
appears in the list ![]() 8. We note
8. We note ![]() the tree auto- maton derived from
the tree auto- maton derived from![]() .
.
To obtain the set ![]() of AST generated by a tree automaton
of AST generated by a tree automaton ![]() from an initial state
from an initial state![]() , you must: 1) Create a root node r, associate the initial state
, you must: 1) Create a root node r, associate the initial state ![]() and add it to the set
and add it to the set ![]() initially empty. 2) Remove from
initially empty. 2) Remove from ![]() an AST t under construction i.e with at least one leaf node
an AST t under construction i.e with at least one leaf node ![]() unlabelled. Let q be the state associated to
unlabelled. Let q be the state associated to![]() . For all transition
. For all transition ![]() of
of![]() , add in
, add in ![]() the trees
the trees ![]() which are replicas of t in which the node
which are replicas of t in which the node ![]() has been substituted by a node
has been substituted by a node ![]() labelled
labelled ![]() and possessing n (unlabelled) sons, each associated to a (distinct) state
and possessing n (unlabelled) sons, each associated to a (distinct) state ![]() of
of![]() . 3) Iterate step (2) until you obtain trees with all the leaf nodes labelled (they are consequently associated to the final states of
. 3) Iterate step (2) until you obtain trees with all the leaf nodes labelled (they are consequently associated to the final states of![]() ): these are AST. We note
): these are AST. We note ![]() the fact that the tree automaton
the fact that the tree automaton ![]() accepts the tree t from the initial state q, and
accepts the tree t from the initial state q, and ![]() (tree language) the set of trees generated by the automaton
(tree language) the set of trees generated by the automaton ![]() from the initial state q. Thus,
from the initial state q. Thus,![]() .
.
As for automata on words, one can define a synchronous product on tree automata to obtain the automaton recognizing the intersection, the union, …, of regular tree languages [13] . We introduce below the definition of the synchronous product of k tree automata whose adaptation will be used in the next section for the derivation of the consensual automaton.
Definition 5. Synchronous product of k automata:
Let ![]() be k tree automata. The synchronous product of these k automata
be k tree automata. The synchronous product of these k automata ![]() denoted
denoted![]() , is the automaton
, is the automaton ![]() defined as follows: 1) Its states are vectors of states :
defined as follows: 1) Its states are vectors of states :![]() ; 2) Its initial state is the vector formed by the initial states of the different automata :
; 2) Its initial state is the vector formed by the initial states of the different automata :![]() ; 3) Its transitions are given by:
; 3) Its transitions are given by:
![]()
2.2. Notions of View, Projection, Reverse Projection and Merging
2.2.1. View, Associated Projection and Merging
The derivation tree giving the (global) representation of a structured document edited in a cooperative way makes visible the set of grammatical symbols of the grammar that participated in its construction. As we mentioned in Section 1 above, for reasons of confidentiality (accreditation degree), a co-author mani- pulating such a document will not necessarily have access to all of these gram- matical symbols; only a subset of them can be considered relevant for him: it is his view. A view ![]() is then a subset of grammatical symbols (
is then a subset of grammatical symbols (![]() ).
).
A partial replica of t according to the view![]() , is a partial copy of t obtained by deleting in t all the nodes labelled by symbols that are not in
, is a partial copy of t obtained by deleting in t all the nodes labelled by symbols that are not in![]() . Figure 5 shows a document t (center) and two partial replicas
. Figure 5 shows a document t (center) and two partial replicas ![]() (left) and
(left) and ![]() (right) obtained respectively by projections from the views
(right) obtained respectively by projections from the views ![]() and
and![]() .
.
Practically, a partial replica is obtained via a projection operation denoted![]() . We therefore denote
. We therefore denote ![]() the fact that
the fact that ![]() is a partial replica obtained by projection of t according to the view
is a partial replica obtained by projection of t according to the view![]() .
.
![]()
Figure 5. Example of projections made on a document and partial replicas obtained.
Let’s note ![]() the fact that the document
the fact that the document ![]() is an update of the document
is an update of the document![]() , i.e.
, i.e. ![]() is obtained from
is obtained from ![]() by replacing some of its buds by trees. In an asynchronous cooperative editing process, there are synchronization points9 in which one tries to merge all contributions
by replacing some of its buds by trees. In an asynchronous cooperative editing process, there are synchronization points9 in which one tries to merge all contributions ![]() of the various co- authors to obtain a single comprehensive document
of the various co- authors to obtain a single comprehensive document ![]() 10. A merging algorithm that does not incorporate conflict management and that relies on a solution to the reverse projection problem is given in [9] .
10. A merging algorithm that does not incorporate conflict management and that relies on a solution to the reverse projection problem is given in [9] .
2.2.2. Partial Replica and Reverse Projection (Expansion)
The reverse projection (also call the expansion) of an updated partial replica ![]() relatively to a given grammar
relatively to a given grammar![]() , is the set
, is the set ![]() of documents conform to
of documents conform to ![]() that admit
that admit ![]() as partial replica according to
as partial replica according to![]() :
: ![]() .
.
A solution to this problem using tree automata is given in [9] ; in that solution, productions of the grammar ![]() are used, to bind to a view
are used, to bind to a view ![]() a tree automaton
a tree automaton ![]() such as the trees he recognizes from an initial state built from
such as the trees he recognizes from an initial state built from ![]() are exactly those having this partial replica as projection according to the view
are exactly those having this partial replica as projection according to the view![]() :
:![]() . Practically, a state q of the automaton
. Practically, a state q of the automaton ![]() is a pair
is a pair ![]() where X is a grammatical symbol, ts is a forest (tree set), and Tag is a label that is either Open or Close and indicates whether the concerned state q can be used to generate a closed node or a bud. The states of
where X is a grammatical symbol, ts is a forest (tree set), and Tag is a label that is either Open or Close and indicates whether the concerned state q can be used to generate a closed node or a bud. The states of ![]() are typed: a state of the form
are typed: a state of the form ![]() is of type X. We also have a function named typeState which, when applied to a state returns its type11. A transition from one state q is of one of the forms
is of type X. We also have a function named typeState which, when applied to a state returns its type11. A transition from one state q is of one of the forms ![]() or
or ![]() . A transition of the form
. A transition of the form ![]() is used to generate AST of type X (i.e. those whose root is labelled by a X-production) admitting “ts” for projection ac- cording to the view
is used to generate AST of type X (i.e. those whose root is labelled by a X-production) admitting “ts” for projection ac- cording to the view ![]() if X does not belong to
if X does not belong to![]() , and “
, and “![]() ” otherwise. Similarly, a transition of the form
” otherwise. Similarly, a transition of the form ![]() is used to generate a single AST reduced to a bud of type X.
is used to generate a single AST reduced to a bud of type X.
The interested reader may consult [9] for a more detailed description of the process of associating a tree automaton with a view and Appendix A for an illustration.
3. Reconciliation by Consensus
3.1. Issue and Principle of the Solution of Reconciliation by Consensus
There are generally two distinct phases when synchronizing replicas of a document [14] : the updates detection phase which consists of recognizing the different replica nodes (locations) where updates have been made since the last synchronization, and the propagation phase which consists in combining the updates made on the various replicas to produce a new synchronized state (document) for each replica. In an asynchronous cooperative editing workflow of several partial replicas of a document, when you reach a synchronization point, you can end up with unmergeable replicas in their entirety as they contain
not compatible updates12 they must be reconciled. This can be done by ques- tioning (cancelling) some local editing actions in order to resolve conflicts and result in a coherent global version said of consensus.
Studies on reconciling a document versions are based on heuristics [15] insofar as there is no general solution to this problem. In our case, since all editing actions are reversible13 and it is easy to locate conflicts when trying to merge the partial replicas (see Section 3.2), we have a canonical method to eliminate conflicts: when merging, we replace any node (of the global document) whose replicas are in conflict by a bud. Thus, we prune at the nodes where a conflict appears, replacing the corresponding sub-tree with a bud of the ap- propriate type, indicating that this part of the document is not yet edited: the documents obtained are called consensus. These are the maximum prefixes without conflicts of the fusion of the documents resulting from the different expansions of the various updated partial replicas. For example, in Figure 8, the parts highlighted (blue backgrounds) in trees (f) and (g) are in conflict; they are replaced in the consensus tree (h) by a bud of type C (node labelled![]() ).
).
The problem of the consensual merging of ![]() updated partial replica whose global model is given by a grammar
updated partial replica whose global model is given by a grammar ![]() can therefore be stated as follows :
can therefore be stated as follows :
Problem of the consensual merging: Given k views ![]() and k partial replica
and k partial replica![]() , merge consensually the family
, merge consensually the family ![]() is to find the most large documents
is to find the most large documents ![]() conforming to
conforming to ![]() such that, for any document t con- forming to
such that, for any document t con- forming to ![]() and admitting
and admitting ![]() as projection according to the view
as projection according to the view![]() ,
, ![]() and t are eventually updates each for other. i.e. (formula 2):
and t are eventually updates each for other. i.e. (formula 2):
![]() 14(2)
14(2)
The solution that we propose to this problem stems from an instrumenta- lization of that proposed for the expansion (Section 2.2.2). Indeed, we use an associative and commutative operator noted ![]() to synchronize the tree auto- mata
to synchronize the tree auto- mata ![]() constructed to carry out the various expansions in order to generate the tree automaton of consensual merging. Noting
constructed to carry out the various expansions in order to generate the tree automaton of consensual merging. Noting ![]() this automaton, the documents of the consensus are the trees of the language generated by the automaton
this automaton, the documents of the consensus are the trees of the language generated by the automaton ![]() from an initial state built from the vector made of the initial
from an initial state built from the vector made of the initial
states of the automata![]() :
:![]() .
.
![]() is obtained by proceeding as follows: 1) For each view
is obtained by proceeding as follows: 1) For each view![]() , build the automaton
, build the automaton ![]() who will carry out the expansion of the partial replica
who will carry out the expansion of the partial replica ![]() as
as
previously indicated (Section 2.2.2):![]() . 2) Using the op-
. 2) Using the op-
erator![]() , compute the automaton generating the consensus language
, compute the automaton generating the consensus language
![]() .
.
3.2. Consensus Calculation
Before presenting the consensus calculation algorithm, let us specify using the concepts introduced in Section 2.1 the notion of (two) documents in conflict. Let ![]() be two trees (documents) with respectively
be two trees (documents) with respectively ![]() and
and ![]() their domains. We say that
their domains. We say that ![]() and
and ![]() admit a consensus, and we note
admit a consensus, and we note![]() , if theirs roots are of the same type15 i.e.
, if theirs roots are of the same type15 i.e.
![]() 16. It is then say that
16. It is then say that ![]() and
and ![]() are in conflict, and it is noted
are in conflict, and it is noted![]() , when they admit a consensus but are not mergeable in their entirety. Intuitively, two documents
, when they admit a consensus but are not mergeable in their entirety. Intuitively, two documents ![]() and
and ![]() (not reduced to buds) are not fully mergeable (see Figure 6), if there exists an address
(not reduced to buds) are not fully mergeable (see Figure 6), if there exists an address ![]() such that if we note
such that if we note ![]() (resp.
(resp.![]() ) the node located to address w in
) the node located to address w in ![]() (resp. in
(resp. in![]() ), then,
), then, ![]() and
and ![]() which are not buds are of the same type but have different labels. i.e. (formula 3):
which are not buds are of the same type but have different labels. i.e. (formula 3):
![]()
Figure 6. Example of documents in conflict.
![]() (3)
(3)
Figure 6 shows two conflicting documents. In fact, at address 2.1 we have two nodes of the same type (“C”) but edited with different C-productions: pro- duction ![]() in the first document, and production
in the first document, and production ![]() in the second one.
in the second one.
3.2.1. Consensus among Multiple (Two) Documents
Let ![]() be two trees (documents) in conflict with respectively
be two trees (documents) in conflict with respectively ![]() and
and ![]() their domains. The consensual tree
their domains. The consensual tree ![]() de- rived from
de- rived from ![]() and
and ![]() (
(![]() ) has as domain the union of domains of the two trees in which we subtract elements belonging to domains of sub-trees derived from the conflicting nodes. In fact, we prune at the nodes in conflict and they appear in the consensus tree as a (unique) bud. So,
) has as domain the union of domains of the two trees in which we subtract elements belonging to domains of sub-trees derived from the conflicting nodes. In fact, we prune at the nodes in conflict and they appear in the consensus tree as a (unique) bud. So,
![]() (4)
(4)
Figure 7 present the document resulting from the consensual merging of the
![]()
Figure 7. Document resulting from the consensual merging of the documents in Figure 6.
documents in Figure 6. We have prume at the level of nodes 2.1 in both do- cuments who are in conflict.
When![]() , there may be nodes of
, there may be nodes of ![]() and those of
and those of ![]() which are updates of the nodes of
which are updates of the nodes of![]() : it is said in this case that
: it is said in this case that ![]() (resp.
(resp.![]() ) and
) and ![]() are updates each for other.
are updates each for other.
Definition 6. Let ![]() be two documents that are not in conflict. It will be said that they are updates each for other and it is noted
be two documents that are not in conflict. It will be said that they are updates each for other and it is noted![]() , if there exists at least two addresses
, if there exists at least two addresses ![]() of their respective domains such that
of their respective domains such that ![]() (resp.
(resp.![]() ) is a bud and
) is a bud and ![]() (resp.
(resp.![]() ) is not.
) is not.
3.2.2. Construction of Consensus Automaton
Consideration of documents with buds requires the readjustment of some models. For example, in the following, we will handle the tree automata with exit states instead of tree automata introduced in definition 4. Intuitively, a state q of an automaton is called an exit state if there is a unique transition ![]() associated to it for generating a tree reduced to a bud of type
associated to it for generating a tree reduced to a bud of type![]() : q is then of the form (Open X, []).
: q is then of the form (Open X, []).
A tree automata with exit states ![]() is a quintuplet
is a quintuplet ![]() where
where ![]() designate the same objects as those introduced in the definition 4, and
designate the same objects as those introduced in the definition 4, and ![]() is a predicate defined on the states (
is a predicate defined on the states (![]() ). Any state q of Q for which
). Any state q of Q for which ![]() is
is ![]() is an exit state.
is an exit state.
A type for automata with exit states can be defined in Haskell [16] [17] by:
![]()
In Section 3.2.1 above, we said that, when two nodes are in conflict, “they appear in the consensus tree as a (unique) bud”. From the point of view of automata synchronization, the concept of “nodes in conflict” is the counterpart of the concept of “states in conflict” (as we specify below) and the above extract is reflected in the automata context by “when two state are in conflict, they appear in the consensus automaton in the form of a (single) exit state”. Thus, if we consider two states of the same type ![]() and
and ![]() (which are not exit states) of two automata
(which are not exit states) of two automata ![]() and
and ![]() with associated transitions families re- spectively
with associated transitions families re- spectively ![]() and
and![]() , we say that the states
, we say that the states ![]() and
and ![]() are in conflict (and we note
are in conflict (and we note![]() ) if there is no transition starting from each of them and with the same label, i.e.
) if there is no transition starting from each of them and with the same label, i.e.
![]()
This can be coded in Haskell by the following function:
![]()
If X is the type of two states q and ![]() in conflict, they admit a single con- sensual state
in conflict, they admit a single con- sensual state ![]() such as
such as![]() . It is therefore obvious that two given automata admit a consensual automaton when their initials states are of the same type. The following function performs this test.
. It is therefore obvious that two given automata admit a consensual automaton when their initials states are of the same type. The following function performs this test.
![]()
The operator ![]() used to calculate the synchronized consensual automaton
used to calculate the synchronized consensual automaton ![]() is a relaxation of the operator used for calculating the automata product presented in the definition 5.
is a relaxation of the operator used for calculating the automata product presented in the definition 5. ![]() is an auto- maton with exit states and is constructed as follows:
is an auto- maton with exit states and is constructed as follows:
・ Its states are vectors of states :![]() ;
;
・ its initial state is formed by the vector of initial states of different automata:![]() ;
;
・ For the exit function , it is considered that when a given automaton ![]() reached an exit state17, it no longer contributes to behavior, but is not opposed to the synchronization of the others automata: it is said “asleep” (see listing “Consensus Listing” below, lines 16, 18 and 23). So, a state
reached an exit state17, it no longer contributes to behavior, but is not opposed to the synchronization of the others automata: it is said “asleep” (see listing “Consensus Listing” below, lines 16, 18 and 23). So, a state ![]() is an exit state if: (a) all composite states
is an exit state if: (a) all composite states ![]() are asleep (see listing “Consensus Listing” below, line 5) or (b) there exist any two states
are asleep (see listing “Consensus Listing” below, line 5) or (b) there exist any two states ![]() and
and![]() , components of q that are in conflict (see listing “Consensus Listing” below, line 11)
, components of q that are in conflict (see listing “Consensus Listing” below, line 11)
![]()
・ Its transitions are given by:
a) If ![]() then
then ![]() is the unique transition of q; X is the type of q.
is the unique transition of q; X is the type of q.
b) Else ![]()
b1) ![]() and
and ![]() /*
/*![]() is asleep*/, else
is asleep*/, else
b2)![]() .
.
a) reflects the fact that if a state q is an exit one, we associate a single transition for generating a tree reduced to a bud of the type of q (see listing “Consensus Listing” below, line 11).
With (b1) we say that, if the component ![]() of q is an exit state, then for all composite state
of q is an exit state, then for all composite state![]() , (
, (![]() ) appearing in the right hand side in the transition (b), the ith component should be asleep. Since it must not prevent other non-asleep states to synchronize, it must be of the form
) appearing in the right hand side in the transition (b), the ith component should be asleep. Since it must not prevent other non-asleep states to synchronize, it must be of the form ![]() where X is the type of the other states
where X is the type of the other states ![]() (being yet synchronized) belonging to
(being yet synchronized) belonging to ![]() (see function forward Sleep State defined in listing “Consensus Listing” below line 23 and used in lines 16 and 18). Finally, with (b2) we stipulate that if
(see function forward Sleep State defined in listing “Consensus Listing” below line 23 and used in lines 16 and 18). Finally, with (b2) we stipulate that if ![]() is a transition of the automaton
is a transition of the automaton![]() , then for all composite state
, then for all composite state![]() , (
, (![]() ) appearing in the right part in the transition (b) above, the ith component is
) appearing in the right part in the transition (b) above, the ith component is ![]() (see listing “Con- sensus Listing” below, lines 12 to 15).
(see listing “Con- sensus Listing” below, lines 12 to 15).
Consensus Listing
![]()
Proposition 7. The tree automaton ![]() recognizes/generates from the initial state
recognizes/generates from the initial state ![]() all the trees from the consensual merging of trees recognized/generated by each automaton
all the trees from the consensual merging of trees recognized/generated by each automaton ![]() from the initial state
from the initial state![]() . Moreover, these trees are the biggest prefixes without conflicts of merged trees.
. Moreover, these trees are the biggest prefixes without conflicts of merged trees.
![]() (5)
(5)
Proof. A tree t is recognized by the synchronized automaton ![]() if, and only if, one can label each of its nodes by a state of the automaton in accordance with what is specified by the transitions of the automaton. Moreover, all the leaf nodes of t must be labelled by using final transitions; in our case, they are of the form
if, and only if, one can label each of its nodes by a state of the automaton in accordance with what is specified by the transitions of the automaton. Moreover, all the leaf nodes of t must be labelled by using final transitions; in our case, they are of the form![]() . This means that if a node whose initial label is a is labelled by the state q and if it admits n successors respectively labelled by
. This means that if a node whose initial label is a is labelled by the state q and if it admits n successors respectively labelled by![]() , then
, then ![]() must be a transition of the automaton. As the automaton is deterministic18 this labelling is unique elsewhere (including the initial state attached to the root of the tree). By focusing our attention both on the state q labelling a node and its ith component
must be a transition of the automaton. As the automaton is deterministic18 this labelling is unique elsewhere (including the initial state attached to the root of the tree). By focusing our attention both on the state q labelling a node and its ith component![]() , on each of the branches of t, 1) we cut as soon as we reach an exit state in relation to the automaton
, on each of the branches of t, 1) we cut as soon as we reach an exit state in relation to the automaton ![]() (i.e.
(i.e. ![]() is an exit state), or, 2) if q is an exit state (in this case we are handling a leaf) and
is an exit state), or, 2) if q is an exit state (in this case we are handling a leaf) and ![]() is not, relative to
is not, relative to ![]() (in this case,
(in this case, ![]() was in conflict with at least one other component
was in conflict with at least one other component ![]() of q); we replace that node with any sub-tree
of q); we replace that node with any sub-tree ![]() that can be generated by
that can be generated by ![]() from the state
from the state![]() . So,
. So,
![]() (6)
(6)
since a state of ![]() is an exit one if and only if each of its components is (in the
is an exit one if and only if each of its components is (in the![]() ) or if at least two of its components are in conflict.
) or if at least two of its components are in conflict.
Conversely, suppose![]() , by definition of the synchronized con- sensual automaton, we have
, by definition of the synchronized con- sensual automaton, we have![]() . So overall
. So overall
![]() (7)
(7)
Suppose that t is recognized by![]() ; thus there is a labelling of its nodes with the states of
; thus there is a labelling of its nodes with the states of ![]() and as the transitions used for the labelling of its leaves are final. Let
and as the transitions used for the labelling of its leaves are final. Let ![]() be a prefix of t. Let us show that
be a prefix of t. Let us show that ![]() is not recognized by
is not recognized by ![]() using the fact that any labelling of
using the fact that any labelling of ![]() has at least one leaf node labelled by a state that is not associated to a final transition. The labels associated to the nodes of
has at least one leaf node labelled by a state that is not associated to a final transition. The labels associated to the nodes of ![]() are the same as those associated to the nodes of same addresses in t because
are the same as those associated to the nodes of same addresses in t because ![]() is a prefix of t and
is a prefix of t and ![]() is deterministic.
is deterministic. ![]() is obtained from t by pruning some sub-trees of t; so naturally he has a (non-zero) number of leaf nodes that can be developed to obtain t. Let us choose a such node and call it
is obtained from t by pruning some sub-trees of t; so naturally he has a (non-zero) number of leaf nodes that can be developed to obtain t. Let us choose a such node and call it![]() . Suppose that it is labelled p and was associated with a state
. Suppose that it is labelled p and was associated with a state ![]() when labelling t. The p_transition that permit to recognize
when labelling t. The p_transition that permit to recognize ![]() is not a final transition. Indeed,
is not a final transition. Indeed, ![]() has in t
has in t ![]() sons whose labels can be suppose to be the states
sons whose labels can be suppose to be the states![]() . This means according to the labelling process and considering the fact that
. This means according to the labelling process and considering the fact that ![]() is deterministic, that the single transition used for labelling
is deterministic, that the single transition used for labelling ![]() and of its
and of its ![]() sons is
sons is ![]() which is not a final transition. Therefore,
which is not a final transition. Therefore, ![]() is not recognized by
is not recognized by![]() . □
. □
3.3. Illustration
Figure 8 is an illustration of an asynchronous cooperative editing process generating partial replicas (Figure 8(c) and Figure 8(e)) in conflict19 from the grammar having as productions:
![]() (8)
(8)
Initially in the process, two partial replicas (Figure 8(b) and Figure 8(d)) are obtained by projections of the global document (Figure 8(a)). After their update (Figure 8(c) and Figure 8(e)) a synchronization point is reached and, by applying the approach described in Section 3.1 i.e, association of tree automata ![]() and
and ![]() respectively to the partial replicas
respectively to the partial replicas ![]() and
and![]() , their con- sensual synchronization in the automaton
, their con- sensual synchronization in the automaton![]() , and finally,
, and finally,
![]()
Figure 8. An edition with conflicts and corresponding consensus.
generation of consensus trees (Figure 8(h)). Remember that this example is fully unfold in Appendix A: therein, we present the different manipulated automata and a set of the simplest consensus documents (Figure 9).
4. Conclusions
We presented in this paper a reconciliation approach said by consensus, of partial replicas of a document submitted to an asynchronous cooperative editing process: so we opted for a partial optimistic replication approach [12] . The approach proposed is based on a relaxation of the synchronous product of auto- mata to construct an automaton capable of generating consensus documents.
The approach proposed in this paper is supported by mathematical proofs of the proposals. The presented algorithms have been implemented in Haskell [16] and experienced in many examples (including the one introduced in Section 3.3 and fully unfold in Appendix A) with convincing results. These algorithms can be also experienced in a truly distributed environment via the graphical editor prototype that we have built for this need; some screenshots are provided in Appendix B.
The deployment and use of this prototype will probably be better off if one incorporates a publishing environment generator which, from a specification of an asynchronous cooperative editing process describing in a DSL (Domain Specific Language) [19] , the model of licit documents (grammar), various co- authors, their publishing sites and views, etc., will generate for each co-author her dedicated publishing environment including, for example, among others: a dedicated editor with conventional facilities of currents editors (syntax high- lighting, code completion, etc.), tools for asking synchronizations, tools for back- up and restoration of partial replicas being edited etc.
Appendix A. An Illustration of the Merging Algorithm
We illustrate the consensual merging algorithm with the grammar of Section 3.3 (formula 8). We associate the automata ![]() and
and ![]() respectively to the updated partial replicas
respectively to the updated partial replicas ![]() and
and ![]() (Figure 8(c) and Figure 8(e)), then we build the automaton of consensus
(Figure 8(c) and Figure 8(e)), then we build the automaton of consensus ![]() by applying the ap- proach described in Section 3.2.2 and finally, present the simplest documents of consensus (Figure 9).
by applying the ap- proach described in Section 3.2.2 and finally, present the simplest documents of consensus (Figure 9).
Linearization of a Structured Document
To simplify the presentation, we represent in the following, trees by their linearization in the form of a Dyck word. To do this, we associate a (various) pair of brackets to each grammatical symbol and the linearization of a tree is obtained by performing a Depth First Search (DFS) of the resulting tree.
The Transition Schemas for the View {A, B}
A list of trees (forest) is represented by the concatenation of their lineari- zations.We use the opening parenthesis “(‘and the closing one’)” to represent Dyck symbols associated with the visible symbol A and the opening bracket “[” and closing “]” to represent those associated with the visible symbol B. Each transition of the automata associated to partial replicas according to the view ![]() is conform to one of the following transition schema20
is conform to one of the following transition schema20
![]() (9)
(9)
![]()
Figure 9. Consensual trees generated from the automaton![]() .
.
Construction of the Automaton ![]() Associated to tv1
Associated to tv1
Having associated Dyck symbols “(‘and’)” (resp. “[‘and’]”) to the grammatical symbol A (resp. B), the linearization of the partial replica ![]() (Figure 8(c)) gives
(Figure 8(c)) gives![]() . As A is the axiom of the grammar, the initial state of the automaton
. As A is the axiom of the grammar, the initial state of the automaton ![]() is
is![]() . When considering only the states accessible from
. When considering only the states accessible from ![]() and by applying the previous schema of transition, we obtain the following automaton (Table 1) for the replica
and by applying the previous schema of transition, we obtain the following automaton (Table 1) for the replica ![]() (Figure 8(c)).
(Figure 8(c)).
The state ![]() in Table 1 is the only exit state of
in Table 1 is the only exit state of![]() . It is easy to verify that the document of Figure 8(f) resulting from the reverse projection of
. It is easy to verify that the document of Figure 8(f) resulting from the reverse projection of ![]() belongs to the language accepted by the automaton
belongs to the language accepted by the automaton![]() .
.
Construction of the Automaton ![]() Associated to tv2
Associated to tv2
As before, by associating to the grammatical symbol C (resp. A) the Dyck symbols “[‘and’]” (resp. “(‘and’)”), we obtain the transition schemas (formula 10) for the automata associated to the partial replicas according to the view![]() .
.
![]() (10)
(10)
The linearization of the partial replica ![]() (Figure 8(e)) is
(Figure 8(e)) is
![]() . The automaton
. The automaton ![]() associates to this replica has as
associates to this replica has as
![]()
Table 1. Automaton accepting updates of the (partial) replica tv1.
initial state ![]() and its transitions are given in Table 2.
and its transitions are given in Table 2.
Let’s note that, the state ![]() is the only exit state of the automaton
is the only exit state of the automaton![]() .
.
Construction of the Consensus Automaton ![]()
By application of synchronous product of several tree automata described in Section 3.2.2 to the automata ![]() and
and![]() , the consensual automaton
, the consensual automaton ![]() has
has ![]() as initial state.
as initial state. ![]() has a transition from
has a transition from ![]() to
to ![]() labelled
labelled![]() . Similarly,
. Similarly, ![]() has a transition from
has a transition from ![]() to
to ![]() labelled
labelled![]() . So we have in
. So we have in ![]() a transition labelled
a transition labelled ![]() for accessing states
for accessing states ![]() from the initial state
from the initial state![]() . Following this principle, we construct the following consensual automaton (Table 3).
. Following this principle, we construct the following consensual automaton (Table 3).
The states ![]() are the exit states of the auto- maton
are the exit states of the auto- maton![]() . They are states whose composite states are either in conflict (for example
. They are states whose composite states are either in conflict (for example ![]() et
et![]() ), or are all exit states (for example
), or are all exit states (for example ![]() ).
).
The use of function that generates the simplest AST (with buds) of a tree language from its automaton [9] on![]() , produced four AST whose derivation trees (the consensus) are shown schematically in Figure 9.
, produced four AST whose derivation trees (the consensus) are shown schematically in Figure 9.
Appendix B. A Prototype of a Cooperative Editor Using Our Algorithms
![]()
Table 2. Automaton accepting updates of the (partial) replica tv2.
cuments using our algorithms for consensus merging of edited partial replicas.
This prototype is used following a networked client-server model. Its user interface offers to the user facilities for creating workflows: grammars, actors and views, initial document, … (Figure 10), editing and validation of partial replicas, connecting to a local or remote workflow (Figure 11). Moreover, this interface also offers him functionality to experience the concepts of projection, expansion and consensual merging (Figure 12). This prototype is designed using Java and Haskell languages.
![]()
Figure 10. Some prototype screenshots showing windows for the creation of a cooperative editing workflow.
![]()
Figure 11. Some prototype screenshots showing the authentication window of a co-author (Auteur1) as well as those displaying the different workflows, local and remote in which he is implicated.
![]()
Figure 12. An illustration of the consensual merging in the prototype.
![]()
Submit or recommend next manuscript to SCIRP and we will provide best service for you:
Accepting pre-submission inquiries through Email, Facebook, LinkedIn, Twitter, etc.
A wide selection of journals (inclusive of 9 subjects, more than 200 journals)
Providing 24-hour high-quality service
User-friendly online submission system
Fair and swift peer-review system
Efficient typesetting and proofreading procedure
Display of the result of downloads and visits, as well as the number of cited articles
Maximum dissemination of your research work
Submit your manuscript at: http://papersubmission.scirp.org/
Or contact jsea@scirp.org
NOTES
1A sort is a datum used to define the structuring rules (syntax) in a document model. Example: a non-terminal symbol in a context free grammar, an ELEMENT in a DTD.
2We designate by global document or simply document when there is no ambiguity, the document including all parts.
3Intuitively, a local model of document is coherent towards a global model if any (partial) document ti that is conform to it, is the partial replica of at least one (global) document t conform to the global model.
4Manipulated documents are structured; they can be intentionally represented by a tree. Intuitively, a node is an identifiable part in the document (a section, a subsection, an image, a table, …): it is the instance of a sort.
5A bud is a leaf node of a tree indicating that an edition must be done at that level in the tree. Edit a bud consists to replace it by a sub-tree using the productions of the grammar of the document.
6XML is the acronym for Extensible Markup Language.
7We are interested in this paper only in the positive edition, based on a partial optimistic replication [12] of edited documents; In fact, the published documents are only increasing: there is no erasure possible as soon as a synchronization has been performed.
9A synchronization point can be defined statically or triggered by a co-author as soon as certain properties are satisfied.
10It may happen that the edition must be continued after the merging (this is the case if there are still buds in the merged document): we must redistribute to each of the n co-authors a (partial) replica ![]() of
of ![]() such that
such that ![]() for the continuation of the editing process.
for the continuation of the editing process.
11![]()
![]()
![]()
12This is particularly the case if there is at least one node of the global document accessible by more than one co-author and edited by at least two of them using different productions.
13Reminder: the editing actions made on a partial replica may be cancelled as long as they do not have been incorporated into the global document.
14The binary relation ![]() when it exists between two trees t1 and t2 expresses the fact that they are possibly updates each for other. This relationship is more explicitly explained in definition 6.
when it exists between two trees t1 and t2 expresses the fact that they are possibly updates each for other. This relationship is more explicitly explained in definition 6.
15Trees we handle are AST and therefore, the nodes are labelled by productions names. Any node labelled by a X-production is said of type X. Furthermore, there is a function type Node such that type Node (t(w)) returns the type of the node located at the address w in t.
16It may then be noted that two documents (AST) admit no consensus if their roots are of different types. However, for applications that interest us, namely structured editing, since the editions are done from the root (which is always of the type of the axiom) to the leaves using productions, the documents we manipulate always admit at least a consensus.
17The corresponding node in the reverse projection of the document is a bud and reflects the fact that the corresponding author did not publish it. In the case that this node is shared with another co-author who published it in its (partial) replica, it is the edition made by the latter that will be retained when merging.
18Automata ![]() being deterministic (see proposition 3.3.3 of [18] ),
being deterministic (see proposition 3.3.3 of [18] ), ![]() is deterministic as synchronous product of deterministic automata.
is deterministic as synchronous product of deterministic automata.
19By realising expansions of each of the replicas, we respectively obtain among others, the documents presented by Figure 8(f) and Figure 8(g) on which one can easily observe a conflict highlighted by areas having a blue background.
20We do not represent the whole set of transition schemas in this example; only the useful subset for reconciliation of closed documents is shown here because the documents to reconcile in this example are all closed (has no buds). To consider buds, one should, for each visible sort X, associate a new pair of Dyck symbols to the bud of type X then, derive the new schemas.