1. Introduction
In collaborative chatting between users, emotions are an important aspect. The detection of the exchange of emotions among users through text messages can help for delivering right emotion in the right time. Several researches used text- based emotion to predict and classify the emotion types, such as [1] [2] [3] and [4] . Jraidi et al. [5] show the impact of using emotion in intelligent system and show how these emotions oriented toward developing emotionally sensitive tutors.
Appraisal is a linguistic theory that tries to model language’s capability to definite opinions and attitudes within text [7] . The appraisal method contains three distinct aspects: Attitude, Engagement, and Graduation. In this paper, we adopt attitudes in its classification. Attitudes are separated into three categories: Affect, Judgment, and Appreciation. Attitude is defined as a mode that anyone acts in a specific condition and shows how he feels [8] . These aspects embody the capability to express emotional, moral, and aesthetic feelings respectively [9] . For example, “when I was in grade 11 in the school, I was punished for no serious mistake of mine” another sentence “when I was in grade 11 in the school, I got an award for my excellence”. Using the dominant meaning methods, the words “punish, and mistake” lead the first sentences to a negative emotion, however, the words “award and excellence” classify the second sentences to a positive emotion.
Detecting emotion from text is useful in understanding users’ feelings towards particular discussion in intelligent learning system. To test our algorithm, we use ISEAR (International Survey on Emotion Antecedents and Reactions), dataset collected by Klaus R. Scherer and Harald Wallbott [9] . ISEAR dataset contains seven major emotions: joy, fear, anger, sadness, disgust, shame, and guilt. The process to classify sentences in this work involves two main steps: representing 40% of dataset to allow learning, extract features based on appraisal method, create dominant meaning hierarchy, train a classifier on prepared examples, and then using the classifier to predict a category.
The remainder of this paper is organized as follows. Section 2 presents the methodology to detect the emotion and how to construct dominant meaning tree. Section 3 describes experiments and discusses the results. Finally, Section 4 summarizes the conclusion.
2. Emotion Detection Methodology
The architecture of the proposed system contains two stages: training stage, and classification stage. The training stage happens on the server side. We apply the dominant meaning methods [6] on the ISEAR dataset [9] to form the hierarchy tree. Based on the ISEAR, the tree consists of seven concepts: joy, fear, anger, sadness, disgust, shame, and guilt.
The classifier unit receives two types of information. A hierarchy tree for dominant meaning for seven classes and ISEAR examples. The classifier in general uses a large amount of labeled training data for text classification, which is a labor-intensive and time-consuming task. In contrast, our approach is to construct the dominant meaning tree and then use this tree to classify incoming examples from Emotion Models unit. This unit contains two types of set of words. First, set coming from Emotion Agent, which extract some features from Chatting GUI unit during the chatting between users, remove stop words, and reformulate in the way Emotion unit can deal with it. Stop words are those that occur commonly but are too general―such as “the”, “an”, “a”, “to”, etc. The algorithm removed the stop words from the collection. Emotion agent use Emotion Algorithm to assign an emotion for each set of features based on the emotion models coming from emotion models unit. After determining the emotion, Emotion Expression assigns a suitable expression for it and sends it to be shown in the Chatting GUI (see Figure 1).
2.1. Constructing Emotion Dominant Meaning Tree
To represent the proposed approach to classify sentiment, suppose that the collection consists of 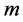 emotion, i.e.
emotion, i.e.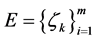 . Given the limited set of examples for each emotion, we try to represent the collection as a hierarchy of dominant meanings.
. Given the limited set of examples for each emotion, we try to represent the collection as a hierarchy of dominant meanings.
In this definition, each emotion is represented by a finite set of examples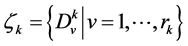 . The question now is how can we use those examples to construct dominant meanings of the corresponding emotion? In other words, those examples include some words that almost come with the corresponding emotion. The challenge is how to determine those words.
. The question now is how can we use those examples to construct dominant meanings of the corresponding emotion? In other words, those examples include some words that almost come with the corresponding emotion. The challenge is how to determine those words.
Each example is represented by a fixed set of words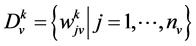 .
.
![]()
Figure 1. Architecture of the emotion detection system.
The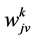 ’s represent the frequency of word
’s represent the frequency of word 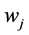 occurs in example
occurs in example 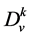 which belongs to emotion
which belongs to emotion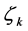 . This frequency is computed as the number of times that the
. This frequency is computed as the number of times that the 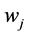 occurs in the
occurs in the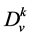 .
.
Our goal is to choose the top-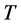 words, which can represent the dominant meanings of emotion
words, which can represent the dominant meanings of emotion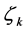 . To do that, we proceed as follows. Suppose that word
. To do that, we proceed as follows. Suppose that word 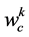 symbolizes emotion
symbolizes emotion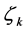 .
.
・ Calculate the values of
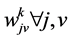 . (1)
. (1)
・ Suppose that 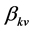 is the frequency of emotion
is the frequency of emotion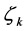 , which appears in example
, which appears in example![]() , where
, where ![]()
・ Calculate the maximum value of![]() ,
,
![]() . (2)
. (2)
・ Calculate the maximum value of![]() ,
,
![]() (3)
(3)
where ![]()
・ Choose![]() , which satisfies
, which satisfies ![]()
・ Finally, consider the dominant meaning probability
・ ![]() . (4)
. (4)
Therefore, we divide ![]() by the maximum value
by the maximum value ![]() of the frequency of
of the frequency of![]() , and then we normalize the results by dividing by the number of examples
, and then we normalize the results by dividing by the number of examples ![]() in collection
in collection![]() . Based on formula (3), we clearly have
. Based on formula (3), we clearly have![]() .
.
2.2. Constructing Emotion Dominant Meaning Models
The proposed system creates sevens models one for each emotion: joy, fear, anger, sadness, disgust, shame, and guilt.
For each emotion![]() , we have a collection of N examples
, we have a collection of N examples
![]() . For each collection, we apply the formula from (1) to (4).
. For each collection, we apply the formula from (1) to (4).
After applying formulas, we get a set of dominant meanings each word in the set has ![]() value for a word
value for a word ![]() and in emotion
and in emotion![]() .
.
We rank the terms of collection ![]() in decreasing order according to formula (4). As a result, the dominant meanings of the emotion
in decreasing order according to formula (4). As a result, the dominant meanings of the emotion ![]() can be represented by the set of words that is corresponds to the set
can be represented by the set of words that is corresponds to the set![]() ; i.e.
; i.e.![]() .
.
Therefore, we select the top-N values of ![]() to form motion dominant meaning tree (EDMT). EDMT represents seven emotions suggested by (Klaus, 1994) as a tree. Each emotion is joined with a slave word. This slave is represent a dominant meaning and associated with the dominant meaning probability of that emotion as shown in Figure 2. In this paper we put the top-N of
to form motion dominant meaning tree (EDMT). EDMT represents seven emotions suggested by (Klaus, 1994) as a tree. Each emotion is joined with a slave word. This slave is represent a dominant meaning and associated with the dominant meaning probability of that emotion as shown in Figure 2. In this paper we put the top-N of ![]() values as an arbitrary value.
values as an arbitrary value.
![]()
Figure 2. Emotion dominant meaning tree.
Accordingly, we can create seven models to represent the emotion. Each model is a set called emotion dominant meaning models![]() . Each
. Each ![]() contains the top-N dominant meaning probability:
contains the top-N dominant meaning probability:
![]() . (5)
. (5)
The corresponding word set of ![]() is represented as:
is represented as:![]() .
.
For a new example![]() ,
, ![]() represents a word in the new example. For each emotion, we compute the model value
represents a word in the new example. For each emotion, we compute the model value ![]() as flowing:
as flowing:
![]() (6)
(6)
where
![]() , for each
, for each ![]()
The emotion detection algorithm returns the emotion ![]() that represents a set of words
that represents a set of words![]() . The algorithm uses Equation (6) to compute the model value for each emotion for the example
. The algorithm uses Equation (6) to compute the model value for each emotion for the example![]() . Therefore, it calculates the highest value and then returns the index of this value. This index is used to determine the emotion.
. Therefore, it calculates the highest value and then returns the index of this value. This index is used to determine the emotion.
3. Experiments and Results
This section presents two purposes. First purpose is used to build Emotion Dominant Meaning Tree. The second purpose is to test the accuracy of using this tree for detecting the emotion.
3.1. Data Sets
The dataset uses ISEAR dataset [9] that contains emotional statements. ISEAR contains 7666 sentences (as shown in Table 1). The dataset is collected from 1096 participants with different cultural background who completed questionnaires about seven emotions: anger, disgust, fear, sadness, shame, joy, and guilt.
3.2. Building Emotion Dominant Meaning Tree
Most of text classification methods use keyword-based methods with thesaurus. In contrast, we use the dominant meaning methods as features to improve accuracy and refine the categories. To build the dominant meaning tree, we use 60% of ISEAR dataset for seven emotion categories (as shown in Table 2): anger,
![]()
Table 1. Characteristics of the ISEAR Dataset.
![]()
Table 2. Characteristics of dataset used to build tree.
disgust, fear, sadness, shame, joy, and guilt.
Stop words were removed in all examples for examples: for, an, the, a, an, another, but, or, yet, so, towards, before, etc.
Based on the Equation (1) to (5), we can build the dominant meaning tree of seven emotion categories, as shown in Figure 2.
Each node contains one emotion. Each emotion is associated with top-N dominant meaning words based. The node between word and the emotion is labeled with its dominant meaning probability as shown in Figure 2. To determine N value, we have to conduct some experimentations with different N values to figure out which N reflects a considerable results. The following subsection presents the accuracy of the proposed method to classify emotion examples.
3.3. Detecting Algorithm Accuracy
The goal of the experiments is to measure the accuracy of the proposed algorithm to predict a single emotional label given an input sentence. We follow Cohen’s Kappa [10] to measure the accuracies of the experiment. We use average precision, recall, and F-measure to measure the classification accuracy.
In this experiment, we use ISEAR dataset to figure out the performance of our proposed mechanism. We used a Java programing language to create a class file to implement Emotion Detection Algorithm. This program classified the tested data in one emotion. The results of precision and recall are shown in Figure 3.
The precision and recall of our proposed approach shows a considerable performance comparing to those in related works.
In his classification he found that using SVM produced better results for sadness (F1 = 0.733) which is better than our approach for sadness (F1 = 0.67). In contrast, our approach has better results in others classes such as anger (F1 = 0.66), disgust (F1 = 0.47), fear (F1 = 0.56), shame (F1 = 0.55), joy (F1 = 0.58), and guilt (F1 = 0.50). Where Balahur results were for anger (F1 = 0.38), disgust
![]()
Figure 3. Precision and recall for dominant meanings.
(F1 = 0.264), fear (F1 = 0.49), shame (F1 = 0.43), joy (F1 = 0.46), and guilt (F1 = 0.42).
Danisman and Alpkocak [11] used the ISEAR collection and used vector space models (VSM) to categorize 801 examples. Our approach showed a significant results anger (F1 = 0.38), joy (F1 = 0.46), and sadness (F1 = 0.67) compared to Danisman and Alpkocak (2008) for anger (F1 = 0.242), joy (F1 = 0.496) and sadness (F1 = 0.371).
On the other hand, in order to test the performance of our proposed approach with alternative methods for emotion detection, we chose the work done by Balahur et al. [12] , as shown in Table 3.
The results of 10-fold cross validation using Support vector machine to classify the whole set of 1081 examples initially chosen. We found that using dominant meaning classifier produced better results all categories than using the method of SVM in Balahur et al. [12] , as shown in Table 3, where our proposed method produced the most accurate results for Sadness class with Precision (27.2) and Recall (60.2). Using 10-fold cross validation with SVM (Balahur, 2011) produced also the most accurate results for sadness class with Precision (0.707) and Recall (0.77). However, our proposed method produces a lower value for precision for two classes “Anger” with (20.2) and “Shame” with (20.2), Balahur’s results produced a lower value for precision a class “Disgust” with 0.292.
Figure 4 shows F1 measure for the results of Dominant meaning approach and 10-fold cross validation using SVM [12] . As we see both our proposed approach and Balahur’s approach have a similar function for drawing F1 measure. We see that the top value for the graph for both approach recorded for “Sadness” class and the bottom value for the graph for both approach recorded for “Disgust” class.
4. Conclusion
Text-Based Emotion detection becomes an important research field with the massive chatting messages coming from social media systems. In this paper, we have proposed an approach to extract user’s emotion based on messages who posts. We used a dominant meaning approach, which looks for the meaning of the word rather than the word itself. To do that, we proposed an architecture for
![]()
Table 3. Characteristics of dataset used to build tree.
![]()
Figure 4. Comparison between the results of dominant meaning approach and 10-fold cross validation-using SVM (Balahur, 2011).
the proposed system to finish two tasks: training and classification. For training system, a hierarchy tree for dominant meaning for seven emotions (“joy, fear, anger, sadness, disgust, shame, and guilt”) is built using ISEAR dataset. We create an algorithm called Emotion Detection Algorithm to classify and find the suitable emotion class based on the text. To experiment the proposed technique, we tested it on the ISEAR dataset, and compare our results with different results that were implemented by Alexandra Balahur [12] and Danisman and Alpkocak [11] . We show that our system has the best results in precision, recall and F-measure.