On Analysis and Evaluation of Comparative Performance for Selected Behavioral Neural Learning Models versus One Bio-Inspired Non-Neural Clever Model (Neural Networks Approach) ()

1. Introduction
This research work introduces a systematic investigational analysis for two naturally diversified adaptive learning phenomena’ paradigms. These diversified paradigms consider two typical behavioral learning performance algorithms of non-human creatures which were biologically classified as Neural (animals), and Non-Neural (ant colonies) Systems’ modeling [1] - [6] .
The first paradigm is associated to adaptive neural behavioral learning inside three animals’ brain: a Dog, a Cat, and a Mouse. However, the second belongs to analysis of bio-inspired behavioral learning associated to ant colony optimization for observed swarm intelligence phenomenon aiming to get optimal solution Traveling Salesman Problem (TSP), based on realistic simulation foraging of behavioral phenomenon observed by real Ant Colony System. Analysis and evaluation of such interdisciplinary challenging learning issue are carried out using Neural Networks’ Conceptual Approach. Herein, this paper presents analytical details for both intelligent behavioral approaches, which were considered via two hand folds as follows. Firstly, on one hand: autonomous inferences and perceptions were performed in nature by non-human brain (animals: Dogs, Cats, and Mice). Secondly, on the other hand paradigm is inspired by source of ant colony optimization originated from intelligent foraging behavioral phenomenon observed by real ant colonies in natural environment. This behavior is exploited in artificial ant colonies for the search of approximate solutions to optimization problems namely Traveling Salesman Problem (TSP).
1.1. First Learning Paradigm
More specifically, the first behavioral algorithmic paradigm considers three nonhuman models. All three neural creatures’ models have been inspired by results observed after behavioral psycho-learning performance in natural real world. Two of introduced models are based on Pavlov’s and Thorndike’s excremental work. In some details, Pavlov’s dog learns how to associate between two inputs sensory stimuli (audible, and visual signals). However, Thorndike’s cat behavioral learning tries to get out from a cage to reach food out of the cage. Both behavioral learning models improve their performance by trial to minimize response time period. The third model is concerned with behavioral learning of mouse while performing trials for getting out from inside Figure 8 maze. That is performed as optimal trial to solve reconstruction problem [7] .
1.2. Second Learning Paradigm
The second algorithmic paradigm is concerned with searching for optimal solution of TSP by using non-neural systems namely, colony system ACS. That model simulates a swarm (ant) intelligent system used for solving TSP optimally. Briefly, ACS algorithm is inspired by the foraging behavior of ants, specifically the pheromone communication between ants regarding a good path between the colony and a food source in an environment. This mechanism is called stigmergy. Interestingly, that mechanism performed by bringing food from different food sources to store (in cycles) at ant’s nest. Interestingly, all of presented models herein shown to behave analogously in agreement with Least Mean Square LMS Algorithm previously suggested at ANN learning.
Principles of biological information processing concerned with learning convergence for both bio-systems have been published at [8] [9] [10] . By some details, in this work an interesting comparative analysis introduced for concepts of behavioral learning phenomenon, versus optimal solution of TSP using swarm intelligence optimization (ACS) [1] [10] [11] [12] . In other words, an investigational analytical overview is presented herein to get insight with behavioral intelligence of non-human creatures’ performance as Neural and Non-Neural Systems [1] [4] [5] [12] .
Briefly, analysis of obtained results by such recent research work leads to discovery of some interesting analogous relations between both behavioral learning paradigms. That concerned with observed resulting errors, time responses, learning rate values, gain factor values versus number of trials, training dataset vectors intercommunication among ants and number of neurons as basic processing elements [5] [13] [14] . However, it seems to observe diversity of behavioral learning curves performance (till reaching optimum state) for proposed biological systems, both are similar to each other (considering normalization of performance curves) [3] [6] . Interestingly, behavioral intelligence & learning performance phenomena carried out by both nonhuman biological systems are characterized by their adaptive behavioral responses to their living environmental conditions. So, all introduced models for both approaches consider input stimulating actions provided by external environmental conditions versus adaptive reactions carried by creatures’ models [1] [9] [15] .
The rest of this paper is organized as follows. At next section, a simple interactive learning model is presented along with a generalized ANN block diagram simulating learning process. Revising of Thorndike’s, Pavlov’s, and mouse’s behavioral learning are introduced briefly at the third section. The fourth section is dedicated to illustrate learning algorithm at ACS.
Obtained simulation results compared with the experimental results are given at the fifth section. Finally, at the last sixth section, some conclusions and valuable discussions are introduced.
2. Interactive Learning Model
2.1. Simplified Interactive Learning Process
Referring to Figure 1, it illustrates a general view of a teaching model qualified to perform simulation of above mentioned brain functions. Inputs to the neural network teaching model are provided by environmental stimuli (unsupervised learning). However, correction signal(s) in the case of learning with a teacher given by output response(s) of the model that evaluated by either the environmental conditions (unsupervised learning) or by supervision of a teacher. Furthermore, the teacher plays a role in improving the input data (stimulating learning pattern) by reducing the noise and redundancy of model pattern input. That is in accordance with tutor’s experience while performing either conventional (classical) learning or CAL. Consequently, he provides the model with clear data by maximizing its signal to noise ratio [12] . Conversely, in the case of unsupervised/self-organized learning, which is based upon Hebbian rule [15] , it is mathematically formulated by Equation (7). For more details about mathematical formulation describing a memory association between auditory and visual signals, please refer to [16] .
The presented model given in Figure 2 generally simulates two diverse learning paradigms. It presents realistically both paradigms: by interactive learning/ teaching process, as well as other self-organized (autonomous) learning. By some details, firstly is concerned with classical (supervised by a tutor) learning observed in our classrooms (face to face tutoring). Accordingly, this paradigm proceeds interactively via bidirectional communication process between a teacher and his learners (supervised learning) [16] [17] . However, the second other learning paradigm performs self-organized (autonomously unsupervised) tutoring process [16] .
2.2. Mathematical Formulation of Learning Paradigms
Referring to above Figure 2; the error vector 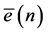 at any time instant (n) observed during learning processes is given by:
at any time instant (n) observed during learning processes is given by:
![]()
Figure 1. Simplified view for interactive learning process.
![]()
Figure 2. Generalized ANN block diagram simulating two diverse learning paradigms adapted from [18] .
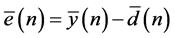 (1)
(1)
where 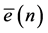 … is the error correcting signal that adaptively controls the learning process,
… is the error correcting signal that adaptively controls the learning process, 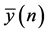 … is the output obtained signal from ANN model, and
… is the output obtained signal from ANN model, and 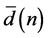 … is the desired numeric value(s).
… is the desired numeric value(s).
Moreover, the following four equations are deduced:
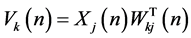 (2)
(2)
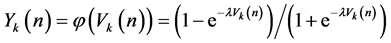 (3)
(3)
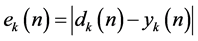 (4)
(4)
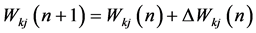 (5)
(5)
where X is input vector and W is the weight vector. φ is the activation function. Y is the output.  is the error value and
is the error value and  is the desired output. Note that
is the desired output. Note that 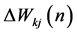 is the dynamical change of weight vector value. Above four equations are commonly applied for both learning paradigms: supervised (interactive learning with a tutor), and unsupervised (learning though student’s self-study). The dynamical changes of weight vector value specifically for supervised phase is given by:
is the dynamical change of weight vector value. Above four equations are commonly applied for both learning paradigms: supervised (interactive learning with a tutor), and unsupervised (learning though student’s self-study). The dynamical changes of weight vector value specifically for supervised phase is given by:
 (6)
(6)
where η is the learning rate value during the learning process for both learning paradigms. At this case of supervised learning, instructor shapes child’s behavior by positive/negative reinforcement Also, Teacher presents the information and then students demonstrate that they understand the material. At the end of this learning paradigm, assessment of students’ achievement is obtained primarily through testing results. However, for unsupervised paradigm, dynamical change of weight vector value is given by:
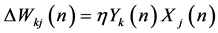 (7)
(7)
Noting that 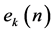 Equation (6) is substituted by
Equation (6) is substituted by  at any arbitrary time instant (n) during the learning process. Instructor designs the learning environment.
at any arbitrary time instant (n) during the learning process. Instructor designs the learning environment.
3. Models of First Learning Paradigm
3.1. Revising of Pavlov’s Work [11]
The psycho-experimental work of Pavlov is known for classical conditioning. It is characterized by following two aspects: A spontaneous reaction that occurs automatically to a particular stimulus, and to alter the “natural” relationship between a stimulus and a reaction response was viewed as a major breakthrough in the study of behavior [15] [19] . By referring to the original Pavlov’s work, let us define what is meant by latency time. This time is briefly, defined as the delay period elapsed since acquisition of two input stimulating signals (pairings), till developing output response signals [10] . In more details, responding signals are held to be of zero value during their correlated latency time periods. Hence, by the end of these periods, output actions are spontaneously developed in a form of some number of salivation drops representing response signals intensities. These intensities observed to be in proportionality with the increase of the subsequent number of trials. So, this relation agrees with odd sigmoid function curve as reaching saturation state [3] [4] . Conversely, on the basis of Pavlov’s obtained experimental results, it is well observed mathematical interrelationship between latency time period versus subsequent number of trials can be illustrated explicitly in the form of hyperbolic function curve that mathematically expressed by following equation:
![]() (8)
(8)
where α and β are arbitrary positive constant in the fulfillment of some curve fitting to a set of points as shown by graphical relation illustrated in Figure 3.
3.2. Revising of Thorndike’s Work [12]
Referring to behaviorism learning theory presented at [19] , Thorndike had suggested three principles, which instructors (who adopted teaching based on behaviorism learning theory) should apply in order to promote effectiveness of behavioral learning process. These principles are given as follows:
・ Present the information to be learned in small behaviorally defined steps.
・ Give rapid feedback to pupils regarding the accuracy of their learning. (Learning being indicated by overt pupil responses).
・ Allow pupils to learn at their own pace.
Furthermore, building on these he proposed an alternative teaching technique called programmed learning/instruction and also a teaching machine that could present programmed material. Initially, cat’s performance trials results in random outputs. By sequential trials, following errors observed to become minimized, by increasing number of training (learning) cycles. Referring to Figure 4, which illustrates original Thorndike’s work results. This figure presents the relation between response time and num-
![]()
Figure 3. Fitting curve for latency time results observed by Pavlov’s experimental work.
![]()
Figure 4. The original result of Thorndike representing learning performance for a cat to get out from the cage for reaching food.
![]()
Figure 5. Thorndike normalized results seem to be closely similar to exponential time decay.
ber of trials. Furthermore, referring to that original Thorndike’s experimental results given at Figure 4, represent behavioral learning performance of Thorndike’s work. However, normalized learning curve that presents performance curve of experimental work is given approximately at Figure 5. Interestingly, the comparative analogy between performance curves of Pavlov’s and Thorndike’s work shown to behave similar to each other [4] .
In general, principle of adaptive learning process (observed during creatures’ interaction with environment) illustrated originally at [17] [20] .
Referring to Figure 6, it observed that by increasing number of training cycles, the first learning algorithm converges to some fixed limiting values (for normalized time response). That observed results consider normalization of both number of trials values versus their corresponding normalized time response (for both original experimental work of Pavlov and Thorndike given at Figure 3 & Figure 4 respectively).
3.3. Mouse’s Trails for Solving Reconstruction Problem
Referring to [18] , the timing of spikes in a population of neurons can be used to reconstruct a physical variable is the reconstruction of the location of a rat in its environment from the place fields of neurons in the hippocampus of the rat. In the experiment reported here, the firing part-terns of 25 cells were simultaneously recorded from a freely moving mouse [7] . The place cells were silent most of the time, and they fired maximally only when the animal’s head was within restricted region in the environment called its place field [19] . The reconstruction problem was to determine the rat’s position based on the spike firing times of the place cells. Bayesian reconstruction was used to estimate the position of the mouse in the Figure 8 maze shown at Figure 7, which adapted from [6] . Assume that a population of N neurons encodes several variables![]() , which will be written as vector x. From the number of spikes
, which will be written as vector x. From the number of spikes ![]() fired by the N neurons within a time interval
fired by the N neurons within a time interval![]() , we want to estimate the value of x using the Bayes rule for conditional probability:
, we want to estimate the value of x using the Bayes rule for conditional probability:
![]() (9)
(9)
Assuming independent Poisson spike statistics. The final formula reads
![]() (10)
(10)
![]()
Figure 6. Comparison between Pavlov and Thorndike work. Considering normalized results after application of ANN.
where k is a normalization constant, P(x) is the prior probability, and fi(x) is the measured tuning function, i.e. the average firing rate of neuron i for each variable value x. The most probable value of x can thus be obtained by finding the x that maximizes![]() , namely,
, namely,
![]() (11)
(11)
By sliding the time window forward, the entire time course of x can be reconstructed from the time varying-activity of the neural population. This appendix illustrates well Referring to results for solving reconstruction (pattern recognition) problem solved by a mouse in Figure 8 maze [7] [21] . That measured results based on pulsed neuron spikes at hippocampus of the mouse brain. In order to support obtained investigational research results and lightening the function of mouse’s brain hippocampus area, three findings have been announced recently as follows:
1) Referring to [22] , experimental testing performed for hippocampal brain area observed neural activity results in very interesting findings. Therein, ensemble recordings of 73 to 148 rat hippocampal neurons were used to predict accurately the animals’ movement through their environment, which confirms that the hippocampus transmits an ensemble code for location. In a novel space, the ensemble code was initially less robust but improved rapidly with exploration. During this period, the activity of many inhibitory cells was suppressed, which suggests that new spatial information creates conditions in the hippocampal circuitry that are conducive to the synaptic modification presumed to be involved in learning. Development of a new population code for a novel environment did not substantially alter the code for a familiar one, which suggests that the interference between the two spatial representations was very small. The parallel recording methods outlined here make possible the study of the dynamics of neuronal interactions during unique behavioral events.
2) The hippocampus is said to be involved in “navigation” and “memory” as if these were distinct functions [23] . In this issue of Neuron this research paper evidence has been provided that the hippocampus retrieves spatial sequences in support of memory, strengthening a convergence between the two perspectives on hippocampal function.
3) Recent studies have reported the existence of hippocampal “time cells,” neurons that fire at particular moments during periods when behavior and location are relatively constant as introduced at [24] . However, an alternative explanation of apparent time coding is that hippocampal neurons “path integrate” to encode the distance an animal has traveled. Here, we examined hippocampal neuronal firing patterns as rats ran in place on a treadmill, thus “clamping” behavior and location, while we varied the treadmill speed to distinguish time elapsed from distance traveled. Hippocampal neurons were strongly influenced by time and distance, and less so by minor variations in location. Furthermore, the activity of different neurons reflected integration over time and distance to varying extents, with most neurons strongly influenced by both factors and some significantly influenced by only time or distance. Thus, hippocampal neuronal networks captured both the organization of time and distance in a situation where these dimensions neuronal networks captured both the organization of time and distance in a situation where these dimensions dominated an ongoing experience as illustrated at Figure 7 [24] .
According to following Table 1, the error value seems to decrease similar to exponential curve decays to some limit value versus (place field) cells.
Noting that, the value of mean error converges (by increase of number of cells) to some limit, excluded as Cramer-Rao bound. That limiting bound is based on Fisher’s information given as tabulated results in the above and derived from [21] . That implies LMS algorithm is valid and obeys the curve.
Furthermore, it is noticed that the algorithmic performance learning curve referred to Figure 7, converged to bounding limit (of minimum error value) fixed Cramer Rao bound (Limiting value). That is analogous to minimum time response corresponding to maximum number of trials limit by referring to above Figure 2. Interestingly, considering comparison between learning curve performances at Figure 8 and learning that at ACS. It observed the analogy when comparing number of place field cells (at hippocampus mouse’s brain area) versus the number of cooperative ants while searching for optimized TSP solution adopting ACS. More details are presented at the simulation results’ Section 5.
4. Second Learning PARADIGM
4.1. Revising Ant Colony System Performance
Referring to Figure 1, ants are moving on a straight line that connects a food source to their nest. It is well known that the primary means for ants to form and maintain the line is a pheromone trail. Ants deposit a certain amount of pheromone while walking, and each ant probabilistically prefers to follow a direction rich in pheromone. This elementary behaviour of real ants can be used to explain how they can find the shortest
![]()
Table 1. Relation between number of cells and mean error in solving reconstruction problem.
![]()
Figure 7. Dissociation between Elapsed Time and Path Integration in the Hippocampus During the delay period of a working memory task required the mouse to run on a treadmill for either a fixed amount, adapted from [24] .
![]()
Figure 8. The dashed line indicates the approach to Cramer-Rao bound based on Fisher information adapted from [6] .
path that reconnects a broken line after the sudden appearance of an unexpected obstacle has interrupted the initial path (Figure 9(A)). In fact, once the obstacle has appeared, those ants which are just in front of the obstacle cannot continue to follow the pheromone trail and therefore they have to choose between turning right or left. In this situation we can expect half the ants to choose to turn right and the other half to turn left (Figure 9(B)). A very similar situation can be found on the other side of the obstacle (Figure 9(C)). It is interesting to note that those ants which choose, by chance, the shorter path around the obstacle will more rapidly reconstitute the interrupted pheromone trail compared to those which choose the longer path. Thus, the shorter path will receive a greater amount of pheromone per time unit and in turn a larger number of ants will choose the shorter path. Due to this positive feedback (autocatalytic) process, all the ants will rapidly choose the shorter path (Figure 9(D)). The most interesting aspect of this autocatalytic process is that finding the shortest path around the obstacle seems to be an emergent property of the interaction between the obstacle shape and ants distributed behaviour: although all ants move at approximately the same speed and deposit a pheromone trail at approximately the same rate, it is a fact that it takes longer to contour obstacles on their longer side than on their shorter side which makes the pheromone trail accumulate quicker on the shorter side. It is the ants’ preference for higher pheromone trail levels which makes this accumulation still quicker on the shorter path. This process is adapted with the existence of an obstacle through the pathway from nest to source and vice versa, however, more detailed illustrations are given through other published research work, [1] . Therein, ACS performance obeys computational biology algorithm used for solving optimally travelling salesman problem TSP [1] .
The paradigm consists of two dominant sub-fields 1) Ant Colony Optimization that investigates probabilistic algorithms inspired by the foraging behavior of ants [1] [25] , and 2) Particle Swarm Optimization that investigates probabilistic algorithms inspired by the flocking and foraging behavior of birds and fish [26] . Like evolutionary computation, swarm intelligence-based techniques are considered adaptive strategies and are typically applied to search and optimization domains. That simulation the foraging behavioral intelligence of a swarm (ant) system used for reaching optimal solution of TSP a cooperative learning approach to the traveling salesman problem optimal solution of TSP considered using realistic simulation of bio-inspired clever Non-neural model namely: ACS [27] .
Referring to two more recent research work [2] [24] , an interesting view distributed biological system ACS is presented. Therein, the ant Temnothorax albipennis uses a learning paradigm (technique) known as tandem running to lead another ant from the nest to food with signals between the two ants controlling both the speed and course of the run. That learning paradigm involves bidirectional feedback between teacher and pupil and considered as supervised learning [24] [25] [26] [28] .
ACS optimization process versus MICE reconstruction problem. Finally the relation between cooperative process in ACS and activity at hippocampus of the mouse brain is illustrated well at two recently published works [3] [4] .
4.2. Cooperative Learning by ACS for Solving TSP
Cooperative learning by Ant Colony System for solving TSP referring to Figure 9, which adapted from [1] , the difference between communication levels among agents (ants) develops different outputs average speed to optimum solution. The changes of communication level are analogues to different values of λ in sigmoid function as shown at Equation (13) in below. This analogy seems to be illustrated well as referring to Figure 4 where the output salivation signal is increased depending upon the value of no of training cycles. When the number of training cycles increases virtually to an infinite value, the number of salivation drops obviously reach a saturation value additionally the pairing stimulus develops the learning process turned in accordance with Hebbian learning rule [17] . However in case of different values of λ other than zero implicitly means that output signal is developed by neuron motors.
![]()
Figure 9. Illustrates the process of transportation of food (from food source) to food store (nest).
5. Simulation Results
5.1. Intercommunication among Ants
Referring to Figure 10 shown in below, the relation between tour lengths versus the CPU time is given. It is observed the effect of ant cooperation level on reaching optimum (minimum tour). Obviously, as level of cooperation among ants increases (better communication among ants) the CPU time needed to reach optimum solution is decreased. So, that optimum solution is observed to be reached (with cooperation) after 300 (msec) CPU the while that solution is reached after 600 (msec) CPU time (without cooperation).
In other words, by different levels of cooperation (communication among ants) the optimum solution is reached after CPU time τ placed somewhere between above two limits 300 - 650 (M. sec). Referring to [1] , cooperation among processing agents (ants) is a critical factor affecting ACS performance as illustrated at Figure 11. So, the number of ants required to get optimum solution differs in accord with cooperation levels among ants. This number is analogous to number of trials in OCR process. Interesting-
![]()
Figure 10. Illustrates performance of ACS with and without communication between ants, adapted from [1] .
![]()
Figure 11. Cooperating ants find better solutions in a shorter time. Average on 25 runs. The number of ants was set to m = 4, adapted from [25] .
ly, in natural learning environment, the (S/N) signal to noise ratio is observed to be directly proportional to leaning rate parameter in self-organized ANN models. That means in less noisy learning environment (clearer) results in better outcome learning performance given in more details at [19] [29] . More precisely, such learning environment with better (S/N) ratio, implicitly results in increasing of stored experience (inside synaptic connectivity) while nonhuman creatures are adopting self-organized learning via interaction with environment [17] . Referring to Equation (11) introduced for solving reconstruction problem (corresponding to the most probable value of x) has great similarity to the equation presented to search for optimal solution considering TSP reached by ACS (for random variable S) as follows.
![]() (12)
(12)
where τ(r,u) is the amount of pheromone trail on edge (r,u), η(r,u) is a heuristic function, which was chosen to be the inverse of the distance between cities r and u, β is a parameter which weighs the relative importance of pheromone trail and of closeness, q is value chosen randomly with uniform probability in [0, 1], q0 (0 ≤ q0 ≤ 1) is a parameter, Mk is memory storage for k ants activities, and S is a random variable selected according to some probability distribution [24] [25] . Synergistic effect by Ant colony intercommunications is given by mathematical formulation for ACS optimization as follows. At recent previous work analogy between ACS performance and ANNs has been illustrated at [2] [5] [6] [30] [31] [32] . The performance of the synergistic effect of ACS referring to the generalized sigmoid function is given as function of discrete integer (+ve) value representing for number of ants as follows:
![]() (13)
(13)
where α … is an amplification factors representing asymptotic value for maximum average speed to get optimized solutions and λ in the gain factor changing in accords with communication between ants. However by this mathematical formulation of that model normalized behavior it is shown that by changing of communication levels (represented by λ) that causes changing of the speeds for reaching optimum solutions. More appropriate that declares the slope (gain factor) for suggested sigmoid function is a direct measure for intercommunications level among ants in ACS in other words, the slope, λ is directly proportional to pheromone trail mediated communication among agents of ACS. Consequently, ACS global performance has become nearly parallel (slope = 0) to the X-axis (number of ants), nevertheless increasing of ants comprising tested colony (slope, λ = 0), that’s the case when no intercommunications between ants exists.
In the given Figure 12, it is illustrated that normalized model behavior according to following equation.
![]() (14)
(14)
![]()
Figure 12. Graphical representation of learning performance of ACS model with different communication levels (λ).
where λi represents one of gain factors (slopes) for sigmoid function.
5.2. Realistic Simulation Program
By referring to Figure 13, it introduces the flowchart for simulation program which applied for performance evaluation of behavioral learning processes. Considering the two adopted cases of biological creatures having either neural or non-neural systems. That figure presents a simplified macro-level flowchart which describes briefly algorithmic steps for realistic simulation program of adopted Artificial Neural Networks’ model for different number of neurons using. The results are shown at the three Figures 14-16 after that program running.
5.3. Least Mean Square LMS Algorithm
At the Figure 14, it presents the learning convergence process for least mean square error as used for training of ANN models [18] . It is clear that this process performed similarly as ACS searching for minimum tour when solving TSP [1] . Furthermore, it obeys the learning performance observed during psycho experimental work carried for animal learning [3] .
6. Conclusions and Discussion
According to the above animal learning experiments (dogs, cats, and mice), and their analysis and evaluation by ANNs modeling, all of them agree well as for ACS, optimization process. Also, the performance of both (ant and animals) is similar to that for latency time minimized by increasing of number of trials. Referring to Figure 6, it is shown that both learning performance curves presenting both work for Thorndike and
![]()
Figure 13. A simplified macro level flowchart describing algorithmic steps for Artificial Neural Networks modeling considering various neurons’ number.
![]()
Figure 14. Illustrate learning performance to get accurate solution with different gain factors 0.05, 1, and 2, while #cycles = 300 and Learning rate = 0.3.
![]()
Figure 15. Illustrate learning performance error-rate with different gain factors when #cycles = 300 and Learning rate = 0.3.
![]()
Figure 16. Illustrate learning performance error-rate with different learning rates when #cycles = 300 and gain factor = 1.
Pavlov are commonly characterized by their hyperbolic decay and also, both obey generalized LMS for error minimization by learning convergence.
In this context, the algorithm agrees with the behavior of brainier mouse behavior (that is genetically reformed) as illustrated at [16] . Generally, the four introduced nonhuman models in this work perform their behavioral learning functions similar to LMS error algorithm, which is introduced at Figure 17.
By some details, artificial neural network models perform computation either on analogue signaling base or on pulsed spikes decoding criterion; they both lead to learning convergence following LMS error algorithm. It is noted that, reconstruction method following Bayesian rule is bounded to Cramer Rao’s limit. This limit is analogous to minimum response time in Pavlov experiment, and Thorndike work as well. Similarly, for ACS, optimization processes are following as LMS error algorithm when performing solution TSP. Additionally; adaptation equations for all of three systems are running in agreement with dynamic behavior of each other. Additionally, the learning
![]()
Figure 17. Idealized learning curve of the LMS algorithm adapted from [18] .
algorithms for the presented four models are close to each other with similar iterative steps (either explicitly or implicitly). Finally, it is worthy to note that the rate of increase of salivation drops is analogous to rate for reaching optimum average speed in ACS optimization process. Similarly, this rate is also analogous to speed of cat getting out from cage in Thorndale’s experiment. It is noted that, increase on number of artificial ants is analogous to number of trials in Pavlov’s work.