Received 18 April 2016; accepted 10 May 2016; published 19 July 2016

1. Introduction
Researchers are trying to design devices which require minimum space and power with high speed. The multipliers are the important unit in many high speed applications. But it needs more components and consumes more power. From the conventional multipliers, Bough-Wooley consumes less power but the bit length is restricted to 16 bits. For high speed devices, Wallace with Booth encoding produces good result. But Wallace will occupy more space due to the usage of more components [1] . To overcome these issues, multiplier based on Vedic Mathematics is designed. In [1] , the Urdhva Tiryakbhyam Vedic multiplier is designed with adiabatic logic. The logic cells used in the half adder, full adder and AND gate are replaced with 2P-2N logic. They focused to reduce the power.
In [2] , vertical and cross wise algorithm is implemented using various compressor adders like 5-3 adders, 10-4 adders, 20-4 adders and 20-5 adders. The percentage improvement between the traditional adders and these compressor adders is much less. The compressor adders are used in the conventional multipliers to validate their proposed work. The result shows the significant improvement. The Vedic multiplier using McCMOS (Multi Channel CMOS) with 65 nm and 45 nm technology is proposed in [3] [4] . The power delay product is reduced from 48% to 70% using this technology.
The MAS (Multiplier Adder Subtractor) unit is incorporated [5] in the design of conventional ALU using Vedic Mathematics. The conventional ALU consists of Arithmetic Unit, Logic Unit and shifter module. MAS unit comprises all the necessary arithmetic modules to build arithmetic unit. In [6] , 16 × 16 bit multiplier block is built, the functionality is verified in XC3STQ144 Xilinx kit, and the delay is compared with conventional multipliers. The final GDSII format is derived using Cadence tool.
The problem solving techniques using Vedic Mathematics not only reduce computational time but also give the way for effective learning. In [7] , the arithmetic operations addition, subtraction, multiplication and division are performed using Nikhilam sutra. In [7] , vinculum operations are explained and the method to find 10’s complement if the number contains n zeros at the right side is well explained. In [8] , Ekanyunena Purvena is explained and its architecture for binary numbers is given. Actually this is the sub sutra for Nikhilam. The important condition is one multiplicand which should contain array of 9 (i.e. 9 or 99 or 9999…). The multiplication is done through subtraction here. In [9] , various conventional multipliers are compared with Vedic multiplier in terms of area, speed and power.
In [10] , the Dadda multiplier is designed with pipelining. They modified the structure of D-Flipflop which is used for pipelining. And also sp-D3Lsum-based HA is used for tree reduction of Dadda algorithm. The design is implemented using 1P-9M Low-K UMC 90 nm CMOS process technology in Cadence Virtuoso. DRC and LVS check for the proposed design is done by Cadence Assura. In [11] , the implementation of linear convolution and circular convolution is done using the Vedic multiplier. In [12] , the Vedic multiplier is designed using Nikhilam sutra and Karatsuba algorithm. In that, the remainder calculation is done through the subtraction operation. The modification of the multiplier structure is done in [13] . Here the remainder is calculated by computing 2’s complement of the input numbers. But in [13] [14] , the inputs are swapped if the multiplier is greater than multiplicand. In this work, without swapping, the multiplication is done through the calculation of remainder using 2’s complement method.
2. Proposed Architectures
The architecture is designed based on the combination of Karatsuba and Nikhilam sutra. in the conventional Karatsuba algorithm, the remainder is determined by taking Least Significant Half of the number without alteration. In the proposed work, the remainder is computed using Nikhilam Sutra. The detailed algorithm is given in [13] [14] . In this section, the proposed algorithms are presented and their architectures for three different modes are given. The results are proven theoretically in this section. Three modes are discussed in detail below.
Mode I―Positive Remainders
Mode II―Negative Remainders
Mode III―Mixed Remainders
2.1. Algorithm for Mode I
Input: A, B
Output: P
Step 1: Considering A and B are N bit numbers and having positive remainders (i.e. both are greater than 2N−1). The positive remainders are derived by considering the numbers without MSB having N − 1 bits. (Considering Ar and Br)
Step 2: Multiplying the remainders Ar and Br. i.e.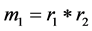 .
.
Step 3: Shifting the input A left side by N − 1 times. (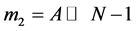 ).
).
Step 4: Shifting the remainder of B, Br by N − 1 times (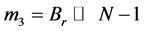 ).
).
Step 5: Adding all the components to derive the final product 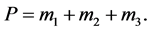
The proposed architecture for positive remainders is shown in Figure 1. As per the algorithm, the product is derived as follows
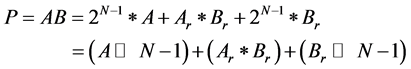 (1)
(1)
In [13] , the architecture of the algorithm is derived based on remainder. The remainder is derived by subtracting the highest weight by the numbers A or B.
2.2. Algorithm for Mode II
Input: A, B
Output: P
Step 1: Considering A and B are having negative remainders. (i.e. both are less than 2N−1). The remainder is computed by complementing A & B with N − 1 bits. (Consider Ar and Br).
Step 2: Multiplying the remainders Ar and Br. i.e.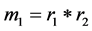 .
.
Step 3: Shifting the input A left side by N − 1 times (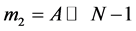 ).
).
Step 4: Shifting the remainder of B, Br by N − 1 times (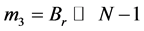 ).
).
Step 5: Adding all the components to derive the final product 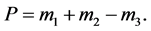
The architecture for negative remainders is shown in Figure 2. The product is determined as follows
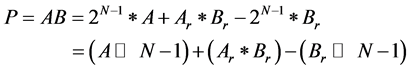 (2)
(2)
2.3. Algorithm for Mode III
Input: A, B
Output: P
![]()
Figure 1. Proposed architecture for positive remainders.
![]()
Figure 2. Proposed architecture for negative remainders.
Step 1: Considering A and B are having mixed remainders (i.e. one is positive remainder and the other is negative remainder). The positive remainder is derived as per Mode I and the negative remainder is calculated as per Mode II (consider Ar and Br).
Step 2: Multiplying the remainders Ar and Br. i.e.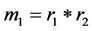 . The product will be negative due to mixed remainders.
. The product will be negative due to mixed remainders.
Step 3: Shifting the input A left side by N − 1 times (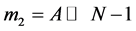 ).
).
Step 4: Shifting the remainder of B, Br by N − 1 times (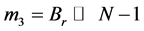 ). The sign of m3 depends on the type of remainder Br.
). The sign of m3 depends on the type of remainder Br.
Step 5: Adding all the components to derive the product![]() .
.
The architecture for mixed remainder is shown in Figure 3. The product of the numbers is calculated as follows
![]() (3)
(3)
The input multiplexer is used here to derive the remainder. Based on MSB value of A and B, the remainder is calculated. For negative remainder, the complement of A is taken. For the positive remainder, the number is taken directly considering N − 1 bits. The multiplier unit is used to multiply the remainder terms![]() . m1 is derived by shifting the value of A by N − 1 bits. (i.e.
. m1 is derived by shifting the value of A by N − 1 bits. (i.e.![]() ). m4 is the term that represents the multiplication of
). m4 is the term that represents the multiplication of![]() . The adder/subtractor is designed to select the operation based on the type of remainder (r2). If BN−1 = 1, the remainder will be negative, adder/subtractor will perform subtraction operation. If BN−1 = 0, it will perform addition operation.
. The adder/subtractor is designed to select the operation based on the type of remainder (r2). If BN−1 = 1, the remainder will be negative, adder/subtractor will perform subtraction operation. If BN−1 = 0, it will perform addition operation.
The combined structure is shown in Figure 4. Unlike [13] [14] , no need to swap the inputs when one number is larger than the other. Using the combined structure, the number in any mode can be calculated. This structure is similar to the structure shown in Figure 3. A simple Ex-or gate is used as control signal to select addition/subtraction operation.
3. Results
The various conventional multipliers are considered and compared with proposed multiplier. The computational delay for various multipliers is listed in Table 1. The simulation result is shown in Figure 5. While comparing delay with other methods, Vedic multiplier has minimum delay among all methods and hence combination of proposed with conventional Vedic has been used for high speed applications. While comparing the area, Wallace will occupy more space because it requires more number of components. The comparison table for power analysis is shown in Table 2. By seeing both results, proposed Vedic multiplier is efficient in area and speed. Therefore, instead of using other methods in the proposed algorithm, the proposed algorithm is called in successive manner. The result for successive approximation of proposed algorithm is shown in Table 3.
![]()
Figure 3. Proposed architecture for mixed remainders.
![]()
Figure 4. Proposed combined architecture of multiplier.
4. Conclusion and Future Work
In this paper, a new multiplication algorithm using Nikhilam sutra is presented. The modification of binary Vedic multiplier with the previous papers is presented here. In the calculation of remainder, a single bit is reduced, and hence usage of components will be reduced. Therefore, the interconnection delay and computation time are reduced. The speed and the area are optimized using this modified Vedic multiplier. The performance of the modified multiplier varies on the type of multiplier used. Finally successive approximation of proposed algorithm is also done here. Comparing with conventional methods, the combination of multiplier with Wallace multiplier gives reduced stage delay. But this combination consumes more power. Normally, Vedic multiplier is used to perform the operation with minimum delay. Therefore, in combination with conventional Vedic multiplier the proposed method gives better result. For high speed applications, proposed method with Wallace multiplier can be used. For low power and low area applications, proposed multiplier with Vedic (Urdhava) or Braun multiplier can be used. From the results it is clear that the proposed algorithm is best suited for high speed
![]()
Figure 5. Simulation waveform for the multiplier with bit size 32.
![]()
Table 1. Comparison of delay with various methods.
![]()
Table 2. Comparison of power with various methods.
![]()
Table 3. Comparison of delay using successive approximation method.
and compact applications.
NOTES
![]()
*Corresponding author.