Design of Low Power and High Speed Correlators for IEEE 802.16 WiMAX Systems ()
Received 6 April 2016; accepted 13 May 2016; published 9 June 2016

1. Introduction
Nowadays, wireless technology is part of everyone’s life. In every consumable from phones to computer, internet, Broadband Wireless Access (BWA) is most popularly used without the use of cable modems and Digital Subscriber Line (DSL) connections. In wireless technique, the signals are transmitted through radio waves. It is possible for long range of communications, which is not possible with the use of wires. One of the wireless techniques is a Metropolitan Area Network (MAN) which is based on IEEE 802.16 standard. It provides fixed broadband wireless access for rural as well as remote areas. Some other wireless accesses are Wi-Fi and WiMAX. The operation of Wi-Fi and WiMAX is similar, but WiMAX operates at high speed and it is used for a large number of users. It has the ability to overcome the physical limitations of wired infrastructure. There are two types of standards developed by the IEEE 802.16 working group, they are fixed usage model and portable usage model. Both fixed and portable applications WiMAX offers 40 Mbps capacity per wireless channel. The important features of IEEE 802.16/WiMAX technologies are frequency < 11 GHz, data rate is up to 100 MHz and distance up to 20 km. The WiMAX physical layer is based on OFDM [1] [2] . It is used by commercial broadband systems such as DSL, Wi-Fi and media to enable high speed data, and multimedia applications. It is a multi-carrier modulation technique, where the closely spaced sub-carrier signals are used to carry the data to the channels in a parallel manner. These subcarriers are orthogonal to each other. To eliminate the Inter Symbol Interference (ISI), the sub-carriers should be non-overlapped. For a complete elimination of ISI, there must be some guard intervals between OFDM symbols. But the guard interval insertion decreases the bandwidth efficiency. It provides multipath resistance and allows WiMAX to operate in Non-Line of Sight (NLOS) conditions [3] .
To improve frequency synchronization, many researches have been done. Cyclic Prefix (CP) based method is used to determine frequency offset and symbol timing [4] . The drawback of this method is that it does not find the start of the frame. So OFDM frames begin with a preamble symbol to estimate the frequency offset. CP methods are based on autocorrelation technique, which is sensitive to Additive White Gaussian Noise and frequency selectivity.
To overcome the drawback of autocorrelation technique, the cross correlation method is used. It accurately determines the start of the frame. Since it has a low signal to noise ratio (SNR), it requires complex computation. Kim et al. proposed the synchronization method that has two separate computation processes. One is autocorrelation for coarse Symbol Time Offset (STO) and Carrier Frequency Offset (CFO) for reduction of hardware cost and reliable frequency synchronization [5] [6] . Another computation process is cross correlation for fine STO and CFO. It causes inter-carrier interference and creates errors in synchronization which leads to inter symbol interference. So synchronization is the critical part of OFDM system. Dick and Harris preferred an autocorrelation based techniques for FPGA implementation, because it required low hardware cost and they used a parallel architecture for OFDM transceiver [7] . In [8] , auto correlation, and cross correlation are compared. The analysis results show that the accuracy of cross correlation is better than the accuracy of autocorrelation and the hardware cost of the method using cross correlation is higher than autocorrelation. This paper proposes a new cross correlator to reduce the hardware cost. When compared to autocorrelation technique, its complexity is high and requires several multipliers. In [3] , multiplier less cross correlator is designed with shift and adds operations which require 26 adders/subtractors.
2. Background
In our generation single person sending several information or multiple person sending multiple information at the same time is greatly increased. So synchronization problem occurs and it creates some frequency offsets. The correlators were designed to overcome this synchronization problem. There are two types of correlation: auto correlation and cross correlation. The function of cross correlator is similar to the convolution operation. It is a standard method to estimate the degree to which the two series of signals are correlated. It is mainly used for determining the timing delay between two signals.
The structure of downlink preamble in IEEE 802.16d standard is shown in Figure 1 [3] [9] . It contains two OFDM symbols named, short training symbol and long training symbol.
The short training symbol is followed CP. It contains four 64 samples which are identical. Long training symbol has two consecutive 128 sample fragments. It also follows the CP guard interval to minimize the inter symbol interference which causes errors in synchronization. For timing synchronization, the cross correlation is
![]()
Figure 1. Structure of IEEE 802.16 preamble.
performed by the 64 samples in the short training symbol. Hence the correlators are designed to perform the cross correlation of 64 coefficients with the received signal. Previously parallel multiplier operations are incorporated with the correlator architectures for improving speed of multiplier based architectures [10] [11] .
2.1. Design of Direct Form Correlator
The correlator is designed to receive complex coefficients. It receives the samples in fractional fixed point format which is called as Q format. Q indicates the number of bits used for fraction. Here 16 samples are used in Q1.15 fixed point format (1) represents the integer and 15 represent the fractional part of the sample.
The correlator correlates the received signals with the short OFDM symbol for timing synchronization. The length of short OFDM symbol is 800 ns and the rate of received samples is 20 MHz. The 16 samples are multiplied with 64 coefficients to generate the proper output. Generally the correlator will perform 320 million complex multiplications per second [12] . Let Rn be the complex valued received sample and Cn be the correlator output, then the correlation equation is
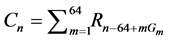 (1)
(1)
where Gm is the mth correlator coefficient, Rn is the received sample and Cn is the output of correlator. The coefficients can be computed from the Equation (2)
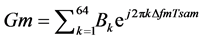 . (2)
. (2)
Here Tsam = 50 ns is the Sampling interval, Bk is the pilot symbol, and ∆f = 312.5 KHz is the subcarrier spacing. The pilot symbol that is used to generate the short OFDM symbols can be computed by Equation (3)
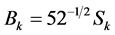 . (3)
. (3)
The real and imaginary part of the coefficients should satisfy
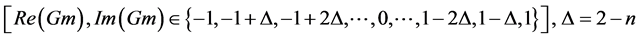 . (4)
. (4)
The complex coefficients can also be computed by
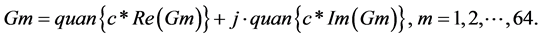 (5)
(5)
The correlator coefficients are computed by (2) and it should satisfy (3), (4) and (5). The coefficients are selected from the sequence of samples from short OFDM symbol and it is tabulated in Table 1.
![]()
Table 1. Selected correlator coefficients for the short OFDM symbol.
The real and imaginary part of the coefficients is computed using sums of power of two operations. The shift and add operations are best replacement of multiplier to design the correlator. If shift and add operations are used for correlator implementation, there is no need of multiplier. The architecture of non-pipelined direct form correlator is shown in Figure 2 [13] . Here Pr indicates the 64 correlation coefficients. These are the complex conjugated values. The output of direct form correlator is given in Equation (6).
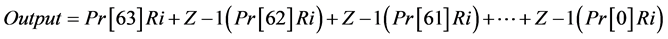 . (6)
. (6)
The product of received sample with the correlator coefficient is obtained by the complex multiplication as
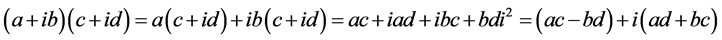 . (7)
. (7)
2.2. Design of Multiplier Less Correlator
The multiplier less correlator is designed to process the complex coefficients as a sum of power of two and the correlator round off the appropriate coefficients. Hence the design of correlator uses shift and add technique instead of multiplier. Thus the multiplier less correlator is more efficient when compared to the design of multiplier based correlator. The architecture of multiplier less correlator is shown in Figure 3 [3] [9] . The correlator is used to correlate the received signal with the known signal for timing synchronization for 802.11. The correlator is used to correlate the received signal with the known signal for timing synchronization for Wireless Local Area Network (WLAN) and Wireless Metropolitan Area Network (WMAN) applications [10] .
Several multiplier less correlators are designed analyzed and its performances were compared for timing synchronization and resource utilization. Compared to these existing correlators, the shift-add technique based correlator is the best one, because it requires only 26 addition/subtraction operations per correlator output. This architecture is mainly used to reduce the complexity in the receiver implementation. Rin is the correlator input, Pr is the selection signal for selecting the output from the shift add block. The shift-add block contains shifter and adder. It calculates the possible correlator coefficients. The shifter in the shift-add block mainly performs the left shift, then the shifted values are added based on the correlator coefficient values. The pre computed values are selected based on Pr[n]. The multiplexed outputs are added to get the final correlator output. Finally by using the shift add block instead of multiplier, the timing synchronization is achieved.
![]()
Figure 3. Architecture of multiplier less correlator.
![]()
Figure 4. Block diagram of proposed correlator.
3. Proposed Correlator Architectures
In OFDM, the overlapping of sub-channels provides good spectral efficiency. But this overlapping leads to channel interference. This is caused by frequency offset. The timing error also creates inter symbol interference which affects the performance of OFDM. To improve OFDM timing synchronization, two correlator architectures are proposed.
3.1. Sharing Technique Based Correlator
The correlator is proposed using an efficient computation sharing technique. This efficient sharing technique reduces the hardware overhead. The block diagram of proposed sharing technique based correlator is shown in Figure 4.
The proposed architecture consists of pre-compute unit, multiplexer and adder. The received signal is given as the input to the pre-compute unit block. The values are pre-computed based on the complex valued coefficient samples.
Then the product of the received sample and the correlator coefficients are selected based on the selection input of the multiplexer. The select line depends on the quantization set which is used for OFDM synchronization. The architecture of sharing technique based correlator is shown in Figure 5. The proposed correlator is based on computation sharing technique that means the common terms of the shifted terms are shared among all the multiplexers. Because of this sharing technique the delay will be reduced. The concept of pre-computation unit is shown in Figure 6. It is used to pre estimate the product of the signals without using multiplier.
The pre-computation unit is used to compute the multiplication of small bit sequence with the received input samples. Once the products of the received sample with the complex correlator coefficients are computed, then the computed values are shared among the multiplexers. For example, only the eight bit alphabets of the
![]()
Figure 5. Architecture of sharing based proposed correlator.
![]()
Figure 6. Block diagram of pre-computation unit.
multiplications are shown in the pre-computation unit. Instead of multipliers, the pre-computation unit is used to compute the product of received samples and the correlator coefficients. The main advantage of a computation sharing technique is time efficiency and reduced area utilization.
The output of the pre-computation block is given as the input to the multiplexer. Based on the quantization value, the product of the received sample and the complex coefficients computed from the pre-computation unit is selected by the multiplexer. The multiplexed pre-computed values are finally added to get the final output.
3.2. Parallel Pre-Compute Correlator
The architecture of parallel pre-compute correlator is shown in Figure 7. The proposed parallel architecture is mainly used in OFDM systems for accurate timing synchronization.
The size of the correlator and the number of registers is based on the input samples. The coefficients are selected based on the preamble samples of the short OFDM signal. Preamble signal is used for transmitting time synchronization. The parallel architecture is also based on computation sharing technique. The product of the received sample with the complex coefficients is estimated by the pre-compute and the selector unit. Pre-computed values are selected based on the multiplexer. Finally the addition process is done in parallel. Because of this parallel processing, it reduces the delay with some area overhead.
4. Results and Discussion
The proposed sharing technique based correlator and the parallel pre-compute architectures are synthesized using Xilinx ISE 13.2 and mapped on Virtex 6 FPGA (Device-XC6VCX75T, Package-FF484 with the speed grade-2) with 40 nm CMOS technology. The behavioral simulation was done in ISIM simulator. The performance of the OFDM is compared in terms of area, power and delay. The comparison of area in terms of number of adders/subtractors and the number of slice LUTs is shown in Table 2.
![]()
Table 2. Number of add/sub in different types of correlators.
Compared to the multiplier less correlator, the proposed pre-compute and parallel pre-compute correlators have some area overhead in terms of number of adders/subtractors. Both the pre-compute and parallel pre-compute correlator uses the sharing technique, but parallel pre-compute correlator needs more add/sub units due to parallel processing.
Area analysis in terms of Slice Registers, slice LUTs and number of occupied slices of various types of correlators is shown in Figure 8. From the obtained results, the proposed pre-compute based and the parallel pre- compute based correlator architectures reduces the area in terms of slice LUTs by 9.3% and 10.43%. Table 3 shows delay and power analysis of different correlators.
From the comparison results, it is observed that the proposed parallel pre-compute and pre-compute correlator architectures reduce the delay and power delay product (PDP). The parallel pre-compute and precompute correlator architectures reduced the delay by 39.59% and 27.68% respectively. The proposed parallel pre-compute and pre-compute techniques provide the power delay product as 40.81% and 29.14% respectively.
5. Conclusions
The cross correlator architectures are proposed for a flexible timing synchronization in Wi-MAX applications. The proposed pre-compute based and the parallel pre-compute based correlator architectures reduce the area by 9.3% and 10.43% respectively and reduce the delay by 27.68% and 39.59% respectively. The proposed schemes reduce the power delay product as 29.14% and 40.81% respectively. Thus the proposed cross correlation techniques provide proper synchronization with reduced cost for communication systems, mainly in IEEE 802.16 standard applications.
As a future work, an area delay power efficient adder will be used to obtain the optimized cross correlator architectures. The ASIC implementation also leads to the optimized cost minimization.