Received 18 February 2016; accepted 26 April 2016; published 29 April 2016

1. Introduction
The polar code belongs to the class of linear block codes. The encoding process can be characterized by the generator matrix. The generator matrix GN for code length N or 2 is obtained by applying the nth kronecker power of the kernel matrix [1] .
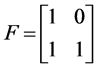 (1)
(1)
Given the generator matrix, the code word x is computed by x = u∙GN, where u denotes the information. The information vector u is arranged in natural order, whereas the code vector x is in a bit reversed order. The encoding complexity of straight forward fully parallel encoder architecture is in the order of (NlogN) for the polar code of length N and takes n stages. When N = 2n, polar code with the length of 32 bit is implemented with 80 ex-or gates and processed in five stages as shown in Figure 1.
In VLSI architecture, reduction focuses on the minimization of the size of the components. Many techniques are involved in the minimization process. Some of the addressable techniques are k-map based Boolean expression method and block optimization method. In general, pipelining can be used in the context of architecture design [2] - [4] . The pipelining transformation leads to a reduction in the critical path, which can be exploited to
![]()
Figure 1. Fully parallel architecture of 32 bit polar encoder.
either increase the clock speed or sample speed or to reduce the power consumption at the same speed. This in turn reduces the effective critical path by introducing pipelined latches along the data path. The pipelined technique can be broadly classified as feed forward and feedback path. The feed forward pipelined encoder structure consists of 2D commutator followed by ex-or and pass gates for achieving high throughput [5] .
The feedback pipelined polar encoder favors for high hardware efficiency rather than high throughput. The number of ex-or gate is equal to the number of processing stages, whereas the number of delay elements gets reduced. In parallel processing, multiple outputs are computed in parallel in a clock period. Therefore, the effective sampling speed is increased by the level of parallelism [6] . This increases the sampling rate by replicating the hardware so that the several inputs can be processed in parallel and several outputs can be produced at the same time.
The polar code architecture is discussed [7] using channel combining phase and channel splitting phase. It incorporates punctured encoding to shorten the length of polar codes. It is observed that reduction of the memory constraints can be achieved during practical applications. The application of polar codes and polarization phenomenon for various problems like wire tap channels [8] , multiple access channels [9] [10] , data compression [11] , and broadcast channels [12] were successful. In addition to the capacity achieving capability, polar codes have interesting properties like good error floor performance [13] . This suggests that the combination of polar coding with other coding schemes could eliminate the shortcomings of both, resulting in a powerful coding paradigm. Furthermore, there are many applications for concatenated codes like deep-space communications, optical transport systems, and magnetic recording channels [14] .
In this paper, the parallelism and pipelining have been combined to achieve an effective encoder structure with minimum registers. This implementation proceeds from the conventional fully parallel 32 bit architecture and transforming as a data flow graph (DFG), delay requirement table, linear lifetime chart and register allocation [15] . The flow of this paper proceeds as follows. Section 2 describes the design of four folded 32 bit polar encoder architecture with each step in detail. Section 3 discusses the architectural design of eight folded polar encoder. Finally the comparative results for fully parallel, four and eight folded architectures with respect to resource utilization are discussed.
2. Four Parallel Folded 32 Bit Polar Encoder
The polar encoder relies on the principle of channel polarization. It is a recursive method used to define the polar codes. A class of codes that can provably achieve the capacity of several classes of channels. It comes under linear codes. The phenomenon of channel polarization includes channel combining and channel splitting. The channel WN can be measured up with two parameters namely mutual information which defines the information capacity and Bhattacharya parameter measures the reliability of the channel.
In synthesizing DSP architectures, it is important to minimize the silicon area of the integrated circuits, which is achieved by reducing the number of functional units, multiplexers, interconnection wires. This in turn may lead to an architecture that uses a large number of registers. To avoid this, various techniques can be used to minimize the number of registers. Folding transformation reduces the hardware utilization by time multiplexing several operations of the functional unit [16] . The DFG of the 32 bit fully parallel polar encoder can be given as shown in Figure 2.
3. Folding Transformation
The DFG of the 32 bit polar code is similar to Fast Fourier Transform (FFT), and it uses the kernel matrix instead of butterfly operation. The 4-parallel folded architecture can be realized by placing 2 functional units in each stage, since each of the functional units compute two bits at a time. Let us consider the four parallel input sequences in natural order. The initial folding sets can be given as: For stage 1: {P0, P2, P4, P6, P8, P10, P12, P14}, {P1, P3, P5, P7, P9, P11, P13, P15}. In this, the two functional units of stage 1 namely P0 and P1 execute simultaneously at the beginning and P2 and P3 at the next cycle. The stage whose index s is less than or equal to log2P, where P is the level of parallelism and has the same folding set as that of the previous one. The stage 2 has the same order as those of stage 1, since it performs the operation within the same four inputs. At later stages, the folding sets are computed by, the property that the functional unit that process a pair of inputs whose indices differ by 2(s−1) is exploited [15] . Thus the folding set of stage 2 can be given as {Q0, Q2, Q4, Q6, Q8, Q10, Q12, Q14}, {Q1, Q3, Q5, Q7, Q9, Q11, Q13, Q15}. In the stage 3, the indices of the two data differ by a factor of four,
![]()
Figure 2. Data flow graph of 32 bit polar encoder.
thus cyclic shifting of four bits right by one can be done by inserting a delay of one time unit. Thus the folding sets of stage 3 are given by {R14, R0, R2, R4, R6, R8, R10, R12}, {R15, R1, R3, R5, R7, R9, R11, R13}. The folding sets of stage 4 and stage 5 can be obtained by cyclic shifting of stage 3 by two in order to enable full utilization of functional units with adjacent iterations. The folding sets of stage 4 and stage 5 can be given as {S10, S12, S14, S0, S2, S4, S6, S8}, {S11, S13, S15, S1, S3, S5, S7, S9} and {T2, T4, T6, T8, T10, T12, T14, T0}, {T3, T5, T7, T9, T11, T13, T15, T1} respectively.
4. Delay Requirement Calculation
The number of delay element required in the folded architecture [3] can be computed
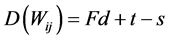 (2)
(2)
where Wij is an edge from the functional unit S to the functional unit T, having the delay d where t and s denote the position in the folding set corresponding to T and S respectively. The delay requirement of four folded 32 bit polar encoder can be given as shown in Table 1.
![]()
Table 1. Original delay requirement D(Wij) for 4-parallel folded Polar encoder.
In Table 1, some edges have negative delays. To have a feasible folded architecture the delay should be greater than or equal to zero for all the edges. Thus we prefer re-timing or pipelining methods for the fully parallel structure to ensure non negative delays. In this, the negative delay should be compensated by inserting at least one delay element to make the value of Equation (2) non negative. The polar encoder utilizes the ex-or operation, and the two inputs should pass through the same number of delay elements. If they are different, additional delays are included to match them. The DFG is pipelined by inserting delay elements, and the red line indicates the pipeline cut-set associated with 4-folded architecture. Thus the recalculated delay is shown in Table 2.
The 32 bit polar encoder with four parallel folded structure can be implemented with 10 functional units and 28 delay elements.
5. Lifetime Analysis
The number of delay elements can be reduced by implementing lifetime analysis for the folded architecture [16] . The linear variable chart represents the lifetime of every variable as in Figure 3. In this, all the edges starting from stage 1 have zero delay. Therefore W2j, W3j and W4j are presented. Here W3,0 is alive for two cycles. Hence, they are produced at stage 1 and consumed in stage 3. The W2j starts at time 0 and proceeds so on. It is taken in the same order as that in DFG. The W3j starts at the next cycle at time 1 and proceeds as j = 0, 1, 4, 5, etc. The next stage W4j starts at time 2 and proceeds as j = 0, 1, 8, 9, etc. in the forward manner. The number of variables alive in each cycle is given at the right side of the chart. Thus the maximum number of live variables is 28, which implies that the four folded 32 bit polar encoder can be implemented with 28 delay elements.
6. Register Allocation
In computing the minimum number of registers required, each variable is allocated to a register. The register allocation table is utilized [17] to verify the allocation in all the 28 registers, and every row describes how registers are allocated at each cycle. The indication in bold font implies that the variable gets consumed at the particular stage. The register allocation for 32 bit four parallel folded polar encoder is shown in Table 3.
7. Proposed Architecture
The four folded parallel pipelined structure for 32 bit polar encoder is shown in Figure 4. It consists of 10 functional units and 28 delay elements. Each stage has two functional units. Stages 1 and 2 include no delay elements. Stages 3, 4 and 5 have several multiplexers placed in front of each functional unit to configure the inputs of the functional units. The proposed architecture continuously processes four samples/cycle, according to folding sets and register allocation table. In this, the inputs are in the natural order and the outputs are in the bit reversed order.
8. Eight Parallel Folded 32 Bit Polar Encoder
The design of eight parallelism considers eight inputs at a time. Hence the stages are split up into four folding sets. The same procedure is applied for eight folded parallelism with the stages depicted below.
Stage 1: {P0, P4, P8, P12} {P1, P5, P9, P13} {P2, P6, P10, P14} {P3, P7, P11, P15}
Stage 2: {Q0, Q4, Q8, Q12} {Q1, Q5, Q9, Q13} {Q2, Q6, Q10, Q14} {Q3, Q7, Q11, Q15}
![]()
Figure 3. Linear lifetime chart for W2j, W3j and W4j.
![]()
Table 2. Recalculated delay requirement D' (Wij) for 4-parallel folded polar encoder.
![]()
Table 3. Register allocation table for W2j, W3j and W4j.
![]()
Figure 4. Proposed 4-parallel folded architecture for encoding the (32, k) polar codes.
Stage 3: {R0, R4, R8, R12} {R1, R5, R9, R13} {R2, R6, R10, R14} {R3, R7, R11, R15}
Stage 4: {S12, S0, S4, S8} {S13, S1, S5, S9} {S14, S2, S6, S10} {S15, S3, S7, S11}
Stage 5: {T4, T8, T12, T0} {T5, T9, T13, T7} {T6, T10, T14, T2} {T7, T11, T15, T3}
The corresponding cut-set is shown in Figure 2, with blue connected lines. The delay requirement table D (Wij) is filled up using Equation (2). This table contains negative delays; it can be set right by using the recalculated delay requirement for eight parallelisms as depicted in Table 4.
The linear lifetime chart is drawn for W3j and W4j, since there exists no cross over with other stage inputs on the W2j stage. This chart minimizes the registers to a count of 24 as shown in Figure 5.
This register count has been used to perform register allocation as illustrated in Table 5.
In the folded architecture the stages 1 and 2 include zero delay and hence no registers are needed. The stage 3 requires eight registers as shown in the linear lifetime chart. The stage 4 requires sixteen registers to obtain the encoded output. Figure 6 depicts the pipeline implementation of the proposed architecture.
9. Results and Discussion
The above designs of 32 bit polar encoder for fully parallel, eight and four folded architectures are simulated using Xilinx 14.6 ISE and implemented in Virtex 5 FPGA and the corresponding outputs are obtained.
The simulation of 32 bit fully parallel architecture for a polar encoder with the input of 32’h FFFFFFFF using Xilinx 14.6 ISIM results in an output of 32’h 80008000 as depicted in Figure 7.
The four parallel folded architecture is simulated with the same input stream as given for fully parallel and verifies the same results as shown above in Figure 8. The synthesis results for 32 bit polar encoder using four folded structure can be done by eight successive executions on the same architecture utilizes 224 registers for execution.
The 8-parallel folded architecture is simulated with the same input stream given in fully parallel results in the same output verifying the functionality of polar code as in Figure 9. The synthesis results for 32 bit polar encoder using eight folded structure can be done by four successive executions on the same architecture utilizes 96 registers.
The partially parallel implementation in [15] concludes that P parallelism of (N, K) polar encoder will arrive at ex-or gates formulated as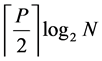 .
.
In addition, there exist N-P delay elements with the throughput of P bits/cycle. Thus the 32 bit polar encoder design for four and eight folding matches exactly with the same criteria. The comparison of resource utilization for the 32 bit polar encoder for fully parallel, four and eight folded architectures is depicted in Table 6.
10. Conclusion and Future Scope
This paper is focused to minimize the hardware resources for the 32 bit polar encoder. Many optimization techniques are implemented in steps to arrive at the proposed architecture for various folding levels. The simulation results show that the folded structure abides the polar encoder functionality. The implementation in Virtex 5
![]()
Figure 5. Linear lifetime chart for W3j and W4j.
![]()
Figure 6. Proposed 8-parallel folded architecture for encoding the polar (32, k) codes.
![]()
Table 4. Original D(Wij) and recalculated D'(Wij) delay requirement table for 8-parallel folded polar encoder.
![]()
Figure 7. Simulation result for fully parallel architecture.
![]()
Figure 8. Simulation result for 4-parallel folded architecture.
![]()
Figure 9. Simulation result for 8-parallel folded architecture.
![]()
Table 5. Register allocation table for W3j and W4j.
![]()
Table 6. Comparison of various folding with fully parallel architecture.
FPGA shows that the folding decreases the functional blocks (ex-or) operations, but needs trade off in the number of delay elements, registers and speed of execution.
NOTES
![]()
*Corresponding author.