Cybersecurity: A Statistical Predictive Model for the Expected Path Length ()
Received 1 March 2016; accepted 2 April 2016; published 5 April 2016

1. Introduction
Cyber-attacks are the most formidable security challenge faced by most governments and large scale companies. Cyber criminals are increasingly using sophisticated network and social engineering techniques to steal the crucial information which directly affects the operational effects of the Government or Company’s objectives. According to the Secunia [1] report 2015, one could see how crucial the volume and magnitude of increasing cyber-security threaten. Thus, in understanding the performance, availability and reliability of computer networks, measuring techniques plays an important role in the subject area.
Quantitative measures are now commonly used to evaluate the security of computer network systems. These measures help administrators to make important decisions regarding their network security.
In the present study, we have first proposed a stochastic model for security evaluation based on vulnerability exploitability scores and attack path behavior. Here, we consider small case scenarios which include three vulnerabilities (high, medium and small) as a base model to understand the behavior of network topology. We structure the attack graph which includes all possibilities that the attacker reach the goal state and use probabilistic analysis to measure the security of the network. In addition, we propose a statistical model that is driven by the mentioned vulnerabilities along with the significant interactions that is highly accurate. This statistical model will allow us to estimate the Expected Path Length and Minimum number of steps to reach the target with probability one. Having these important estimates, we can take counter steps and acquire relevant resources to protect the security system from the attacker. In addition, utilizing this model we have identified the significant interaction of the key attributable variables. Also we can rank the attributable variables (vulnerabilities) to identify the percentage of contribution to the response (Expected Path Length and Minimum number of steps to reach the target) and furthermore one can perform surface response analysis to identify the acceptable values that will minimize the Expected Path Length among others.
2. Background and Terms of Cybersecurity
Here we review some of the terminology associated with cyber security for the convenience of the reader. We also describe some basic aspects of Markov chains properties that we utilized in fulfilling the objectives of the present study.
Figure 1 and Figure 2 below give a schematic presentation of the Common Vulnerability Scoring System (CVSS) which is the basis of the metric calculation model and the temporal and environmental matrices calculation model, respectively.
2.1.1. Vulnerabilities
In computer security, a vulnerability [2] - [4] is a weakness which allows an attacker to reduce a system’s information assurance. Vulnerability is the intersection of three elements, which are, systems susceptibility to the
![]()
Figure 1. Common vulnerability scoring system-base metric calculation model.
![]()
Figure 2. Common vulnerability scoring system-temporal and environmental metrics calculation model.
flaw, attacker access to the flaw, and attacker capability to exploit the flaw.
To exploit a vulnerability, an attacker must have at least one applicable tool or technique that can connect to a system weakness. In this frame, vulnerability is also known as the attack surface.
The attack surface of a software environment is the sum of the different points (the “attack vectors”) where an unauthorized user (the “attacker”) can try to enter data to or extract data from an environment.
2.1.2. Attack Graphs
An attack graph [5] [6] is a succinct representation of all paths through a system that ends in a state where an intruder has successfully achieved his goal.
Attack graphs describe ways in which an adversary can exploit vulnerabilities to break into a system. System administrators analyze attack graphs to understand where their system’s weaknesses lie and to help decide which security measures will be effective to deploy. In practice, attack graphs are produced manually by Red Teams. Construction by hand, however, is tedious, error-prone, and impractical for attack graphs with large number of nodes.
2.1.3. Frei’s Vulnerabilities Lifecycle
Frei’s Vulnerability Lifecycle [7] is a representation of stages that vulnerability faces with time. This model calculates the likelihood of an exploit or patch being available a certain number of days after its disclosure date.
2.1.4. Common Vulnerability Scoring System (CVSS)
Common Vulnerability Scoring System (CVSS) [8] is a free and open industry standard for assessing the severity of computer system security vulnerabilities. It is under the custodianship of the Forum of Incident Response and Security Teams (FIRST). It attempts to establish a measure of how much concern a vulnerability warrants, compared to other vulnerabilities, so efforts can be prioritized. The scores are based on a series of measurements (called metrics) based on expert assessment. The scores range from 0 to 10. Vulnerabilities with a base score in the range 7.0 - 10.0 are High, those in the range 4.0 - 6.9 as Medium, and 0 - 3.9 as Low. CVSS calculating method is described by Figure 1 and Figure 2 are given in Section 2.
2.1.5. Cyber Situational Awareness
Tim Bass [9] first introduced this concept and this is the immediate knowledge of friendly, adversary and other relevant information regarding activities in and through cyberspace and the Electromagnetic Spectrum (EMS). It is obtained from a combination of intelligence and operational activity in cyberspace, the EMS, and in the other domains, both unilaterally and through collaboration with our unified action and public-private partners.
Cyber situational awareness is the capability that helps security analysts and decision makers:
・ Visualize and understand the current state of the IT infrastructure, as well as the defensive posture of the IT environment.
・ Identify what infrastructure components are important to complete key functions.
・ Understand the possible actions an adversary could undertake to damage critical IT infrastructure components.
・ Determine where to look for key indicators of malicious activity.
2.2. Markov Chain and Transition Probability
A discrete type stochastic process 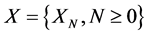 is called a Markov chain [10] if for any sequence
is called a Markov chain [10] if for any sequence 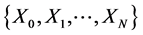 of states, the next state depends only on the current state and not on the sequence of events that preceded it, which is called the Markov property. Mathematically we can write this as follows:
of states, the next state depends only on the current state and not on the sequence of events that preceded it, which is called the Markov property. Mathematically we can write this as follows:
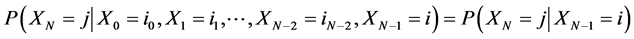 .
.
We will also make the assumption that the transition probabilities 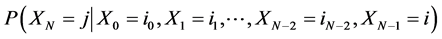 do not depend on time. This is called time homogeneity. The transition probabilities (Pi,j) for Markov chain can be defined as follows:
do not depend on time. This is called time homogeneity. The transition probabilities (Pi,j) for Markov chain can be defined as follows:
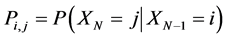 .
.
The transition matrix P of the Markov chain is the 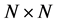 matrix whose
matrix whose 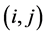 entry
entry 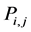 satisfied the following properties.
satisfied the following properties.
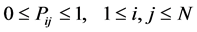
and
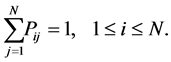
Any matrix satisfying the above two equations is the transition matrix for a Markov chain.
To simulate a Markov chain, we need its stochastic matrix P and an initial probability distribution πo.
Here we shall simulate an N-state Markov chain (X; P; π0) for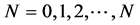 , time periods. Let X be a vector of possible state values from sample realizations of the chain. Iterating on the Markov chain will produce a sample path {XN} where for each N, XN Î X. When writing simulation programs this is about using uniformly distributed U [0, 1] random numbers to obtain the corrected distribution in every step.
, time periods. Let X be a vector of possible state values from sample realizations of the chain. Iterating on the Markov chain will produce a sample path {XN} where for each N, XN Î X. When writing simulation programs this is about using uniformly distributed U [0, 1] random numbers to obtain the corrected distribution in every step.
Transient States
Let P be the transition matrix [10] for Markov chain Xn. A “state i” is called transient state if with probability 1 the chain visits i only a finite number of times. Let Q be the sub matrix of P which includes only the rows and columns for the transient states. The transition matrix for an absorbing Markov chain has the following canonical form.
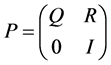 .
.
Here P is the transition matrix, Q is the matrix of transient states, R is the matrix of absorbing states and I is the identity matrix.
The matrix P represents the transition probability matrix of the absorbing Markov chain. In an absorbing Markov chain the probability that the chain will be absorbed is always 1. Hence, we have
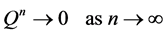 .
.
Thus, is it implies that all the eigenvalues of Q have absolute values strictly less than 1. Hence, ![]() is an invertible matrix and there is no problem in defining the matrix
is an invertible matrix and there is no problem in defining the matrix
![]() .
.
This matrix is called the fundamental matrix of P. Let i be a transient state and consider![]() , the total number of visits to i. Then we can show that the expected number of visits to i starting at j is given by
, the total number of visits to i. Then we can show that the expected number of visits to i starting at j is given by![]() , the
, the ![]() entry of the matrix M.
entry of the matrix M.
Therefore, if we want to compute the expected number of steps until the chain enters a recurrent class, assuming starting at state j, we need only sum ![]() over all transient states i.
over all transient states i.
3. Cybersecurity Analysis Method
The core component of this method is the attack graph [11] . When we draw an attack graph for a cybersecurity system it has several nodes which represent the vulnerabilities that the system has and the attacker’s state [12] . We consider that it is possible to go to a goal state starting from any other state in the attack graph. Also an attack graph has at least one absorbing state or goal state. Therefore we will model the attack graph as an absorbing Markov chain [12] .
Absorbing state or goal state is the security node which is exploited by the attacker. When the attacker has reached this goal state, attack path is completed. Thus, the entire attack graph consists of these type of attack paths.
Given the CVSS score for each of the vulnerabilities in the attack Graph, we can estimate the transition probabilities of the absorbing Markov chain by normalizing the CVSS scores over all the edges starting from the attacker’s source state.
We define,
![]() = probability that an attacker is currently in state j and exploits a vulnerability in state i.
= probability that an attacker is currently in state j and exploits a vulnerability in state i.
n = number of outgoing edges from state i in the attack model.
vj = CVSS score for the vulnerability in state j.
Then formally we can define the transition probability below,
![]() .
.
By using these transition probabilities we can derive the absorbing transition probability matrix P, which follows the properties defined under Markov chain probability method.
3.1. Attack Prediction
Under the Attack prediction, we consider two methods to predict the attacker’s behavior.
3.1.1. Multi Step Attack Prediction
The absorbing transition probability matrix shows the presence of each edge in a network attack graph. This matrix shows every possible single-step attack. In other words, the absorbing transition probability matrix shows attacker reaches ability within one attack step. We can navigate the absorbing transition probability matrix by iteratively matching rows and columns to follow multiple attack steps, and also raise the absorbing transition probability matrix to higher powers, which shows multi-step attacker reach ability at a glance.
For a square (n × n) adjacency matrix P and a positive integer k, then Pk is P raised to the power k: Since P is an absorbing transition probability matrix with time, this matrix goes to some stationary matrix Π, where the rows of this matrix are identical. That is,
![]()
At the goal state column of this matrix has ones, so we can find the minimum number of steps that the attacker should try to reach to the goal state with probability 1.
3.1.2. Prediction of Expected Path Length (EPL)
The Expected Path Length (EPL) measures the expected number of steps the attacker will take starting from the initial state to reach the goal state (the attacker’s objective). As we discussed earlier P has the following canonical form.
![]() .
.
Here, P is the transition matrix, Q is the matrix of transient states, R is the matrix of absorbing states and I is the identity matrix.
The matrix P represents the transition probability matrix of the absorbing Markov chain. In an absorbing Markov chain the probability that the chain will be absorbed is always 1. Thus, we have
![]() .
.
This implies that all the eigenvalues of Q have absolute values strictly less than 1. Thus, ![]() is an invertible matrix and there is no problem in defining the matrix
is an invertible matrix and there is no problem in defining the matrix
![]() .
.
Using this fundamental matrix M of the absorbing Markov chain we can compute the expected total number of steps to reach the goal state until absorption.
Taking the summation of first row elements of matrix M gives the expected total number of steps to reach the goal state until absorption and the probability value relates to the goal state gives the expected number of visits to that state before absorption.
4. Illustration: The Attacker
To illustrate the proposed approach model that we discussed in section 3, we considered a Network Topology [3] [12] - [14] given in Figure 3, below.
The network consists of two service hosts IP 1, IP 2 and an attacker’s workstation, Attacker connecting to each of the servers via a central router.
In the server IP 1 the vulnerability is labeled as CVE 2006-5794 and let’s consider this as V1.
In the server IP 2 there are two recognized vulnerabilities, which are labeled CVE 2004-0148 and CVE 2006-5051. Let’s consider this as V2 and V3, respectively.
We proceed to use the CVSS score of the above vulnerabilities. And the exploitability score (e (v) in Figure 1) of each vulnerabilities as given in Table 1, below.
Host Centric Attack graph
The host centric attack graph is shown by Figure 4, below. Here, we consider that the attacker can reach the
goal state only by exploiting V2 vulnerability. The graph shows all the possible paths that the attacker can follow to reach the goal state.
Note that IP1,1 state represents V1 vulnerability and IP2,1 and IP2,2 states represent V2 and V3 vulnerabilities, respectively. Also, the notation “10” represents the maximum vulnerability score and this provides attacker the maximum chance to exploit this state. Attacker can reach each state by exploiting the relevant vulnerability.
4.1. Adjacency Matrix for the Attack Graph
Let s1, s2, s3, s4, represent the attack states for Attacker, (IP1,1), (IP2,1) and (IP2,2), respectively.
To find the weighted value of exploiting each vulnerability from one state to another state, we divide the vulnerability score by summation of all out going vulnerability values from that state.
For our attack graph the weighted value of exploiting each vulnerability is given below.
1st row probabilities:
Weighted value of exploiting V1 from s1 to s2 is![]() .
.
Weighted value of exploiting V2 from s1 to s3 is![]() .
.
2nd row probabilities:
Weighted value of exploiting V2 from s2 to s3 is![]() .
.
3rd row probabilities:
Weighted value of exploiting V1 from s3 to s2 is![]() .
.
Weighted value of exploiting V3 from s3 to s4 is![]() .
.
4th row probabilities:
Weighted value of exploiting V3 from s4 to s4 is 1.
For the Host Centric Attack graph we can have the Adjacency Matrix as follows.
![]()
Utilizing the information given in Table 1, the matrix A is given by
![]()
Here, 0.5455 is the probability that attacker exploit V1 vulnerability in first step, from s1 to s2. We can explain 0.0588 as the probability that once in state IP2,1 can exploit V3 vulnerability and reach to IP2,2 in first attempt. Similarly each probability represents the chance to exploit relevant vulnerability from one state in the first attempt.
We want to use this matrix to answer the important question in cyber security analysis. We want to find the minimum number of steps to reach the goal state (final destination) with probability one and the expected path length metric.
4.2. Finding Stationary Distribution and Minimum Number of Steps
By using the above matrix A, we can find the probabilities with two, three and several attempt by the attacker to reach the goal state using ![]() matrices. From these matrices we can find all possible probabilities from one state to another that the attacker can reach by two steps A2, three steps A3 and four steps A4 and up to p steps Ap respectively. We continuous this process until we reach the absorbing matrix and that p value gives the minimum number of steps that the attacker is required to reach the goal state with probability one.
matrices. From these matrices we can find all possible probabilities from one state to another that the attacker can reach by two steps A2, three steps A3 and four steps A4 and up to p steps Ap respectively. We continuous this process until we reach the absorbing matrix and that p value gives the minimum number of steps that the attacker is required to reach the goal state with probability one.
We proceed by changing the CVSS score and calculate for each combination of V1, V2 and V3 the minimum number of steps that the attacker will reach the goal state with probability one. These calculations are given in Table 2, below.
![]()
![]()
Table 2. Number of steps for absorbing matrix.
For example, it will take minimum 68 steps with vulnerability configuration of V1 = 10, V2 = 9, V3 = 8 for the attacker to reach the final goal with probability one. The largest number of steps for the attacker to achieve his goal is 844 steps by using the vulnerabilities, V1 = 10, V2 = 2 and V3 = 1, with probability one.
4.3. Expected Path Length (EPL) Analysis
As described under Section 3.1.2 we measure the expected number of steps the attacker will take starting from the initial state to compromise the security goal. In Table 3, we present the calculations of the Expected Path Length of the attacker for various combinations of the vulnerabilities V1, V2 and V3.
For example, it will take 8.25 EPL with vulnerability configuration of V1 = 10, V2 = 9, V3 = 8 for the attacker to compromise the security goal. The largest Expected Path Length of the attacker is 72.8 using V1 = 8, V2 = 2 and V3 = 1.
5. Development of the Statistical Models
The primary objective here is to utilize the information that we have calculated to develop a statistical model to predict the minimum number of steps to reach the stationary matrix and EPL of the attacker. We used the application software package “R” [15] for required calculations in developing these models.
5. 1. Developing a Statistical Model to Predict the Minimum Number of Steps
By using the information in Table 2, we developed a statistical model that estimates the minimum number of
![]()
![]()
Table 3. Expected path length for several vulnerabilities.
![]()
Table 4. Parametric Model: ![]() and
and ![]() values.
values.
steps the attacker takes to reach the goal state with probability one.
The quality of the model is measured by ![]() and
and ![]() values as defined below:
values as defined below:
The first model in Table 4 does not include interactions of the three Vulnerabilities, V1, V2 and V3 and ![]() and
and ![]() reflect its quality of 0.7244 and 0.7173. The second model shows that there is a significant binary interaction of the each factors and the statistical model shows a significant improvement with
reflect its quality of 0.7244 and 0.7173. The second model shows that there is a significant binary interaction of the each factors and the statistical model shows a significant improvement with ![]() and
and ![]() of 0.8835 and 0.8773 respectively. However, the best statistical model is obtained when we consider in addition to individual contributions of V1, V2 and V3, two way and three way significant interactions. Thus, from the above table the third model with
of 0.8835 and 0.8773 respectively. However, the best statistical model is obtained when we consider in addition to individual contributions of V1, V2 and V3, two way and three way significant interactions. Thus, from the above table the third model with ![]() and
and ![]() of 0.9428 and 0.9376 respectively attest to the fact that this statistical model is excellent in estimating the minimum number of steps that an attacker will need to achieve his goal.
of 0.9428 and 0.9376 respectively attest to the fact that this statistical model is excellent in estimating the minimum number of steps that an attacker will need to achieve his goal.
5.2. Developing a Parametric Model to Predict the Expected Path Length
By using Table 3 results we developed a model to find the Expected Path Length that the attacker will take starting from the initial state to reach the security goal.
To utilize the quality of the model we use R2 concept and by comparing the values in Table 5, the third model gives the highest R2 and adjusted R2 value. Therefore we can conclude that the third model gives the best prediction of EPL.
5.3. Comparison of Parametric/Statistical Model Value with Markov Model Value
From the comparison shown in Table 6, we can conclude that our proposed statistical model gives accurate predictions.
5.4. Rank of Attributable Variables
In Table 7, below we present the ranks of the most important attributable variables with respect to their contribution to estimate the EPL.
The most attributable variable (vulnerability) is V3 in quadratic form and individually. Whereas the minimum risk factor is the vulnerability V1. Thus, one can use this ranking to take precautionary measures addressing the most dangerous vulnerability or vulnerabilities with priority.
![]()
Table 5. Parametric model (EPL): R2 and adjusted R2 values.
![]()
Table 6. Error calculation of parametric/statistical model (EPL) and Markov model.
![]()
Table 7. Ranking the variables according to contribution.
6. Conclusions
We have developed a very accurate statistical model that can be utilized to predict the minimum steps to reach the goal state and predict the expected path length.
This developed model can be used to identify the interaction among the vulnerabilities and individual variables that drive the EPL.
We ranked the attributable variables and their contribution in estimating the subject length. By using these rankings, security administrators can have a better knowledge about priorities. This will help them to take the necessary actions regarding their security system.
Here we develop a model for three vulnerabilities and we can expand this model to any large
Network System. Thus, the proposed methods will assist in making appropriate security decisions in advance.
Appendix
Model 1R results
1) ![]()
Here y―# of steps takes to reach the goal state with highest probability
Xi―Vulnerabilities
bi―coefficient
Coefficients:
Estimate Std. Error t value Pr (>|t|)
(Intercept) 344.167 41.154 8.363 1.55e−13***
X1 35.284 5.984 5.896 3.74e−08***
X2 −34.115 5.984 −5.701 9.21e−08***
X3 −67.803 5.984 −11.331 <2e−16***
---
Signif. codes: 0 “***” 0.001 “**” 0.01 “*” 0.05 “.” 0.1 “ ” 1
Residual standard error: 90.95 on 116 degrees of freedom
Multiple R-squared: 0.7244, Adjusted R-squared: 0.7173
F-statistic: 101.6 on 3 and 116 DF, p-value: <2.2e−16
2) ![]()
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 446.865 72.410 6.171 1.09e−08***
X1 67.645 9.772 6.922 2.85e−10***
X2 −81.662 23.169 −3.525 0.000613***
X3 −149.982 29.943 −5.009 2.04e−06***
X4 −1.240 2.516 −0.493 0.623005
X5 −13.700 3.863 −3.546 0.000570***
X6 29.354 2.516 11.667 <2e−16***
---
Signif. codes: 0 “***” 0.001 “**” 0.01 “*” 0.05 “.” 0.1 “ ” 1
Residual standard error: 59.9 on 113 degrees of freedom
Multiple R-squared: 0.8835, Adjusted R-squared: 0.8773
F-statistic: 142.9 on 6 and 113 DF, p-value: <2.2e−16
AIC = 1371.591
3) ![]()
Call:
lm(formula = y ~ X)
Residuals:
Min 1Q Median 3Q Max
−119.916 −25.326 5.661 26.622 110.223
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 689.84236 105.66582 6.529 2.17e−09***
X1 51.17739 23.71769 2.158 0.033141*
X2 −138.81536 26.81969 −5.176 1.04e−06***
X3 −328.09288 58.78621 −5.581 1.76e−07***
X4 −0.36269 3.50341 −0.104 0.917737
X5 9.29187 6.64327 1.399 0.164745
X6 39.11435 10.51884 3.719 0.000318***
X7 −0.08396 1.86012 −0.045 0.964079
X8 8.47917 1.86012 4.558 1.35e−05***
X9 17.96149 1.86012 9.656 2.61e−16***
X10 −3.47455 1.07421 −3.235 0.001613**
---
Signif. codes: 0 “***” 0.001 “**” 0.01 “*” 0.05 “.” 0.1 “ ” 1
Residual standard error: 42.74 on 109 degrees of freedom
Multiple R-squared: 0.9428, Adjusted R-squared: 0.9376
F-statistic: 179.7 on 10 and 109 DF, p-value: <2.2e−16
AIC = 1362.254
4) ![]()
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 621.3262 32.8175 18.933 <2e−16***
X1 56.8012 4.0550 14.008 <2e−16***
X2 −132.3630 13.7273 −9.642 <2e−16***
X3 −253.7456 14.8482 −17.089 <2e−16***
X4 30.1674 4.6875 6.436 3.15e−09***
X5 7.3590 1.4064 5.233 7.88e−07***
X6 17.9615 1.8543 9.687 <2e−16***
X7 −2.3535 0.3204 −7.344 3.56e−11***
---
Signif. codes: 0 “***” 0.001 “**” 0.01 “*” 0.05 “.” 0.1 “ ” 1
Residual standard error: 42.61 on 112 degrees of freedom
Multiple R-squared: 0.9416, Adjusted R-squared: 0.9379
F-statistic: 258 on 7 and 112 DF, p-value: <2.2e−16
AIC = 1304.753
Model 2R results
1) ![]()
Here y―# of steps takes to reach the goal state with highest probability
Xi―Vulnerabilities
bi―coefficient
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 35.9750 4.1628 8.642 3.53e−14***
X1 3.6224 0.6053 5.985 2.47e−08***
X2 −3.4970 0.6053 −5.778 6.48e−08***
X3 −6.8457 0.6053 −11.310 <2e−16***
---
Signif. codes: 0 “***” 0.001 “**” 0.01 “*” 0.05 “.” 0.1 “ ” 1
Residual standard error: 9.199 on 116 degrees of freedom
Multiple R-squared: 0.7253, Adjusted R-squared: 0.7181
F-statistic: 102.1 on 3 and 116 DF, p-value: <2.2e−16
2) ![]()
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 46.3018 7.3227 6.323 5.28e−09***
X1 6.9038 0.9882 6.986 2.08e−10***
X2 −8.2824 2.3430 −3.535 0.000592***
X3 −15.1780 3.0281 −5.012 2.01e−06***
X4 −0.1283 0.2544 −0.504 0.615103
X5 −1.3842 0.3907 −3.543 0.000577***
X6 2.9700 0.2544 11.673 <2e−16***
---
Signif. codes: 0 “***” 0.001 “**” 0.01 “*” 0.05 “.” 0.1 “ ” 1
Residual standard error: 6.058 on 113 degrees of freedom
Multiple R-squared: 0.8839, Adjusted R-squared: 0.8778
F-statistic: 143.4 on 6 and 113 DF, p-value: <2.2e−16
AIC = 821.6622
3) ![]()
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 70.62069 10.68479 6.609 1.47e−09***
X1 5.33882 2.39830 2.226 0.028066*
X2 −14.10835 2.71197 −5.202 9.32e−07***
X3 −33.14449 5.94439 −5.576 1.81e−07***
X4 −0.04135 0.35426 −0.117 0.907303
X5 0.94165 0.67176 1.402 0.163826
X6 3.94315 1.06365 3.707 0.000331***
X7 −0.01535 0.18809 −0.082 0.935119
X8 0.86413 0.18809 4.594 1.17e−05***
X9 1.81443 0.18809 9.646 2.74e−16***
X10 −0.35045 0.10862 −3.226 0.001656**
---
Signif. codes: 0 “***” 0.001 “**” 0.01 “*” 0.05 “.” 0.1 “ ” 1
Residual standard error: 4.322 on 109 degrees of freedom
Multiple R-squared: 0.943, Adjusted R-squared: 0.9378
F-statistic: 180.4 on 10 and 109 DF, p-value: <2.2e−16
AIC = 812.3033
4) ![]()
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 64.04972 3.31940 19.296 <2e−16***
X1 5.80147 0.41015 14.145 <2e−16***
X2 −13.46770 1.38848 −9.700 <2e−16***
X3 −25.64100 1.50186 −17.073 <2e−16***
X4 3.05457 0.47413 6.442 3.05e−09***
X5 0.74725 0.14225 5.253 7.21e−07***
X6 1.81443 0.18755 9.674 <2e−16***
X7 −0.23834 0.03241 −7.353 3.41e−11***
---
Signif. codes: 0 “***” 0.001 “**” 0.01 “*” 0.05 “.” 0.1 “ ” 1
Residual standard error: 4.31 on 112 degrees of freedom
Multiple R-squared: 0.9418, Adjusted R-squared: 0.9381
F-statistic: 258.8 on 7 and 112 DF, p-value: <2.2e−16
AIC = 754.87
NOTES
![]()
*Corresponding author.