Error Analysis of ERM Algorithm with Unbounded and Non-Identical Sampling ()
Received 9 November 2015; accepted 24 January 2016; published 27 January 2016

1. Introduction
In learning theory we study the problem of looking for a function or its approximation which reflects the relationship between the input and the output via samples. It can be considered as a mathematical analysis of artificial intelligence or machine learning. Since the exact distributions of the samples are usually unknown, we can only construct algorithms based on an empirical sample set. A typical setting of learning theory in mathe- matics can be like this: the input space X is a compact metric space, and the output space 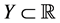 for regression. (When
for regression. (When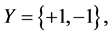 ,it can be regarded as a binary classification problem.) Then
,it can be regarded as a binary classification problem.) Then 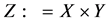 is the whole sample space. We assume a distribution
is the whole sample space. We assume a distribution 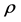 on Z, which can be decomposed to two parts: marginal distribution
on Z, which can be decomposed to two parts: marginal distribution 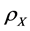 on X and conditional distribution
on X and conditional distribution 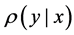 given some
given some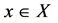 . This implies
. This implies
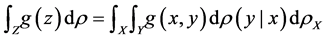
for any integrable function 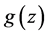 [1] .
[1] .
To evaluate the efficiency of a function 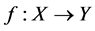 we can choose the generalization error:
we can choose the generalization error:
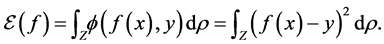
Here 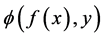 is a loss function which measures the difference between the prediction
is a loss function which measures the difference between the prediction 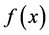 via f and the actual output y. It can be hinge loss in SVM (support vector machine) or pinball loss in quantile learning and etc.. In this paper we focus on the classical least square loss
via f and the actual output y. It can be hinge loss in SVM (support vector machine) or pinball loss in quantile learning and etc.. In this paper we focus on the classical least square loss  for simplicity. [2] shows that
for simplicity. [2] shows that
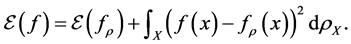 (1)
(1)
From this we can see the regression function
![]()
is our goal minimizing the generalization error. The empirical risk minimization (ERM) algorithm aims to find a function which approximates the goal function ![]() well. While
well. While ![]() is always unknown beforehand, a sample set
is always unknown beforehand, a sample set ![]() is accessible. Then ERM algorithm can be described as
is accessible. Then ERM algorithm can be described as
![]()
where function space ![]() is the hypothesis space which will be chosen to be a compact subset of
is the hypothesis space which will be chosen to be a compact subset of![]() .
.
Then the error produced by ERM algorithm is![]() . We expect it is close to the optimal one
. We expect it is close to the optimal one![]() , which means the excess generalization error
, which means the excess generalization error ![]() should be small, while the sample size m tends to infinity.
should be small, while the sample size m tends to infinity.
Dependent sampling has considered in some literature such as [3] for concentration inequality and [4] [5] for learning. More recently, in [6] and [7] , the authors studied learning with non-identical sampling and dependent sampling, and obtained satisfactory learning rates.
In this paper we concentrate on the non-identical setting that each sample ![]() is drawn according to a different distribution
is drawn according to a different distribution ![]() on Z. And each
on Z. And each ![]() can also be decomposed to marginal distribution
can also be decomposed to marginal distribution ![]() and conditional distribution
and conditional distribution![]() . Assume they are elements of
. Assume they are elements of ![]() and
and ![]() respectively, where
respectively, where ![]() and
and ![]() are Hölder spaces with
are Hölder spaces with![]() . Hölder spaces
. Hölder spaces ![]() is the set of continuous functions with finite norm
is the set of continuous functions with finite norm
![]()
where
![]()
We assume a polynomial convergence condition for both sequences ![]() and
and![]() , i.e., there exist
, i.e., there exist ![]() and
and![]() , such that
, such that
![]() (2)
(2)
![]() (3)
(3)
Power index b measures quantitatively differences between the non-identical setting and the i.i.d. case. The distributions are more similar as b is larger, and when ![]() it is indeed i.i.d. sampling, i.e.
it is indeed i.i.d. sampling, i.e. ![]() and
and ![]() for any
for any![]() . The following example is taken from [8] .
. The following example is taken from [8] .
Example 1. Let ![]() be a sequence of bounded functions on X such that
be a sequence of bounded functions on X such that![]() . Then the sequence
. Then the sequence ![]() defined by
defined by ![]() satisfies (2) for any
satisfies (2) for any![]() .
.
On the other hand, most literature assume the output space is uniformly bounded, that is, ![]() for some positive constant M and almost surely with respect to
for some positive constant M and almost surely with respect to![]() . A typical kernel dependent result for the least-squares regularization algorithm under this assumption is [9] . There the authors get a learning rate close to 1 under some capacity condition for the hypothesis space. However, the most common distribution-Gaussian distribution is not bounded. This requirement is from the bounded condition in Bernstein inequality and limits the application of algorithms. In [10] - [13] , some unbounded conditions for the output space are discussed in different forms, which extends the classical bounded condition. Here we will follow the latter one which is more generalized and simple in expression, and this is the second novelty of this paper. We assume the moment incremental condition for the output space, an extension of that we proposed in [11] :
. A typical kernel dependent result for the least-squares regularization algorithm under this assumption is [9] . There the authors get a learning rate close to 1 under some capacity condition for the hypothesis space. However, the most common distribution-Gaussian distribution is not bounded. This requirement is from the bounded condition in Bernstein inequality and limits the application of algorithms. In [10] - [13] , some unbounded conditions for the output space are discussed in different forms, which extends the classical bounded condition. Here we will follow the latter one which is more generalized and simple in expression, and this is the second novelty of this paper. We assume the moment incremental condition for the output space, an extension of that we proposed in [11] :
![]() (4)
(4)
and
![]() (5)
(5)
We can see the Gaussian distribution satisfies this setting.
Example 2. Let ![]() and
and![]() . If for each
. If for each ![]() and the condition distribution
and the condition distribution ![]() is a normal distribution with variance
is a normal distribution with variance ![]() bounded by
bounded by![]() , then (4) is satisfied with
, then (4) is satisfied with ![]() and
and![]() .
.
Next we need to introduce the covering number and interpolation space.
Definition 1. The covering number ![]() for a subset
for a subset ![]() of
of ![]() and
and ![]() is defined to be the minimal integer N such that there exist N balls with radius
is defined to be the minimal integer N such that there exist N balls with radius ![]() covering
covering![]() .
.
Let the hypothesis space![]() , be a compact Banach space with inclusion
, be a compact Banach space with inclusion ![]() bounded and compact. We follow the assumption [14] [15] that there exist some constants
bounded and compact. We follow the assumption [14] [15] that there exist some constants ![]() and
and![]() , such that the hypothesis space satisfies the capacity condition
, such that the hypothesis space satisfies the capacity condition
![]() (6)
(6)
where![]() . Capacity condition describes the amount of functions in the hypothesis space.
. Capacity condition describes the amount of functions in the hypothesis space.
The sample error will decrease but approximation error will increase when covering number of H is larger (or simply say H is larger). So how to choose an appropriate hypothesis space is the key problem of ERM algorithm. We will demonstrate this in our main theorem.
Definition 2. The interpolation space ![]() is a function space consists of
is a function space consists of ![]() with norm
with norm
![]()
where ![]() is the K-functional defined as
is the K-functional defined as
![]()
Interpolation space is used to characterize the position of the regression function, and it is related with the approximation error. Now we can state our main result as follow.
Theorem 1. If ![]() with bounded inclusion
with bounded inclusion![]() , and satisfies (6) with r,
, and satisfies (6) with r, ![]() ,
, ![]() for some
for some![]() , the sample distribution satisfies (2), (3) for some
, the sample distribution satisfies (2), (3) for some ![]() and
and![]() , (4) and (5). For any
, (4) and (5). For any![]() , choose the hypothesis space
, choose the hypothesis space ![]() to be the ball of H centered at 0 with radius
to be the ball of H centered at 0 with radius![]() , where
, where ![]() and
and
![]()
Moreover, we assume all functions in H and ![]() are Hölder continuous of order s, i.e., there is a constant
are Hölder continuous of order s, i.e., there is a constant![]() , such that
, such that
![]() (7)
(7)
Then for any![]() , with confidence at least
, with confidence at least![]() , we have
, we have
![]()
Here ![]() is a constant independent with m and
is a constant independent with m and![]() .
.
Remark 1. In [6] , the authors pointed out that if we choose the hypothesis space to be the reproducing kernel Hilbert space (RKHS) ![]() on
on![]() , and the kernel
, and the kernel![]() , then our assumption (7) will hold true. In particular, if the kernel is chosen to be Gaussian kernel
, then our assumption (7) will hold true. In particular, if the kernel is chosen to be Gaussian kernel![]() , then (7) holds for any
, then (7) holds for any![]() . [16] discussed this in detail.
. [16] discussed this in detail.
In all, we extend the polynomial convergence condition on the conditional distribution sequense and accordingly, set the moment inremental condition for the sequence in the least squares ERM algorithm. By error decomposition, truncate technique and unbounded concentration inequality, we can finally obtain the total error bound Theorem 1.
Compared with the non-identical settings in [6] and [17] , our setting is more general since the conditional distribution sequence ![]() is also a polynomially convergence sequence, but not identical as in their settings. This together with unbounded y lead to the main difficulty for the error analysis in this paper.
is also a polynomially convergence sequence, but not identical as in their settings. This together with unbounded y lead to the main difficulty for the error analysis in this paper.
For the classical i.i.d. and bounded conditions, [9] indicates that ![]() and kernel
and kernel ![]() while
while![]() , the rate of least square regularization algorithm is
, the rate of least square regularization algorithm is ![]() for any
for any![]() . [17] shows that
. [17] shows that
under some conditions on kernel, object function![]() , exponential convergence condition for distribution sequence and choose some special parameters, the optimal rate of online learning algorithm is close to
, exponential convergence condition for distribution sequence and choose some special parameters, the optimal rate of online learning algorithm is close to
![]() . In [6] , the best case occurs when
. In [6] , the best case occurs when ![]() and kernel
and kernel![]() . The rate of least square regularization algorithm can be close to
. The rate of least square regularization algorithm can be close to![]() . However, our result implicates that while
. However, our result implicates that while![]() ,
, ![]()
tends to 1 and ![]() tends to 0, since p can be any integer, the learning rate can be arbitrarily close to
tends to 0, since p can be any integer, the learning rate can be arbitrarily close to![]() , which is the same as in i.i.d. case [9] , and better than the former results with non-identical settings. With this result, we can extend the application of learning algorithm to more situations and still keep the best learning rate. The explicit expression of
, which is the same as in i.i.d. case [9] , and better than the former results with non-identical settings. With this result, we can extend the application of learning algorithm to more situations and still keep the best learning rate. The explicit expression of ![]() in the theorem can be found through the proof of the theorem below.
in the theorem can be found through the proof of the theorem below.
2. Error Decomposition
Our aim, the error ![]() is hard to bound directly, we need a transitional function for analyzing. By the compactness of
is hard to bound directly, we need a transitional function for analyzing. By the compactness of ![]() and continuity of functional
and continuity of functional![]() , we can denote
, we can denote
![]()
Then the generalization error can be written as
![]()
The first term on the right hand side is the sample error, and the second term ![]() is called approximation error which is independent with samples. [18] analyzed the approximation error by approxi- mation theory. In the following we mainly study the sample error bound.
is called approximation error which is independent with samples. [18] analyzed the approximation error by approxi- mation theory. In the following we mainly study the sample error bound.
Now we break the sample error to some parts which can be bounded using truncate technique and unbounded concentration inequality. We refer the error decomposition ![]() to [6] . Denote
to [6] . Denote
![]()
![]()
then ![]() and we have
and we have
![]()
In the following, we call the first and fourth brackets drift errors, and the left sample errors. We will bound the two types of errors respectively in the following sections, and finally obtain the total error bounds.
3. Drift Errors
Firstly we consider the drift error involving ![]() in this section.To avoid handling two polynomial convergence sequences simultaneously, we break the drift errors to two parts. Meanwhile, a truncate technique is used to deal with the unbounded assumption. Since
in this section.To avoid handling two polynomial convergence sequences simultaneously, we break the drift errors to two parts. Meanwhile, a truncate technique is used to deal with the unbounded assumption. Since ![]() is a subset of
is a subset of![]() , functions in
, functions in ![]() is uniformly bounded. Then we have
is uniformly bounded. Then we have
Proposition 1. Assume ![]() for some
for some![]() , for any
, for any ![]()
![]()
Proof. From the definition of ![]() and
and![]() , we know that
, we know that
![]()
Since![]() , we can bound the first term inside the bracket as follow.
, we can bound the first term inside the bracket as follow.
![]()
But for any ![]() and
and![]() , there holds
, there holds
![]()
From (3.12) in [6] , we have
![]()
Then we can bound the sum of the first term as
![]()
Choose K to be![]() , we have
, we have
![]()
For the second term, notice![]() , and
, and ![]() so
so
![]()
Therefore
![]()
Combining the two bounds, we have
![]()
And this is indeed the proposition.
For the drift error involving![]() , we have the same result since
, we have the same result since ![]() as well, i.e.,
as well, i.e.,
Proposition 2. Assume ![]() for some
for some![]() , for any
, for any![]() , we have
, we have
![]()
4. Sample Error Estimate
We devote this section to the analysis of the sample errors. For the sample error term involving![]() , we will use the Bennett inequality as in [11] and [19] , which is initially introduced in [20] . Since two polynomial convergence conditions are posed on the marginal and conditional distribution sequences, we have to modify the
, we will use the Bennett inequality as in [11] and [19] , which is initially introduced in [20] . Since two polynomial convergence conditions are posed on the marginal and conditional distribution sequences, we have to modify the
Bennett inequality to fit our setting. Denote ![]() and
and ![]() for an integrable function g, the lemma can be stated as follow.
for an integrable function g, the lemma can be stated as follow.
Lemma 1. Assume ![]() holds for
holds for ![]() and some constants
and some constants ![]() , then we have
, then we have
![]()
For our non-identical setting, we can have a similar result from the same idea of proof. By denoting ![]() and
and![]() , the following lemma holds.
, the following lemma holds.
Lemma 2. Assume ![]() and
and ![]() for some constants
for some constants ![]() and any
and any![]() , then we have
, then we have
![]()
Now we can bound the sample error term ![]() by applying this lemma.
by applying this lemma.
Proposition 3. Under the moment incremental condition (4), (5) and notations above, with probability at least![]() , we have
, we have
![]()
where ![]() and
and ![]() is the approximation error.
is the approximation error.
Proof. Let
![]() , then
, then
![]()
Since![]() , we have
, we have
![]()
for any![]() , where 1and
, where 1and![]() . In the same way, we have the following bounds
. In the same way, we have the following bounds
![]()
as well. Then from Lemma 2 above, we have
![]()
Set the right hand side to be![]() , we can solve that
, we can solve that
![]()
Therefore with confidence at least![]() , there holds
, there holds
![]()
This proves the proposition.
For the sample error term involving![]() , analysis will be more involved since we need a concentration inequality for a set of functions. Firstly we have to introduce the ratio inequality [9] .
, analysis will be more involved since we need a concentration inequality for a set of functions. Firstly we have to introduce the ratio inequality [9] .
Lemma 3. Denote ![]() for
for![]() , which satisfies
, which satisfies ![]() and
and ![]() for some constants
for some constants ![]() and
and![]() , then we have
, then we have
![]()
Proof. Let ![]() to be
to be ![]() in the Lemma 2, from the proof of the last proposition, we can conclude that
in the Lemma 2, from the proof of the last proposition, we can conclude that
![]()
Note that ![]() and the lemma is proved.
and the lemma is proved.
Then we have the following result.
Lemma 4. For a set of functions ![]() with
with![]() , construct functions
, construct functions ![]() for
for![]() , with confidence at least
, with confidence at least![]() , we have
, we have
![]()
where ![]() for any
for any ![]()
Proof. Since ![]() is an element of
is an element of![]() , from Lemma 3 we have
, from Lemma 3 we have
![]()
then there holds
![]()
Set the right hand side to be ![]() and we have with probability at least
and we have with probability at least![]() ,
,
![]()
Here![]() . And this proves the lemma.
. And this proves the lemma.
Now by a covering number argument we can bound the sample error term involving![]() .
.
Proposition 4. If ![]() for some
for some![]() , where H satisfies the capacity condition, for any
, where H satisfies the capacity condition, for any![]() , with confidence at least
, with confidence at least![]() , there holds
, there holds
![]()
Proof. Denote ![]() where
where ![]() is to be determined, then we can find an
is to be determined, then we can find an ![]() -net
-net ![]() of
of![]() , and there exist a function
, and there exist a function![]() , we have
, we have
![]()
For the first term, since ![]() for all
for all![]() , we have
, we have
![]()
And for the third term,
![]()
we need to bound
![]()
Let ![]() and then
and then
![]()
From Lemma 1 we have
![]()
Set the right hand side to be ![]() and with confidence at least
and with confidence at least ![]() we have
we have
![]()
And this means,
![]()
with probability at least![]() .
.
The second term can be bounded by 4 above. That is, with confidence at least![]() , we have
, we have
![]()
Since ![]() by assumption, and
by assumption, and
![]()
combining the three parts above, we have the following bound with confidence at least![]() ,
,
![]()
By choosing ![]() for balancing, we have
for balancing, we have
![]()
with confidence at least![]() , this proves the proposition.
, this proves the proposition.
5. Approximation Error and Total Error
Combining the results above, we can derive the error bound for the generalization error![]() .
.
Proposition 5. Under the moment condition for the distribution of the sample and capacity condition for the hypothesis space![]() , for any
, for any ![]() and
and![]() , with confidence at least
, with confidence at least![]() , we have
, we have
![]()
where![]() .
.
What is left to be determined in the proposition is the approximation error![]() . By the choice of hypothesis space we can get our main result.
. By the choice of hypothesis space we can get our main result.
Proof of Theorem 1. Let
![]()
and![]() , assume
, assume ![]() without loss of generality, and
without loss of generality, and![]() , Proposition 5 indicates that
, Proposition 5 indicates that
![]()
holds with confidence at least ![]() for any
for any![]() , where
, where ![]() is a constant independent on m or
is a constant independent on m or![]() .
.
For the approximation error![]() , we can bound it by Theorem 3.1 of [18] . Since the hypothesis space
, we can bound it by Theorem 3.1 of [18] . Since the hypothesis space![]() , and
, and ![]() with
with![]() , we have
, we have
![]()
The upper bound B is now chosen to be ![]() since
since![]() , then with confidence at least
, then with confidence at least![]() ,
,
![]()
By choosing
![]()
we have
![]()
holds with confidence at least![]() . Denote
. Denote![]() , then the theorem is obtained.
, then the theorem is obtained.
6. Summary and Future Work
We investigate the least squares ERM algorithm with non-identical and unbounded sample, i.e., polynomial convergence for ![]() and
and ![]() and moment inremental condition for the latter ones. Analogue
and moment inremental condition for the latter ones. Analogue
error decomposition as classical analysis for least sqaures regularization [9] [11] is conducted. Truncate techni- que is introduced for handling unbounded setting, and Bennett concentration inequality is used for the sample error. By the above analysis we finally get the error bound and learning rate.
However, our work only considers the ERM algorithm. It is neccesary for us to extend this to the regulari- zation algorithms which are more widely used in practice. A more recent relative reference can be found in [21] . Another interesting topic in future study is dependent sampling [7] .
NOTES
![]()
*This work is supported by NSF of China (Grant No. 11326096, 11401247), Foundation for Distinguished Young Talents in Higher Education of Guangdong, China (No. 2013LYM 0089), Doctor Grants of Huizhou University (Grant No. C511.0206) and NSF of Guangdong Province in China (No. 2015A030313674).
#Corresponding author.