1. Introduction
An experiment is a planned inquiry to obtain new facts or to confirm or deny the results of previous experiments, where such inquiry will aid in a decision [1] . Usually, statistical experiments are conducted in situations in which researchers can manipulate the conditions of the experiment and can control the factors that are irrelevant to the research objectives.
According to [2] , experimental design refers to a plan for assigning subjects to experimental conditions and the statistical analysis associated with the plan. The design of an experiment to investigate a scientific or research hypothesis involves a number of integrated activities:
· Formulation of statistical hypotheses that are germane to the scientific hypothesis;
· Determination of the experimental conditions (independent variable) to be used, the measurement (dependent variable) to be recorded, and the extraneous conditions (nuisance variables) that must be controlled;
· Specifications of the number of subjects (experimental units) required and the population from which they will be sampled;
· Specification of the procedure for assigning the subjects to the experimental conditions;
· Determination of the statistical analysis to be performed.
In short, an experimental design identifies the independent, dependent, and nuisance variables and indicates the way in which the randomization and statistical aspects of an experiment are to be carried out.
The most common experimental plans are: Completely Randomized Design (CRD), Randomized Blocks Design (RBD) and Latin Squares Design (LSD), while the most popular schemes are: single factor, factorial and split-plot experiments [3] .
The analysis of variance was introduced by Sir Ronald A. Fisher and is essentially an arithmetic process for partitioning a total sum of squares into components associated with recognized sources of variation. It has been used to advantage in all fields of research where data are measured quantitatively [1] .
According to [4] , the two main aims of classical ANOVA are:
· to examine the relative contribution of different sources of variation (factors or combination of factors, i.e. the predictor variables) to the total amount of the variability in the response variable, and;
· to test the null hypothesis (H0) that population group or treatment means are equal.
That is, according to [5] , given a certain number of treatments (say I treatments) and denoting their means by θ1, θ2, …, θI, the hypothesis are
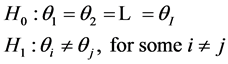
Nevertheless, for the ANOVA’s F test to be valid, three basic assumptions are required [6] :
1) Errors are independent and normally distributed;
2) Errors present homogeneity of variance; and
3) Additivity of terms of the model.
For instance, for the completely randomized design, one assumes that
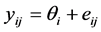
and
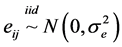
where yij is the j-th replication of the i-th treatment; θi = θ + τi is the mean of the i-th treatment; eij is the random error associated to yij and 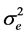 the common error variance.
the common error variance.
If the omnibus hypothesis of equality of means is rejected, a researcher is still faced with the problem of deciding which of the means are not equal. A significant F test indicates that something has happened in an experiment that has a small probability of happening by chance [2] . Thus, according to [1] [2] [4] [7] , when treatments are qualitative, several proposals of contrasts among means are available in literature, such as the test of Tukey, Duncan, Student-Newman-Keuls, t, Bonferroni, Dunn, Dunn-Šidák, Dunnett, Gomes-Howell, Fisher- Hayter, Scheffé and others.
On the other hand, when treatments are quantitative, linear regression analysis can be applied in ANOVA [5] . According to [2] , a linear model consists of two parts: a model equation and associated assumptions. The model equation relates the observable random variable to underlying parameters and random variables in a linear manner. The assumptions specify the nature of the random components and any restrictions that the parameters must satisfy. Consider the multiple regression model
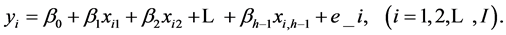
where yi is the value of the dependent variable for experimental unit i; 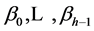 are unknown parameters;
are unknown parameters; 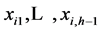 are independent variables; ei is a random error term with mean equal to zero and variance equal to
are independent variables; ei is a random error term with mean equal to zero and variance equal to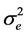 ; ei and ei' are uncorrelated for all i ≠ i'.
; ei and ei' are uncorrelated for all i ≠ i'.
Several features of the model deserve further comment:
1) The observed value of yi is the sum of two components: the constant predictor term, 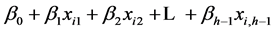 , plus the random error term, ei. The error term reflects that portion of yi that is not accounted for by the independent variables. Because the error term is a random variable, yi is also a random variable.
, plus the random error term, ei. The error term reflects that portion of yi that is not accounted for by the independent variables. Because the error term is a random variable, yi is also a random variable.
2) The expected value of the error term equals zero, E(ei) = 0; it follows that the expected value of yi is equal to the constant predictor term.
3) If the independent variables are quantitative, the unknown parameters can be interpreted as follows: The parameter β0 is the Y intercept of the regression line. The 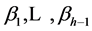 are partial regression coefficients, or weights applied to the xij to optimally predict yi. The parameter β1, for example, indicates the change in the mean response per unit increase in xi1 when
are partial regression coefficients, or weights applied to the xij to optimally predict yi. The parameter β1, for example, indicates the change in the mean response per unit increase in xi1 when 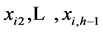 are held constant.
are held constant.
4) When there is only one independent variable, the model is a simple regression model; when there are two or more independent variables, it is a multiple regression model.
5) The error term, ei, is assumed to have constant variance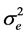 . It follows that the variance of yi is
. It follows that the variance of yi is 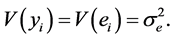
6) The error terms are assumed to be uncorrelated. The value of ei is not related to the value of ei' for all i ≠ i'. Because the ei’s are uncorrelated, the yi’s are also uncorrelated.
When planning a factorial experiment, it is often desirable to include certain extra treatments falling outside the usual factorial scheme. Reference [8] discusses the exact analysis of an experiment of this type. The author points out that, since the additional treatment is randomized in with others, one should perform the standard ANOVA considering all treatments (including the additional) without the factorial structure; and then perform the factorial analysis (without the additional treatment). Such procedure enables to contrast the additional treatment with the factorial experiment and decide if their means differ through F test.
2. R Packages to Analysis Experiments
The analysis of experimental designs already can be performed in R using some specific packages. First of all, we have the basic package stats, that contains standard (general) functions for analyzing data from designed experiments, such as lm() and aov(). Package stats also has a few functions for get and set contrast matrices, for multiple comparison and some convenience functions like model.tables(), replications() and plot.design() [9] . However, depending on the design and the complexity of the experiment, the analysis can be a hard task.
In this topic, we briefly describe some contributed packages for the same purpose.
AlgDesign: Algorithmic experimental Designs. According to [10] , with package ALgDesign we may evaluate a design, blocked or not, using eval.blockdesign() and eval.design() functions respectively. It also enables to generate a full factorial design using function gen.factorial() and create a candidate list of mixture variables with gen.mixture() function. This package also allows to block experimental designs using various criteria with function optBlock(), calculate an exact or approximate algorithmic design for one of three criteria (D, A and I), using Federov’s exchange algorithm (function optFederov()), and find a design using the specified criterion via Federov’s algorithm applied to a random subset of all possible candidate points (function optMonteCarlo()).
dae: Design and ANOVA of Experiments. The package dae [11] provides several tools on experimental design and R factors. It includes a group of functions that aid to generate experimental designs, as fac.nested() that can handle various nested structures and functions for combining several factors into one (function fac.combine()) or dividing one factor into several factors (function fac.divide()). It also includes functions that facilitate diagnostic checking after an aov, like function fitted.aovlist() that extracts the fitted values for all the fitted terms in the model and residuals.aovlist() that extracts the residuals in the analysis.
DoE.base: Package DoE.base [12] supplies mainly full factorial designs blocked or not and orthogonal arrays for (industrial) experiments. Some functions that allows such analysis are function fac.design() that creates full factorial designs with arbitrary numbers of levels, and potentially with blocking, and function oa.design() that access orthogonal arrays, allowing limited optimal allocation of columns.
experiment: Package experiment, according to [13] , offers some functions for designing and analysing randomized experiments. For instance, function randomize() allows to randomize the treatment assignment for complete randomized experiments, randomized-block experiments and matched-pair designs. Function ATEcluster() allows estimating various average treatment effect in cluster-randomized experiments without using pre-treatment covariates. Function CACEcluster() allows to estimate various complier average causal effect in cluster-randomized experiments without using pre-treatment covariates when unit-level noncompliance exists. Function NoncompLI() allows to estimate the average causal effects for randomized experiments with noncompliance and missing outcomes under the assumption of latent ignorability.
GAD: General ANOVA Designs. According to [14] , package GAD handles general balanced analysis of variance models with fixed/random effects and orthogonal/nested effects (the latter can only be random). It contains functions that perform a Cochran’s test of the null hypothesis that the largest variance in several sampled variances are the same (function C.test()), construct the mean squares estimates of an ANOVA design (function estimates()), considering the complications imposed by nested/orthogonal and fixed/random factors, fit a general ANOVA design (function gad()) and function snk.test() performs a SNK post-hoc test of means on the factors of a chosen term of the model.
3. Package Features
The package ExpDes [15] has as main objective the analysis of balanced experiments under fixed models. A special feature of this package is to allow the complete analysis in a single run. Its output summarizes what the researcher will need to interpret the most likely hypothesis to be evaluated.
ExpDes was created in 2009 and since then is used in classes at the Federal University of Alfenas, Brazil. During almost three years, its Portuguese and English versions were expanded, debugged and distributed on the website https://sites.google.com/site/ericbferreira/. Along 2011 it was released in Brazil. The first seminar took place at the Federal University of OuroPreto, Brazil.
The main purpose of the package ExpDes is to analyze simple experiments under completely randomized designs (crd()), randomized block designs (cbd()) and Latin square designs (latsd()). Also enables the analysis of treatments in a factorial design with 2 and 3 factors (fat2.crd(), fat3.crd(), fat2.rbd(), fat3.rbd()) and also the analysis of split-plot designs (split2.crd(), split2.rbd()).
Other functionality is analyzing experiments with one additional treatments on completely randomized design and randomized blocks design with 2 or 3 factors (fat2.ad.crd(), fat2.ad.rbd(), fat3.ad.crd() and fat3.ad.crd()).
After loading the package and reading and attaching the data, a single command is required to analyze any situation. For instance, consider a double factorial scheme under a completely randomized design plus an additional treatment:
fat2.ad.crd(factor1,factor2,repet, resp, respAd, quali=c(T,F), mcomp=”tukey”, fac.names=c(“F1”,”F2”), sigT=.05, sigF=.05)
Besides both factors (factor 1 and factor 2), repetitions (repet), response variable (resp) and response from the additional treatment (respAd), one must inform whether each factor is qualitative or not (quali), the desired multiple comparison test (mcomp)―to be used only for significant qualitative factors, the factor names to be used along the output report (fac.names) and the desired significance considered for the multiple comparison test (sigT, default is 5%) and F test (sigF, default is 5%).
The first information on the output is a legend of the factors followed by the conventional analysis of variance table (Figure 1).
Information on normality of residuals―according to the Shapiro-Wilk test [16] ―are provided for almost all designs. For the specific case of experiments with additional treatment, is also displayed the contrast between such treatment and the whole factorial (Figure 2).
Considering the pre-specified significance level, the functions consider the interactions significant or not, and analyse them or the single factors (Figure 3).
As illustrated in Figure 4, given the rejection of the null hypothesis, the comparison of the treatment means becomes necessary. For situations of qualitative treatments there are several options of multiple comparison tests available for the argument mcomp, such as Tukey (“tukey”, default), Scott-Knott (“sk”), Duncan (“Dun-
![]()
Figure 1. Legend and analysis variance table for a double factorial scheme under completely randomized design with an additional treatment.
![]()
Figure 2. Shapiro-Wilk normality test and contrast between the addition treat- ment and the whole factorial.
![]()
Figure 3. Analysis of the significant interaction.
![]()
Figure 4. Tukey’s multiple comparison test for qualitative factors.
can”), Student-Newman-Keuls (“snk”), Student’s t test (“lsd”), Bonferroni (“lsdb”) and a Bootstrap multiple comparison test (“ccboot”).
For comparison of quantitative treatments is available the routine of linear regression (by ordinary least squares) incorporated the analysis of variance. This routine fits polynomial models up to the third power, presenting individual analysis of variance and lack of fit (Figure 5).
The routines have certain autonomy because with only the information of the level of significance adopted by the researcher and the type of treatment the analysis will be performed automatically. Tests for the single factors or interactions are held only when necessary.
4. Final Remarks
Experimental Designs are meant to be a valuable package to help researchers analyze experimental data without a lot of work or complication. It is available for free and there is no intention to charge for its use, even after new features added to it.
The ExpDes package must be maintained and upgraded by the authors. For next steps, authors are concerned with homogeneity of variances tests, other multiple comparison tests, analysis of unbalanced experiments and the enhancement of the regression procedures.
Acknowledgements
Special acknowledgements to FAPEMIG for the financial support.