Imperceptible and Robust DWT-SVD-Based Digital Audio Watermarking Algorithm ()
1. Introduction
In the last years, the necessity for copyright protection of digitized media (audio, image, and video) has arisen. There are some traditional techniques used for copyright protection such as cryptography [1] -[3] . Cryptography protects the content during the transmission but as soon as the data is decrypted, it is impossible to track its reproduction or retransmission [4] . In a nutshell, conventional cryptographic systems provide a little production against data piracy [3] [4] . Due to the wide growth of the Internet and spreading many recording applications that do not take into account the copyright protection, the digital watermarking comes as a complement to cryptographic processes that enforces intellectual property rights and protects digital media from tampering [5] -[14] . In digital watermarking, the media producers are capable of embedding a sideband data into the source content which can be of any media type like text, audio, pictures, or video [15] -[19] . Interestingly, this watermark (embedded data) will remain present in the source content even after decryption process [20] -[26] . However, there are many techniques proposed for watermarking audio, image, and video which are extensively discussed in the literature [27] -[37] . On the other hand, there are many applications use digital watermarking, out of which copyright protection, fingerprinting, tamper proofing, medical image watermarking, broadcast monitoring, indexing, as well as bank monitoring systems [3] [4] . As a matter of fact, most of these applications require the watermarking algorithms to be resistant against attacks and signal processing modifications [7] [8] .
In the context of this work, the phrase “digital watermarking” refers to “invisible audio watermarking” in which the watermark is hidden within an audio file [2] -[4] . It is considered as immature digital watermarking as the human auditory system is more sensitive than the human visual system (image and video watermarking) [4] - [6] . Additionally, the amount of hidden data in audio watermarking is lower than that in video watermarking [7] - [9] . It is noteworthy to mention that there are many attacks which can severely affect the image and video watermarks but cannot do so in audio watermarks [7] . Therefore, audio watermarking becomes of a great interest as far as intellectual property rights are concerned, particularly protection against online music piracy and content identification [8] . Usually, any efficient audio watermarking technique must fulfill certain properties or objectives where the most important are: robustness, imperceptibility, and complexity [4] [20] -[23] . Robustness refers to the case where the watermark is retained in the source content despite several stages of processing [18] [19] . Imperceptibility ensures that the quality of the host signal is not perceivably distorted [24] -[26] . Lastly, complexity appertains to the amount of effort and time required for watermark embedding and extraction techniques [3] [8] .
1.1. Previous Works
There are many related works that are relevant to the theme of this paper [28] -[30] [32] [38] -[42] . The authors in [28] proposed a secure digital watermarking algorithm. They constructed the watermark as an independent and identically distributed Gaussian random vector by inserting it in a spread-spectrum. After that, they added the watermark to the image by modifying the largest 1000 coefficients. This algorithm is robust to signal processing operations (such as lossy compression) and geometric transformations (such as rotation). In [29] and for the sake of addressing the data-hiding process, the authors explored both traditional and novel techniques like echo data hiding, phase coding, and least significant bit (LSB) coding considering three applications: copyright protection, tamper proofing, and augmentation data embedding. In [30] , the author incorporated the DC-level shifting me- thod with their audio watermarking algorithm. In order to indicate the watermark bits 0 or 1, they shifted the DC levels of the audio signal frames to positive or negative. They correctly extracted the watermark bits from the watermarked audio signal without using the original audio signal.
The authors in [32] proposed an audio watermarking algorithm that exploits the masking phenomena of the human auditory system to guarantee that the embedded watermark is imperceptible. This is performed by break- ing each audio clip into smaller segments and then adding a perceptually shaped pseudo-random sequence. However, the authors in [38] introduced a new watermark embedding algorithm that combines both frequency hopping spread spectrum and frequency masking techniques. They evaluated their audio watermarking algorithm with respect to imperceptibility and robustness. They experimentally concluded that their proposed algorithm is robust to MP3 compression.
The authors in [39] proposed an imperceptible and robust audio watermarking algorithm through cascading two powerful transforms: Discrete Wavelet Transform (DWT) and the Singular Value Decomposition (SVD) as follows: they used first a four-level DWT and then applied SVD in which the obtained S matrix is used for embedding the bits of binary-image (watermark). In the matrix formation, the details D sub-bands are duplicated in the DC matrix produced. Additionally, they used the value of 0.2 for watermark intensity. They evaluated their audio watermarking algorithm with respect to imperceptibility and robustness considering both pop music and speech audio signals. In [40] , the authors improved the audio watermarking algorithm proposed by [39] through using only a two-level DWT. They embedded their watermark bits in the generated DWT coefficients. Authors in [41] enhanced the digital audio watermarking algorithm proposed by [39] through embedding the owner’s thumbprint as a watermark image in order to prove the ownership. Moreover, they minimized the period of the original audio signal by reducing the number of watermark bits through using cryptographic hash function which mainly generates and embeds the digest of the thumbprint watermark instead of its image. In [42] , the authors ameliorated the audio watermarking algorithms proposed by [39] - [41] through incorporating a new audio signal framing (i.e., taking one frame and skipping the other 29 frames). Moreover, they proposed a new DWT matrix formation to reduce the D components which are repeated several times in the matrix formation produced in [39] - [41] .
1.2. Our Approach
In this paper, we seek to improve the imperceptibility and robustness obtained by currently proposed audio watermarking algorithms. In other words, we propose in this paper very efficient watermarking embedding and extraction techniques that mainly take advantage of DWT and SVD. In these techniques, a new matrix formulation of details sub-bands is proposed in which the redundancy among its elements is totally disappeared. Furthermore, many experiments were conducted to study the affect of employing multiple levels of DWT and different watermark intensities on the imperceptibility and robustness utilizing the proposed matrix formation. We eventually conclude that the use of two-level DWT and 0.1 for watermark intensity utilizing the proposed matrix formation outperform many relevant watermarking algorithms with reference to imperceptibility and robustness performance objectives considering different audio files and lengths of watermarks. Moreover, we amalgamate the code assignment method to further improve the imperceptibility.
1.3. Organization
The remainder of this paper is organized as follows. Section 2 shows the proposed algorithm in which the embedding and extraction techniques are extensively demonstrated. Performance evaluation is provided in Section 3. Our experimental results along with necessary discussions are presented in Section 4. Finally, the conclusion of this work is discussed in Section 5.
2. The Proposed Algorithm
Our proposed algorithm adopts combination of two powerful transforms, namely, DWT, which is a novel discipline capable of giving a time-frequency representation of any given signal [43] , and SVD, which is a numerical technique applied after DWT [39] . We illustrate the algorithm by providing two techniques that belong to watermark embedding and extraction, respectively, as follows:
2.1. Watermark Embedding Technique
Figure 1 shows the major steps performed to develop our proposed watermark embedding technique.
The bullet points, illustrated below, explain in details our watermark embedding approach:
● We sample the original audio signal using a sampling frequency of 44,100 samples per second. After that,
![]()
Figure 1. Watermark embedding technique.
we partition it into frames where each frame consists of 50,000 samples.
● On each frame, we perform a two-level DWT transformation. Consequently, three multi-resolution sub- bands: D1, D2 and A2 are produced. The details sub-bands are annotated by D1 and D2 while the approximation sub-band is symbolized by A2.
● A new matrix formulation of details D sub-bands is used as shown in Figure 2. The matrix is of size 2x (length_of_each_frame/2) and called DZ matrix.
● We apply SVD to decompose the DZ matrix. Consequently, three orthonomal matrices S, U and VT are generated. Due to using two-level DWT, the S will be a 2 × 2 diagonal matrix as follows:
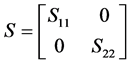 (1)
(1)
where S11 is used for embedding and S22 does not change.
● In the watermark formation shown at the rightmost side of Figure 1, our binary-image is converted into one- dimensional vector V where its length is p × k (image size) such that:
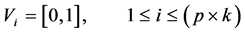 (2)
(2)
● We embed the bits of our converted binary-image into the DWT-SVD-transformed audio signal using the following function:
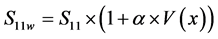 (3)
(3)
where S11w is the watermarked S11, α is the watermark intensity, and 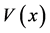 is the watermark bit which accepts only the values of 0 and 1.
is the watermark bit which accepts only the values of 0 and 1.
● Finally, we apply the inverse SVD and DWT to obtain the watermarked audio signal.
Procedure 1 describes the pseudocode of implementing the watermark embedding technique that is mainly used to embed a binary-image in the left and right channels of the stereo signal.
![]()
![]()
Figure 2. Matrix formulation of details D sub-bands.
2.2. Watermark Extraction Technique
In watermark extraction technique and in order to obtain our binary-image, we need to have the watermarked audio signal and singular values for each frame of the original audio signal. Figure 3 describes the major steps required to develop this technique.
The main operations of this approach can be summarized as follows:
● We sample the watermarked audio signal using the same sampling frequency used in the embedding and then we partition it into frames while each frame consists of 50,000 samples.
● On each frame, we perform a two-level DWT transformation.
● We arrange the two details sub-bands D1 and D2 into a matrix form as shown in Figure 2.
● SVD is applied to get the binary-image by comparing the obtained singular values with the other corresponding original singular values as shown below (given 0.1 for watermark intensity):
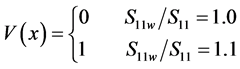 (4)
(4)
Details about choosing the value of 0.1 for watermark intensity will be provided shortly.
● Finally, we construct the original binary-image by re-forming the extracted bits.
Procedure 2 shows the pseudocode required for implementing the watermark extraction technique.
![]()
3. Performance EvaluationThere are two popular and effective metrics used to evaluate the performance of audio watermarking algorithms, these are, imperceptibility and robustness [38] - [42] [44] [45] .
![]()
Figure 3. Watermark extraction technique.
3.1. Imperceptibility (Inaudibility)
A digital watermark can be called imperceptible or perceptible. It is called imperceptible if the original audio signal and watermarked audio signal are perceptually indistinguishable. On the other side, a digital watermark is called perceptible if its presence in the watermarked audio signal is observed [46] - [48] . To evaluate the imperceptibility of our algorithm, we use signal-to-noise ratio (SNR) as an objective measure and mean opinion score (MOS) as a subjective measure as follows [49] :
 (5)
(5)
where A is the original pop signal and A' is the watermarked pop signal. It is worth mentioning that higher values of SNR indicate that the signal is more imperceptible. However, MOS is usually measured by having many people listen to a pair of original and watermarked audio signals for many times in which a grade of range (1 - 5) (as shown in Table 1) is provided for that pair [49] - [51] . The average grade of each pair considering all listeners provides the MOS grade.
3.2. Robustness
According to its resistance to transformations, a digital watermark can be called fragile, semi-fragile, or robust [52] [53] . To evaluate the robustness of our algorithm, we used a set of attacks, which affect audio signals, adopted from Stirmark® watermarking benchmark (such as Add, Filter, and Modification attacks) [54] and Adobe® Audition® software (like Echo and MP3 attacks) [55] . However, to find the difference between the original image and extracted image after being affected by aforementioned attacks, we used the correlation factor ρ that has a range of (0 - 1) in which 0 and 1 represent random and perfect linear relationships, respectively. It is found as follows [40] :
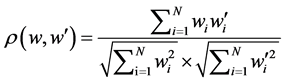 (6)
(6)
where N is the number of pixels in a watermark, 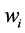 is the original watermark bit, and
is the original watermark bit, and 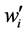 is the extracted watermark bit.
is the extracted watermark bit.
4. Results and Discussion
We use .WAV pop music file of length 600,000 samples (13.5 seconds). The .WAV music signal is a stereo- type, thus, we embed our watermark, which is a binary-image, in the left and right channels. Figure 4 shows the original audio signal before embedding while Figure 5 shows the watermark which is of length 4 × 6 pixels.
![]()
Figure 5. The watermark which represents a binary image.
Figure 6 shows the watermarked audio signal. It is interesting to notice that the original and watermarked audio signals are indistinguishable which indicates that the watermarked audio signal is imperceptible. The little difference between them is as a result of embedding the watermark bits into the DWT-SVD-transformed audio signal as described in Equation (3).
Figure 7 shows the results of SNR versus watermark intensity (α) when employing a four-level DWT. The increase in the SNR as the watermark intensity decreases is noticed. As α decreases, the difference between S11w and S11, described in Equation (3), decreases as well. Therefore, the denominator of Equation (5) (i.e.,![]() ) decreases which leads to increasing the SNR.
) decreases which leads to increasing the SNR.
It is shown in Figure 8 that the SNR dreareses as the employed number of DWT levels increases considering the watermark intenstiy 0.1. It brings the attention that the SNR peaks the others when employing a two-level DWT (i.e., SNR = 36.4063). As a matter of fact, this can be justified as follows: when applying the SVD on a five-level DWT, the S matrix will be of size 5 × 5 as the following:
![]()
Figure 7. SNR versus watermark intensity.
![]()
Figure 8. SNR versus the use of a matrix of details D sub-bands utilizing different levels of DWT (1 - 5 levels).
![]() (7)
(7)
Accordingly, the original singular values will be kept except S11 that will be used for embedding. On the other hand, when applying SVD on a four-level DWT, S55 will not exist. Similarly, when applying a two-level DWT, S33, S44, and S55 will not exist. Consequently, the amount of data used is decreased, causing an increase in SNR. Unlike the others, applying SVD on one-level DWT leads to having a matrix of just one element S11, which will be changed due to embedding. As a result, the generated matrix is totally new which undoubtedly ends in obtaining the worst SNR. To further prove the efficiency and imperceptibility of our proposed algortihm, the obtianed MOS value for the pair of original and watermarked signals, when being averaged for a period of 10 times considering 5 listeners and watermark intensity 0.1, is 5.
Table 2 shows ρ for different values of α. It is interesting to notice that all ρ values are the same as long as the watermark intensity falls between 0.4 and 0.1. Once the watermark intensity dips below 0.1, the ρ values get worse. Referring to Figure 8, the best SNR is obtained after operating 0.1 for watermark intensity and applying SVD on a two-level DWT, considering the matrix formation discussed in Figure 2. Therefore, we conclude that the optimum combination to acquire the highest imperceptibility and robustness is by employing 0.1 for α and a two-level DWT with no redundant details sub-bands. To visually realize their contributions, Figure 9 shows the extracted watermarks along with their corresponding ρ values after applying different attacks, utilizing α = 0.1 and a two-level matrix formation.
In order to strengthen the quality of the watermarked audio signal, we use the concept of code assignment which is briefed by breaking or segmenting the watermark bits into frames of length 2-bit and then assigning new codes for frames in which the bit “1” appears only once per frame. Table 3 shows the code assignment using 4-bit assigned code. Figure 10 shows SNR versus different lengths of assigned code. Starting from 3-bit assigned code, increasing the length of assigned code has a negative impact on the SNR. This is expected due to increasing the number of frames required to transmit the binary-image which in turn brings on increasing the denominator of Equation (5) that consequently gives rise to decreasing the SNR. It attracts the attention that using 3-bit assigned code improves the SNR better than all larger lengths and a smaller length (i.e., 2-bit) which refers to the case of excluding the code assignment (normal case). This indicates that optimizing the code assignment method enhances the SNR significantly.
Table 4 shows the comparisons made with prior relevant works considering SNR and MOS performance metrics. The contributions of our proposed algorithm are very impressive and leading the light.
![]()
Table 2. ρ for different values of α.
![]()
Table 3. Code assignment using 4-bit assigned code.
![]()
Table 4. Comparison with prior works.
![]()
Figure 9. Extracted watermarks considering various attacks.
![]()
Figure 10. SNR versus different assigned code lengths.
5. Conclusion
Due to the wide proliferation of digital media, e.g., audio, video, and images as a result of having efficient distribution, reproduction, and manipulation, new challenges belong to copyright enforcement arise. As far as the cryptography is concerned, the media will be no longer protected as soon as the encrypted data is decrypted. Unlike encryption, in digital watermarking, the watermark is designed to permanently reside in the host media. Although watermarking schemes focus on image and video copyright protection has received a great deal of attention recently in the literature, the use of audio watermarking still of a great interest as the opportunity of achieving higher robustness is possible. In this paper, we proposed new audio watermarking embedding and extraction procedures in which not only the DWT and SVD are used, but also a new matrix formation of details sub-bands which is characterized of being redundancy-free is proposed. Furthermore, optimization is performed among all steps available in our procedures to maximize the imperceptibility and robustness performance objectives. Our results are so promising and assuredly outperform those obtained from appurtenant former works.
Acknowledgements
The author would like to thank the student, Zeina N. Shammout, who has helped in implementing the proposed algorithm and making this work possible.