Comparative Study of Different Representations in Genetic Algorithms for Job Shop Scheduling Problem ()
1. Introduction
Scheduling is a decision-making process which deals with allocation of resources to tasks over given time-periods and its goal is to optimize one or more objective functions. A scheduling problem is represented by triplet α/β/γ. α field describes machine environment; β field provides details of processing characteristics and constraints and γ field describes the objective function to be minimized. Being essentially a combinatorial optimization problem, job shop scheduling has caught the attention of researchers in the last so many years for optimized performance. Combinatorial optimization problems can be classified as easy and hard. Problems which are polynomialy solvable with limited number of variables are treated easy and are called P. The notion polynomial solvable depends on the type of encoding. It is assumed that problems describing numerical data are binary encoded and the number of steps involved in solving these increases exponentially with increase in length of string and hence computational time will be enormously large and treated to be hard problems. Job scheduling problems belong to this category and are termed NP-Hard [1] . In the practical manufacturing environment, the scale of job shops is generally much larger than that of JSSP bench mark instances considered in theoretical research. Optimization algorithms for job shop scheduling usually proceed by Branch and Bound and among the most recent and successful, ones are those of Carlier and Pinson (1989) and Applegate and Cook (1991) [2] . Approximation procedures or heuristics were initially developed on the basis of priority rules or dispatching rules. The quality of solutions generated by these procedures leave plenty of room for improvement (1998) [3] . Therefore, traditional or meta-heuristic algorithms can hardly be able to solve such problems satisfactorily. In manufacturing workshops, availability of computational resources is much less than the laboratories which lead to difficulty in exploring all possible feasible solutions. Under such circumstances, it is reasonable to reduce the search space and range to only promising areas. The very idea of using constructive heuristics and heuristic search algorithms for larger problem sizes of JSSP is the computational expensive nature of enumerative techniques and Lagranngian algorithms. According to Osman (1996), a heuristic search “is an iterative generation process which guides a subordinate heuristic by combining intelligently different concepts for exploring and exploiting the search spaces”.
Extensive use of genetic algorithms to solve job shop scheduling problems can be seen through literature survey [4] . However, how effectively genetic algorithms can be used in JSSP case is not completely explored. In this context, some direction is provided by Tamer F. Abdelmaguid [5] in his paper. Ga’s are based on an abstract model of natural evolution, such that quality of individuals builds to the highest level compatible with the environment (constraints of the problem). (Holland, 1975; Goldberg, 1989)
Representations in GA environment applied so far in job shop scheduling can be classified into nine categories as given by Cheng et al. (1996):
1) Operation based 2) Job based 3) Job pair relation based 4) Completion time based 5) Random keys 6) Preference list based 7) Priority rule based 8) Disjunctive graph based. 9) Machine based.
Nine categories mentioned above can be grouped into two basic encoding approaches—direct and indirect encoding. In direct approach, a Πj schedule is encoded as a chromosome and genetic operators are used to evolve better individual ones. Categories 1 to 5 are examples of this category. In case of indirect approach, a sequence of decision preferences will be encoded into a chromosome. In this, encoding, genetic operators are applied to improve the ordering of various preferences and a Πj schedule is then generated from the sequence of preferences. Categories 6 to 9 are examples of this category [6] . These representations need to be studied in case of job shop scheduling problems to compare their performance criteria to generate optimal or near optimal solutions, even though computational comparison of different representations is reported in a tutorial paper by Cheng, Gen and Tsujimura [6] . A report by Anderson, Glass and Potts [7] , conducted with different metaheuristics approaches including four different GA implementations, lacks in consistency as well as coherence as regards number of test problems being tested with requisite number of runs.
The rest of this paper is organized as follows: We will start with mathematical models with certain assumptions that have been used in next section followed by the literature review on the different GA representations used in the case of JSP. Followed by review of GA representations, we will discuss regarding different GA operators frequently used by researchers and our own views on adding other operators not discussed so far. Now, we will analyze the experimental results conducted followed by the conclusion provided in the final part of this paper.
2. Problem Formulation
Since it is an important practical problem, some authors have formulated various JSP models based on different production situations and problem assumptions. The most common assumptions in case of JSP are:
1) A machine may process more than one job at a time;
2) No job may be processed by more than one machine at a time;
3) The sequence of machines which a job visits is completely specified and has a linear precedence structure;
4) Processing times are known. All the processing times are assumed to be integers;
5) Each job must be processed on each machine only once. There is no recirculation;
6) Set-up times are assumed zero;
7) Pre-emption is not allowed.
Let “J” represent a set of jobs and each job will be processed on a set of machines in a particular order. Let I = (1…..v) represent the operation indexes. The operation indexes are assigned such that for a job , the subset of consecutive indexes
, the subset of consecutive indexes , is a subset containing indexes for that job. Now from the subset Ik depending on the priority operation with higher or lower value is processed first. Let pi be the processing time of ith operation, the job which it belongs to is j(i) and the machine on which ith operation carried is m(i).
, is a subset containing indexes for that job. Now from the subset Ik depending on the priority operation with higher or lower value is processed first. Let pi be the processing time of ith operation, the job which it belongs to is j(i) and the machine on which ith operation carried is m(i).
Now the objective of scheduling process is to determine the start time sti of an operation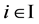 . While assigning a job to a machine based on above calculations following constraints should be taken into consideration viz. The technological constraints will take care of order of operations to be carried out on a job and a second set of constraint will take care of conflict of two jobs to be processed on the same machine simultaneously. Accordingly:
. While assigning a job to a machine based on above calculations following constraints should be taken into consideration viz. The technological constraints will take care of order of operations to be carried out on a job and a second set of constraint will take care of conflict of two jobs to be processed on the same machine simultaneously. Accordingly:
 (1)
(1)
and
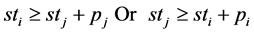 (2)
(2)
Is the equation to satisfy the conflict of two jobs on the same machine at the same time.
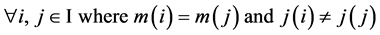
Different total cost functions that can be studied are
 …Is called Bottleneck objective and
…Is called Bottleneck objective and
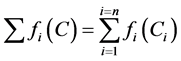 … Is called Sum Objective.
… Is called Sum Objective.
The most common objective functions are the make span max  and total flow time
and total flow time
 , and weighted (total) flow time
, and weighted (total) flow time . We have considered the minimization of make span as our objective function. Mannes’ [8] proposed an integer linear programming model (ILP) which uses different forms of binary variables. This model has gained larger interest in the research community due to small number of variables considered in the model. The technological constraints of Equation (1) are analogous to a series of consecutive activities that are carried out in project scheduling. This analogy has motivated importing project networks into JSP environment. To represent disjunctive constraints as in Equation (2), additional sets of arcs required. This is achieved in a disjunctive graph model [9] and PIAN model [10] .
. We have considered the minimization of make span as our objective function. Mannes’ [8] proposed an integer linear programming model (ILP) which uses different forms of binary variables. This model has gained larger interest in the research community due to small number of variables considered in the model. The technological constraints of Equation (1) are analogous to a series of consecutive activities that are carried out in project scheduling. This analogy has motivated importing project networks into JSP environment. To represent disjunctive constraints as in Equation (2), additional sets of arcs required. This is achieved in a disjunctive graph model [9] and PIAN model [10] .
In the disjunctive graph model, a disjunctive arc is defined between a pair of operations that share the machine. Each disjunctive arc is assigned a binary decision variable such that selection on the value that variable defines the length and direction of each disjunctive arc. This is to the Mannes’ model. Very efficient algorithms like immediate selections and shifting bottleneck heuristics were proposed by Carlier [11] and Adams [12] and Lars Monch [13] , which are derived from disjunctive graph model.
A variable notation of the type
 = 1…if operation ‘i’ is processed on machine ‘m’ in unit time ‘t’
= 1…if operation ‘i’ is processed on machine ‘m’ in unit time ‘t’
= 0...otherwise.
In ILP model was proposed by Bowman [14] . Wagner [15] proposed a model where a variable notation of the type: 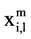 = 1…if operation ‘i’ takes ‘ith’ position in the processing sequence on machine ‘m’
= 1…if operation ‘i’ takes ‘ith’ position in the processing sequence on machine ‘m’
= 0...otherwise.
And. Mannes’ [8] proposed a model where a variable notation of the type: 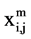 = 1…if operation ‘i’ is processed prior to operation ‘j’ on machine m.
= 1…if operation ‘i’ is processed prior to operation ‘j’ on machine m.
= 0...otherwise.
3. Representation of the Problem in GA and GA Operators
Darwin’s principle “survival of the fittest” can be used as a starting point in introducing evolutionary computation. The problems of chaos, chance, non linear interactivities and temporality being solved by biological species are proved to be in equivalence with classic method of optimization [15] .
Evolutionary computations techniques that contain algorithms based on evolutionary principles are used to search for an optimal or best possible solution for a given problem. In a search algorithm, number of possible solutions is available and the task is to find the best possible solution in a fixed amount of time. Traditional search algorithms randomly search (e.g. random walk) or heuristically search (e.g. gradient descent), explore one solution at a time in the search space to find best possible or optimal solution, which is computationally inefficient as the search space grows in size. Whereas evolutionary algorithms from such traditional algorithms are population based. Evolutionary algorithm performs a directed efficient search by adaptation of successive generations of a larger number of individuals. Genetic Algorithms is one such evolutionary algorithm in finding an optimal or near optimal solution to a problem. In a traditional genetic algorithm, the representation is bit length string. Its approach is to generate a set of random solutions from the existing solutions, so that there is an improvement in the quality of solutions throughout the generations. This implementation is achieved through main GA operators’ viz. random selection of two solutions from individuals in the parent generation; performing crossover operation on these two solutions to generate two new child solutions. Crossover operation is performed by exchanging specific elements of the two solutions selected; and mutation operation is conducted on child solutions to further explore the search space for better solutions. Different variations in simple GA approach can be found in literature survey to improve its search capabilities [16] . Representation of solutions of an optimization problem is to be done in a suitable format in GA to deal with reproduction and mutation operators. This format or structure referred as genotype, needs to be easily interpretable to a solution of the problem under study. In a combinatorial optimization problem, representation of a solution in GA is difficult as well as a challenging task. These are problems containing discrete decision variables and are interrelated by logical relationships. As a result, different mathematical models may exist for the same combinatorial optimization problem and this may lead to different representations for the same problem.
As explained above Cheng, Gen and Tsujimura [6] in their paper representation of JSP in GA into direct and indirect type. Further to that, T. F. Abdelmaguid [17] in his paper classified GA representations into Model based and Algorithm based. In our opinion, all representations are algorithm based though they appear to be model based.
In Priority Rule Based (PR) representation, a chromosome is represented as a string of (n − 1) entries (p1, p2…pn) where n − 1 is the number of operations in the problem instance. An entry p1 represents a priority rule selected beforehand. Accordingly, a conflict in the ith iteration of Giffler and Thompson algorithm [18] should be resolved using priority rule represented by pi. It means an operation from the conflict set has to be selected by the pi ties are broken randomly. In GA domain, a best set of priority rules should be selected. Here simple crossover yields feasible schedules.
In Random Keys Representation (RK) was first proposed by Bean [19] . In this representation, each gene is represented with random numbers generated between 0 and 1. These random numbers in a given chromosome are sorted out and are replaced by integers and now the resulting order is the order of operations in a chromosome. This string is then interpreted into a feasible schedule. Any violation of precedence constraints can be corrected by a correction algorithm incorporated.
In Operation based representation, each gene represents an operation. A chromosome contains as many genes as the number of operations. For example, an nx m JSP there will be nxm genes in the chromosome. Beirwirth proposed a technique “permutation with repetition” [20] which is similar to operation based representation. Fang [21] also proposed a kind operation based representation where string contains nxm chunks which are large enough to hold the largest job number for the nxm JSP. Whereas Beirwirth used a special GOX crossover technique to generate feasible schedule, Fang used a special decoding approach to decode a chromosome into a valid schedule always.
The Preference List based representation (PL) uses a string of operations for each machine instead of a single string for all operations which is a direct representation of processing sequence decision variables. Quite often violation of constraints is encountered which can be overcome by repair algorithm.
In the Machine based representation, [21] the chromosome contains a string of length equal to the number of machines. The sequence of machines in the string is the order by which a machine is treated as a bottleneck machine in the shifting bottleneck algorithm [12] .
In the Job based representation [22] a chromosome is a string of length equal to the number of jobs in the problem under study. Using this representation, a simple algorithm can generate a feasible schedule given sequence of the jobs onto different machines.
4. Methodology
The reproduction and mutation operators applied to JSP model are generally adopted from Travelling Salesman Problem because of the similarity in representations. Reproduction operators are generally required in GA to conduct the neighborhood search and a mutation operator generally ensures that the solution is not trapped in local minima. The design of both operators is crucial for the success of GA. Among the reproduction operators reported in the literature, PMX (partially matched crossover) [23] , OX (ordered crossover) [24] and uniform crossover [25] are extensively used in JSSP. PMX and OX crossover techniques use either single point or two point crossover. Different mutation operators used are swap mutation, inversion mutation and insertion or shift mutation reported in the literature [17] .
In general, the flow chart for GA can be represented as shown.
5. Results and Analysis
In our experiment, four representations are used viz. Operation based (OB), Job based (JB), Machine based (MB), Priority rule based (PR). All experiments are conducted with 50 generations and a population size of 1000. Mutation probability varies with 0.1 to 0.9 values dynamically and elite population size is 20%. Reproduction probability used in our experiment is 0.1 Parents in our experiment are selected from two groups sorted out based on fitness value (i.e. minimum make span). Each parent is selected from these groups probabilistically.
In our experimentation, GA is programmed with different reproduction and mutation operators’. Instead of selecting operators randomly as in [17] , we have built-in reproduction operators and are being used across the representations and the benchmark instances. The benchmark problems used in this paper are taken from OR library [26] available in World Wide Web. All the experiments are conducted with a Pentium-4 dual core processor with clock speed of 2.06 GHz and RAM of 512 Mbs. 68 benchmark instances are taken and in the single run, the best and average values are obtained and compared with lower bound or optimum value of the benchmark instance. Results are shown in Table 1. Different graphs generated are also shown below.

Table 1. Results of benchmark instances under different representations.
Continued
6. Conclusion & Future Scope
Figure 1 shows a plot of % deviations of different instances from the Lower Bound values or Optimum values vs. different representations in GA. It is clear that all representations, across the benchmark instances have shown nearly similar deviations. It is quite clear from the graph that Job Based representations have shown considerable lower peaks. This shows that with the use of proper local search technique it is possible to find the optimal solution.
Figure 2 and Figure 3 show a plot of average deviations of different representations. Except Machine based all other representations have shown the similar deviation. We conclude from this plot that Machine based representation performance is poor and Job based representation performance is better.
The evolution process over 50 generations for the benchmark instance ABZ 5 for instance has been shown in Figure 4 under different representations and convergence of CAR-07 under different representations is also shown in Figure 5. The convergence in case of JB and PR representation is comparatively better than other representations. Whereas JB starts with lesser initial value compared to PR, evolution is faster in case of PR than JB. However, JB could achieve the lowermost value which is why we intend to use this in our further studies. The present work is limited to performance study of different representations of JSP in GA only.
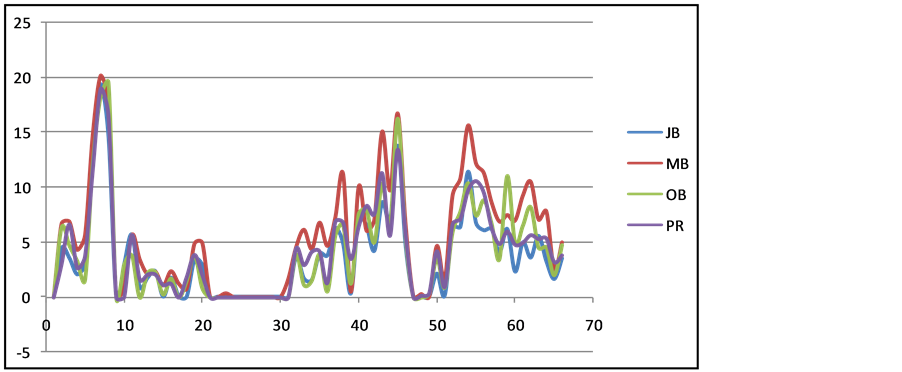
Figure 2. Deviations of different instances under different representations.
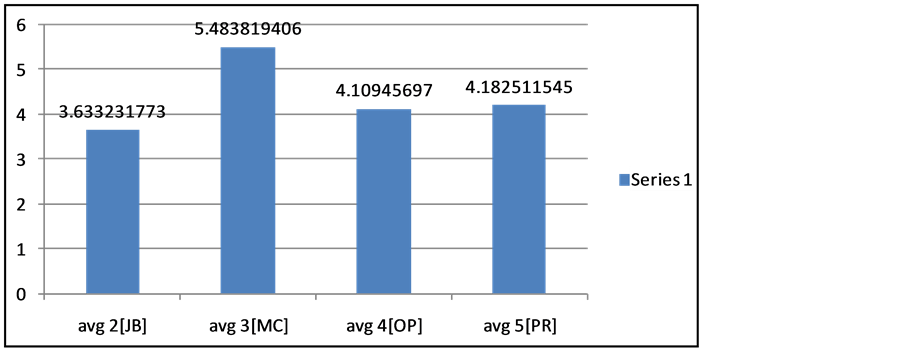
Figure 3. Avg. deviation vs. GA representations.
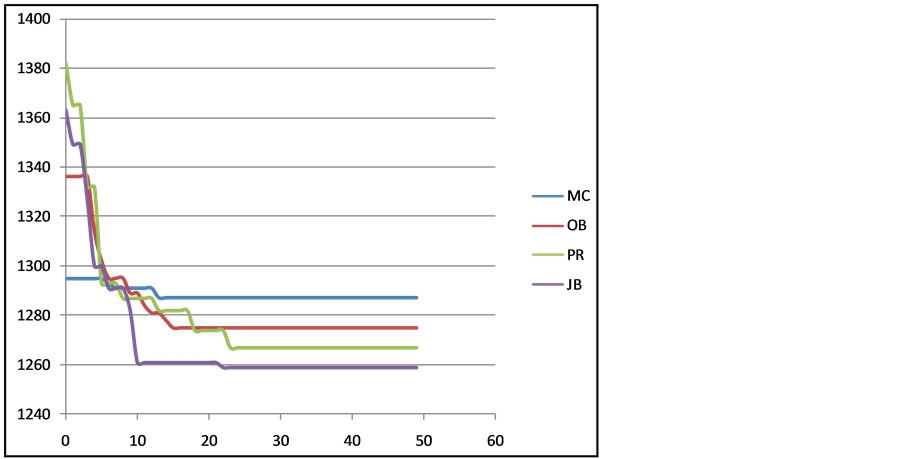
Figure 4. Evolution of ABZ5 under different representation.

Figure 5. Evolution of CAR-07 under different representations.
In our further study, we intend to use Job based representation In GA and with the aid of other techniques work to get optimum solutions in possible number of instances.
NOTES
*Corresponding author.