Cognitive Software Engineering: A Research Framework and Roadmap ()
1. Introduction
Software projects are known to run behind schedule. This is due to the complexity of the daily tasks assigned to the software engineers. The complexity emanates from many aspects. For example, the natural language, which is the main communication means, often introduces ambiguity in communication and requirements. The complexity of programs’ logic leads to defects and mistakes. The several design models which usually represent the same entity from different perspectives and at different abstraction levels make it difficult to understand the whole system structure and the flow of control and data between the different components of the software to build. The high number of risks, requirements, constraints, goals, design options, and implementation alternatives make it difficult to decide about priorities, mitigation plans, and technology and implementation options. The variable performance, mood, expectations, and social skills of the stakeholders and software team members create other problems that often lead to the poor productivity too.
All these difficulties are dealt with by the software team as cognitive agents. In this context, a two-fold research objective raises itself: reduce the cognitive burden for software engineers and make their cognitive tasks more efficient. Task automation is an obvious means for this aim. Task automation in Software Engineering exists and covers many activities of the software development process. The set of tools that are used are called Computer Aided Software Engineering (CASE) tools. However, as we will explain in Section 3, most of the current Software Engineering task automation does not apply on the human cognitive processes that software engineers employ in their daily duties. The objective of the present paper is to suggest a research framework and roadmap to bring more maturity to CASE tools in order for them to be cognitive, and for Software Engineering to become Cognitive Software Engineering. This leveraging principle of the present investigation marks out its research plan, which is centered around analyzing at which extent the current CASE tools fulfill the requirement of embodying the cognitive tasks of software engineers. As result of this analysis, the present article identifies the daily tasks and skills of software professionals, elaborates a maturity model of CASE tools, and suggests a metric to measure the cognitive gap that separates CASE tools and Software Engineering as a discipline from the objective of being cognitive.
Section 2 lists the Software Engineering tasks and skills. Section 3 presents a cognitive maturity model of CASE tools and elaborates a method to measure their maturity degree. Section 4 presents a research plan for Cognitive Software Engineering and analyzes its epistemological status. Section 5 concludes the article.
2. Software Engineering Tasks and Competencies
In order to be able to analyze CASE tools, we first need to establish a list of the Software Engineering daily tasks and competencies. For this aim, we considered two data sources. First, a set of emails and documents which have been used by the author of the present article during more than twelve years of software industry experience as developer, tester, architect, designer, team leader, project manager, and R & D director, have been analyzed in order to derive the set of Software Engineering tasks and competencies. The completeness of the derived list was then validated using the competency list of the Career Space. The latter is a European Union initiative, which gathered a consortium of eleven major IT and Telecommunication companies like BT, Cisco, IBM, Microsoft, Nokia, and Siemens. This consortium’s aim was to address the problem of IT professionals’ shortage in Europe. Among their objectives was the elaboration of a list of competencies. For that, the consortium first determined a set of professional job profiles and then determined the required set of competencies for every profile. The competencies of the Career Space are listed in [1] . Our list of competencies is presented in Table 1. As the reader may notice, the list does not contain general skills of project management or quality assurance. That is because the original list of the Career Space contains project management and quality assurance skills that are specific to IT and Software Engineering. This perfectly fits our objective in the present research. Another characteristic of the list of Table 1 is that the competencies are at a level of abstraction that is lower than the Career Space’s abstraction level. We chose this level of detail in order to be able to thoroughly analyze CASE tools based on these competencies.
3. Maturity of CASE Tools and Software Engineering
The essence of the software professionals’ cognitive work can be modeled as input-processing-output. Inputs are data or more complex artifacts. The engineer may need to cognitively process data or artifacts in order to prepare the suitable representation of inputs. We consider such a task as part of processing. For example, in order to detect inconsistencies in a set of requirements, the analyst may need to re-write the requirements in a given syntax before reasoning about inconsistencies. We consider rewriting and reasoning as a single cognitive task. We do not consider the manual entry of data of any kind as cognitive. Outputs can be data or artifacts, not processing of any kind, with variable complexity degrees. CASE tools are expected to either assist or autonomously perform processing. Based on this model, we identify four complexity levels of CASE tool operation, which we consider as maturity levels (ML) as well:
· ML-0 (non-automated): the engineer performs processing.
· ML-1 (assisted): the tool performs part of processing under control and monitoring of the engineer.
![]()
![]()
Table 1. Software engineering competencies.
· ML-2 (automated): the tool performs processing under control and monitoring of the engineer. In specific situations, the engineer may need to intervene or approve the tool’s decision.
· ML-3 (delegated): the tool autonomously performs processing with no control of the engineer. The latter may check the tool’s performance.
It is worth to note here that the literature reported a few other rating models of CASE tools, which are not relevant however, because they are not based on a cognitive perspective. In [2] , a rating model is elaborated based on the COCOMO effort multipliers. In [3] , a model is proposed to rate CASE tools according to how long they are available on the market.
Now that we identified maturity levels, we can analyze the maturity of the existing CASE tools. Table 2 contains 198 CASE tools, which were analyzed based on the maturity model. This list was obtained from [4] -[6] after excluding tools that are no longer available on the Web and those which are irrelevant. For every task in Table 1, the corresponding set of CASE tools of Table 2 has been identified. Then, the ML of the most mature among these tools was assigned to the task in Table 1 (third column). If there are more than one tool with the highest ML, the fourth column in Table 1 contains only one among them as example. Obviously, no CASE tool corresponds to ML-0. We could not, unfortunately, present the mapping between Table 1 and Table 2 because of the lack of space.
Considering ML-3 as the ideal level for cognitive CASE tools, the maturity degree (MD) of every set of competencies 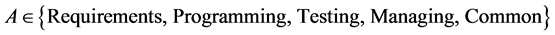 can be calculated using Table 1 and Equation (1):
can be calculated using Table 1 and Equation (1):
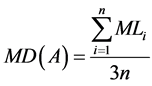 (1)
(1)
where n is the number of tasks and competencies under A, and MLi is the ML of the task or competency i. The cognitive gap can then be derived using Equation (2):
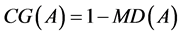 (2)
(2)
The MD and the CG of Software Engineering as whole discipline can be calculated in the same way by considering n as the number of all the tasks and competencies in Table 1. Table 3 contains the results. For example, 88% of the programming tools belong to ML-1 and 13% of the testing tools are at ML-2. Only 2% of all the CASE tools belong to ML-3 (last line in Table 3), and 6% of all the CASE tools are at ML-2. Requirement en-
gineering’s MD is 0.29. Software Engineering’s MD is 0.22 and its CG is 0.78. This means that Software Engineering is 78% far from being fully delegated, in the sense of the here proposed maturity model. The least cognitive gap is scored by programming (0.58) then design (0.67).
4. Towards a Cognitive Software Engineering
4.1. Research Plan
The research question for the future is: how to reduce the cognitive gap of Software Engineering to 0? In other
words: how to build a CASE tool for every competency in Table 1, which corresponds to ML-3? This research question raises another one about the scientific foundation of this endeavor: do CASE tools need to be cognitive systems? We conjecture that they do. This leads us to agree on the definition of cognitive systems because there is no single and widely adopted one. On the website of the European Network for the Advancement of Artificial Cognitive Systems (euCognition) [7] , the definition of cognition itself is considered as one among a list of scientific controversies in the field. Interestingly, the euCognition organized a survey on the definition of cognition systems. Thirty eight definitions from respondents were selected and made available on their website. One can easily distinguish between two kinds of definitions; let us call them high cognition and low cognition. High cognition definitions of cognitive systems give emphasis to higher processes like abstracting percepts, having self-awareness, and interacting with people exactly like human beings (believable characters). Low cognition definitions of cognitive systems are more pragmatic. For the current research, we adopt one of these definitions which we borrow from Jir Wiedermann: “an artificial cognitive system is [···] designed by people to realize a cognitive task. The aim of the design is to construct a system producing a behavior that is qualified by system’s designers as a reasonable behavior performing the task at hand. What is a cognitive task depends on the designers.” Based on this definition, Cognitive Software Engineering aims at building CASE tools as cognitive systems that successfully perform cognitive tasks of software professionals. The CASE tools’ aim is not to absolutely incarnate higher cognitive processes like perception and self-awareness. The only objective is to be effective. It is the responsibility of future research to verify whether cognitive CASE tools require higher cognitive abilities. This claim is not with no foundation, however. The research in cognitive systems itself did not completely solve the dilemma of whether a cognitive system must incarnate cognitive processes like emotion or suffice it to be effective for the targeted task [8] .
Based on this epistemological principle, we can now propose a research process for Cognitive Software Engineering:
· Identify the cognitive model of the task: which describes the required cognitive operations and skills along with the ontology, knowledge, information structures, rules, and work procedures, which are involved in accomplishing the target task.
· Design and Implement: how can tools assist engineers in performing the task? How can tools replace engineers in performing the task? (Re)design the tool and implement.
· Validate: observe and evaluate.
· Improve: if necessary, go to step 1.
In the second step of this research process, the researcher has to decide whether the research’s aim is ML-3 or a lower level. For the first step, identifying the cognitive model of the task, the researcher needs a reference cognitive model which contains the cognitive operations that might be involved in the studied task. For this aim, we here propose a modified version of Bloom’s cognitive model also known as Bloom’s taxonomy [9] , which is presented in Table 4. Our modification consists in adding the set of synthetic cognitive skills, which we derived during the analysis of the Software Engineering cognitive tasks in order to elaborate Table 1. They are synthetic because they employ other elementary skills (remembering, understanding, etc.). Here are short definitions of the main cognitive processes of Bloom’s taxonomy:
· Remember: retrieving knowledge from memory.
![]()
Table 4. Modified bloom’s taxonomy.
· Understand: meaning of oral, written, and graphic messages.
· Apply: using a given procedure for a given purpose.
· Analyze: breaking the whole into its parts and determining how the parts relate to each other and to the whole.
· Evaluate: judging based on criteria.
· Create: assembling parts together to create a new whole.
4.2. Preludes of Cognitive Software Engineering
A few CASE research works analyzed the human cognitive processes and tried to automate them. They can be considered as the preludes of Cognitive Software Engineering. Argo/UML [10] is a CASE tool that contains a set of concurrent threads called critics. The latter monitor the work of the UML designer and check the conformance to the UML diagrams with specified syntactical and semantic rules. If a critic detects a deviation from any of those rules, it advises the designer. Argo/UML corresponds to ML-1 because part of the cognitive design tasks is automated. What is interesting in Argo/UML is that it has been built after the analysis of the cognitive processes involved in design [10] . From the perspective of Table 4, the author of Argo/UML considered the following cognitive skills:
· Predicting: critics “know” that if the designer interrupts a design task, he/she will probably switch to an alternative design option because there might have been a blocking problem. In such a case, critics will try to help the designer pursue the initial task in order to avoid the costly mental context switching.
· Recalling: if the designer insists on switching to another design task, critics will record the current context in order for the designer to avoid forgetting incomplete sub-tasks or details.
· Classifying and inferring: critics suggest to the designer to switch to a task that needs minimal updates in the current mental context instead of tasks that need important mental changes.
· Recognizing and generating: critics recognize the fixation situations where the designer focuses too much on one design alternative. They then try to bring the attention to other alternatives.
[11] deals with the problem of program comprehension. A CASE tool is designed and prototyped based on an analysis of the cognitive processes involved in program comprehension. The program is presented to the developer in terms of a network whose nodes are software components. The developer can choose different levels of abstraction for the nodes. Compared with Table 4, here are the main cognitive skills automated by this work:
· Explaining: nodes that correspond to software components are annotated as they are created.
· Organizing: pieces of code are associated with corresponding nodes in the tree.
· Recalling and recognizing: the tool records the path that led to the current node.
4.3. Cognitive Software Engineering: Lakatosian or Kuhnian?
Cognitive Software Engineering brings a new research interest, which consists to consider the cognizant subjects, namely software professionals, instead of continuing to focus on the application of patterns: patterns of methodologies, processes, system models, programs, and artifacts. Highly influenced by Systems Engineering and Project Management, the focus on patterns tended so far to put the cognizant subject under the control of best practices, best patterns. This is clearly expressed in early definitions of Software Engineering. For example, [12] defines Software Engineering as “the disciplined development and evolution of software systems based upon a set of principles, technologies and processes.”
Let us try to epistemologically situate the here preached move from Software Engineering to Cognitive Software Engineering. The latter comes from the need to reduce the cognitive burden for software professionals. In the Kuhnian vision [13] , such a need may be considered as a crisis, which is favorable to the emergence of a new paradigm. The new paradigm then represents a discontinuity with the former paradigm. In the Lakatosian vision [13] , the need is not a real crisis, and the resulting move is characteristic of young scientific theories which did not find a dominating paradigm yet. Such a move preserves the continuity. Based on the Lakatosian epistemology, Software Engineering can be portrayed as consisting of a conceptual core and a conceptual belt. The conceptual core encompasses the set of disciplines (requirements, design, etc.), processes, patterns, models, tools, artifacts, metrics, and roles. A Lakatosian conceptual belt (also called: protective belt) is the set of auxiliary hypotheses. Software Engineering’s belt consists of the set of widely agreed knowledge, rules, and best practices; for example, the advantages of Object Oriented analysis and design, the de facto link between real- time systems and concurrent processes or threads, the benefits of using a configuration management or a bug tracking system, the advantages of code refactoring, etc. A problem shift in the sense of Lakatos is considered as a widening of the conceptual belt, which leads to the evolution of the research program without affecting its core.
We conjecture that Cognitive Software Engineering is a problem shift in the sense of Lakatos, not a new paradigm in the sense of Kuhn. In other words: it is a natural evolution, not a conceptual revolution. It is complementary to Software Engineering and represents a widening of the conceptual belt of Software Engineering through introducing the cognitive dimension as part of the scientific problematic.
5. Conclusion
The present article sketched a roadmap for the evolution of Software Engineering towards Cognitive Software Engineering, through integrating the cognitive dimension in the CASE research. As stated in Section 4.2, a very few research works tried to tailor CASE tools to the actual cognitive processes that are employed by software engineers during their daily tasks. As a direct consequence, at the best of our knowledge, there is no commercial CASE tool that fully performs software cognitive tasks. The evolution from the current CASE tools to cognitive ones constitutes the research object of Cognitive Software Engineering. The methodology of this evolution was the main motivation of the current article. A research framework has been proposed, which consists of: 1) a comprehensive list of Software Engineering tasks and skills; 2) a generic cognitive model and a research procedure to analyze software professionals’ needs, and design and implement cognitive CASE tools for them; and 3) a maturity model and a formal method to measure the maturity of CASE tools. As a result, the cognitive gap between the current Software Engineering and the targeted Cognitive Software Engineering was estimated to be 78%. This number cannot pretend to be accurate, however, because it highly depends on our analysis of 198 CASE tools, which cannot be mistake-free. An epistemological analysis of the relation between Cognitive Software Engineering and Software Engineering has also been performed. This analysis shows that Cognitive Software Engineering is a natural and Lakatosian evolution of Software Engineering, not a paradigm revolution in the sense of Kuhn.