1. Introduction
Stemming means finding the root or stem from the given inflected word. It is used in Natural Language processing, Information Retrieval, Text Mining etc. Mostly, stemming is used to improve the performance for NLP (Natural Language Processing). For example, if the word such as “उपरथिहरु” is used for NLP. Searching with this long string may degrade the performance, but if the stemming is done with this word i.e. रथि. Obviously, the performance is increased because we don’t need to search other unnecessary words.
Apart from the Natural Language Processing Task, the stemming plays a very important role in text mining task of computer science. In the process of stemming normally the input tokens are given the core engine which strips the inflected word leading to proper root which is used for better searching in search engine (Figure 1).
For stemming purpose, different algorithms are available in text mining purpose. They include rule based, machine learning based and statistical based algorithms.
The input and output of the data are given in Table 1 for the demonstration. The required output is given into second column whereas the word to be tested is given in the first column.
2. Literature Review
Several works have been performed in the field of stemming including German, Spanish, Indian and etc. Talking about Indian stemming which is more similar to Nepali

Table 1. Mapping of inflected word and stem/root.
stemming, have performed stemming work in their own different local languages like Tamil, Punjabi, Bengali, Gujarati, Hindi, Marathi etc. Similarly, Arabians have also performed such operation in their local language. Although many algorithms exists, they are mainly focused on their native language only.
[1] performed stemming approach in Arabic text. They used five methods. Of which four of these were positional letter ranking approach and fifth was traditional rule based system and found that rule based system performed well when combining with correction algorithm. Similarly, [2] used machine learning approach for stemming approach and it performed high accuracy. For performing such stemming approach they used different classifier like Naïve Bayesian, Bayesian Network, OneR, ZeroR and J148 algorithms. [3] used light stemmer with heuristic and co-occurrence of information retrieval approach. For handling co-occurrence they used clustering approach. [4] used different existing stemming algorithms and comparisons is made. They include Lovins, Porter Stemmer etc. [5] discussed about different stemming algorithms for English Language and a hybrid algorithm is made for Gujarati incorporating different algorithms. Some performed stemming of the Arabic text using Hidden Markov model [6] which gave more accuracy. Similarly [7] stemmed the Hindi Texts using hybrid approach. In this approach, they used the combination of brute force and suffix stripping approach which tries to remove the problem of over-stemming and under-stemming. The very preliminary phase of Hindi was Light Stemmer which was done by [8]. It is just a set few rules with the help of which stemming are done. Similarly, [9] uses stemming algorithms for Punjabi words which are based on the algorithms defined by [10,11]. It exploits brute force approach with few stripping strategy. It just matches the patterns and displays the root from the database. It the searching word is found, its respective stem is retrieved otherwise it just stems the affix and gives the output. [12] used stemming approach for text classification in Arabic language. For preprocessing the texts, they used stemming and performed classification. Similarly, [12-17] has done research on their different languages like Bengali, Punjabi etc. [18] performed research of different stemming algorithms. [19] explains stemming algorithms for Arabic language using parallel corpus and [20] has explained different stemming algorithms. [21-23] also performed different stemming approach for their own language like Nepali and Turkish.
3. Proposed Model
For explaining the proposed model, following things are taken into consideration: prefix, suffix and root.
3.1. Suffix
Suffix means those words that come after the root or stem. Around 150 suffixes are taken into consideration.
3.2. Prefix
These are the words that are added to the front part of the Nepali words. Around 35 words are taken.
3.3. Roots
Around 700 complex stem words are taken into consideration for research activity.
3.4. Hybrid Methodology
This algorithm is based on classical rule based stemming algorithms like [8]. It exploits the features of string similarity function of dynamic programming [23]. The complete flow of algorithm is given in Figure 2 below.
This algorithms in context free algorithm. i.e., it doesn’t care about the context of the word. It strips the words from the inflected word. For example, in this algorithm, after entering the inflected word the stripping operation is performed. Incremental stripping approach is
employed for suffix portion. But for prefix portion, it is not employed. For example, उपरथिहरुले = उप + रथि + हरु + ले. In this example, “हरु” and “ले” are two suffixes stripped through incremental approach and “उप” is prefix. Similarly, for prefix portion longest length stripping approach is followed. In this method, the longest size of the prefix is stripped although there may be presence of another affix. For example, अमान्छे = अ + मान्छे and अधिकरण = अधि + करण. In this example, “अ” and “अधि” both are prefix but priority is given to the prefix having longest size like “अधि” not “अ”.
As 0.50 was found to be the best threshold in [24], it is taken as the best threshold. After stripping the word, the words are compared with the roots stored in database using string similarity function which has used dynamic programming approach for comparing.
The output obtained from this stop is stripped word but in some time, the word may be over stripped or under stripped. In order to compensate the over stripped or under stripped words, the concept of string similarity approach is exploited.
4. Evaluation and Output
For the evaluation purpose, around 1200 complex words are taken as test keywords. It was implemented under Visual Studio 2008. Programming language was C#. For measuring the performance, precision and recall are used.
The comparison of the hybrid algorithms with traditional rule based algorithm is made. The output is listed in Table 2.
Similarly, the output of the stemming using traditional rule based system is listed in Table 3.
5. Conclusion and Limitation
After performing the research on stemming of Nepali Keywords, following conclusions are made:
• The recall of rule based system was 68.43 and the recall of Enhanced system was 72.1.
• The over stripping and under stripping are recovered by Enhanced System.
• Its context free nature is not handled.
• Few rules are applied.
• Incremental stripping of prefix is not allowed.
• Longest length stripping is not applied in suffix portion although it is applied in prefix portion.
• It can be compared with many other algorithms.
• The less number of words stored in corpus leads to wrong output so more number of words are necessary in corpus.
• Different thresholds for measuring the distance can be used.
• Different similarity measures can be used and compared.
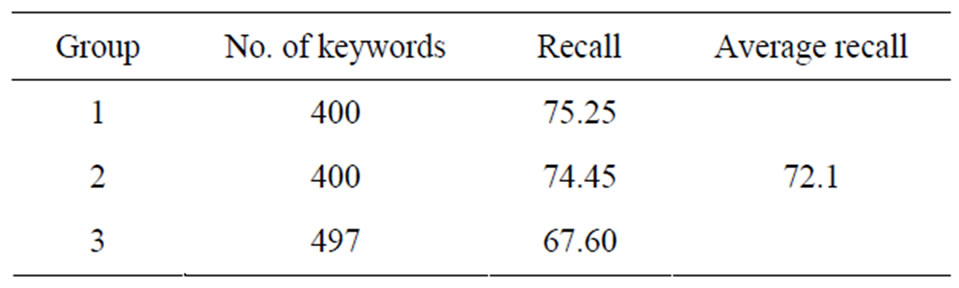
Table 2. Output of rule based system.

Table 3. Output of modified algorithms.
6. Acknowledgements
Thanks to Dr. Bipul Shyam Purkayastha from Assam University, India for providing me an implausible support. Similarly, special thanks go to Mr. Bikash Balam from Central Department of Computer Science and Information Technology, Tribhuvan University along with my students and colleagues for supporting me.