Adaptive Lossy Image Compression Based on Singular Value Decomposition ()
1. Introduction
Advances in digital imaging and video acquisition equipments, such as cameras, cell phones, and tablets, have enabled the generation of large volumes of data. Many applications use images and videos, such as medicine [1] , remote sensing [2] , microscopy [3] , surveillance and security [4] .
Adjacent pixels in images and videos usually have a high correlation, which leads to redundancy and demands high storage consumption. In order to reduce the space required and the transmission time of images and videos, several compression techniques have been proposed in the literature. These techniques explore data redundancies and are generally classified into two categories of compression methods: lossless and lossy.
In lossless compression methods, the original data can be completely recovered after the decompression process [4] , whereas, in lossy compression methods, certain less relevant information is discarded, such that the resulting image is different from the original image. Ideally, this loss should be tolerated by the receiver [4] .
As the main contribution of this work, we present and evaluate a lossy-based image compression method based on the singular value decomposition (SVD) technique [5] [6] . The originality of the method resides mainly in the choice of eigenvalues and the partitioning of the images in an adaptive way, as well as a detailed investigation in the use of the SVD for the image compression. Experiments show that the proposed method is able to achieve better results than those obtained with the direct application of SVD. In addition, new insights to the singular value decomposition-based compression method are provided.
This paper is organized as follows. Some relevant concepts and approaches related to the topic under investigation are briefly described in Section 2. The proposed method for image compression using singular value decomposition is presented in Section 3. The results are reported and discussed in Section 4. Final considerations are presented in Section 5.
2. Related Work
Compression techniques [7] - [16] play an important role in the storage and transmission of image data. Their main purpose is to represent an image in a very compact way, that is, through a small number of bits without losing the essential content of the information present in the image.
Image compression methods are generally categorized into lossless and lossy approaches [17] [18] [19] . In lossless compression, all information originally contained in the image is preserved after it is uncompressed. In lossy compression, only part of the original information is preserved when the images is uncompressed.
Image compression methods are based on reducing redundancies in the data representation. The redundancies present in images can be divided into three categories [4] [20] . The coding redundancy refers to the use of a number of bits greater than absolutely necessary to represent the intensities of the pixels of the image. The interpixel redundancy is associated with the relation or similarity of neighboring pixels. Finally, the psychovisual redundancy concerns the imperceptible details of the human visual system.
Some lossless compression methods that explore coding redundancy are Huffman coding [21] , Shannon-Fano coding [22] , arithmetic coding [23] and dictionary-based encoding such as LZ78 and LZW [24] . Run-length coding [25] , bit plane coding [26] and predictive coding [27] explore interpixel redundancy. Lossy compression methods, such as predictive coding by delta modulation (DM) [28] [29] or by differential pulse-code modulation (DPCM) [30] and transform coding [31] [32] , typically explore psychovisual redundancy.
A common transformation employed in image compression is the singular value decomposition (SVD). Waldemar et al. [33] proposed a hybrid system with Karhunen-Loéve (KL) vectors and SVD for image compression. Ranade et al. [34] performed permutations on the input image as a preprocessing, before applying the SVD. Rufai et al. [35] combined the SVD with wavelet difference reduction (WDR), in which the input image is first compressed using the SVD and then compressed again with the WDR.
In this work, we apply the use of singular value decomposition in image compression and analyze its use locally and with an optimal choice of eigenvalues.
3. Adaptive Image Compression
In this section, we present our adaptive image compression approach based on singular value decomposition, the image partitioning process and the compression evaluation metrics.
3.1. Image Compression
The diagram presented in Figure 1 presents the main steps of the image compression and decompression method proposed in this work. The compression algorithm has as input an image
and, as output, the compressed image represented by the singular value decomposition matrices in a binary file. The decompression algorithm has as input the binary file containing the decomposition matrices and, as output, an image
. The steps of the method are presented in detail as follows.
Initially, we calculate the singular value decomposition (SVD) for the entire image. The SVD of a real matrix
corresponds to the factorization
where U is a real unit matrix
,
is a diagonal rectangular matrix
with diagonal nonnegative real numbers and V is a real unit matrix
.
Since U and VT U are real unitary matrices, then
and
, where I is the identity matrix. Thus, U and VT are orthogonal matrices. The columns of U are the eigenvectors of the matrix
, the columns of V are the eigenvectors of the matrix
and the diagonal elements of the matrix
are the square roots of eigenvalues of
or
. The eigenvalues are arranged in the matrix
in descending order, that is, if
are the diagonal elements of
, then
. Then,
(1)
Using the entire SVD arrays, with
, would typically make SVD matrices larger than the original matrix. Since we are interested in lossy compression, some of the eigenvalues above a certain
can be discarded, decreasing the final size of the three matrices.
Considering that the
elements are sorted in descending order, the first terms
contribute more significantly to the summation. Thus, we determine the i value that optimizes
![]()
Figure 1. Main stages of the image compression and decompression process.
(2)
where
is the variance maintained by choosing the first i eigenvalues, calculated as
(3)
where
and
is the relative redundancy of data, which can be expressed as
(4)
The factor
is used to weight the two terms, calculated as
(5)
(6)
The adaptive choice of the i value is made by means of the optimization described previously and not by assigning a fixed minimum variance, as in many approaches of the literature [33] [34] . The motivation for this decision lies in the fact that we will consider a given eigenvalue if the cost to add it will compensate for the significance it carries, that is, adding the eigenvalue
would increase the number of bytes in the compressed image as opposed to improving the image quality.
In addition, other methods available in the literature [33] [34] do not consider or discuss the fact that the matrices generated by the SVD are real numbers (usually 64 bits), whereas an image is typically integer (8 bits), which makes the direct application of SVD unfeasible. Thus, we apply a rounding in the matrices obtained by the decomposition, so that we consider only the first three decimal places. This rounding can be expressed as
(7)
where h is the original value of the (real) matrix and f is the value obtained after rounding (integer). In this work, we consider
for two main reasons. First, this will cause us to have 3-digit numbers since the original values are in the range
, which is interesting because the linear transformation that will be applied considers the interval from 0 to 255. Thus, a lower degree of loss will be obtained by changing the range of numbers. In addition, using smaller values for d showed, empirically, a great loss of information, whereas using larger values did not show significant improvement. This rounding is not applied to the
matrix, since its value is not between 0 and 1.
Then, we apply a linear transformation that maps the original interval to the range 0 to 255 expressed as
(8)
where
and
are the minimum and maximum values of the matrix, respectively, whereas
and
are 0 and 255, respectively. The variable f represents the original value and g the value obtained after the transformation.
Then, the image is divided into four blocks of the same size, and the compression is recursively applied to each of the blocks. This division is performed until the image has a certain minimum size. A quadtree decomposition is formed from this process, where the inner nodes represent the divisions of the image and the leaf nodes represent the SVD matrices.
Figure 2(a) presents an example of a binary image of
pixels. White pixels have a value of 0, whereas black pixels have a value of 1. The rank of the matrix representing this image is
since no row or column is linearly dependent on the other. Figure 2(b) presents a partitioning, in which only pixels of the same intensity were kept together. The quadtree corresponding to the division performed is illustrated in Figure 2(c).
Since all regions have pixels of the same intensity, the rank of each region in Figure 2(b) is equal to
. Figure 2(d) presents an image where 4 pixels are black, but with another configuration. This image has rank
, which shows a dependence of the rank and, consequently, of the good performance of the SVD in relation to the image content.
![]()
Figure 2. Example of image partitioning using the quadtree decomposition.
The number of units (number of values) required to store the SVD matrices can be expressed as
(9)
where r is the rank, whereas p and n are the dimensions of the original image. The first term of the sum (r) corresponds to the diagonal matrix size
, whereas the other values correspond to the two other matrices U and V. Thus, the number of units needed to store the image shown in Figure 2(a) is given by
(10)
On the other hand, for the image after partitioning, illustrated in Figure 2(b), the number of units can be calculated as
(11)
We note that, for this division in the image, the number of units needed to store the SVD matrices has decreased. The amount of units needed to store SVD matrices with the division (considering all divisions with the same rank) is smaller than in the entire image, since
(12)
where
is the rank of the matrices after division and
is the rank of the original matrix.
In our method, we determine the best alternative, that is, whether the decomposition will be calculated in the entire image or in its four blocks, from the optimal value calculated with Equation (2). Thus, the block division will be chosen if
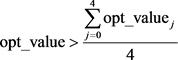 (13)
(13)
where opt_value is the optimal value for the entire image and 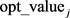 is the optimal value for the j-th block.
is the optimal value for the j-th block.
For color images, a decomposition is calculated separately for each color channel. Finally, having the necessary information, the compressed image is stored in a binary file. Figure 3 shows the protocol used to store the image, with header and data.
The binary file has at its beginning a global header, shown in Figure 3(a). In this header, three values are stored: the width (n) and height (p) of the image,
![]()
Figure 3. Image representation in a binary file.
and the number of channels (ch) of the image. They determine the size of each node in the tree, which is necessary to correctly retrieve the data in the decompression step.
The tree nodes are stored, as shown in Figure 3, having a local header and data. The first information in this header is the type of node: 1) internal or 2) leaf. For internal nodes, we do not have data, but four children. Thus, after an internal node, four other nodes are expected. For the leaf nodes, besides the node type, we have the rank value r, the minimum and maximum values of each of the matrices. Finally, we have the data for that particular node.
Given the compressed image, the file is read and the tree is reconstructed. For each SVD matrix, a linear transformation is applied in order to return it to the original interval. This is done by using Equation (8), where, in this case, 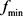 and
and 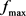 are 0 and 255 and
are 0 and 255 and 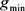 and
and 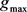 are the various minimums and maximums of the original matrix. Next, we apply a transformation inverse to that made in Equation (7) to retrieve the decimal values. Finally, the matrices are multiplied to obtain an uncompressed image.
are the various minimums and maximums of the original matrix. Next, we apply a transformation inverse to that made in Equation (7) to retrieve the decimal values. Finally, the matrices are multiplied to obtain an uncompressed image.
3.2. Evaluation Metrics
We evaluated the compression under two different aspects: the size of the compressed image and the quality of the uncompressed image. For the first, we adopted the compression rate that can be expressed as
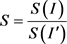 (14)
(14)
where 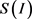 refers to the size of the uncompressed image in bytes, whereas
refers to the size of the uncompressed image in bytes, whereas 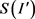 refers to the size of the compressed image in bytes. The result of this measurement indicates how many times the compressed image is smaller than the original image.
refers to the size of the compressed image in bytes. The result of this measurement indicates how many times the compressed image is smaller than the original image.
To evaluate the quality of the decompressed image, we used the mean of the structural similarity index (MSSIM), expressed as
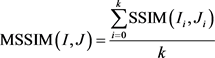 (15)
(15)
where I and J are the original and uncompressed images, respectively. 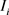 and
and 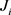 are the i-th windows of the images and k is the total number of windows. The structural similarity index (SSIM) [36] is expressed as
are the i-th windows of the images and k is the total number of windows. The structural similarity index (SSIM) [36] is expressed as
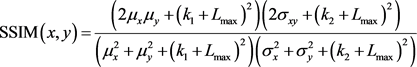 (16)
(16)
where 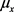 and
and 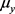 are the means of x and y,
are the means of x and y, ![]() and
and ![]() are the variances of x and y. The variable
are the variances of x and y. The variable ![]() is the covariance between x and y, whereas
is the covariance between x and y, whereas ![]() and
and ![]() are constants. The SSIM values are in a range of
are constants. The SSIM values are in a range of![]() , where the higher the value, the greater the similarity.
, where the higher the value, the greater the similarity.
4. Experimental Results
This section presents the results of experiments conducted on a set of twenty input images. Table 1 summarizes some relevant characteristics of the images. Seventeen images were extracted from a public domain repository [37] , whereas the other three were collected separately.
![]()
Table 1. Images used in our experiments.
In the experiments performed, we compared the relationship between the compression ratio and the MSSIM value. Initially, Table 2 presents different strategies for choosing the ![]() eigenvalue. The first strategy, used in other approaches available in the literature [34] , considers a minimum variance to be preserved in the image. Thus, the eigenvalue
eigenvalue. The first strategy, used in other approaches available in the literature [34] , considers a minimum variance to be preserved in the image. Thus, the eigenvalue ![]() is chosen so that the variance maintained by the eigenvalues
is chosen so that the variance maintained by the eigenvalues ![]() is greater than or equal to the minimum variance, whereas the second strategy chooses an optimal eigenvalue
is greater than or equal to the minimum variance, whereas the second strategy chooses an optimal eigenvalue![]() , as defined in Equation (2).
, as defined in Equation (2).
We can notice that the results obtained by the optimal choice have a compression ratio always greater than 1, in order to obtain a smaller image in all cases, and with high MSSIM values. Since different images have different variance, requiring different amounts of eigenvalues to obtain the same variance, as discussed in Section 0, the minimum variance cannot be used as a fixed value. For example, for images #1 and #5, the compression ratio is less than 1 with variance 0.95, whereas, for image #14, maintaining a variance of 0.9 has already caused the compression ratio to be less than 1. This demonstrates the need to make an adaptive choice. Figure 4 compares the different versions obtained for image #17.
![]()
Table 2. Comparison between minimum variance and optimal choice.
![]()
Figure 4. Result comparison for image #17.
It can be observed that, despite a considerably high result in the MSSIM of the global version with variance 0.8 (0.970), the visual result, shown in Figure 4(b), is very poor, whereas the results are superior with the optimal choice, however, still having some problems.
The artifacts that can be seen in Figure 4(c) occur mainly due to the rounding and linear transformation defined in Equations (7) and (8). This problem can be overcome by a more local strategy, such as the one adopted in this work and with the result shown in Figure 4(d). This improvement probably occurs since the values obtained from the matrices after the decomposition are in a smaller range and closer to 0 to 255, because they have a smaller variation in the image.
As discussed in Section 0 and observed from the previous results, the SVD technique applied globally may not be adequate. Thus, Table 3 presents the results obtained by considering the image divided into square blocks of different sizes. In addition, it presents the results obtained with the method presented in this work, that is, with the adaptive choice of blocks and eigenvalues.
Comparing the results obtained with those shown in Table 2, overall, the compression rates of the images increased, maintaining high MSSIM values. This demonstrates the validity of the local division strategy which, in addition to the reduction of the artifacts shown in Figure 4(c), obtains better quantitative results.
The compression and MSSIM values obtained with the adaptive division are generally similar to those obtained with the fixed block size. However, for image #7, which consists of a chessboard, the result obtained is considerably superior in terms of compression ratio, which demonstrates superiority of the adaptive division. This result can vary considerably in different images with the change of the constant values given in Equation (6). The values used were chosen empirically in order to obtain a good result in all images.
Figure 5 illustrates the result obtained for image #4 considering the different local versions. We can observe, through the resized region, that some fine details of the image are lost in the compression process. In this case, this occurs most notably with a smaller block size. This is an apparent limitation of our adaptive division, which could select a larger block size in those regions, in order to preserve more detail. In order to circumvent this problem, we could choose a more suitable value for![]() , used in Equation (2), or limit the minimum size of the block adaptively.
, used in Equation (2), or limit the minimum size of the block adaptively.
![]()
Figure 5. Result comparison for image #4.
![]()
Table 3. Comparison between fixed and adaptive block partitioning.
It is noteworthy that the requirements for storing the compressed images could still be reduced. For example, a flag used to determine the node type could be only 1 bit long, instead of 1 byte as employed in our implementation for simplification purposes.
5. Conclusions
This work described and implemented a new lossy image compression method based on the singular value decomposition. The proposed approach used an optimal choice of eigenvalues computed in the decomposition, as well as an adaptive block partitioning. We also presented a protocol for storing the SVD matrices.
Experiments were conducted on a dataset composed of twenty images—seventeen extracted from a public domain repository and commonly used in the evaluation of image processing tasks, the other three images collected separately. The results obtained show that the optimal choice of eigenvalues is relevant due to differences in different image contents.
Due to rounding performed in the compression process, the overall approach achieved lower compression rate and added artifacts to the images. In addition, the adaptive partitioning strategy obtained, in some cases, considerably superior results in terms of compression ratio. However, some fine image details may be lost in the compression process based on local strategy.
Acknowledgements
The authors are thankful to São Paulo Research Foundation (FAPESP grants #2017/12646-3 and #2014/12236-1) and National Council for Scientific and Technological Development (CNPq grant #309330/2018-1) for their financial support.