An Extended Bivariate T-Distribution Type Symmetry Model for Square Contingency Tables ()
1. Introduction
Consider an
square contingency table with the same row and column ordinal classifications. Let
denote the probability that an observation will fall in the ith row and jth column of the table (
). The symmetry (S) model is defined by
(1)
see Bowker [1] and Bishop et al. [2] . This model indicates a structure of symmetry of the probabilities with respect to the main diagonal of the table. Agresti [3] considered the linear diagonals-parameter symmetry (LDPS) model defined by
(2)
This indicates that the probability that an observation will fall in the
th cell,
, is
times higher than the probability that it falls in the
th cell. A special case of the LDPS model obtained by putting
is the S model. Furthermore, Tomizawa [4] proposed an extended linear diagonals-parameter symmetry (ELDPS) model defined by
(3)
This indicates that the probability that an observation will fall in the
th cell,
, is
times higher than the probability that it falls in the
th cell.
Consider random variables X and Y having a joint bivariate normal distribution with means
,
, variances
,
and covariance
, where ρ is the correlation coefficient
. The joint bivariate normal density
satisfies
(4)
where
When
,
satisfies
(5)
where
Agresti [3] [5] described the relationship between the LDPS model and the joint bivariate normal distribution as follows: the LDPS model may be appropriate for a square ordinal table if it is reasonable to assume an underlying bivariate normal distribution with equal marginal variances. Also, Tomizawa [4] pointed out that the ELDPS model may be appropriate for a square ordinal table if it is reasonable to assume an underlying bivariate normal distribution with different marginal variances.
Consider a bivariate t-distribution with m degree of freedom. The limit of this joint probability density function as
is bivariate normal. Therefore, the LDPS model may be appropriate if it is reasonable to assume an underlying bivariate t-distribution with equal marginal variances such that m degree of freedom is very large. Also, the ELDPS model may be appropriate if it is reasonable to assume an underlying bivariate t-distribution with different marginal variances such that m degree of freedom is very large.
Consider the
square contingency table with ordered categories. For any fixed constant
, Iki et al. [6] proposed the t-distribution type symmetry (TS(m)) model defined by
(6)
A special case of this model obtained by putting
is the S model. The TS(m) model indicates that the difference between the symmetric two probabilities raised to the power
is proportional to the distance from the main diagonal of the
table. The TS(m) model may be appropriate if it is reasonable to assume an underlying bivariate t-distribution with equal marginal variances having m degrees of freedom (see Iki et al. [6] ).
Now, we are interested in considering a new model, which is appropriate if it is reasonable to assume an underlying bivariate t-distribution with different marginal variances.
The purpose of present paper is to introduce an extended TS(m) model. Section 2 proposes an extended TS(m) model and describes the properties of the new model. Section 3 describes the relationships between the extended TS(m) model and t-distribution by the simulation study. Section 4 illustrates the use of our new model with father’s and son’s occupational structure data. Section 5 provides some concluding remarks.
2. Extended Bivariate T-Distribution Type Symmetry Model
Consider random variables X and Y having a joint bivariate t-distribution with
degrees of freedom, and means
,
, variances
,
, and correlation coefficient
. The probability density function
is
(7)
where
See, e.g., Muirhead [7] . Another form of the probability density function
is expressed as
(8)
where
We note that
. Also, the probability density function
satisfies
(9)
where
For continuous bivariate data, when we make the
square contingency table formed using
’s cut points for each of row and column variables, we are interested in the structure of asymmetry of bivariate discrete probabilities
. Consider the
square contingency table with ordered categories. For any fixed constant m, we propose a model defined by
(10)
where
. We shall refer to this model as an extended t-distribution type symmetry (ETS(m)) model. The ETS(m) model may be appropriate if it is reasonable to assume an underlying bivariate t-distribution with different marginal variances having m degrees of freedom. Under the ETS(m) model, setting
, we see that
(11)
where
Namely, the ETS(m) model approaches the ELDPS model as m becomes larger, although the TS(m) model approaches the LDPS model as m becomes larger (see Appendix 1).
The ETS(m) model is also expressed as
(12)
where
A special case of this model obtained by putting
is the TS(m) model.
The maximum likelihood estimates of expected frequencies under the ETS(m) model could be obtained using the Newton-Raphson method in the log-likelihood equation (see Appendix 2). For the ETS(m) model,
are determined by
of
, R of
, 1 of
and 1 of
, thus a total of
. Therefore, the number of degrees of freedom (df) for the ETS(m) is
, which is one less than that for the TS(m) model, and equal to that for the ELDPS model.
3. Simulation Study
As described in Section 2, the ETS(m) model may be appropriate for a square ordinal table if it is reasonable to assume an underlying bivariate t-distribution with different marginal variances having m degrees of freedom. We shall consider the simulation study based on bivariate t-distribution. Consider random variables X and Y having a bivariate t-distribution with
degrees of freedom, and means
,
, variances
,
and correlation coefficient
. (Note that it is possible to take various values of ρ.) Such random numbers are obtained by using normal random number and chi-square random number with m degree of freedom. Suppose that there is an underlying bivariate t-distribution with some conditions, namely,
and 1.7, and a
table of sample size 1000 is formed using cut points for each variable at
.
Then, we shall count the frequencies of acceptance (at the 0.05 significance level) based on the likelihood ratio chi-squared statistic for testing the hypothesis that the ETS(m) model or the TS(m) model with the corresponding m degrees of freedom of underlying t-distribution holds per 10000 times for
tables on each conditions. From Table 1, we see that the ETS(m) model gives good fit, however, the TS(m) model gives poor fit. Thus, from the result of simulation for comparison the ETS(m) and TS(m) models, we obtain that if it is reasonable to assume the underlying bivariate t-distribution with different marginal variances and the ratio of different marginal variances (i.e.,
) being large, the corresponding ETS(m) model rather than the TS(m) model would fit the data well without depending the value of degrees of freedom m.
![]()
Table 1. The frequencies of acceptance (at the 0.05 significance level) based on the likelihood ratio chi-squared statistic for testing the hypothesis that the ETS(m) model or the TS(m) model with the corresponding degrees of freedom of underlying t-distribution holds per 10,000 times for
tables on some ratios of variances
and m degrees of freedom.
4. Example
The data in Table 2 is taken from Tominaga [8] . These data describe the cross-classification of father’s and son’s occupational status categories in Japan, which were examined in 1955. From Table 3, we see that the TS(m) (
) models fit these data poorly, however, the ETS(m) (
) and the ELDPS models fit these data well. We obtain the similar result without depending the value of degree of freedom m, although the detail is omitted. We also see that the values of the likelihood ratio chi-squared statistic G2 for the ETS(m) model approach the value of G2 for the ELDPS model as
![]()
Table 2. The cross-classification of father’s and son’s occupational status categories in Japan, which were examined in 1955 from Tominaga [8] . (The parenthesized values are the maximum likelihood estimates of expected frequencies under the ETS(5) model.)
Note: (1) is upper non-manual, (2) lower non-manual, (3) manual, and (4) agriculture.
![]()
Table 3. Likelihood ratio chi-squared values G2 for models applied to Table 2.
*means significant at the 0.05 level.
the value of m increases. Under the ETS(5) model, the maximum likelihood estimates of
and
are
and
, respectively.
Therefore, the difference between the probability raised to the power
[=−0.286] that the occupational status category of the father in pair is i and that of his son is
and the probability raised to the power that the occupational status category of the father in pair is j and that of his son is i, is
. For example, the difference between the probability raised to the power that the occupational status category of the father in pair is (1) “upper non-manual” and that of his son is (2) “lower non-manual” and the probability raised to the power that the occupational status category of the father in pair is (2) “lower non-manual” and that of his son is (1) “upper non-manual”, is estimated to be -0.400 [
]. Namely, the probability that the occupational status category of the father in pair is (1) “upper non-manual” and that of his son is (2) “lower non-manual” is estimated to be greater than the probability that the occupational status category of the father in pair is (2) “lower non-manual” and that of his son is (1) “upper non-manual”. Also, the probability that the occupational status category of the father in pair is (1) and that of his son is (3) is estimated to be greater than the probability that the occupational status category of the father in pair is (3) and that of his son is (1). However, for the other symmetric two probabilities with respect to the main diagonal, the probability that the occupational status category of the father in pair is j and that of his son is
is estimated to be greater than the probability that the occupational status category of the father in pair is i and that of his son is j.
5. Concluding Remarks
From the result of simulation studies, the ETS(m) model would be appropriate for a square contingency table if it is reasonable to assume an underlying bivariate t-distribution with different marginal variances, although, the TS(m) model may be appropriate for a square contingency table if it is reasonable to assume an underlying bivariate t-distribution with equal marginal variances having m degrees of freedom.
Acknowledgements
The authors would like to thank referees for helpful comments.
Appendix 1
The TS(m) model is also expressed as
(A.1)
where
. Under the TS(m) model, we see that
(A.2)
where
Namely, the TS(m) model approaches the LDPS model as m becomes larger.
Appendix 2
Let
denote the observed frequency in the ith row and jth column of the table (
), with
. Assume that a multinomial distribution applies to the
table. We consider the maximum likelihood estimates of expected frequencies
under the ETS(m) model. We must maximize the Lgrangian
(A.3)
with respect to
and
. Setting the partial derivations of L equal to zero, we obtain the equations:
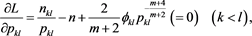 (A.4)
(A.4)
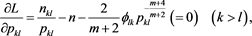 (A.5)
(A.5)
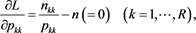 (A.6)
(A.6)
(A.7)
(A.8)
(A.9)
Using the Newton-Raphson method, we can solve Equations (A.4) to (A.9) with respect to
and
. Noting that
, we obtain the maximum likelihood estimates of
and the parameters
and
under the ETS(m) model.