Development of a Modelling Script of Time Series Suitable for Data Mining ()
Received 30 May 2016; accepted 19 July 2016; published 22 July 2016

1. Literature review
During the last few years and due to the numerous advances in information systems, the use of means designed for the acquisition of data such as web and mobile applications, social networks, etc. has massively increased. As a result of this “information revolution”, the world of science has been saturated with data of varied origin. It is estimated that 90% of all data have been created in the last two years (2013-2015) [1] . At the IOD (Information On Demand) Conference held in 2011, IBM presented the explosion of data in today’s society as a problem, and put forward how companies are facing the challenge of obtaining relevant and valuable information from this vast amount of data. The amount of data in the world is expected to double every two years, according to the data scientist Mark van Rijmenam, founder of Datafloq, in addition to increase 2.5 exabytes per day [1] .
This enormous amount of information is known as Big Data. The vast majority of these data, which come from astronomy, genomics, telephony, credit card transactions, Internet traffic and web information processing, primarily, are acquired systematically with a certain frequency, being therefore time series [2] - [4] . The tendency to manipulate large quantities of data is due to the need, in many cases, to include the data obtained from the analysis of large databases in new databases, such as business analyses [5] . Besides data manageability, other factors to consider are the speed of analysis/scanning speed, access, search and return of any element. It is important to understand that conventional databases are a significant and relevant part of an analytical solution [6] [7] .
Today, the explosion of data poses a problem given the amount of these increases overwhelmingly; in fact this situation reaches occasionally the point when it is not possible to gain an useful insight from them. Therefore, it is necessary to organise, classify, quantify and of course exploit this information to obtain maximum performance for the benefit of scientific research. In response to this difficulty the concept of Data Mining arises that refers to the non-trivial automated process which identifies valid, previously unknown, potentially useful and funda- mentally understandable patterns in the data.
The literature shows that Data Mining techniques are used to extract information from very diverse back- grounds as the power consumption of a region [8] , modelling and optimisation of wastewater pumping systems [9] and the establishment of the position of wind turbines to obtain the maximum possible wind currents [10] .
A common pattern of all previous studies is the use of time series for the analysis and visualisation of information. A way to perform the processing of time series is through the creation of mathematical models that identify and predict their behaviour. One of these are the ARIMA models [11] , that extract the most relevant data from the dataset identifying the patterns of the series at different levels of the timescale and simplify a large amount of data in a simple equation, hence their utility and application in Data Mining. ARIMA models are within the Data Mining techniques, as these are used in time series, therefore being a very useful tool to extract relevant information from Big Data.
In the field of the analysis and visualisation of data, the development of free software is a good tool for both analytical and visual integration of information. In this section of the processing of data, software for the analysis and visualisation of data allow to work with large volumes of data completed over a period of time [12] . The development of statistical software that allows to work on the analysis of time series further facilitates the implementation of ARIMA models.
The use of free access software as Rstudio, which is an integrated development environment for R, has the advantage of enabling programming statistical packages as required, as well as of applying all kinds of time series analysis, in addition to reducing economic costs in any research project. In the present work a script has been developed in the environment of programming R language that allows the implementation, processing and visualisation of ARIMA models, in order to make it easier for scientists to know about the exploration, exploitation and manipulation of large volumes of univariate data carrying associated timescales. The script development and implementation structure is shown in Figure 1.
this script achieves the implementation of the Box-Jenkins methodology [11] for the development of ARIMA-models; in this way, the researcher is able to decompose the time series and to obtain the most relevant information of the characteristics of the temporal series, showing the extent to which this script helps in the exploration, exploitation and manipulation of data.
2. Information about the ST.R File
This document provides information about what is and how to use the ST.R script.
2.1. What Is ST.R?
ST.R is a code in R language developed for the treatment of time series and the realisation of ARIMA models following the Box-Jenkins methodology [11] . The script is split into two blocks. The first one is a collection of
![]()
Figure 1. Structure of development and implementation of the script in R. The different actions to be followed for the implementation of the script are shown. It is a conceptual model of implementation where Excel is used as a possible tool for data management. Source: own elaboration.
commands for the numerical and graphic description of the time series, and the development of the ARIMA models. In the second block the commands of different precision measurements are set up, which allow to compare the forecasts made by the models with the actual data with the aim of selecting the model with the most optimal fit to actual observations [13] [14] .
2.2. How to Use ST.R
In order to successfully run the ST.R script, the necessary libraries are lmtest and tseries. These libraries are available from the repository Comprehensive R Archive Network (CRAN) at http://CRAN.R-project.org/package=OptGS. In this work, the R “stat” package version 3.3.0 was used, using “ARIMA” argument. The fitting methods are described in the R manual [15] .
2.3. ST.R Structure
1) Graphical representation: graphical representation of the time series to visualise its components (trend, cycle, stationarity and random or irregular component (Figure 2 and Figure 3).
2) Trend analysis: the existence or non-existence of the trend is studied from the graphical results. A linear trend will be removed with first differences. However, for a nonlinear trend two differences are used. The Dickey-Fuller [16] and KPSS [17] tests are used for the analysis (Figure 4).
3) Homocedasticity analysis: This is done from both a visual and a mathematical perspective. From a visual point of view, it is carried out through the study of the thickness of the series. If this thickness remains constant, with no major irregularities observed, the series will be homocedastic; otherwise, the series will be considered heterocedastic. From a mathemathical, it is carried out with the application of the homoscedasticity Breusch- pagan test [18] (Figure 5).
![]()
Figure 2. An R Graphical User Interface (GUI) for step 1. Graphical representation.
![]()
Figure 3. An R Graphical User Interface (GUI) for step 1. Graphical representation.
4) Stationarity analysis: As a result of the steps above, when neither seasonal cycle, nor trend, nor a significant thickness alteration of the series are to be perceived, the series is regarded as stationary (Figure 5).
5) Model identification: the most optimal model type is determined from the order of the Autoregressive procedure and moving averages of the constituents, both uniform and seasonal. This choice is made from autocorrelation (FAC) and partial autocorrelation (partial FAC) functions (Figure 5).
6) Estimation of the coefficients of the model: the order of the model having been established, the estimation of its parameters is made. Given it is an iterative calculation process, initial values (pool of models) can be suggested (Figure 5).
![]()
Figure 4. An R Graphical User Interface (GUI) for step 2. Trend analysis.
![]()
Figure 5. An R Graphical User Interface (GUI) for steps 3 - 7, 10. Homocedasticity analysis; stationarity analysis; model identification; estimation of the coefficients of the model; detailed error analysis; forecast.
7) Detailed error analysis: It is made from the verified differences between values observed empirically and estimated by the model for their final assessment. It is necessary to check an inconsistent regime of them and analyse the existence of significant errors. The Ljung-Box test is applied [19] (Figure 5).
8) Contrast of model validity: the model or models initially selected are quantified and valued using various statistical measures. The measures applied are: R2 (coefficient of determination), % SEP (standard error percentage), E2 (coefficient of efficiency), ARV (average relative variance), AIC (Akaike information criterion), RMSE (root mean square error) and MAE (mean absolute error) (Figure 6).
9) Model selection: based on the results of the previous steps, the model to work on is decided upon (Figure 6).
10) Forecast: the most optimal model will be used as the prediction base tool (Figure 5).
2.4. ARIMA Models
The univariate ARIMA models (p,d,q) [11] try to explain the behaviour of a time series from past observations of the series itself and from past forecast errors. The compact notation of the ARIMA models is as follows:
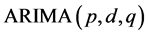 (1)
(1)
where p is the number of autoregressive parameters, d is the number of differentiations for the series to be stationary, and q is the number of parameters of moving averages. The Box-Jenkins model (p,q) is represented by the following equation:
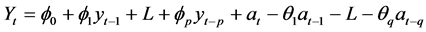 (2)
(2)
The autoregressive part (AR) of the model is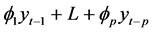 , while the part of moving averages of the
, while the part of moving averages of the
![]()
Figure 6. An R Graphical User Interface (GUI) for steps 8 and 9. Contrast of model validity; model selection.
from the data, by means of any consistent statistic. The ARIMA models allow fitting the trend plus the stationarity in data. In this case, the model is noted as:
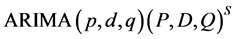 (3)
(3)
where P is the number of autoregressive parameters in the seasonal part, D is the number of differentiations for the series to be seasonal in the seasonal part, Q is the number of parameters of moving averages in the seasonal part and S is the series frequency.
The Box-Jenkins method provides forecasts without any previous conditions, apart from being parsimonious with regard to coefficients [20] . Once the model has been found, forecasts and comparisons between actual and estimated data for observations from the past can be done immediately [21] .
The identification of the parameters p, q, P, Q and S is done by inspecting the autocorrelation function (ACF) and the partial autocorrelation function (PACF), taking into account differentiation and seasonal differentiation [22] .
To create models, the most suitable values of p, d and q were used, according to the measures of accuracy which are presented in the section of criteria for model selection. The parameters ϕ and θ are set through the use of the function minimisation procedures so that the square sum of residues be minimised.
The time series trend is studied applying the Dickey-Fuller [16] and KPSS [17] tests. The Dickey-Fuller test contrasts the null hypothesis that there is a unit root in the autoregressive polynomial (non-stationary series) against the alternative hypothesis that holds the opposite. The KPSS is another test with the same aim, but not exclusive of autoregressive models, supplementary of the former, which contrasts the null hypothesis that the series is stationary around a deterministic trend against the unit root alternative (non-stationary series). Homoscedasticity is studied through the Breusch-Pagan test [18] , which contrasts the null hypothesis that holds heteroscedasticity exists against its nonexistence.
2.5. Model Selection Criteria
The correlation between the actual and forecast data for a variable (x) is expressed by using the correlation coefficient. The coefficient of determination (R2) describes the proportion of total variation in the actual data, which can be explained by the model. The coefficient of determination shows a range of variation [0-1]. If R2 = 1, it means a perfect linear fit, that is to say the proportion of total variation in the actual data is explained by the model. Instead if R2 = 0, the model does not explain anything of the proportion of total variation in the actual data [23] .
Other selection measures applied in R are the standard error of prediction percentage (% SEP) [24] , the efficiency coefficient (E2) [25] [26] , the average relative variance (ARV) [27] and the Akaike information criterion (AIC) [28] . The first four estimators are unbiased estimators which are used in order to check to what extent the model is able to explain the total variance of the data, while the AIC uses the maximum likelihood function to select the model which best fits data. Moreover, it is advisable to quantify the error in the same units as the studied variable.
These measures, or absolute error measures, include the root mean squared error (RMSE) and the mean absolute error (MAE), both expressed as follows:
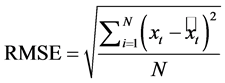 (4)
(4)
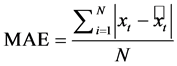 (5)
(5)
where 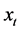 is the variable observed at moment t,
is the variable observed at moment t, 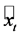 is the estimated variable at the same moment t and N is the
is the estimated variable at the same moment t and N is the
total number of observations of the validation set.
The standard error of forecast percentage, % SEP, is defined as:
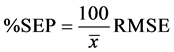 (6)
(6)
where ![]() is the average of the variable observed of the validation set. The main advantage of %SEP is its non-dimensionality, which allows to compare the forecasts of the different models on the same base.
is the average of the variable observed of the validation set. The main advantage of %SEP is its non-dimensionality, which allows to compare the forecasts of the different models on the same base.
The efficiency coefficient (E2) and the average relative variance (ARV) are used to verify how the model explains the total variance of data and to represent the proportion of the variation of the data observed considered for the model. E2 and ARV are defined as:
![]() ,
,![]() (7)
(7)
The sensitivity to the atypical values due to squaring the terms of the difference is associated to E2 or to ARV. The Akaike information criterion (AIC) combines the maximum likelihood theory, theoretical information and information entropy [29] , and is defined by the following equation [30] [31] :
![]() (8)
(8)
where N is the total number of observations of the validation set, k is the number of the parameters of the estimated model, MSE is the mean square error estimated, which is defined by the following equation [30] [31] :
![]() (9)
(9)
where N is the total number of observations of the validation set, k is the number of parameters of the estimated
Depending on the fit, a model which explains a high variance level (R2, ARV, E2) in the validation period is associated to low absolute error (RMSE, MAE), relative (% SEP) and Akaike (AIC) values. Hence, the hypothesis is validated that when using AIC the best model will be that which presents the lowest value, since its likelihood function will fit the data more accurately [28] .
2.6. Application
The nature of information differs now from that of information in the past. Due to the vast amount of measuring devices (sensors, microphones, cameras, medical scanners, images, etc.), the data generated by these elements are the largest of the entire available information spectrum. For this reason, the analysis of the wealth of time series has been carried out in a continuous and frequent way [33] in order to obtain the prediction variables and thus to be able to warn behaviour in the environment these occur.
The analyses of time series take into account the degree of dependence between observations and allow to obtain valid inferences without violating basic assumptions of the statistical model or introducing variations in order to overlook this problem; this way, the model further fits the real behaviour of the series.
Since time series are currently employed in different and various fields of knowledge―telecommunications [34] , fisheries [35] , medicine [36] , etc.―it is important to perform a script that allows to give a global and integrated vision on the treatment of time series grouping all the relevant information with the characteristics of the series and prediction models.
Treatment and analysis of time series using free software such as R presents advantages and disadvantages in comparison with private software. On the one hand R has been used in this work as a free and cross-platformer software, making it easy to work with different operating systems. As it has an open source, it is continuously updated by users, not to mention its great graphical power. On the other hand we are aware that the development of this script in the R programming environment presents a number of drawbacks, such as abundant but unstructured help information or packages and functions that make it difficult to locate specific information in a given search. Error messages do not show clearly where in the development of the script the bug is committed, which creates problems for users with little experience in this programming environment making the initiation tedious. R is a programming language in lines of commands, which does not use menus as other statistical programs (e.g., Statgraphics) interfaces. However this can also be an advantage since R advanced users are able to schedule the treatment and analysis of data, in order to understand the basis of the statistical development and data analysis.
To this aim the ST.R script has been created, whose main objective is the analysis and development of forecasting models for time series. It can be established that time series models allow to estimate the degree of significance of a level change which is operated as a result of the application of a treatment [37] . These models not only allow to obtain statistical inferences on treatment action, but also solve the problem of dependence inherent to this type of designs which use a single subject.
In this work, Excel has been used for the database structure management. We know that this system is not sufficiently solvent to support the current data productions [38] . Although Excel is satisfactory for time series management since this working field is univariate based, Excel has also the advantage of being user friendly and accessible for most users. Then this system is considered an efficient tool when it comes to structuring univariate time series.
3. Conclusion
In conclusion, the present script aims to be a useful and efficient tool to give a global and integrated vision on the time series treatment through the application of Data Mining based on ARIMA models. Introducing this script has made it possible to group all the most relevant information related to the series and prediction models characteristics in order to be able to optimise decision-making in research, in the sense of obtaining more robust and reliable results to support the study.
Acknowledgements
We thank Sonia Páez-Mejías for the edition of the manuscript in English. We also wish to acknowledge Miguel Ángel Rozalén Soriano for the constructive comments and suggestions about Big Data and Data Mining. This study has been submitted to the V International Symposium on Marine Sciences (July, 2016). The authors are grateful to anonymous referees for their helpful comments and CACYTMAR (Centro Andaluz de Ciencia y Tecnología Marinas) for funding support.