Received 15 March 2016; accepted 26 April 2016; published 29 April 2016

1. Introduction
Numbers are used to count objects, compare amounts, calculate, determine order, make measurements, encode information and transmit data. This multifunctional use of numbers in our daily lives is reflected in language too. Although the words expressing the basic numerals are limited in number, numeral expressions are seen more frequently than one can expect. Numerals are found in various linguistics items such as idioms, proverbs and slangs.
In grammars of Turkish, as for most languages, numerals are covered under adjectives (Hengirmen, 2005; Banguoğlu, 2000; Gencan, 1992; Kornfilt, 1997; Lewis, 1967; Göksel & Kerslake, 2005) . Other studies on numerals in Turkish discussed the use of numerals in literary texts with reference to their etymological and mythological roots instead of their structural properties (Güvenç, 2009; Durbilmez, 2011) . These classifications miss the morphological and syntactic properties of the numeral expressions in Turkish and solely focus on the functional and pragmatical aspects of these expressions.
In this study, I aim at exposing the morphosyntactic properties of numerals in Turkish with regard to Booij’s (2009) classification and Hurford’s (2007) “packaging strategy”. In this respect, I will first review Booij’s and Hurfords’s approach to numerals with crosslinguistic examples and present a comprehensive account of morphosyntactic properties of numerals. Later I will provide general information on numerals in Turkish and I will classify them with regard to the theoretical background presented in Section 2. In the last section, I will present the syntactic analyses of Turkish cardinal, ordinal, distributional and fractional numerals.
2. The Morphosyntactic Representation of Numerals
Selecting a Template
As in many languages such as English, German, French, Dutch, etc., the numerals in Turkish are complex linguistic expressions “that are formed by an iterative rule system which enables the language user to form numeral expressions in an infinite number, in principle” (Booij, 2009: p. 5) . Cardinal numbers above 12 in English, German and Dutch, above 15 in Spanish and above 16 in French are complex linguistic expressions. In Turkish cardinal numbers above ten are complex expressions (Table 1).
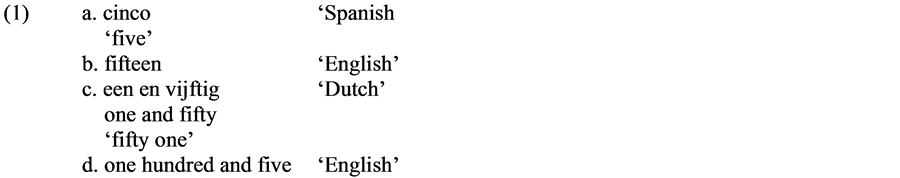
![]()
Table 1. Simple and complex cardinal numbers in various languages.
Booij gives a classification of categorial features of numeral expressions in languages and asserts that they can be classified in terms of carrying the features Number [Num], Noun [N] and Multiplication [M] (Booij, 2009: p. 9) :

According to the classification exemplified in (2) honderd, duizend, miljoen and miljard carry the feature [N] and could bear suffixes that can be attached to nouns, and therefore they are considered as words similar to nouns. The feature [M] on these words causes them to appear in singular form when they follow a numeral expression. Differently from honderd and duizend, miljoen and miljard cannot be used on their own without following a numeral expression since they do not carry a [Num] feature (Booij, 2009: p. 9) . Considering this analysis and Hurford’s analyses (1975, 1987, 2007), Booij argues that numeral expressions can project phrases (Booij, 2009: p. 9) and therefore they have a syntactic representation.
In order to support the argument that numeral expressions do have a syntactic structure we need an approach that can explain this representation. In this respect, Hurford’s (1975, 1987, 2007) “Packaging Strategy” (henceforth PS) could be referred to. PS is a universal constraint on any system, which uses syntactic structures to specify advanced number systems, i.e. the operations of addition and multiplication (Hurford, 2007: 773). PS is devised within the transformational grammar framework and aims at presenting the rules that generate all numeral expressions in an economic fashion without compromising semantic acceptability (Hurford: 2007: 773- 774).
PS asserts that all numeral expressions in natural languages are generated according to a small set of phrase structure rules (henceforth PSRs) (2007: 774):

In the PSR in (3) the DIGIT is the cardinal numbers (one, two, three, etc.); M is the multipliers (hundred, thousand, million, billion, etc.). According to the rule a numeral may comprise of a single DIGIT as well as a PHRASE or PHRASE and NUMBER. The PHRASE may comprise of an M or an M and NUMBER (Hurford, 2007: 774). The rule in (3) is a recursive one, namely it can be used again and again to form all numeral expressions in a language.
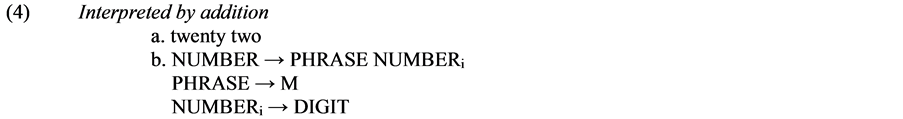
The numeral “twenty two” in (4a) is formed using the PSRs listed in (4b) and interpreted by addition. This numeral is formed by adding the NUMBER comprising of the DIGIT “two”, to the PHRASE comprising of the M “twenty”.

The numeral “two hundred” in (5a), on the other hand, is formed by multiplication of the NUMBER comprising of the DIGIT “two” and the M “hundred”.
We can show the numerals formed with the PSRs in the Packaging Strategy with tree diagrams as below:
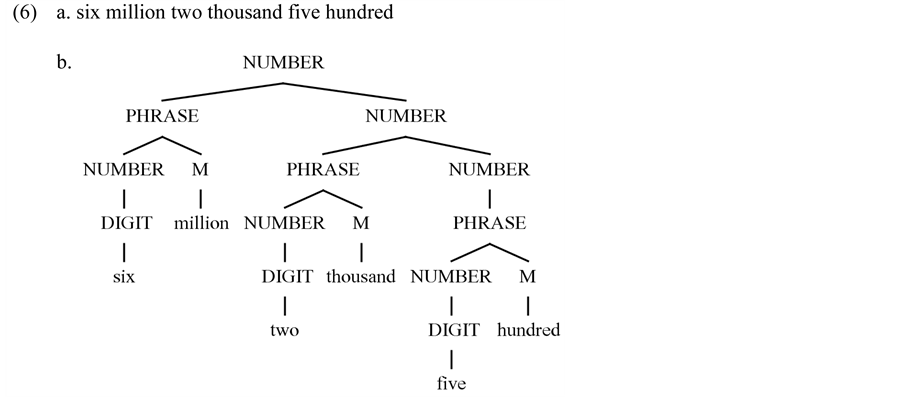
The example in (6) presents the syntactic representation of the numeral “six million two thousand five hundred”. According to this, the numeral comprises of the PSRs in (3) and includes both addition and multiplication. While the numeral expressions “six million”, “two thousand” and “five hundred” are interpreted by multiplication, the numeral as a whole is interpreted by addition of these smaller expressions. Hurford summarizes the Packaging Strategy, which operates via the structure presented in (3) as below (Hurford, 2007: 773):
(7) Packaging Strategy: The sister constituent of a NUMBER must have the highest possible value.
According to Hurford, in the additive constructions the constituents with greater values are packed nearer to the higher positions of the tree diagram, therefore they are to the left of the structure (2007: 774). As it is seen in the tree diagram in (6b) the greatest valued constituent “six million” is at the top of the tree, in other words to the leftmost of the structure.
In multiplicative constructions the greater-valued multiplicative bases are packed nearer to the higher positions of the tree. This results in greater-bases being positioned to the right of the lower ones (Hurford 2007: 775).

As it is seen in (8a)-(8c), the base M “thousand” with the greatest multiplication value is higher in the tree structure to the right of the base M “six hundred” which has a smaller value.
3. Numerals in Turkish
In this section, I will first provide general information about the numerals in Turkish, and later I will analyze the syntactic structures of the cardinal numbers in Turkish with reference to the analyses presented in the previous section. Later, I will provide the morphosyntactic analyses the ordinal, distributional and fractional numerals.
The numerals in Turkish generally comprise of the linguistic items called the cardinal numbers. In addition to cardinal numbers, Turkish has some words that are used like cardinals, ordinal numbers which are formed using the morpheme {-(I)ncI}, distributional numbers which are formed using the morpheme {-(ş)Ar}, and fractional numbers which are formed using the words “virgül (comma), bölü (divide)” or using a noun compound (Göksel & Kerslake, 2005) . Some examples to numerals in Turkish are presented in Table 2.
3.1. The Categorial Properties of Numerals in Turkish
As I already mentioned in Section 2, Booij (2009) asserts that the numerals in languages may carry the features [NUM], [N] and [M]. In this respect the categorical properties of Turkish cardinals can be shown as in Table 3.
As it is seen in Table 3, the cardinal numbers from 1 to 9 have the [+N] and [+NUM] features. In other words these may bear the morphemes that can be added to nouns and they can be used in a numeral expression on their own.
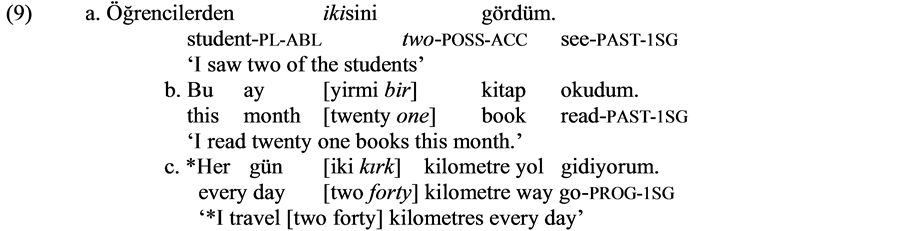
![]()
Table 3. Categorial properties of cardinals in Turkish.
In (9a) the number “iki” (two) could bear the possessive and accusative markers which can be added to nouns due to its [+N] feature. In (9b) the number “bir” (one) is used in a numeral expression due to its [+NUM] feature; however, in (9c) the number “kırk” (forty) does not have the feature [+M] and thus does not allow another number to precede itself and cannot form a numeral with the preceding number.
The words “yüz” and “bin”, hundred and thousand respectively, have the [+N], [+NUM] and [+M] features. Therefore these words function as noun and can bear the morphemes which can be added to nouns; as a numeral expression and thus modify the nouns following them; and as multiplier in numeral expressions and thus allowing the formation of greater numeral expressions.

In (10a) the word “bin” could bear the nominal morphemes by functioning as a noun due to the [+N] feature. In (10b), the word “yüz” is used as quantifier before a noun due to its [+NUM] feature. In (10c), again the word “yüz” is used to form a greater numeral expression by functioning as a multiplier with its [+M] feature, and allowing another numeral expression to precede itself.
The borrowings “milyon, milyar, trilyon, katrilyon” etc., “million, billion, trillion and quadrillion” respectively, only have the features [+N] and [+M]. They do not have the [+NUM] feature and cannot function as quantifiers when they are used on their own. For these words to function as a quantifier, another numeral expression should precede them.

In (11a) the word “milyon” functions as a noun due to its [+N] function and could bear the nominal morphemes. In (10b) the same word allows another numeral expression before itself due to the [+M] feature and thus forms a greater numeral expression. However, in (10c) the use of the world “milyar” on its own yielded an ungrammatical sentence since it does not have [+NUM] feature and thus cannot modify the following noun.
After explaining the categorial properties of numerals in Turkish, we may now proceed the next section where I present the syntactic analyses of numerals in Turkish.
3.2. The Syntactic Representation of Numerals in Turkish
With regard to the syntactic representation of numerals in Turkish, Göksel & Kerslake assert that in the numerals between 11 and 99, the numbers one-to-nine follow the number with a greater value; but in numerals greater than 100 the numbers between 1 - 99 follow the number with a greater value (2005: 181). Apart from this statement Göksel & Kerslake (2005) do not elaborate the syntactic structure of numerals in Turkish. At this point, we may refer back to the PS that I mentioned in the previous section. PS argues that the numerals in natural languages are generated depending on some certain phrase structure rules (Hurford, 2007: 774); which are repeated below:

The PSRs given in (3’) are iterated to generate all the possible numeral expressions in a language. PS can be summarized as below as a constraint on grammaticality of numeral expressions generated based on the PSRs given in (3’):
(7’) Packaging Strategy: The sister constituent of a NUMBER must have the highest possible value.
The packaging strategy repeated in (7’) aims at forming grammatical numeral expressions. Accordingly, the sister node of a NUMBER constituent within a numeral expression could either be a PHRASE-another numeral expression with a greater value―or a MULTIPLIER. Using the PSRs in (3’) and considering the PS in (7’) we may discuss the syntactic representations of numerals in Turkish as below.

There are some numerals which are formed via interpretation by addition in (12a)-(12b). While the PSR forms a structure comprising of a single DIGIT in (12a), it forms a structure similar to coordinated structures in (12b) comprising of two different NUMBER constituents with different DIGITs as constituents.
![]()
The structure in (13b) is consistent with the PS that asserts that in structure where the interpretation is done via addition, the constituents with greater values are positioned to the left of the phrase structure. Here, the constituent with the greater value, “kırk”, is positioned to the left of the constituent with the smaller value, “üç”.
There are some numerals which are formed via interpretation by multiplication in (12c)-(12d). While there is a numeral comprising of PHRASE with a single M constituent in (11c); there is a numeral comprising of a PHRASE with an M constituent and another NUMBER constituent.
![]()
The structure in (14b) again is consistent with the PS which asserts that the sister node of a NUMBER constituent in a numeral expression should have the greatest value. Hurford (2007: 775) asserts that, in interpretation by multiplication, the bases with a multiplier which have a greater value are packaged to the right of the numeral expression with a smaller value. In (14b) the M constituent “yüz” is positioned to the right of the number “iki” which is smaller of value. In addition, the sister node of NUMBER constituent has the highest possible value.
The interaction between the PSRs which form the interpretation by addition and the PSRs which form the interpretation by multiplication, results in structures as below:
![]()
The phrase marker in (15b) shows how the numeral “beşyüzbeş” is formed using the PSRs and hierarchically structured. According to PS, the sister node of the NUMBER constituent in (15b), i.e. the PHRASE constituent, carries the greatest value. Any configuration against this strategy yields an ungrammatical structure as in (16) below:
![]()
In (16), since the sister node of the NUMBER constituent, “beşyüz” with the greatest value, is not positioned to the left, the expression “beşbeşyüz” is ungrammatical. This indicates that the Packaging Strategy operates in Turkish also.
After describing the categorial features and presenting the syntactic analyses of numerals in Turkish, we may now proceed the next subsection where I present the morphosyntactic analyses of the ordinal numerals in Turkish.
3.3. Morphosyntactic Properties of Ordinal Numerals in Turkish
The ordinal numerals, which are used to determine and express the order of entities in a group, are formed by adding the {-(I)ncI} morpheme to the cardinal numbers in Turkish (Göksel & Kerslake, 2005: p. 182) .
![]()
The {-(I)ncI} morpheme which forms the ordinal numerals in Turkish is positioned to the rightmost of the numeral expressions, in other words it is inserted as the sister node of the whole numeral expressions. The ordinal numeral morpheme cannot be inserted as a sister of a NUMBER constituent lower in the numeral expression.
![]()
At this point I argue the the ordinal numerals in (17a)-(17b) and (18a) have a phrase structure similar to the one given below:
![]()
As it is seen in (19b), the ordinal numeral morpheme is positioned at the topmost position of the phrase marker and therefore c-commands the whole numeral expression. Any different configuration yields ungrammatical results.
![]()
In (20b) the ordinal numeral morpheme does not c-command the whole numeral, but it commands the NUMBER constituent which is a constituent of a greater numeral expression. This generates an ungrammatical structure. The ordinal numeral morpheme in Turkish should be positioned to the topmost position on the phrase marker and should c-command the whole numeral expression. The formation of ordinal numerals does not impose any contraints on the inner structure of the NUMBER constituent which is c-commanded by the ordinal numeral morpheme. In other words, sister node of the ordinal number morpheme may either be simple numerals comprising of a single M or DIGIT or complex numeral expressions:
![]()
Now we may discuss the morphosyntactic properties of distributional numerals in Turkish.
3.4. Morphosyntactic Properties of Distributional Numerals in Turkish
The distributional numerals, which bear the function of allocation, division and distribution of entities, are formed by adding the morpheme {-(ş)Ar} to the cardinal numbers in Turkish (Göksel & Kerslake, 2005: p. 183) . Göksel & Kerslake assert that the distributional numeral morpheme, in numerals which are multiples of 100, can be added to the fist part the numeral expression or to the word “yüz” (Göksel & Kerslake, 2005: p. 183) :
![]()
Considering the examples in (22) we can surmise that distributional numeral morpheme can be inserted to any position in the phrase marker comprising the numeral expressions:
![]()
![]()
As we can see in (23b) and (23d) the distributional numeral morpheme can c-command a DIGIT or a PHRASE and thus, two different distributional numeral with the same value could be obtained. However, there are situations in Turkish in which the distributional numeral morpheme is not free as it is seen in the examples above:
![]()
As it is seen in (24a) the distributional numeral morpheme can c-command the DIGIT “iki” in the numeral expression “ikişermilyon”; the same morpheme cannot c-command the M “milyon” or the PHRASE “ikimilyon” in a grammatical construction. However, it can c-command the PHRASE “üçyüz” in (23) or the M “yüz”. This asymmetry cannot be explained syntactically in terms of PSRs. I argue it is possible to explain this asymmetry by referring to the categorial features of numerals. While the number “üç” in (23) has the categorial features [+N] and [+NUM], the number “yüz” has the categorial features [+N], [+NUM] and [+M]. On the other hand the number “million” in (24) has the categorial features [+N] and [+M]. When we compare these categorial features, we see that “milyon” lacks the feature [+NUM]. On this respect I argue that the distributional numeral morpheme can c-command a DIGIT with [+NUM] feature or a PHRASE with an M constituent bearing the feature [+NUM].
After considering the morphosyntactic properties of numerals, now we may now proceed to the morphosyntactic properties of fractional numerals in Turkish.
3.5. Morphosyntactic Properties of Fractional Numerals in Turkish
The fractional numerals, which express a part of a whole or a fraction of an integer, present different structural configurations in Turkish. In addition to reserved words such as “çeyrek (quarter), buçuk (half), yarım (halve), yarı (half)”, there are syntactic structures that express fractionals such as “dörttebir (one forth), üçbölüiki (three divided by two), üçvirgüliki (three point two)” in Turkish (Göksel & Kerslake, 2005: p. 182) .
![]()
The categorial features of the reserved words expressing fractions are as below:
![]()
The fractional numeral “buçuk” can bear the nominal morphemes; however, although it can bear the fractional numeral morpheme and has the [+NUM] feature, the use of “buçuk” as a modifier on its own may not sound too well-formed:
![]()
The fractionals “çeyrek” and “yarım” in (28a)-(28c) can bear the nominal morphemes, can function as modifiers and can function as M in numeral expressions.
![]()
As the word “yarı” does not have the [+NUM] and [+M] features, it is used as a noun in genitive-possessive constructions and gives a fractional reading:
![]()
Apart from the reserved words mentioned in the examples above, Turkish fractional numerals can be formed using complex syntactic structures.
![]()
Hurford states that fraction is the division of the value given in the first constituent of the numeral expression to the value of the second constituent (Hurford, 2010: p. 123) . Hurford proposes the PSRs below for the fractional numeral expressions:
![]()
According to the PSR in (31a) a numeral expression can be comprised of a DIGIT, a FRACTION or a PHRASE. The PSR in (31b) states that a FRACTION can be comprised of two NUMBER constituents. Hurford (2010) does not give further details about fractional numerals and does not explain the complex syntactic structures in the fractional numeral expressions.
In this study, differently from Hurford (2010) , I propose a new set of PSRs that would devise a unified approach to numeral expressions including fractional numerals:
![]()
According to the PSRs in (32) a fractional numeral expression is a phrase comprising of a NUMBER constituent and the FRACTION constituent. The PSRs in (32) can explain the fractional numerals in Turkish formed with both reserved words and complex syntactic structures.
![]()
![]()
In (34) I assume, following Svenious (2004) , the constituent “üçte” in the fraction phrase (FRACTIONP) is a case phrase (KP) since it contains a case morpheme “-te” and the features of the K head percolates up to the Fraction head. My aim here is to explain different fractional constructions in a unified manner.
![]()
In (36) two separate fractionals are used together. In the first part of the fractional expression, a lexical fractional expression “tam” is used, while in the second part a complex syntactic construction, a KP is used. There is another fractional numeral expression with the same value in Turkish as “ikivirgülüç”.
![]()
![]()
![]()
I propose that the “virgule” in (37) functions as a FRACTION head and the construction “ikivirgülüç” has a structure presented in (37b). We can see the similarity between (36b) and (37b) in (37c).
4. Conclusion
Numbers are frequently used in daily speech, yet the studies on the use and structure of numeral expressions are limited in Turkish. In this study, I tried to give a comprehensive account of numeral expressions in Turkish following the categorial classification of Booij (2009) and the syntactic analyses of Hurford (2007, 2010). In addition to these, I proposed a new approach to the fractional numeral expressions, explaining the syntactic structure with a unified approach. The new set of Phrase Structure Rules presented in the study can explain all kinds of numeral expressions, ordinal, cardinal, and fractional, with a single set of PSRs. The new PSRs can also explain different constructions for fractional numerals which seem very diverse. I believe that this study paves the way for future studies onmorphosyntactic properties of lexical items expressing units (length, weight, area, volume, etc.) and some reserved words such as “tane” (piece).