Non-Stationary Random Process for Large-Scale Failure and Recovery of Power Distribution ()
Received 11 May 2015; accepted 26 February 2016; published 29 February 2016

1. Introduction
The power grid is a vast interconnected network that delivers electricity to customers. Power distribution system lies at the edge of the power grid [1] . Power distribution provides medium and low voltages to residences and organizations. Distribution networks consist of a large numbers and diverse types of components, such as substations, power lines, poles, feeders, and transformers. Many such components are distributed in the open and exposed to external hazards such as hurricanes, derechoes, and ice storms [2] . About 90% of total failures occurred at power distribution [3] . Thus power distribution is particularly susceptible to external disruptions from severe weather [3] .
A fundamental research issue pertaining to this real problem is the resilience of power distribution to large- scale external disruptions. Here, resilience corresponds to the ability of power distribution to reduce failures and recover rapidly when failed [4] . Until now, tremendous efforts have been directed to resilience of the core that consists of the major power generation and transmission of high voltages [5] - [7] . For example, cascading failures at transmission networks have been studied widely [6] [8] - [11] . However, the majority of the failures occurred during severe storms are often at power distribution rather than transmission networks [12] . As the demand for energy grows, the edge of the grid becomes more and more important. For example, a utility (dis- tribution system operator) can serve millions of customers in America. Damages from such hazards as severe storms to power distribution can profoundly impact a large number of users. Hence, the resilience of power distribution requires significant study. Resilience of power distribution under severe weather poses unique challenges:
・ Randomness and dynamics (i.e., non-stationarity) of failures and recoveries,
・ Time-varying resilience at the network level,
・ Estimation of non-stationarity and the resilience using real data from the electric grid.
A pertinent first step is to model large-scale failures and recoveries. Such a model is a prerequisite for deriving a resilience metric at the network level. The metric needs to reflect the intrinsic characteristics of large- scale failures and recoveries. Severe weather disruptions such as hurricanes evolve randomly and dynamically. So do large-scale failure and recovery at power distribution. For example, failures occur and recover depending on random factors such as the intensity of a storm and dynamic allocations of repair crews. These factors vary with time. Hence, it is appropriate to model based on non-stationary random processes.
Prior approaches account for randomness of failures but rarely dynamics [6] [9] [13] - [15] . Models for failures are widely studied in computer-communication, e.g., finite state Markov process [16] and reliability of other multi-component systems [17] [18] . These models are stochastic but assume stationary properties or distributions. Stochastic models and random processes are also studied for other aspects of power distribution systems (e.g., forecasting and modeling renewable resources and power generations [19] - [21] , stability of power flows [22] , demand response [23] , maintenance process [24] , and degradation process [25] ). We develop an approach to learn from data for non-stationary stochastic processes on weather-induced failures and recoveries [26] .
Another challenge is how to quantify the resilience of power distribution. Resilience in this work measures the performance of power distribution during severe weather. In principle, such a resilience metric should manifest the difference between the performance in severe weather and normal operations [4] . Various reliability metrics are developed and widely used, including the IEEE standard indices for power systems [27] . The reliability metrics are for daily operations where disruptive events (e.g., severe weather) are excluded [27] . It is thus infeasible for the reliability measures to be used to study resilience that focuses on power failures and recoveries induced by severe weather events. During a severe weather event such as a hurricane, large-scale failures and recoveries can occur, which is significantly different from that in daily operations. Resilience metrics are thus open and much needed for both industry and communities as advocated by the recent reports in the nation [3] [28] . Several resilience measures are developed by the prior works, including a static metric of fragility [29] and dynamic metrics of functionality or quality [4] . How resilience evolves with time is modeled by brute force [4] [30] or averaging over time [31] [32] . In principle, resilience as a performance measure at the system-level is lacking. Such a resilience metric needs to be derived from a system model of failures and recoveries.
A third challenge is that unknown parameters of non-stationary models and a resilience metric need to be estimated from real data [33] . Prior works studied the power failures using historical data from previous storms [13] [34] - [36] . As the models were static, the learned parameters provided the static characteristics of power failures. Dynamic characteristics of power failures have been studied little from real data. Recovery is rarely studied using real data. A challenge is to learn from one external disruption such as a hurricane, as real data is rare and often unavailable from many large-scale weather disruptions.
The contribution of this work is to address the above three challenges, which are:
・ To develop a model based on non-stationary random processes,
・ To derive a dynamic resilience metric based on the model,
・ To learn time-varying model parameters and resilience metric using large-scale real data.
We first formulate, from bottom up, an entire life cycle of large-scale failure and recovery. The problem formulation begins at the finest level of network nodes based on temporal-spatial stochastic processes. Since each external disruption results in one snapshot of nodal states (failed and normal), information from one weather event is insufficient for completely specifying a temporal-spatial model [37] . Thus we focus on temporal models by aggregating spatial variables. Such an aggregation enables this work to focus on the non-stationary nature of failure and recovery at a moderate time scale, e.g., minutes and beyond. Such a time scale concurs with that of an evolution of a severe storm [38] . Failure and self-recovery that occur in seconds or shorter within power distribution systems are studied in other contexts [39] .
A resulting temporal model can be approximated by a 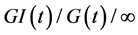 queue [40] . The arrival process to the queue characterizes failures with a general time-varying distribution
queue [40] . The arrival process to the queue characterizes failures with a general time-varying distribution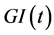 . The service time of the queue corresponds to the delay for failures to recover, and has a general time-varying distribution
. The service time of the queue corresponds to the delay for failures to recover, and has a general time-varying distribution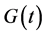 .
. 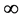 means that it is possible for failures to recover immediately. Note that such a queue is easily extensible to multiple queues at different geo-locations [26] without loss of generality. Such a queuing model is an approximation of recovery in practice as first-come-first-service policy is assumed. When recovery is conducted with certain optimality, intuitively such a model services provides a “lower bound” for the performance of restoration.
means that it is possible for failures to recover immediately. Note that such a queue is easily extensible to multiple queues at different geo-locations [26] without loss of generality. Such a queuing model is an approximation of recovery in practice as first-come-first-service policy is assumed. When recovery is conducted with certain optimality, intuitively such a model services provides a “lower bound” for the performance of restoration.
We study an analytically tractable case of 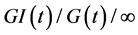 queue through the Transient Little’s Law [40] , which characterizes an entire non-stationary life-cycle of large-scale failures. The importance of Transient Little’s Law is that two simple quantities, failure rate and probability distribution of failure duration, completely quantify the dynamic model to the first moments. This simplifies definition of dynamic resilience and estimation of models parameters from data. We define a dynamic resilience metric that includes not only resistance to failures but also fast recovery as one additional attribute. Such a dynamic metric shows the time-evolution of network resilience during an external disruption. Finally, the non-stationary model and the resilience metric are applied to a real life example of large scale failures of power distribution. The failures occurred during Hurricane Ike in 2008. Real data from power distribution is used to study failure and recovery processes as well as resilience.
queue through the Transient Little’s Law [40] , which characterizes an entire non-stationary life-cycle of large-scale failures. The importance of Transient Little’s Law is that two simple quantities, failure rate and probability distribution of failure duration, completely quantify the dynamic model to the first moments. This simplifies definition of dynamic resilience and estimation of models parameters from data. We define a dynamic resilience metric that includes not only resistance to failures but also fast recovery as one additional attribute. Such a dynamic metric shows the time-evolution of network resilience during an external disruption. Finally, the non-stationary model and the resilience metric are applied to a real life example of large scale failures of power distribution. The failures occurred during Hurricane Ike in 2008. Real data from power distribution is used to study failure and recovery processes as well as resilience.
The rest of the paper is organized as follows. Section 2 provides background knowledge and an example of large-scale failures at power distribution. Section 3 develops a problem formulation from nodes (components) to 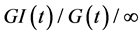 queue at the network level. Transient Little’s Law is applied to obtain the non-stationary failure and recovery rates. Section 4 defines resilience based on the non-stationary model. Section 5 estimates pertinent model parameters and the resilience metric using large-scale real data. Section 6 discusses our findings and concludes the paper.
queue at the network level. Transient Little’s Law is applied to obtain the non-stationary failure and recovery rates. Section 4 defines resilience based on the non-stationary model. Section 5 estimates pertinent model parameters and the resilience metric using large-scale real data. Section 6 discusses our findings and concludes the paper.
2. Background and Example
To provide intuition for modeling on failures and recoveries induced by severe weather, we begin with two examples.
2.1. Synthetic Example
The first example illustrates how failures can be induced by severe weather. The example is on a small section of a power distribution system drawn from [13] and shown in Figure 1(a). The section consists of two sources  and
and , seven components
, seven components 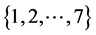 and five loads
and five loads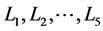 . A component can be a transformer, a feeder, a pole, or a circuit. Links correspond to power lines. Assume either a source or a component or a link can fail during a hurricane. Assume primary source
. A component can be a transformer, a feeder, a pole, or a circuit. Links correspond to power lines. Assume either a source or a component or a link can fail during a hurricane. Assume primary source 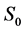 is used in normal operations; and back-up source
is used in normal operations; and back-up source 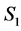 is used if
is used if 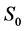 fails. The following scenarios can occur:
fails. The following scenarios can occur:
a) If any of the components 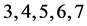 fails independently due to an external disruption, and if both the primary and the back-up sources can be in operation, there is no electricity supply to the loads that are connected to the failed components. Thus, the components and the loads experience independent failures. Such independent failures can be caused directly by external factors at a time scale of a minute or beyond.
fails independently due to an external disruption, and if both the primary and the back-up sources can be in operation, there is no electricity supply to the loads that are connected to the failed components. Thus, the components and the loads experience independent failures. Such independent failures can be caused directly by external factors at a time scale of a minute or beyond.
b) If ![]() and
and ![]() both fail due to an external disruption, there is no electricity supply to any loads. Hence, the components and loads experience dependent failures that can occur at the same time. The scenario of dependent failures also applies to failed substations and other components upstream in a radial topology of power distribution that cause loss of electricity at other nodes. Such dependent failures often occur within a time scale of seconds. Note that such dependent failures do not exhibit cascading effects that occurred in transmission networks due to a radial topology of power distribution.
both fail due to an external disruption, there is no electricity supply to any loads. Hence, the components and loads experience dependent failures that can occur at the same time. The scenario of dependent failures also applies to failed substations and other components upstream in a radial topology of power distribution that cause loss of electricity at other nodes. Such dependent failures often occur within a time scale of seconds. Note that such dependent failures do not exhibit cascading effects that occurred in transmission networks due to a radial topology of power distribution.
c) Recovery depends on the types of failures, restoration schemes, as well as the terrene conditions. For example, if either source ![]() or component 1 or component 2 fails, the electricity supply to all loads can be recovered almost immediately when
or component 1 or component 2 fails, the electricity supply to all loads can be recovered almost immediately when ![]() is in operation. Generalizing this scenario, self-recovery and automated reconfiguration built in power distribution usually operate within seconds [41] . However, if a power line to a load fails because of a fallen tree, the recovery may require dispatching crews to the field, and thus be prolonged depending on environmental constraints, preparedness, and resources.
is in operation. Generalizing this scenario, self-recovery and automated reconfiguration built in power distribution usually operate within seconds [41] . However, if a power line to a load fails because of a fallen tree, the recovery may require dispatching crews to the field, and thus be prolonged depending on environmental constraints, preparedness, and resources.
In summary, failures and self-recoveries in a small time-scale of seconds depend on detailed topology and self-recovery schemes. Failure and recovery at a larger time scale of minutes and beyond are often due to external disruptions that evolve dynamically and randomly.
2.2. Real Data
The second example illustrates non-stationary failures and recoveries. The example uses real data on an operational power distribution system during Hurricane Ike. Hurricane Ike occurred in 2008 and affected more than 2 million customers at densely populated areas in Texas and Louisiana. Figure 1(b) shows a histogram on failure occurrence time and duration at the distribution network before, during and after the hurricane (see Section 5 for details on the data). The histogram demonstrates the non-stationarity of the power failures and recoveries during the hurricane:
a) Failure occurrence was time-varying and random. More failures occurred during the hurricane than those that occurred before and after.
b) Recovery time was also time-varying and random. Recovery time was different for failures occurred at different time. For example, more failures occurring during the hurricane recovered slowly than those that occurred before and after.
As the result, the probability distributions of failure-occurrence and failure duration vary with time in minutes and hours. Note that information on root causes of failures and recoveries is unavailable, which is beyond the scope of this work.
3. Stochastic Model
We now formulate time evolution of large-scale failure and recovery as a non-stationary random process. We begin with detailed information on nodal states (failure and normal). We then aggregate the spatial variables of nodes to obtain the temporal evolution of failure and recovery of an entire network.
3.1. Failure and Recovery Probability
A spatial-temporal random process provides theoretical basis for modeling large-scale failures at the finest scale of nodes (component). The shorthand notation i is used to specify both the index of a node and its corresponding geo-location, where ![]() for a power distribution network with n nodes. The temporal variable is continuous time t.
for a power distribution network with n nodes. The temporal variable is continuous time t.
Let ![]() be the state of the i-th node at
be the state of the i-th node at![]() , where
, where![]() . Two states are considered for a node.
. Two states are considered for a node. ![]() if the i-th node is in failure, e.g., there is no electricity supply at location i and time t.
if the i-th node is in failure, e.g., there is no electricity supply at location i and time t. ![]() if the node is in normal operations. Here, two-state rather than multi-state failure models are considered for simplicity. A network state is then characterized by
if the node is in normal operations. Here, two-state rather than multi-state failure models are considered for simplicity. A network state is then characterized by![]() . For analytical tractability, failures and recoveries are assumed to have been detected already [42] . Hence state estimation from power flows [43] is out of the scope of this work.
. For analytical tractability, failures and recoveries are assumed to have been detected already [42] . Hence state estimation from power flows [43] is out of the scope of this work.
Failures caused by external disruptions exhibit randomness. Whether and when a node fails is random. Whether and when a failed node recovers is also random. Given time![]() ,
, ![]() characterizes the probability that node i is in the failure state at
characterizes the probability that node i is in the failure state at![]() , where
, where ![]() is a small time duration. Assume a node changes state, i.e., from failure to normal and vice versa. Then for the i-th node,
is a small time duration. Assume a node changes state, i.e., from failure to normal and vice versa. Then for the i-th node, ![]() ,
,
![]() (1)
(1)
Equation (1) models an individual node in a network. The model includes Markov temporal dependence for nodal states which is a simple assumption for state transitions. Such a model can be applied to a heterogeneous grid where nodes experience different failure and recovery processes in general. There are no assumptions on an underlying network topology nor independence/dependence of failures. Such n equations for n nodes together form a spatial-temporal model for a network.
Each severe weather event generates one snapshot of network states. Information available on failures and recoveries is often from one or a few events. Such information is insufficient for specifying the spatial-temporal model. Hence, we derive a temporal model in this work by considering an entire network as a whole.
3.2. Temporal Process
Our temporal model aggregates spatial variables from Equation (1),
![]() (2)
(2)
The probability can be further related to an indicator function, e.g.,![]() . We now define a temporal process as follows.
. We now define a temporal process as follows.
Definition 1. Let ![]() be the number of nodes in the failure state at time t.
be the number of nodes in the failure state at time t. ![]() is a temporal random process, where
is a temporal random process, where
![]() (3)
(3)
![]() is an indicator function, i.e.,
is an indicator function, i.e., ![]() if event A occurs, and
if event A occurs, and![]() , otherwise.
, otherwise.
Let ![]() represent an increment of the number of failures in interval
represent an increment of the number of failures in interval![]() . Combining Equations 2 and 3, the expected increment of failures at time t is
. Combining Equations 2 and 3, the expected increment of failures at time t is
![]() (4)
(4)
An increment ![]() for the total number of nodes in a failure state can result from either newly failed or newly recovered nodes. To further characterize the temporal process, we define a failure process and a recovery process respectively.
for the total number of nodes in a failure state can result from either newly failed or newly recovered nodes. To further characterize the temporal process, we define a failure process and a recovery process respectively.
Definition 2. Failure process ![]() is the number of failures that occur up to time t.
is the number of failures that occur up to time t.
Now we assume that failure ![]() is a counting process with independent increments (given weather conditions): For any
is a counting process with independent increments (given weather conditions): For any![]() , increments
, increments ![]() ‘s are independent. Such independence assumption results naturally from randomly occurring failures given weather conditions. Here the assumption holds at the time scale of minutes or hours at which severe weather (e.g., high-speed wind) evolves. Dependent failures can occur at smaller time scale of seconds, which is due to a structure of power distribution [39] . This is beyond the scope of here and will be addressed in a subsequent work. Hence the time-scale of failure processes is assumed to be in minutes here.
‘s are independent. Such independence assumption results naturally from randomly occurring failures given weather conditions. Here the assumption holds at the time scale of minutes or hours at which severe weather (e.g., high-speed wind) evolves. Dependent failures can occur at smaller time scale of seconds, which is due to a structure of power distribution [39] . This is beyond the scope of here and will be addressed in a subsequent work. Hence the time-scale of failure processes is assumed to be in minutes here.
Definition 3. Recovery process ![]() is the number of recoveries that occur up to time t.
is the number of recoveries that occur up to time t.
Assume ![]() is sufficiently small so that at most one failure occurs during
is sufficiently small so that at most one failure occurs during![]() . Then,
. Then,
![]() (5)
(5)
Similarly, assume that, at most one recovery occurs during ![]() for a sufficiently small
for a sufficiently small![]() . Let
. Let ![]() be an increment of the number of recoveries. Then,
be an increment of the number of recoveries. Then,
![]() (6)
(6)
Here recovery time (or failure duration) is also assumed at the time scale of minutes. Equation (2) can be rewritten as![]() . Furthermore, assume at
. Furthermore, assume at![]() ,
, ![]() ,
, ![]() , and
, and![]() . Aggregating increments from 0 to t, we have
. Aggregating increments from 0 to t, we have![]() . This is intuitive that the number of failures equals to the difference between the total failures and the recoveries occurred so far.
. This is intuitive that the number of failures equals to the difference between the total failures and the recoveries occurred so far.
Hence, the expected number of nodes in the failure state equals the difference between the expected failures and the expected recoveries. The time-scale of a minute enables this work to focus on modeling failures that are induced by external disruptions and the recoveries that can not be accomplished by instant self-healing schemes. The aggregation conceals spatial variables [26] , network topology [39] and automated reconfiguration that are not discussed in this work.
3.3. Dynamic Queuing Model and Transient Little’s Law
Failure ![]() and recovery
and recovery ![]() can be further related through a time-varying
can be further related through a time-varying ![]() queue [40] [44] as shown in Figure 2.
queue [40] [44] as shown in Figure 2.
1) The arrival process to the queue corresponds to the number of failures ![]() with independent increments. The increments have a general time-varying distribution
with independent increments. The increments have a general time-varying distribution![]() .
.
2) A failure that occurs in ![]() experiences delay
experiences delay ![]() before recovery. The delay corresponds to failure duration and has a general time-varying probability density function
before recovery. The delay corresponds to failure duration and has a general time-varying probability density function![]() .
.
3) The departure process of the queue corresponds to the number of recoveries![]() .
. ![]() implies an infinite number of servers for repair. This means that it is possible for recovery to occur right after failure.
implies an infinite number of servers for repair. This means that it is possible for recovery to occur right after failure.
A ![]() queue is applied here for the first time to characterize the temporal characteristics of a non-stationary joint failure-recovery process. Analytical expressions of departure processes are often intractable for general arrival processes. But the expected number of failures and recoveries, i.e., the first moments of the arrival and departure processes, can be quantified in a simple form through Transient Little’s Law [40] . In fact,
queue is applied here for the first time to characterize the temporal characteristics of a non-stationary joint failure-recovery process. Analytical expressions of departure processes are often intractable for general arrival processes. But the expected number of failures and recoveries, i.e., the first moments of the arrival and departure processes, can be quantified in a simple form through Transient Little’s Law [40] . In fact,
![]()
Figure 2. Application of ![]() queue and transient little’s law.
queue and transient little’s law.
Transient Little’s Law provides an analytically tractable case of ![]() queue [40] .
queue [40] .
Theorem 1. Transient Little’s Law [40]
Consider ![]() as an independent counting process. Let
as an independent counting process. Let ![]() be the delay for an arrival in
be the delay for an arrival in![]() , where
, where![]() . Assume that an arrival of an increment does not affect the delay of previously arrived increments. Then the expected number of arrivals in the queue at time t is
. Assume that an arrival of an increment does not affect the delay of previously arrived increments. Then the expected number of arrivals in the queue at time t is
![]() (7)
(7)
where ![]() is the arrival rate,
is the arrival rate,
![]() (8)
(8)
Consider an increment of arrivals as new failures, an arrival rate as a failure rate, a delay as a failure duration, and departures as recoveries. Assume that recoveries occur following first-in-first-out (FIFO) policy. Transient Little’s Law can then be directly applied to our problem. The theorem has an intuitive explanation: ![]() is the average number of arrivals (failures) in
is the average number of arrivals (failures) in![]() , where
, where ![]() is sufficiently small.
is sufficiently small. ![]() is the probability that an arrival (failure) at
is the probability that an arrival (failure) at ![]() does not recover until time t. Hence,
does not recover until time t. Hence, ![]() is the total average number of failures that do not recover until time t. The mathematical proof of the theorem can be found in [40] .
is the total average number of failures that do not recover until time t. The mathematical proof of the theorem can be found in [40] .
Define recovery rate ![]() as the expected number of new recoveries per unit time at time t,
as the expected number of new recoveries per unit time at time t,
![]() (9)
(9)
Applying Transient Little’s Law, the recovery rate can be related to a failure rate and a recovery time distribution by the corollary below.
Corollary 1. Let ![]() be an independent (failure) increment process with a rate function
be an independent (failure) increment process with a rate function![]() . Let
. Let ![]() be a failure duration with a conditional probability density function
be a failure duration with a conditional probability density function![]() , where
, where![]() ,
,![]() . Then recovery rate
. Then recovery rate ![]() satisfies
satisfies
![]() (10)
(10)
The proof of the corollary is in Appendix 1. In summary, two pertinent quantities completely determine the expected number of failures and recoveries: Failure rate ![]() and probability density function of failure duration given failure occurrence time
and probability density function of failure duration given failure occurrence time![]() .
.
4. Resilience
We now derive a resilience metric using the pertinent parameters for an entire life cycle of non-stationary failure and recovery. While resilience can be characterized from multiple dimensions [4] , the infrastructure of power distribution is where failures occur. Hence we quantify the so-called (system) resilience by characterizing failures and recoveries of all nodes in a distribution network.
4.1. Infant and Aging Recovery
For an non-stationary recovery process, a failure duration depends on when the failure occurs (Figure 1). Given threshold![]() , the conditional probability that duration
, the conditional probability that duration ![]() is bounded by
is bounded by ![]() for failures that occur at time t is
for failures that occur at time t is
![]() (11)
(11)
When ![]() is sufficiently small, this probability characterizes rapid recovery referred to as infant recovery. This terminology is borrowed from infant mortality in survivability analysis [45] . Infant recovery is a desirable characteristic of power distribution. In contrast, slow recovery is referred to as aging recovery that is analogous to aging mortality [46] . Obviously, aging recovery is undesirable.
is sufficiently small, this probability characterizes rapid recovery referred to as infant recovery. This terminology is borrowed from infant mortality in survivability analysis [45] . Infant recovery is a desirable characteristic of power distribution. In contrast, slow recovery is referred to as aging recovery that is analogous to aging mortality [46] . Obviously, aging recovery is undesirable.
Definition 4. Infant and aging recovery
Let ![]() be a threshold value. If a node remains in failure for a duration less than
be a threshold value. If a node remains in failure for a duration less than![]() , a recovery is an infant recovery. Otherwise, the recovery is an aging recovery. Infant recovery is characterized by
, a recovery is an infant recovery. Otherwise, the recovery is an aging recovery. Infant recovery is characterized by![]() . Aging recovery is characterized by
. Aging recovery is characterized by![]() .
.
Note here ![]() is a function of failure occurrence time. Hence, in general, a recovery process is non-stationary.
is a function of failure occurrence time. Hence, in general, a recovery process is non-stationary.
4.2. Dynamic Resilience Metric
As failure and recovery processes are dynamic, a resilience metric should be dynamic also. Furthermore, how resilience varies with time should result from the dynamic model of failure-recovery processes. Following such a principle, we define resilience from bottom-up, starting with one node. Probability ![]() that node i is in normal operations characterizes the ability to resist to failures at time t. Probability of infant recovery
that node i is in normal operations characterizes the ability to resist to failures at time t. Probability of infant recovery ![]() characterizes the ability of the node to quickly recover. Combining these two abilities, we define resilience as follows.
characterizes the ability of the node to quickly recover. Combining these two abilities, we define resilience as follows.
Definition 5. Resilience of a node
Given threshold value ![]() on failure durations, resilience
on failure durations, resilience ![]() for node i is the probability that the node is either functioning or exhibiting infant recovery, where
for node i is the probability that the node is either functioning or exhibiting infant recovery, where
![]() (12)
(12)
Aggregating the resilience of nodes over an entire network, (system) resilience ![]() is the expected percentage of nodes that are either functioning or recovering within
is the expected percentage of nodes that are either functioning or recovering within ![]() upon failures.
upon failures.
Definition 6. Resilience of a network
Given threshold value ![]() on failure durations, resilience
on failure durations, resilience ![]() of a network is
of a network is
![]() (13)
(13)
Hence, aggregating over spatial variables, network topology and automated reconfiguration, the resilience of a network is an average resilience of all network nodes:
![]() (14)
(14)
![]() exhibits the following properties:
exhibits the following properties:
1) Resilience is a property of a distribution network as a whole to survive large-scale external disruptions.
2) Resilience is a function of time that reflects temporal evolutions of failures and recoveries in a network.
3) Resilience shows the ability of a distribution network to resist failures and recover rapidly.
4) Resilience depends on threshold ![]() on failure durations. The failures that can recover within
on failure durations. The failures that can recover within ![]() are considered tolerable in terms of the resilience metric. When
are considered tolerable in terms of the resilience metric. When![]() , the resilience metric offers no tolerance to delays in recovery, and only characterize the ability of resisting to failures.
, the resilience metric offers no tolerance to delays in recovery, and only characterize the ability of resisting to failures.
4.3. Resilience Parameters
The resilience metric can be characterized by the parameters of the model, i.e., non-stationary random processes in Section 1. In particular, the resilience metric (Equation (13)) can be represented through a simple expressions owing to Transient Little’s Law,
![]() (15)
(15)
The second term corresponds to the aging recoveries at time t. Let ![]() and
and ![]() is the conditional cumulative distribution function of duration
is the conditional cumulative distribution function of duration![]() . The resilience can also be viewed as one minus the expected percentage of nodes in aging recovery.
. The resilience can also be viewed as one minus the expected percentage of nodes in aging recovery.
The above expression shows that given threshold![]() , two parameters
, two parameters ![]() and
and ![]() together determine the system resilience. A smaller failure rate results in more functioning network nodes and thus a larger resilience. A higher percentage of infant recovery results in a fewer aging recoveries and thus a larger resilience. Our model is determined by these two time-varying parameters to the first moments (see Section 1). So is the resilience metric.
together determine the system resilience. A smaller failure rate results in more functioning network nodes and thus a larger resilience. A higher percentage of infant recovery results in a fewer aging recoveries and thus a larger resilience. Our model is determined by these two time-varying parameters to the first moments (see Section 1). So is the resilience metric.
4.4. Resilience of Non-Homogeneous Poisson Processes
A special case of resilience is when the failure process is a Non-Homogeneous Poisson Process (NHPP). As a commonly-used failure process [47] , a non-homogeneous Poisson Process ![]() has independent increments and can be completely determined by time-varying rate function
has independent increments and can be completely determined by time-varying rate function![]() ,
,
![]() (16)
(16)
When a failure process is an NHPP, a ![]() queue reduces to a
queue reduces to a ![]() queue.
queue. ![]() represents a Poisson failure process with a time-varying rate. Furthermore, a recovery process is also an NHPP [40] . When
represents a Poisson failure process with a time-varying rate. Furthermore, a recovery process is also an NHPP [40] . When![]() , the recovery process becomes stationary.
, the recovery process becomes stationary. ![]() model reduces to
model reduces to ![]() queue developed in [48] .
queue developed in [48] .
4.5. Threshold
Threshold ![]() is a pertinent parameter that measures the degree of resilience in terms of infant recovery.
is a pertinent parameter that measures the degree of resilience in terms of infant recovery. ![]() can be determined by service requirements. For example,
can be determined by service requirements. For example, ![]() hours is used by Distribution System Operators (power utilities) when it is acceptable to restore a failure within 24 hours after severe weather strikes.
hours is used by Distribution System Operators (power utilities) when it is acceptable to restore a failure within 24 hours after severe weather strikes.
![]() can characterize a special value of
can characterize a special value of ![]() as follows. Consider a scenario where failures occur suddenly and intensely due to severe storm, e.g., from a hurricane. That is,
as follows. Consider a scenario where failures occur suddenly and intensely due to severe storm, e.g., from a hurricane. That is, ![]() characterizes impulse-like failures that increases sharply from a small value,
characterizes impulse-like failures that increases sharply from a small value, ![]() , at time 0 (normal operation) to a large value,
, at time 0 (normal operation) to a large value, ![]() , in short duration
, in short duration![]() . The failure rate can then be written as
. The failure rate can then be written as![]() , where
, where ![]() is the unit step function and
is the unit step function and![]() . Furthermore, consider a special case when infant recovery dominates, i.e.,
. Furthermore, consider a special case when infant recovery dominates, i.e., ![]() for
for![]() . This implies that all failures recover within duration
. This implies that all failures recover within duration![]() . The expected number of nodes in failures at time t is
. The expected number of nodes in failures at time t is
![]() (17)
(17)
where![]() . The terms
. The terms ![]() include the remnants when
include the remnants when ![]() is approx- imated using the first-moment
is approx- imated using the first-moment![]() . This expression shows that infant recoveries occur within
. This expression shows that infant recoveries occur within ![]() after failures erupt. Here
after failures erupt. Here ![]() is assumed to be larger than the duration of failure process
is assumed to be larger than the duration of failure process ![]() for simplicity. In contrast, when aging recovery dominates,
for simplicity. In contrast, when aging recovery dominates, ![]() for
for![]() . The expected number of nodes in failure at time t is
. The expected number of nodes in failure at time t is
![]() (18)
(18)
where![]() . This expression shows that aging recoveries do not start until delaying
. This expression shows that aging recoveries do not start until delaying ![]() from the eruption of failures.
from the eruption of failures.
In general, a failure-recovery process can be regarded as a combination of these two special cases. At time![]() , when a severe storm starts to impact a power grid, the failure process dominates, and
, when a severe storm starts to impact a power grid, the failure process dominates, and ![]() increases rapidly. The recovery process starts after occurrences of failures, and gradually dominates. When parts of the failures recover within time duration
increases rapidly. The recovery process starts after occurrences of failures, and gradually dominates. When parts of the failures recover within time duration ![]() (i.e., as infant recoveries), there can be a sharp decrease in
(i.e., as infant recoveries), there can be a sharp decrease in![]() . The remaining failures are restored with longer delays as aging recoveries. Therefore after the sharp decrease,
. The remaining failures are restored with longer delays as aging recoveries. Therefore after the sharp decrease, ![]() may decrease at a slower rate. Following these scenarios, we expect to see a sharp decrease after a sharp increase in the temporal curve of
may decrease at a slower rate. Following these scenarios, we expect to see a sharp decrease after a sharp increase in the temporal curve of![]() . The time delay between the two sharp changes can be chosen as
. The time delay between the two sharp changes can be chosen as![]() , where
, where
![]() (19)
(19)
5. Numerate Results of Real Data
We apply the non-stationary failure-recovery processes to a real-life example of large-scale failures caused by a hurricane. Our focus is on estimating the three pertinent quantities![]() ,
, ![]() and threshold
and threshold ![]() using real data. These parameters are then used to measure dynamic resilience of an operational power distribution network.
using real data. These parameters are then used to measure dynamic resilience of an operational power distribution network.
5.1. Real Data and Processing
Hurricane Ike was one of the strongest hurricanes that occurred in 2008. Ike caused large scale power failures, resulted in more than two million customers without electricity, and was considered by many as the second costliest Atlantic hurricane of all time [49] [50] .
Reported by the National Hurricane Center [38] , the storm started to cause power outages across the onshore areas in Louisiana and Texas on September 12, 2008 prior to the landfall. Ike then made the landfall at Galveston, Texas at 2:10 a.m. Central Daylight Time (CDT), September 13, 2008, causing strong winds, flooding, and heavy rains across Texas. The hurricane weakened to a tropical storm at 1:00 p.m. September 13 and passed Texas by 2:00 a.m. September 14.
Widespread power failures were reported across Louisiana and Texas starting September 12 [50] . A major utility collected data on power failures from more than ten counties. The outages included various component failures in the distribution network such as failed circuits, fallen trees/poles, and non-operational substations. The raw data set consists of 5152 samples. Each sample consists of the failure occurrence time (![]() ) and duration (
) and duration (![]() ) of a component (i) in a distribution network. The accuracy for time t is one minute. In the data set, 2005 samples were from 7 a.m. September 12 to 4 a.m. September 14, during which Hurricane Ike made the landfall in Texas. These failures are considered to be resulting from the hurricane, and form our data set.
) of a component (i) in a distribution network. The accuracy for time t is one minute. In the data set, 2005 samples were from 7 a.m. September 12 to 4 a.m. September 14, during which Hurricane Ike made the landfall in Texas. These failures are considered to be resulting from the hurricane, and form our data set.
Among the 2005 samples, there are groups of failures that occurred within a minute. Failures within a group are considered as dependent and aggregated as one failed entity. Each group has a unique failure occurrence time ![]() and duration
and duration![]() . There were also groups of failures that recovered within a minute that are combined as one entity of recovery also. After preprocessing the groups as one entity, the resulting data set had 465 failed entities at the time scale of a minute. Two outliers with negative failure duration were further removed. The remaining 463 failed entities from 7 am September 12 to 4 am September 14 form data set
. There were also groups of failures that recovered within a minute that are combined as one entity of recovery also. After preprocessing the groups as one entity, the resulting data set had 465 failed entities at the time scale of a minute. Two outliers with negative failure duration were further removed. The remaining 463 failed entities from 7 am September 12 to 4 am September 14 form data set![]() .
.
The 463 samples are then randomly partitioned into a training set of 333 samples and a test set of 130 samples. The training set is used to learn parameters. The test set is used for validating the model and the parameters.
5.2. Empirical Failure Process
We now use the data set to study the empirical processes![]() ,
, ![]() , and
, and ![]() which are sample means of the expectations
which are sample means of the expectations![]() ,
, ![]() , and
, and![]() , respectively.
, respectively.
5.2.1. Estimating Failure Rate
First, we use the training set to determine failure rate![]() . We estimate the empirical rate function through a
. We estimate the empirical rate function through a
simple moving average [51] :![]() , where
, where ![]() hours. We use the training set to
hours. We use the training set to
estimate the failure rate and use the testing set to validate the estimation. Figure 3(a) shows the estimated failure rate and the estimation error with the 95% confidence interval. The failure rate increased and decreased in accordance with the evolution of the hurricanes. Before 7 p.m. September 12, when the hurricane was yet to arrive, the rate was less than 5 new failures per hour. Then the failure rate increased rapidly and reached the maximum value of 50 new failures per hour. The peak time of the failure rate coincided with the time of the landfall at 2:10 CDT September 13 [38] . After that, the failure rate reduced to a small value of less than 5 new failures per hour. As the failure rate was time varying, the failure process was non-stationary.
5.2.2. Non-Homogeneous Poisson Model
We now consider hypothesis ![]() that these 463 failure occurrences are governed by a non-homogeneous
that these 463 failure occurrences are governed by a non-homogeneous
Poisson process. If ![]() is true, the assumption of our model is validated that the failure occurrences have an independent increments.
is true, the assumption of our model is validated that the failure occurrences have an independent increments.
We perform Pearson’s test [52] on hypothesis ![]() that the empirical failure process
that the empirical failure process ![]() follows a non- homogeneous Poisson Process with rate function
follows a non- homogeneous Poisson Process with rate function![]() . The test focuses on two aspects: (a) the independence of the failures occurred at the large time scale of tens of minutes, and (b) the empirical rate function
. The test focuses on two aspects: (a) the independence of the failures occurred at the large time scale of tens of minutes, and (b) the empirical rate function ![]() is sufficient for characterizing the failure process. Detailed procedure of the test is in Appendix 2. The time duration is divided into 400 intervals between 7 a.m. September 12 and 4 p.m. September 14. In each interval, the number of new failures is compared with its expectation computed from
is sufficient for characterizing the failure process. Detailed procedure of the test is in Appendix 2. The time duration is divided into 400 intervals between 7 a.m. September 12 and 4 p.m. September 14. In each interval, the number of new failures is compared with its expectation computed from![]() . The sum of the square errors from all of the intervals results in a chi-square statistic. The chi-square statistic is
. The sum of the square errors from all of the intervals results in a chi-square statistic. The chi-square statistic is![]() , with a degree of freedom of 2. Given a confidence level at 95%, the threshold value is obtained as
, with a degree of freedom of 2. Given a confidence level at 95%, the threshold value is obtained as![]() , where
, where![]() . The chi-square statistic
. The chi-square statistic ![]() obtained from the data is below the threshold
obtained from the data is below the threshold![]() . Hence hypothesis
. Hence hypothesis ![]() is not rejected.
is not rejected.
However, not rejecting ![]() is insufficient for accepting the hypothesis. The goodness of fit of NHPP to the data is further validated through the Quantile-Quantile (QQ) plot as shown in Figure 3(b), where the samples are compared with an NHPP with rate function
is insufficient for accepting the hypothesis. The goodness of fit of NHPP to the data is further validated through the Quantile-Quantile (QQ) plot as shown in Figure 3(b), where the samples are compared with an NHPP with rate function![]() . The figure shows a good fit of the NHPP to the data. Hence, the 463 power failures occurred independently, and follow a non-homogeneous Poisson process.
. The figure shows a good fit of the NHPP to the data. Hence, the 463 power failures occurred independently, and follow a non-homogeneous Poisson process.
5.3. Empirical Recovery Process
Next we study empirical recovery-time distribution ![]() given the failure occurrence time. Our objective is to identify infant and aging recovery.
given the failure occurrence time. Our objective is to identify infant and aging recovery.
5.3.1. Data
The 463 samples in our data set consist of durations of the failures that occurred from 7 a.m. September 12 to 4 p.m. September 14. Figure 1(b) shows the joint empirical distribution ![]() of these samples. Each bin is two hours on failure occurrence time and 12 hours on failure durations. The height of each bin located at failure occurrence time t and duration d represents the number of failures that occurred at t and lasted for d hours.
of these samples. Each bin is two hours on failure occurrence time and 12 hours on failure durations. The height of each bin located at failure occurrence time t and duration d represents the number of failures that occurred at t and lasted for d hours.
5.3.2. Mixture Model
As the failure durations varied with the hurricane (Figure 1(b)), we choose a mixture model for the probability density function ![]() for duration
for duration ![]() give failure time t,
give failure time t,
![]() (20)
(20)
where ![]() is the number of mixtures at time t,
is the number of mixtures at time t, ![]() (
(![]() ) is a weighting factor for the jth mixture function
) is a weighting factor for the jth mixture function![]() , and
, and![]() . Both the mixture functions and the weight factors vary with failure time t for a non-stationary recovery process.
. Both the mixture functions and the weight factors vary with failure time t for a non-stationary recovery process.
We select a Weibull distribution as a mixture function because the parameters exhibit clear physical meaning [26] . Mathmatically the Weibull mixtures can be expressed as
![]() (21)
(21)
where![]() ,
, ![]() and
and ![]() are the shape and scale parameters respectively. When the shape parameter
are the shape and scale parameters respectively. When the shape parameter ![]() is less than 1 and/or the scale parameter
is less than 1 and/or the scale parameter ![]() are small,
are small, ![]() signifies short failure durations and thus the infant recovery. Weighting factor
signifies short failure durations and thus the infant recovery. Weighting factor ![]() characterizes the importance of a component
characterizes the importance of a component![]() . For a non-stationary recovery process, these parameters vary with failure time t.
. For a non-stationary recovery process, these parameters vary with failure time t.
5.3.3 Parameter Estimation
The parameters of the Weibull mixtures are estimated from the training samples. For simplicity, we divide the failure time into 5 intervals shown in Figure 1. Within an interval ![]() (
(![]() ),
),![]() is assumed to be a time homogeneous function that does not vary with failure time t. Across different intervals,
is assumed to be a time homogeneous function that does not vary with failure time t. Across different intervals, ![]() ‘s have different parameters for non-stationarity. The parameters of the mixtures of the Weibull distribution are estimated through maximum likelihood estimation [53] , and the estimated mixture distributions are shown in Figure 4. Each mixture represents one cluster of failure durations, and mixture parameters are different for different intervals. For example, in interval
‘s have different parameters for non-stationarity. The parameters of the mixtures of the Weibull distribution are estimated through maximum likelihood estimation [53] , and the estimated mixture distributions are shown in Figure 4. Each mixture represents one cluster of failure durations, and mixture parameters are different for different intervals. For example, in interval ![]() (the time when the network was not yet impacted by Hurricane Ike), most failure durations were as short as a few hours. In interval
(the time when the network was not yet impacted by Hurricane Ike), most failure durations were as short as a few hours. In interval![]() ,
, ![]() and
and ![]() (the reigning time of the hurricane), there were more prolonged failures, when restoration became more difficult than that for daily operations. The failure duration exhibits a distinct distribution for different intervals, confirming non-stationarity of the recovery process.
(the reigning time of the hurricane), there were more prolonged failures, when restoration became more difficult than that for daily operations. The failure duration exhibits a distinct distribution for different intervals, confirming non-stationarity of the recovery process.
5.4. Resilience
We now study time evolution of resilience. First, we obtain an optimal threshold ![]() for this power distribution network. The “optimal” threshold here refers to a best partition between the infant and aging recoveries. Such a partition is obtained empirically from data. Figure 5(a) shows the comparison between
for this power distribution network. The “optimal” threshold here refers to a best partition between the infant and aging recoveries. Such a partition is obtained empirically from data. Figure 5(a) shows the comparison between ![]() and
and![]() . As we expected,
. As we expected, ![]() first increased to its maximum value after the failures occurred, and then dropped to its minimum value. The duration between the maximum and the minimum is 15.50 hours. Thus
first increased to its maximum value after the failures occurred, and then dropped to its minimum value. The duration between the maximum and the minimum is 15.50 hours. Thus ![]() hours is identified as the threshold. The threshold is depicted in Figure 4. The mixture component that on the left of the threshold line corresponds to infant recovery. In total, 50.75% of the failures are categorized as infant recoveries.
hours is identified as the threshold. The threshold is depicted in Figure 4. The mixture component that on the left of the threshold line corresponds to infant recovery. In total, 50.75% of the failures are categorized as infant recoveries.
The network resilience is then obtained through Equation (15) using the failure rate ![]() and distribution of failure duration
and distribution of failure duration![]() . Figure 5 shows the time evolution of network resilience
. Figure 5 shows the time evolution of network resilience![]() . The dynamic evolution of resilience provides the following observations.
. The dynamic evolution of resilience provides the following observations.
![]()
Figure 4. Non-stationary (empirical) distribution of failure durations with respect to the failures occurred in the five intervals ![]() (
(![]() ) depicted in Figure 1(b). The width of each bar is 8 hours. The colors represent different mixtures of Weibull distribution.
) depicted in Figure 1(b). The width of each bar is 8 hours. The colors represent different mixtures of Weibull distribution.
![]()
![]() (a) (b)
(a) (b)
Figure 5. (a) Threshold![]() . (b) Dynamic evolution of resilience of the distribution network.
. (b) Dynamic evolution of resilience of the distribution network.
・ Prior to the hurricane, no failures occurred yet, and the resilience was close to 1.
・ A large number of failures then occurred and reduced the resilience to a lower level. How fast the resilience decreased was measured by![]() . The decreasing speed reached the maximum after 16.45 hours since the first failure appeared. In the meantime, the failure rate also reached the maximum.
. The decreasing speed reached the maximum after 16.45 hours since the first failure appeared. In the meantime, the failure rate also reached the maximum.
・ At 3 am September 14th, about 42.7 hours after the first observed failure (24.8 hours after the landfall, and 26.25 hours after the failure rate reached the maximum value) the resilience reached the minimum value. There, 46% (214 out of 463) of total failures were in aging recovery. The maximum reduction of resilience from that of
the normal operation was![]() , where n was the total number of nodes in the network. At this time, the network was experiencing the most impact from the hurricane.
, where n was the total number of nodes in the network. At this time, the network was experiencing the most impact from the hurricane.
・ After the minimum, the resilience increased when more failures were restored. The impact from the hurricane was fading gradually. It took about 10.7 days for the resilience to return to that of the normal operation from the minimum value.
The dynamic resilience metric ![]() resulting from the non-stationary model provides following insights and understanding. First, the static resilience developed in the previous works is overly-pessimistic for quantifying the resilience before and after the landfall of the hurricane, where either few failures occurred or most failures recovered. The static metrics are overly-optimistic around the landfall, where a large number of failures experienced aging recovery. Second, the dynamic resilience metric quantifies joint effects of failure and recovery processes, showing not only the failure rate but also the speed of recovery. Third, the dynamic metric reveals the worst-case resilience of the network during a hurricane. The dynamic resilience also identifies the time when the resilience reached the worst value, showing an important period during a life-cycle of failures and recoveries. For example, the network was the weakest in the duration (26.25 hours) between the failure rate reached its peak value and the resilience attained the minimum, when most failures already occurred but the restoration slowed down to aging recovery. When the network survived the weakest period, the resilience began to improve due to recovery and few additional failures.
resulting from the non-stationary model provides following insights and understanding. First, the static resilience developed in the previous works is overly-pessimistic for quantifying the resilience before and after the landfall of the hurricane, where either few failures occurred or most failures recovered. The static metrics are overly-optimistic around the landfall, where a large number of failures experienced aging recovery. Second, the dynamic resilience metric quantifies joint effects of failure and recovery processes, showing not only the failure rate but also the speed of recovery. Third, the dynamic metric reveals the worst-case resilience of the network during a hurricane. The dynamic resilience also identifies the time when the resilience reached the worst value, showing an important period during a life-cycle of failures and recoveries. For example, the network was the weakest in the duration (26.25 hours) between the failure rate reached its peak value and the resilience attained the minimum, when most failures already occurred but the restoration slowed down to aging recovery. When the network survived the weakest period, the resilience began to improve due to recovery and few additional failures.
6. Conclusions
We have derived a non-stationary random process to model large-scale failure and recovery of a power distribution network under external disruptions. The resulting model is a dynamic ![]() queue that has independent failure increments and time-varying distributions for failure durations. Transient Little’s Law provides a simple characterization of the non-stationary failure and recovery processes through two quantities: a time-varying failure rate and a probability distribution of failure durations. A new metric on resilience is then defined using these two quantities together with a threshold on failure durations. The resilience metric is dynamic, showing both the ability of network to remain operational and recover rapidly from failures during severe weather. A threshold on rapid and slow recovery has been identified as a time duration between the maximum and minimum difference of the failure rate and the recovery rate. A minimum value of the resilience is then obtained to show how much the resilience deviates from that of the normal operation.
queue that has independent failure increments and time-varying distributions for failure durations. Transient Little’s Law provides a simple characterization of the non-stationary failure and recovery processes through two quantities: a time-varying failure rate and a probability distribution of failure durations. A new metric on resilience is then defined using these two quantities together with a threshold on failure durations. The resilience metric is dynamic, showing both the ability of network to remain operational and recover rapidly from failures during severe weather. A threshold on rapid and slow recovery has been identified as a time duration between the maximum and minimum difference of the failure rate and the recovery rate. A minimum value of the resilience is then obtained to show how much the resilience deviates from that of the normal operation.
We had used real data from an operational network that was impacted by Hurricane Ike. The failure rate and non-stationary probability distribution of failure durations as well as resilience metric are estimated from the real data. The failure process has been shown to be an non-homogenous Poisson process at the time scale of minutes. The recovery-time distribution has been modeled as Weibull mixtures with time-varying parameters. A threshold value is obtained as 15.5 hours for this network, where 50.8% of the failures recovered rapidly. The network resilience reached its minimum value 24.8 hours after the landfall when the aging recoveries were 46% of all failures. The network experienced the most difficult time when the failure rate reached the peak value and the aging recovery dominated until the resilience decreased to the minimum. It then took about 10 days for the network to regain 100% resilience from the minimum value. These observations suggest that enhanced recovery, especially during the most difficult duration, can perhaps reduce the worst impact to the network and improve the overall resilience and the recovery time.
There are several directions for extensions of this work. The first is to utilize spatial and network variables in the non-stationary model. Temporal resilience can then be extended to measure spatiotemporal characteristics. Different time scales may need to be considered to account for the impacts from a system structure. Such extensions are natural as our model is derived from bottom-up starting with nodes at certain geo- and system- locations. Our preliminary work shows a step towards such an extension [39] . The second is to characterize the impacts of failures and recoveries to customers. This may involve more complex models beyond aggregated non-stationary random processes and Transient Little’s Law.
Acknowledgements
The authors would like to thank Chris Kung, Jae Won Choi, Daniel Burnham and Xinyu Dai for data processing, Kurt Belgum for helpful comments on the manuscript, Anthony Kuh, Vince Poor, and Nikil Jayant for helpful discussions. The support from the National Science Foundation (ECCS 0952785) is gratefully acknowledged.
Appendix
1. Proof of Corollary 1
Proof: We begin with the Transient Little’s Theorem. Computing the derivative of both sides of Equation (7), we have
![]() (22)
(22)
where ![]() is the cumulative distribution function of failure duration. Change the order of derivative and integral, we have
is the cumulative distribution function of failure duration. Change the order of derivative and integral, we have
![]() (23)
(23)
The first term on the right-hand-side is![]() . By definition of
. By definition of![]() ,
, ![]() and
and![]() , the second term is
, the second term is![]() , i.e., the recovery rate
, i.e., the recovery rate ![]() (Equation (10)).
(Equation (10)).
2. Pearson’s Hypothesis Test
Pearson’s Hypothesis Test: The hypothesis test is based on a chi-square statistic which compares the failure occurrence times with their sample mean. The details of testing ![]() that failure occurrence times are drawn from a NHPP
that failure occurrence times are drawn from a NHPP ![]() are given here.
are given here.
1) Compute the estimated failure rate![]() . At time t, count the number of failures in
. At time t, count the number of failures in![]() ,
,
![]() .
.
2) Divide the failure occurrence times into m non-overlapping intervals![]() . Count the number of failure occurrences in each interval. Let
. Count the number of failure occurrences in each interval. Let ![]() denote the number of occurrence in interval i, where
denote the number of occurrence in interval i, where![]() . Let
. Let![]() .
.
3) Count![]() , which is the observed number of intervals with j failure occurrences,
, which is the observed number of intervals with j failure occurrences, ![]() , where
, where![]() .
.
4) Use the estimated ![]() to compute
to compute![]() , which is the expected number of intervals with j failure
, which is the expected number of intervals with j failure
occurrences.![]() , where
, where![]() .
.
5) Compute the sum![]() .
. ![]() is a chi-square statistic, with degree of freedom dof = k −
is a chi-square statistic, with degree of freedom dof = k −
(number of independent parameter fitted) − 1. Since one parameter ![]() is fitted, the degree of freedom is
is fitted, the degree of freedom is![]() .
.
6) Given a confidence level, for instance 95%, we obtain a threshold value![]() . The hypothesis
. The hypothesis ![]() is rejected if
is rejected if![]() ; otherwise,
; otherwise, ![]() cannot be rejected.
cannot be rejected.