Second-Order MaxEnt Predictive Modelling Methodology. II: Probabilistically Incorporated Computational Model (2nd-BERRU-PMP) ()
1. Introduction
An accompanying work [1] has presented a comprehensive second-order predictive modeling (PM) methodology based on the maximum entropy (MaxEnt) principle [2] , for obtaining best-estimate mean values and correlations for model responses and parameters, which was designated by the acronym 2nd-BERRU-PMD. The attribute “2nd” indicates that this methodology incorporates second-order uncertainties (means and covariances) and second-order sensitivities of computed model responses to model parameters. The acronym BERRU stands for “Best-Estimate Results with Reduced Uncertainties” and the last letter (“D”) in the acronym indicates “deterministic,” referring to the deterministic inclusion of the computational model responses.
Alternative to the 2nd-BERRU-PMD methodology, this work presents the 2nd-BERRU-PMP methodology for obtaining best-estimate mean values and correlations for model responses and parameters. The 2nd-BERRU-PMP methodology is also based on the MaxEnt principle but includes the computational model responses probabilistically-through a MaxEnt representation-in contradistinction to its deterministic inclusion within the 2nd-BERRU-PMD methodology. This (contra) distinction is indicated the last letter (“P”) in the acronym, which refers to the “probabilistic” inclusion of the computed model responses.
This work is structured as follows: Section 2 presents the second-order MaxEnt probabilistic representation of the computational model. Section 3 presents the “second order predictive modeling methodology with probabilistically included computed responses” (2nd-BERRU-PMP) methodology. Although both the 2nd-BERRU-PMP and the 2nd-BERRU-PMD methodologies yield expressions that include second (and higher) order sensitivities of responses to model parameters, the respective expressions for the predicted responses, calibrated predicted parameters and their predicted uncertainties (covariances) are not identical to each other, although they encompass, as particular cases, the results produced by the extant data assimilation [3] [4] and data adjustment procedures [5] [6] [7] [8] [9] . Comparisons with the results produced by the first-order BERRU-PM methodology [10] [11] [12] are also presented. The advantages of the 2nd-BERRU-PMP methodology over the results produced by the data assimilation method [3] [4] are presented in Section 5. The discussion presented in Section 6 concludes this work. Illustrative applications of the 2nd-BERRU-PMP and the 2nd-BERRU-PMD methodologies to forward and inverse problems are currently in progress.
2. Second-Order MaxEnt Probabilistic Representation of the Computational Model
The modeling of a physical system requires consideration of the following modeling components:
1) A mathematical model comprising linear and/or nonlinear equations that relate the system’s independent variables and parameters to the system’s state (i.e., dependent) variables. In this work, matrices will be denoted using capital bold letters while vectors will be denoted using either capital or lower-case bold letters. The symbol “
” will be used to denote “is defined as” or “is by definition equal to.” Transposition will be indicated by a dagger (
) superscript. The equalities in this work are considered to hold in the weak (“distributional”) sense.
2) Nominal values and uncertainties that characterize the model’s parameters.
3) One or several computational results, customarily referred to as model responses (or objective functions, or indices of performance), which are computed using the mathematical model; and
4) External to the model: experimentally measured responses that correspond to the computed responses, with their respective experimentally determined nominal (mean) values and uncertainties (variances, covariances, skewness, kurtosis, etc.). Occasionally, measurements of correlations among the measured responses and the model parameters, as well as externally performed measurements of model parameters (in addition to the information about parameters used in the model-computations) might be available.
The model parameters usually stem from processes that are external to the physical system (and, hence, model) under consideration and their precise values are seldom, if ever, known. The known characteristics of the model parameters may include their nominal (expected/mean) values and, possibly, higher-order moments (i.e., variance/covariances, skewness, kurtosis), which are usually determined from experimental data and/or processes external to the physical system under consideration. Occasionally, just the lower and the upper bounds may be known for some model parameters. Without loss of generality, the model parameters will be considered in this work to be real-valued scalars, and will be denoted as
, where the quantity “TP” denotes the “total number of model parameters.” Mathematically, these parameters are considered as components of a TP-dimensional vector denoted as
, defined over a domain
, which is included in a TP-dimensional subset of the
. The components of the TP-dimensional column vector
are considered to include imprecisely known geometrical parameters that characterize the physical system’s boundaries in the phase-space of the model’s independent variables. The model parameters can be considered to be quasi-random scalar-valued quantities which follow an unknown multivariate distribution denoted as
. The mean values which will be called “nominal” values in the context of computational modeling of the model parameters will be denoted as
; the superscript “0” will be used throughout this work to denote “nominal values.” These nominal values are formally defined as follows:
(1)
The expected values of the measured parameters will be considered to constitute the components of a “vector of nominal values” denoted as
.
The covariance,
, of two model parameters,
and
, is defined as follows:
(2)
The covariances
are considered to be the components of the parameter covariance matrix, denoted as
.
The results computed using a mathematical model are customarily called “model responses” (or “system responses” or “objective functions” or “indices of performance”). Consider that there are a total number of TR such model responses, each of which can be considered to be a component of the “vector of model responses”
. Each of these model responses is formally a function (implicit and/or explicit) of the model parameters
, i.e.,
. The uncertainties affecting the model parameters
will “propagate” both directly and indirectly, through the model’s dependent variables, to induce uncertainties in the computed responses, which will therefore be denoted as
. Each computed response can be formally expanded in a multivariate Taylor-series around the parameters’ mean values. In particular, the fourth-order Taylor-series of a system response, denoted as
, around the expected (or nominal) parameter values
has the following formal expression:
(3)
In Equation (3), the quantity
indicates the computed value of the response using the expected/nominal parameter values
. The notation
indicates that the quantities within the braces are also computed using the expected/nominal parameter values. The quantity
in Equation (3) comprises all quantifiable errors in the representation of the computed response as a function of the model parameters, including the truncation errors
of the Taylor-series expansion, possible bias-errors due to incompletely modeled physical phenomena, and possible random errors due to numerical approximations. The radius/domain of convergence of the series in Equation (3) determines the largest values of the parameter variations
which are admissible before the respective series becomes divergent. In turn, these maximum admissible parameter variations limit, through Equation (3), the largest parameter covariances/standard deviations which can be considered for using the Taylor-expansion for the subsequent purposes of computing moments of the distribution of computed responses.
As is well known, and as indicated by Equation (3), the Taylor-series of a function of TP-variables [e.g.,
] comprises TP 1st-order derivatives,
distinct 2nd-order derivatives, and so on. The computation by conventional methods of the nth-order functional derivatives (called “sensitivities” in the field of sensitivity analysis) of a response with respect to the TP-parameters (on which it depends) would require at least
large-scale computations. The exponential increase with the order of response sensitivities of the number of large-scale computations needed to determine higher-order sensitivities is the manifestation of the “curse of dimensionality in sensitivity analysis,” by analogy to the expression coined by Bellman [13] to express the difficulty of using “brute-force” grid search when optimizing a function with many input variables. The “nth-order Comprehensive Adjoint Sensitivity Analysis Methodology for Nonlinear Systems” (nth-CASAM-N) conceived by Cacuci [14] and the “nth-order Comprehensive Adjoint Sensitivity Analysis Methodology for Response-Coupled Forward/Adjoint Linear Systems” (nth-CASAM-L) conceived by Cacuci [15] are currently the only methodologies that enable the exact and efficient computation of arbitrarily high-order sensitivities while overcoming the curse of dimensionality.
Uncertainties in the model’s parameters will evidently give rise to uncertainties in the computed model responses
. The computed model responses are considered to be distributed according to an unknown distribution denoted as
. The unknown joint probability distribution of model parameters and responses will be denoted as
. The approximate moments of the unknown distribution of
are obtained by using the so-called “propagation of errors” methodology, which entails the formal integration over
of various expressions involving the truncated Taylor-series expansion of the response provided in Equation (3). This procedure was first used by Tukey [16] . Tukey’s results were generalized to 6th-order by Cacuci [15] .
The expectation value,
, of a computed response
is obtained by integrating formally Equation (3) over
, which yields the following expression:
(4)
The expectation values
,
, are considered to be the components of a vector defined as follows:
.
The expression of the correlation between a computed responses and a parameter variance, which will be denoted as
, is presented below:
(5)
The correlations
,
,
, are considered to be the components of a “parameter-response computed correlation matrix” denoted as
and defined as follows:
(6)
The expression of the covariance between two responses
and
, denoted as
, is presented below:
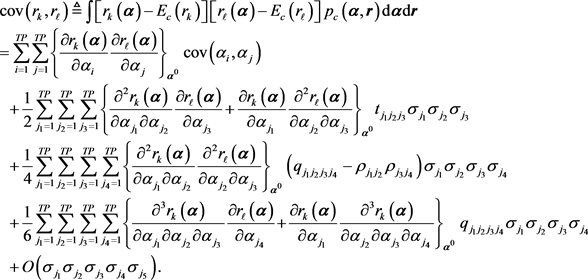 (7)
(7)
The covariances
,
, are considered to be the components of a “computed-responses covariance matrix” denoted as
and defined as follows:
(8)
The information provided in Equations (1)-(8) regarding the mean values and correlations for the model parameters and computed model responses will be used to construct a second-order MaxEnt approximation, denoted as
, to represent the distribution
of computed model responses and parameters. The distribution
is constructed by following the procedure outlined in Appendix, to obtain the following expression:
, (9)
where:
. (10)
It is important to note that even though the MaxEnt distribution represented in Equation (9) is a multivariate normal distribution characterized by just the first-order moments (mean values) and second-order moments (variance/covariances) of the full but unknown “joint distribution
of computed responses and parameters,” the components of the vector
of mean values and the components of the covariance matrix
may comprise terms involving third- and higher-order response sensitivities and parameter correlations (e.g., triple and quadruple correlations), if available, as indicated in Equations (4), (5), and (7).
3. 2nd-BERRU-PMP: Second Order Predictive Modeling Methodology with Probabilistically Included Computed Responses
This Section presents the mathematical and physical considerations leading to the development of the second-order predictive modeling methodology in which the computational model is probabilistically incorporated with the measurements into the combined 2nd-order MaxEnt posterior distribution which represents all of the available computational and experimental information. This methodology will be designated using the acronym 2nd-BERRU-PMP, where the last letter (“P”) indicates “probabilistic.” Subsection 3.1 presents the general case, in which measurements (mean values and correlations) for parameters are available−in addition to the information used in the computational model−for incorporation together with the measured responses into the MaxEnt probabilistic representation of the computational model in order to finally obtain the joint posterior distribution that would represent all of the available second-order information. This general case seldom occurs in practice because additional measurements regarding the model parameters (outside of, and in addition to, their use in the model) are rarely available. Usually, only measurements for responses are available for incorporation into the MaxEnt representation of the computational model; this case is analyzed in Subsection 3.2.
3.1. General Case: Measurements for Both Responses and Parameters Are Available for Combination with the MaxEnt Probabilistic Representation of the Computational Model to Obtain Their Joint Posterior Distribution
In the most general case, measurements could be available not only for the responses (results) of interest but also about the parameters used in the model to compute the respective results. In such a case, the second-order MaxEnt distribution which will represent probabilistically the computed model responses and model parameters is to be combined with a second-order MaxEnt distribution which is to represent probabilistically the measured model responses and the additionally measured model parameters (i.e., model parameters measured in addition to, and independently of, the computational model). Since only first- and second-order moments are considered to be available, each of these MaxEnt distributions will be multivariate normal distributions, so their combination will also yield a multivariate posterior MaxEnt distribution (for all of the first- and second-order available moments).
Consider that the total number of experimentally measured responses is TR. The information usually available regarding the distribution of such measured responses comprises the first-order moments (mean values), which will be denoted as
,
, and the second-order moments (variances/covariances), which will be denoted as
,
, for the measured responses. Occasionally, measured correlations between the model parameters and the measured responses could also be available. The letter “e” will be used either as a superscript or a superscript to indicate experimentally measured quantities. The expected values of the measured responses will be considered to constitute the components of a vector denoted as
. The covariances of the measured responses are considered to be components of the
-dimensional covariance matrix of measured responses, which will be denoted as
. In principle, it is also possible to obtain correlations between some measured responses and some model parameters. When such correlations between measured responses and measured model parameters are available, they are defined as
,
;
, and can formally be considered to be elements of a rectangular correlation matrix which will be denoted as
. In the most general situation, it is possible to have not only measured responses but also new measurements for the parameters, in addition to and independently of, the parameters used in the mathematical/computational model (i.e., where they are considered to have nominal values
and covariance matrix
). These measured parameters will be considered to have a vector of mean values denoted as
, and a covariance matrix denoted as
.
The MaxEnt principle can now be applied, as described in Appendix, to construct the least informative (and hence, most conservative) distribution using the available experimental information, to obtain the following expression:
(11)
where:
(12)
The joint posterior probability distribution of all computed and experimentally measured quantities, which will be denoted as
where the subscript “p” indicates “posterior,” is obtained as the properly normalized product of the distributions
and
. Since both
and
are normally distributed, it follows that the posterior probability
will also be normally distributed and will be given by the following expression:
(13)
where the normalization constant K and the quadratic form
have the following expressions, respectively:
(14)
(15)
(16)
(17)
The expression obtained in Equation (13) provides the exact first-order (mean values) and second-order (variances and co-variances) of the most comprehensive combined distribution of computations and measurements of responses and parameters. In practice, however, such a comprehensive amount of experimental information is highly unlikely to be available. Furthermore, even if such massive amount of experimental information were available, the inversion of the matrix
may be impractical since it would require massive computational resources when the physical systems involve many (thousands of) parameters.
3.2. Practical Case: Only Response Measurements Are Available for Combination with the MaxEnt Probabilistic Representation of the Computational Model to Obtain Their Joint Posterior Distribution
In practice, the information (mean values and covariances) about the model parameters indicated in Equations (1) and (2) is obtained and assessed prior to using this information in the mathematical/computational model used for computing responses. Thus, all of the information available regarding the model parameters would be used to construct the components of the vector
of parameter nominal values and the components of the parameter covariance matrix
. In practice, only information about measured responses would become additionally available, i.e., only the vector
and the covariance matrix
would become available for combination with the computational information. In such a case, the MaxEnt distribution corresponding to Equation (11) will reduce to the following expression:
(18)
Furthermore, when only the experimental information represented by the distribution
is available, the posterior joint probability distribution of the computed and measured quantities, which will be denoted as
will have the following form:
(19)
The evaluation of the moments of the posterior distribution represented by Equation (19) will involve the evaluation of ratios of integrals having the following form:
. (20)
The evaluations of expressions such as shown in Equation (20) can be performed to a high degree of accuracy, with a controlled error, by employing the saddle-point (Laplace) method, see e.g., [17] [18] , which yields the following result:
, (21)
where:
1) The derivative of a function with respect to a component of
is denoted using a subscript, e.g.,
,
,
, where TI denotes the total number of independent variables;
2) The superscripts denote the respective component of the inverse Hessian of the respective function, e.g.,
denotes the
-element of the inverse Hessian matrix
;
3) An index that appears as a subscript and a superscript implies a summation over all possible values of that index;
4) The “hat” denotes that the respective quantity is to be evaluated at the saddle point of
, which is defined as the point at which the gradient
of
vanishes, i.e.,
.
The saddle-point of the normalization integral N will be denoted as
and is defined by the following relations:
(22)
To obtain the partial gradients (differentials) shown in Equation (22), it is convenient to write the matrix
in the form
, and use this form together with the definitions provided in Equations (10) and (12) in Equation (19) to expand the functional
into the following form:
(23)
Taking the partial differentials of the expression in Equation (23) yields the following equation for determining the coordinates of the saddle point
:
(24)
Solving Equation (24) leads to the following expressions for the coordinates
and
of the saddle point:
, (25)
. (26)
The best-estimate predicted mean values for the responses and parameters are defined below:
, (27)
. (28)
The superscript “bep” has been used in Equations (29) and (30), respectively, to indicate that the expressions obtained for the respective predicted responses and parameters are “best estimates with probabilistic computational model.” The saddle-point method is applied to evaluate the integrals represented by Equations (27) and (28), respectively, to obtain the following expressions for the optimally-predicted “best-estimate” values for the responses and calibrated parameters:
, (29)
. (30)
Since the components of the vector
, and the components of the matrices
and
can contain arbitrarily high-order response sensitivities to model parameters, the expressions presented in Equations (29) and (30) generalize the previous formulas of this type found in data adjustment/assimilation procedures published to date (which contain at most second-order sensitivities). The best-estimate parameter values are the “calibrated model parameters” which can be used for subsequent computations with the “calibrated model.”
The second-order moments of the posterior distribution
comprise the covariances between the best estimated response, which will be denoted as
, the covariances between the best-estimate parameters, which will be denoted as
, and the correlations between the best-estimate parameters and responses, which will be denoted as
. The expression of the “best-estimate probabilistic model” posterior parameter covariance matrix,
, for the best-estimate responses
is derived by using the result given in Equation (29) to obtain the following expression:
. (31)
The following important result has been used to obtain the expression provided in Equation (31):
(32)
As indicated in Equation (31), the initial covariance matrix
for the experimentally measured responses is multiplied by the matrix
, which means that the variances contained on the diagonal of the best-estimate matrix
will be smaller than the experimentally measured variances contained in
. Hence, the incorporation of experimental information reduces the predicted best-estimate response variances in
by comparison to the measured variances contained a priori in
. Since the components of the matrix
contain high-order sensitivities, the formula presented in Equation (31) generalizes the previous formulas of this type found in data adjustment/assimilation procedures published to date.
The expression of the “best-estimate” posterior parameter covariance matrix
for the best-estimate parameters
is derived by using the result given in Equation (30) to obtain:
(33)
The matrices
and
are symmetric and positive definite. Therefore, the subtraction indicated in Equation (33) implies that the components of the main diagonal of
must have smaller values than the corresponding elements of the main diagonal of
. In this sense, the combination of computational and experimental information has reduced the best-estimate parameter variances on the diagonal of
. Since the components of the matrices
,
, and
contain high-order response sensitivities, the formula presented in Equation (33) generalizes the previous formulas of this type found in data adjustment/assimilation procedures published to date.
The expressions of the “best-estimate” posterior parameter correlation matrix
and/or its transpose
, for the best-estimate parameters
and best-estimate responses
, are derived by using the results given in Equation (29) and Equation (30) to obtain the following expressions:
(34)
(35)
Since the components of the matrices
and
contain high-order sensitivities, the formulas presented in Equations (34) and (35) generalize the previous formulas of this type found in data adjustment/assimilation procedures published to date.
It is important to note from the results shown in Equations (29)-(35) that the computation of the best estimate parameter and response values, together with their corresponding best-estimate covariance matrices, only involves a single matrix inversion when computing
, which entails the inversion of a matrix of size
. This is computationally very advantageous, since
, i.e., the number of responses is much less than the number of model parameters in the overwhelming majority of practical situations.
Using Equations (24), (29) and (30) in Equation (23) yields the following expression for the minimum value,
, of the quadratic form
:
(36)
As the expression obtained in Equation (36) indicates, the quantity
represents the square of the length of the vector
, measuring (in the corresponding metric) the deviations between the experimental and nominally computed responses. The quantity
is independent of calibrating (or adjusting) the original data, so it can be evaluated directly from the given data (i.e., model parameters and computed and measured responses, together with their original uncertainties) after having computed the matrix
. As the dimension of the vector
indicates, the number of degrees of freedom characteristic of the calibration under consideration is equal to the number TR of experimental responses.
4. Inter-Comparison: 2nd-BERRU-PMP vs. 2nd-BERRU-PMD
In this section, the results obtained for the best-estimate mean values for the responses and parameters, together with their corresponding best estimate covariances/correlations will be compared to the corresponding results produced by the 2nd-BERRU-PMD methodology, as well as to the corresponding results produced by the 1st-BERRU-PM [10] [11] [12] .
4.1. Inter-Comparison of Expressions for the Best-Estimate Predicted Mean Values for Responses
Recall that the 2nd-BERRU-PMD (best-estimated values with deterministically incorporated computed responses) methodology incorporates deterministically (into the second-order MaxEnt representation of the experimentally measured responses) the following second-order Taylor-expansion of the computed responses:
(37)
In Equation (37), the components of the vector
represent the values of the model responses computed at the nominal parameter values
, and the other vectors and matrices contain first-order and second-order sensitivities of responses with respect to the model parameters, evaluated at the nominal parameter values
, as defined below:
(38)
The expressions of the end-results produced the “best-estimated values with deterministically incorporated computed responses” (2nd-BERRU-PMD) methodology will be designated using the superscript “bed.” The expression obtained using the 2nd-BERRU-PMD methodology for the best-estimate responses is as follows [1] :
, (39)
where the vector
is the solution of the following iterative (Newton’s method) equation
(40)
In Equation (40), the components/elements
of the Jacobian matrix
have the following expressions:
(41)
where:
; (42)
(43)
. (44)
. (45)
(46)
(47)
The initial iterate for starting the iterations for obtaining solution of Equation (40) can be chosen [1] as follows:
(48)
(49)
(50)
(51)
The first-iterate
of the solution of Equation (40) has the following expression:
(52)
Using the first-iterate,
, in Equation (39) yields the following expressions for the “first-iterate best-estimate” values for the responses:
(53)
It is noteworthy that the “vector of deviations”
can be considered to be a (quasi-) random variable; it has been shown in [1] that the “vector of mean values of deviations”
and the covariance matrix
of the vector of deviations
have the following expressions (up to second-order sensitivities):
; (54)
. (55)
Comparing the expression of the first-iterate, cf., Equation (53) produced by the 2nd-BERRU-PMD methodology with the corresponding expression produced by the 2nd-BERRU-PMP methodology, cf. Equation (29), indicates that both expressions include the second-order sensitivities of the responses with respect to the parameters, but in distinct ways. Furthermore, the expression produced by the 2nd-BERRU-PMP methodology, cf. Equation (29), can include all of the response sensitivities and parameter correlations of order higher than two, if available. Such an inclusion of higher-order sensitivities and parameter correlations is not provided by the result, cf. Equation (53), obtained using the 2nd-BERRU-PMD methodology.
The expression provided in Equation (29) coincides with the expression provided in Equation (53) only if the following relationship holds:
(56)
The equality in Equation (56) can hold if the following conditions are simultaneously satisfied:
,
,
,
,
,
, in which case we also have the relation
. These conditions are satisfied if all of the sensitivities higher than first-order are ignored, and if the experimental responses are uncorrelated to the model parameters. In this particular case, the results produced by the 2nd-BERRU-PMP and 2nd-BERRU-PMD methodologies also coincide with the results produced by the first-order 1st-BERRU-PM methodology.
4.2. Inter-Comparison of Expressions for the Best-Estimate Predicted Mean Values for Parameters
The expression obtained using the 2nd-BERRU-PMD methodology for the best-estimate parameters is as follows [1] :
. (57)
Using the first-iterate
in Equation (57) yields the following first-iterate expression for the best-estimate parameters:
(58)
Comparing the expression provided in Equation (58), namely the first-iterate produced by the 2nd-BERRU-PMD methodology, with the corresponding expression produced by the 2nd-BERRU-PMP methodology, cf. Equation (30), indicates that both expressions include the second-order sensitivities of the responses with respect to the parameters, but in distinct ways. Furthermore, the expression produced by the 2nd-BERRU-PMP methodology, cf. Equation (30), can include all of the response sensitivities and parameter correlations of order higher than two, if available. Such an inclusion of higher-order sensitivities and parameter correlations is not possible with the result obtained using the 2nd-BERRU-PMD methodology, cf. Equation (58).
The expression provided in Equation (30) coincides with the expression provided in Equation (58) only if the following relationship holds:
(59)
The equality in Equation (59) can hold if the following conditions are simultaneously satisfied:
,
,
,
,
,
, in which case we also have the relation
. These conditions are satisfied if all of the sensitivities higher than first-order are ignored. In this particular case, the results produced by the 2nd-BERRU-PMP and 2nd-BERRU-PMD methodologies also coincide with the results produced by the first-order 1st-BERRU-PM methodology.
4.3. Inter-Comparison of Expressions for the Best-Estimate Predicted Response Covariances
The expression obtained using the 2nd-BERRU-PMD methodology [1] for the “first-iterate best-estimate” covariance matrix
for the responses is as follows:
(60)
where:
(61)
Comparing the 2nd-BERRU-PMD-expression provided in Equation (60) with the corresponding expression obtained using the 2nd-BERRU-PMP methodology, cf. Equation (31), indicates that both expressions include the second-order sensitivities of the responses with respect to the parameters, but in distinct ways. Furthermore, the expression produced by the 2nd-BERRU-PMP methodology, cf. Equation (31), can include all of the response sensitivities and parameter correlations of order higher than two, if available. Such an inclusion of higher-order sensitivities and parameter correlations is not possible with the result obtained using the 2nd-BERRU-PMD methodology, cf. Equation (60).
The expression provided in Equation (31) coincides with the expression provided in Equation (60) only if the following relationship holds:
(62)
The equality shown in Equation (62) can hold only if all of the second-order sensitivities are neglected, and if the experimental responses are uncorrelated to the model parameters, in which case the following simplifications occur:
,
, and
, in which case we also have the relation
. In this particular case, the results produced by the 2nd-BERRU-PMP and 2nd-BERRU-PMD methodologies also coincide with the results produced by the first-order 1st-BERRU-PM methodology.
4.4. Inter-Comparison of Expressions for the Best-Estimate Predicted Parameter Covariances
The expression obtained using the 2nd-BERRU-PMD methodology [1] for the “first-iterate best-estimate” covariance matrix
for the model parameters is as follows:
(63)
were:
(64)
Comparing the 2nd-BERRU-PMD-expression provided in Equation (63) with the corresponding expression obtained using the 2nd-BERRU-PMP methodology, cf. Equation (33), indicates that both expressions include the second-order sensitivities of the responses with respect to the parameters, but in distinct ways. Furthermore, the expression produced by the 2nd-BERRU-PMP methodology, cf. Equation (33), can include all of the response sensitivities and parameter correlations of order higher than two, if available. Such an inclusion of higher-order sensitivities and parameter correlations is not possible with the result obtained using the 2nd-BERRU-PMD methodology, cf. Equation (63).
The expression provided in Equation (33) coincides with the expression provided in Equation (63) only if the following relationship holds:
(65)
The equality shown in Equation (65) can hold only if all of the second-order sensitivities are neglected, and if the experimental responses are uncorrelated to the model parameters, in which case the following simplifications occur:
,
, in which case we also have the relation
. In this particular case, the results produced by the 2nd-BERRU-PMP and 2nd-BERRU-PMD methodologies also coincide with the results produced by the first-order 1st-BERRU-PM methodology.
4.5. Inter-Comparison of Expressions for the Best-Estimate Predicted Correlations between Parameters and Responses
The expression obtained using the 2nd-BERRU-PMD methodology [1] for the “first-iterate best-estimate” correlation matrix
for the parameters and responses is as follows:
(66)
Comparing the 2nd-BERRU-PMD-expression provided in Equation (66) with the corresponding expression obtained using the 2nd-BERRU-PMP methodology, cf. Equation (34), indicates that both expressions include the second-order sensitivities of the responses with respect to the parameters, but in distinct ways. Furthermore, the expression produced by the 2nd-BERRU-PMP methodology, cf. Equation (34), can include all of the response sensitivities and parameter correlations of order higher than two, if available. Such an inclusion of higher-order sensitivities and parameter correlations is not possible with the result obtained using the 2nd-BERRU-PMD methodology, cf. Equation (66)
The expression provided in Equation (34) coincides with the expression provided in Equation (66) only if the following relationship holds:
(67)
The equality shown in Equation (67) can hold only if all of the second-order sensitivities are neglected, and if the experimental responses are uncorrelated to the model parameters. In this particular case, the results produced by the 2nd-BERRU-PMP and 2nd-BERRU-PMD methodologies also coincide with the results produced by the first-order 1st-BERRU-PM methodology.
5. Fundamental Advantages of 2nd-BERRU-PMP over Second-Order Data Assimilation
This section summarizes the decisive advantages of the 2nd-BERRU-PM methodology over the 2nd-Order Data Assimilation methodology [3] [4] . The 2nd-Order Data Assimilation methodology [3] [4] relies on using a 2nd-order procedure to minimize a user-defined functional which is meant to represent, in a chosen norm (usually the energy-norm), the discrepancies between computed and experimental results (“responses”). Mathematically, the 2nd-Order Data Assimilation method involves the following steps [3] [4] :
1) Consider that the physical system is represented, as in [1] , by the operator equations
. Consider that the vector of measured responses (“observations”), denoted by the vector
, is a known function of the vector of state-variables
and of the vector of errors
, having the following expression:
, where
denotes a known vector-function of
. The error term,
, is considered here to include “representative errors” stemming from sampling and grid interpolation; the mean value of
corresponds to
and the covariance matrixof
corresponds to
. As described in [3] [4] ,
is often considered to have the characteristics of “white noise,” in which case
is a normal distribution with mean
and covariance
. In addition, it is assumed that the prior “background” information is also known, being represented by a multivariate normal distribution with a known mean, denoted as
, and a known covariance matrix denoted as
, i.e.,
. The posterior distribution,
, is obtained by applying Bayes’ Theorem to the above information, which yields the result
, where:
. (68)
The maximum posterior estimate is obtained by determining the minimum of the functional
, which occurs at the root (s) of the following equation:
. (69)
where
denotes the Jacobian matrix of
with respect to the components of
.
The “first-order data assimilation” procedure solves Equation (69) by using a “partial quadratic approximation” to
, while the “second-order data assimilation” procedure solves Equation (69) by using a “full quadratic approximation” to
, as detailed in [3] [4] , to obtain the “optimal data assimilation solution,” which is here denoted as
, as the solution of Equation (69). The following fundamental differences become apparent by comparing the “Data Assimilation” result represented by Equation (69) and the 2nd-BERRU-PMP results.
2) Data assimilation (DA) is formulated conceptually [3] [4] either just in the phase-space of measured responses (“observation-space formulation”) or just in the phase-space of the model’s dependent variables (“state-space formulation”). Hence, DA can calibrate initial conditions as “direct results” but cannot directly calibrate any other model parameters. In contradistinction, the 2nd-BERRU-PMP methodology is formulated conceptually in the most inclusive “joint-phase-space of parameters, computed and measured responses.” Consequently, the 2nd-BERRU-PMP methodology simultaneously calibrates responses and parameters, thus simultaneously providing results for forward and inverse problems.
3) If experiments are perfectly well known, i.e., if
, Equation (69) indicates that the DA methodology fails fundamentally. In contradistinction, Equations (33)-(35) indicate that the 2nd-BERRU-PMP methodology does not fail when
because, in any situation,
.
4) The DA methodology also fails fundamentally when the response measurements happen to coincide with the computed value of the response, i.e., when
at some point in the state-space. In such a case, the DA’s Equation (69) yields the trivial result
. In contradistinction, the 2nd-BERRU-PMP methodology does not yield such a trivial result when the response measurements happen to coincide with the computed value of the response, i.e., when
, because the difference
, which appears on the rights sides of Equations (29) and (30), remains non-zero due to the contributions of the second- and higher-order sensitivities of the responses with respect to the model parameters, as shown in Equation (4), i.e.,:
,
for
. This situation clearly underscores the need for computing and retaining (at least) the second-order response sensitivities to the model parameters. Although a situation when
is not expected to occur frequently in practice, there are no negative consequences (should such a situation occur) if the 2nd-BERRU-PMP methodology is used, in contradistinction to using the DA methodology.
5) The 2nd-BERRU-PMP methodology only requires the inversion of the matrix
of size
. In contradistinction, the solution of the “1st-order DA” requires the inversion of the Jacobian
of
, while the solution of the “2nd-order DA” also requires the inversion of a matrix-vector product involving the Hessian matrix of
; these matrices are significantly larger [3] [4] than the matrix
. Hence, the 2nd-BERRU-PM methodology is significantly more efficient computationally than DAE.
6) The DA methodology is practically non-extendable beyond “second-order.” A “3rd-order DA” would be computationally impractical because of the massive sizes of the matrices that would need to be inverted. In contradistinction, the 2nd-BERRU-PM methodology presented herein already comprises 4th-order sensitivities of responses to parameters and can be readily extended/generalized to include even higher-order sensitivities and parameter correlations.
All of the above advantages of the 2nd-BERRU-PM methodology over the DA methodology stem from the fact that the 2nd-BERRU-PM methodology is fundamentally anchored in physics-based principles (thermodynamics & information theory) formulated in the most inclusive possible phase-space (namely the combined phase-space of computed and measured parameters and responses), whereas the DA methodology is fundamentally based on the minimization of a subjective user-chosen functional.
6. Discussion and Conclusions
This work has presented the “second order predictive modeling methodology with probabilistically included computed responses” (2nd-BERRU-PMP) methodology, as underscored by the letter “P” in the acronym (which indicates the “probabilistic” inclusion of the computed model responses). This methodology is a companion to the alternative 2nd-BERRU-PMD methodology, in which the computational model is included deterministically, as underscored by the letter “D” in this acronym. Both methodologies are fundamentally based on the MaxEnt principle. Although both the 2nd-BERRU-PMP and the 2nd-BERRU-PMD methodologies yield expressions that include second (and higher) order sensitivities of responses to model parameters, it is shown in this work that the respective expressions for the predicted responses, calibrated predicted parameters and their predicted uncertainties (covariances) are not identical to each other. Nevertheless, these second-order methodologies encompass, as particular cases, the results produced by the extant data assimilation [3] [4] , data adjustment procedures [5] [6] [7] [8] [9] , and the first-order BERRU-PM methodology [10] [11] [12] .
Notably, the 2nd-BERRU-PMP methodology enables the use of sensitivities and parameter correlations beyond second-order, if available; this opportunity is not available within the 2nd-BERRU-PMD methodology. If it is imperative to combine experimental information for both the responses and parameters with the computational information produced by the model, then the complete Gaussian expression of the 2nd-BERRU-PMP should be used, if it is possible to accommodate the massive computational requirements underlying the inversion of the matrices that arise within this methodology. On the other hand, the simplest to implement computationally is the simplified 2nd-BERRU-PMP, which should be used when experimental information about the model parameters in addition to the information used in the computational model is not important. The 2nd-BERRU-PMD methodology offers an intermediary alternative, being easier to implement computationally than the complete version of the 2nd-BERRU-PMP methodology but involving more computations than the simplified 2nd-BERRU-PMP methodology.
Illustrative applications of the 2nd-BERRU-PMP and the 2nd-BERRU-PMD methodologies to various paradigm forward and inverse problems are currently in progress.
Appendix: Construction of the Second-Order Maximum Entropy Distribution for Responses and Parameters
When an unknown distribution
, defined on a domain
(where
denotes the domain of definition of the parameters and
denotes the domain of definition of the responses) needs to be reconstructed from a finite number of its known moments, the principle of maximum entropy (MaxEnt) originally formulated by Jaynes [2] provides the optimal compatibility with the available information, while simultaneously ensuring minimal spurious information content. In particular, when only the first-order and second-order moments of the joint distribution of model parameters and responses
are known, the corresponding second-order MaxEnt distribution
is constructed by following the procedure outlined below.
1) Known means and covariances for responses:
(70)
(71)
2) Known means and covariances for parameters:
(72)
(73)
(74)
According to the MaxEnt principle, the probability density
would satisfy the “available information” provided in Equations (70)-(74), without implying any spurious information or hidden assumptions, if:
1)
maximizes the Shannon [19] information entropy, S, as defined below:
, (75)
2)
satisfies the “moments constraints” defined by Equations (70)-(74);
3)
satisfies the normalization condition:
(76)
The MaxEnt distribution
is obtained as the solution of the constrained variational problem
, where the entropy (Lagrangian functional)
is defined as follows:
(77)
In Equation (77), the quantities
,
,
,
, and
denote the respective Lagrange multipliers, and the factors 1/2 have been introduced for subsequent computational convenience.
Solving the equation
yields the following expression for the resulting MaxEnt distribution
:
, (78)
where the various vectors and matrices are defined as follows:
(79)
(80)
The normalization constant
in Equation (104) is defined as follows:
(81)
In statistical mechanics, the normalization constant Z is called the partition function (or sum over states) and carries all of the information available about the possible states of the system, while the MaxEnt distribution
is called the canonical Boltzmann-Gibbs distribution. The integral in Equation (107) can be evaluated explicitly by conservatively extending the computational domain D to the entire multidimensional real vector space
, where
, to obtain the following expression:
(82)
The Lagrange multipliers are determined in terms of the known information (means and covariances of parameters and responses) by differentiating the “free energy”
with respect to the components of the vector
to obtain the following expressions:
(83)
(84)
The results obtained in Equations (83) and (84) can be collectively written in vector-matrix form as follows:
(85)
On the other hand, it follows from Equation (82) that:
(86)
The relations obtained in Equations (85) and (86) imply the following relation:
(87)
Differentiating a second time the relation provided in Equation (83) or (84) yields the following relations:
(88)
(89)
(90)
The results obtained in Equations (88)-(90) can be collectively written in vector-matrix form as follows:
(91)
On the other hand, it follows from Equation (86) that:
(92)
The relations obtained in Equations (91) and (92) imply the following relation:
(93)
Introducing the results obtained in Equations (87) and (93) into Equation (78) and (82) yields the following expression for the MaxEnt distribution
:
(94)