Robust Variance Components Estimation in the PERG Mixed Distributions of Empirical Variances—PEROBVC Method ()
1. Introduction
A detailed presentation of Variance and Covariance Components Models can be found in Rao and Kleffe [1], as well as in Krishnaiah [2].
However, in the applications deviations appear from the assumptions under which these solutions are obtained, which also leads to negative estimates of variance components. The main source of these deviations is the contaminating distribution of observations (also presence of outliers), which, as a rule, always appears. Therefore, Variance Components (VC) solutions are always studied, which are less sensitive or insensitive to these deviations. Such properties are characteristic for robust solutions, out of which the following ones are here presented:
Maximum Likelihood Approaches to Variance Component Estimation and to Related Problems [3]; Robust Estimation of Variance Components [4], Estimation and Use of Variance Components [5], Robust Variance Estimation in Linear Regression [6], Robust Variance Estimation for Random Effects Meta-analysis [7], Robust Variance Estimation in Meta-regression with Dependent Effect Size Estimates [8], Robust Estimation of Linear Mixed Models [9].
Robust estimates of variances and of their components have been continually applied in various fields [10] - [21] (a more detailed presentation can be seen in [22]).
Regarding a GPS measurement error as a random process and modeling the process realization structurally as a 2-way hierarchical classification with random effects, Perović [23] studied a robust solution for variance components in GPS measurements—PERG2FH method. Perović [22] also robustly estimated the parameters for both distributions of normally distributed observations that form Tukey’s mixed distribution.
From the said above it is seen that robust methods for estimation of Variance Components are studied. However, studies of Variance Components estimates on the basis of empirical variances distributions, except the standard procedure, have not been undertaken. For this reason the present author has devoted himself to VC research on the basis of these distributions, so that the here presented method was invented.
In the present paper a mixed distribution composed of two distributions of empirical variances is considered, where one of them is basic and the other one is contaminating, with an essential assumption that the variances of both distributions are obtained on the basis of primary normal distributions, as well as that they have the same degrees of freedom. The present author names this distribution PERG mixed-distribution of empirical variances (PERG—from initial letters of the author’s names: Perović Gligorije), which is presented in Figure 1 and described by means of the following model
(1)
1PEROBVC is an abbreviation of the initial letters: Perović’s Robust Variance Components Estimation Model.
where F1 is the basic distribution, F2 the contaminating distribution, both of empirical variances s2 with f d.f. and ε (0 < ε < 0.5) the contaminating degree.
On the basis of such a composition of the mixed distribution of empirical variances the author obtained a robust solution named Perović’s Robust Variance Components Estimation Model—PEROBVC1 method for variances and for observation numbers for both distributions. In this way the method eliminates the influences of gross errors and outliers on the estimates of distribution parameters.
The key difference between the PEROBVC method and the existing ones is that distribution censoring is not used, but instead on the basis of structural decomposition in two distributions, except obtaining parameter estimates of the two distributions, the question of outliers is simultaneously solved.
Consequently, the PEROBVC method has the following properties:
1) Unbiased (exact) variance estimates for the basic distribution, as the most important property,
2) Unbiased (exact) variance estimates for the contaminating distribution,
3) Estimates of observation numbers for both distributions and in this way percentage estimates concerning fractions of basic and contaminating distributions in the mixed one.
The correctness of the PEROBVC method has been verified on exact (expected) values of some quantities from the mixed PERG distribution, as well as on examples of measurements in 2D control geodetic networks.
The variance estimate for the basic distribution obtained by applying the PEROBVC method is compared to its ML estimate.
The structure of the further presentation is the following: 1) establishing the PEROBVC method, 2) way of solving the formulated problem, 3) presentation of robust ML estimation method, 4) correctness verification for PEROBVC method by comparing its solution to the ML one and 5) verification on examples of geodetic measurements in to 2D control networks.
2. Basis of PEROBVC Method
The idea of PEROBVC method has been presented in [24] (Section 32.14).
Consider a PERG mixed distribution (Figure 1) of empirical variances
and
(2)
with
and with the same degrees of freedom,
. The variances are obtained from primary normally distributed observations with expectations
![]()
Figure 1. Density plot for PERG mixed distribution f (s2) of empirical variances with 4 d. f. (f = 4); with
is the basic with
and
is the contaminating distribution with
(here
) and contaminating degree ε = 0.40.
;
,
where
and
are the distribution functions of the empirical variances
and
. The task is to estimate the variances
and
of both distributions on the basis of the mixed distribution with f known. In addition to the solving of this task, the method also yields estimates of the numbers of observations
and
for both component distributions
and
, i.e. the contaminating degree is estimated.
The point B divides the domain of
into two sub-domains X and Y (Figure 1) and let be:
and
—numbers of all observations, (
and
), within X and Y;
and
—numbers of observations for
and
within X;
and
—numbers of observations for
and
within Y,
, (3)
The point B will be chosen in such a way that within the interval (0, B) the observations
dominate, whereas within [B, ¥) the observations
dominate from where it follow that it must be B = Bopt (also see Figure 1).
Here the point B is defined according as
, (4)
where d is the width of the rounding interval for observations s2.
For the sake of simplifying the following designations are introduced:
(5)
Then the density of the random variable
-distribution can be written as
,
(6)
where
is the gamma function of f/2. Then
(7)
. (8)
From the equality condition for the ordinates of the two distribution densities, i.e. from the condition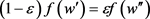 , one obtains optimal point B (Bopt)
, one obtains optimal point B (Bopt)
(9)
3. PEROBVC Solution
The estimates of the variance components for both distributions are obtained from the event-probability maximum
where
,
,
, whose likelihood function, to the proportionality constant k, is
,
where:
,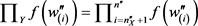 .
.
In view of (5)-(8) one finds:
. (10)
Furthermore lnL will be used there is:
, (11)
where c is a constant.
According to the asymptotic theory it is:
, (12a)
. (12b)
Bearing in mind (10)-(12) and introducing the substitutions
from the necessary maximum condition: (a)
and (b)
we get the equations
Their solution is given as simple iterations
, (13a)
. (13b)
where the numbers
,
,
and
are determined from the expressions
, (14)
whereas
and
are determined as
(15)
Note 1. The initial values for the variance components can be assumed, for example, as:
and
.
If the model assumptions are not satisfied, for example, if the distribution instead of a long tail has a shortened tail (from the right), then for one of the variances we obtain negative estimates. ∆
Note 2. Blunders in the observations (measurements with large gross errors) must be rejected before applying the PEROBVC method. For example, first find
and then
.
Those
exceeding
are rejected, whereas this procedure is repeated once more with non-rejected results. ∆
The advantages of the PEROBVC method are:
1) Unbiased estimators for
and
, if B are close to Bopt, and
2) Minimal variances for
.
The disadvantages of the PEROBVC method are:
1) A sensitivity to the choice of the point B, (point B must be close to Bopt), which can result in negative estimates for either of the variances
or
, or for both, and
2) Sensitivity to the choice of the initial values for the variances,
and
, which, also, can result in negative estimates for one or both variances.
The stopping criterion for the iterative process: Let
be the vector of parameter estimates in the k-th iteration and d the difference vector of these estimates from the (k + 1)-th and k-th iterations,
, then the iterations should be stopped if
(16)
4. Some Robust Estimation
In this case we shall use the method of Maximum Likelihood (ML).
The Robust Maximum Likelihood (ML) Estimation
The ML method is based on the assumption that in the domain X there exists only variances
(
; with
) of the basic distribution, whereas in the Y interval in addition to basic variances exist the variances of contaminating distributions. Therefore the point B in Figure 1 will be the censoring point.
The ML solution is obtained from the probability maximum for the event
,
where
,
, one obtains the likelihood function (with proportionality constant k):
.
Hence it follows
.
From the necessary condition
one obtains
.
Their solution is given as simple iterations
, (17)
where
,
,
. (18)
The stopping criterion for the iterative process can be based on the parameter difference
between two iterations:
,
, (19)
5. Results and Discussion
Example 1. By using the functions F-RAN1 and F-RAN2 [25], one simulates 10,000, (n = 10,000), samples (series) of size 4, f = 3, with F-RAN1 5000 samples are simulated (
),
and the variance estimate (from these 5000 samples)
, with F-RAN2 also 5000 samples (
), of the same size, with
and variance estimate (from these 5000 samples)
. Then a PERG mixed distribution (2), is formed (
).
Since the variances
and
are known then, according to (6), one can also find, B optimal, obtaining Bopt = 2.772589.
In Table 1, for 4 partitions (X, Y), we present the PEROBVC estimates of the variances
and
, as well as the contamination percentage
, (
).
From Table 1 it is easily noticed that the variance components, as well as the numbers of observations for both distributions, are well estimated, i.e. their values are very close to the real ones. It is also noticed that the values of the ML estimates for
are smaller than those of the PEROBVC ones for
(where it is
). ▲
Example 2. In the 2D geodetic control network of object “TUZLA” [26] from the measurements of 328 (n = 328), horizontal angles, with a theodolite Wild T3, in 6 quick locks, in stable and unstable conditions, a mixed distribution of empirical variances (in ["2]), with f = 5 d.f., is obtained (Table 2).
In Table 3, for 7 partitions (X, Y), we present the estimates of the variances
![]()
Table 1. Results of PEROBVC and ML estimations in simulated PERG mixed distribution of empirical variances s2 with
,
,
(
),
,
, f = 3 d.f., and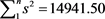 .
.
![]()
Table 2. Ordered grouped increasing sequence of 328 (n = 328) empirical variances, with f = 5 d.f., of horizontal angle measurements with a theodolite Wild T3 in the geodetic 2D control network of object “TUZLA” in epochs 1979, 1981 and 1984.
![]()
Table 3. Results of PEROBVC and ML estimates of variances for PERG mixed distribution composed of 328 (n = 328), empirical variances of horizontal angles in the 2D control network of object “TUZLA”, in epochs 1979, 1981 and 1984; f = 5 d.f., and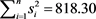 .
.
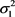 and
and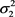 , as well as the contamination percentage
, as well as the contamination percentage  (
(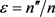 ).
).
According to an a priori analysis for the horizontal-angle measurements in stable conditions, following Činklović [27], one obtains 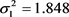 ["2], resulting in a very good agreement with 1.8109 ["2] obtained by using PEROBVC method based on the measurements.
["2], resulting in a very good agreement with 1.8109 ["2] obtained by using PEROBVC method based on the measurements.
Besides, on the basis of the results presented in Table 3 one concludes about a very high stability of the estimator for the variance component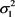 .
.
In Example 2 the average value from the ML estimates for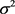 , (
, (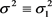 ), is also smaller than the average value of the PEROBVC estimates for
), is also smaller than the average value of the PEROBVC estimates for 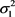 (1.6753 < 1.8109).
(1.6753 < 1.8109).
It should be noted that for the partition 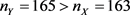 the numbers of observations
the numbers of observations ![]() and
and ![]() are well estimated, although B = 1.8 is significantly smaller than Bopt = 8.18. ▲
are well estimated, although B = 1.8 is significantly smaller than Bopt = 8.18. ▲
Note 3. In Examples 1-2 the ML estimates for ![]() are smaller than the corresponding PEROBVC estimates for
are smaller than the corresponding PEROBVC estimates for![]() , (
, (![]() ), because higher values of empirical variances are in the end of the distribution so that they do not enter the ML estimate for
), because higher values of empirical variances are in the end of the distribution so that they do not enter the ML estimate for![]() . ∆
. ∆
On the basis of applications of the PEROBVC method in the treatment of real geodetic measurements, Example 2, the present author concludes that the variance estimator of the basic distribution![]() , has a good stability.
, has a good stability.
Generally, the PEROBVC method offers good estimates, especially for![]() , which is illustrated by Examples 1-2.
, which is illustrated by Examples 1-2.
6. Conclusions
On the basis of the obtained results in Examples 1-2 we can conclude the following:
1) On the basis of exact (expected) values from Example 1 the validity of the PEROBVC method in the variance estimation, as well as the estimates of numbers of observations, for both distributions in the PERG mixed distribution of empirical variances is confirmed. Here the variance estimates for both distributions, basic and contaminating ones, are correct; i.e. their values are exact.
2) On the basis of realistic measurements for the horizontal angles in the geodetic 2D control network from Examples 2 good (satisfactory) parameter estimates for both distributions are also confirmed.
3) In Example 2 the variance estimate for the basic distribution is confirmed through the result of the a priori analysis.
Acknowledgements
Dr ZORICA Cvetković from the Astronomical Observatory in Belgrade is the author of the FORTRAN programmes who performed the calculations in the examples. The OBJEKTIV GEO D.O.O. Company from Belgrade (Serbia) has financially supported the publishing of the article.