Parallel Quick Search Algorithm for the Exact String Matching Problem Using OpenMP ()
1. Introduction
String matching algorithms are an important class of string algorithms that try to find a place where one or several strings (also called patterns) are found within a larger string or text. The fundamental string matching problem is defined as follows: given two strings a text and a pattern, determine whether the pattern appears in the text [1] . String matching algorithms are applied in many computer applications, such as data processing, image and voice recognition, information retrieval, computational biology and chemistry [2] . Furthermore, string matching algorithms have become a significant component of applications which are used to search nucleotide or amino acid sequence patterns in biological sequence databases in recent years [3] . Therefore, the performance of the string matching algorithms plays a prominent role in the performance of these computer applications [4] . This research concentrates on the problems which are related to the performance of the Quick Search string matching algorithm. Therefore, the main question is “How to reduce execution time of the Quick Search string matching algorithm by using OpenMP parallel method?” Therefore, the sub question of the main question is “How to prove the performance improvement of the parallel version of the Quick Search string matching algorithm compared with its performance of the sequential version of the Quick Search string matching algorithm?” Therefore, the objective of this paper is to investigate the suitability of parallelizing the Quick Search algorithm on multi-core environment using OpenMP.
2. Related Work
2.1. Parallel Processing
Parallel Processing is defined as the efforts of multiple concurrent processing units that works together to resolve computational problems [5] . The fundamental idea of the parallel programing is to divide the task into sub-task which can be solved simultaneously on multiple Central Processing Units (CPU’s), each sub-task of the program is sub divided into several of instructions and just one program of instructions to be carried out at any particular moment in time [6] .
2.2. Parallel String Matching Algorithms
Parallel computation holds outstanding potential of enhancing the processing and execution times of data in comparison with sequential computation which probably takes a lot of valuable time to show results. At first, generally there are many numerous parallel string matching algorithms which have been produced every single one with the intention of accelerating the overall performance of the algorithms and preserving time via the application of multi-processors. OpenMP directives is used to parallelize the string matching algorithms in a multi-core CPU environment which has broad attraction several realms of computer science; one example of these fields is the security applications, in [7] the potential for improving the speed of Intrusion Detection System (IDS) is mentioned, which is a system use to detect the hacker that try to hack the network and report this act of sabotage to the network administrator. The OpenMP directives and Pthread API which are Parallelization methods are used to speed up the Quick Search algorithm and to test the proposed method, which was dependent on analyzing several factors―such as length of pattern and size of dataset―to select the number of threads for parallel execution.
Parallel string matching algorithms have also an astonishing position in biological applications. Therefore, in [8] the author introduces a hybrid OpenMP/MPI parallel model by utilizing the benefits of shared and distributed memory technologies to the parallel three types of string matching algorithms. As a result, they were very capable of obtain optimum results with specific different types of biological databases in their proposed model. Additionally, in [9] the same author presents a different research indicated that the technique of data partitioning as well as the type of data are extremely essential factors that control the parallelization efficiency.
3. The Proposed Method
This section includes detailed explanations around the important features along with the behavior examination of Quick Search algorithm. The key reason of examining the behavior of the sequential Quick Search algorithm which involve the preprocessing phase as well as searching phase is to find out the compute-intensive portions of the code, that could be parallelize using OpenMP.
3.1. Sequential Quick Search Algorithm
Quick Search algorithm is a simplified version of Boyer Moore algorithm solves the string matching problem. In general, the Quick Search algorithm composes from two logical phases, pre-processing and searching phase [10] . The preprocessing and searching phases of the Quick Search algorithm, are summarized in the next subsections, as shown in Figure 1.
3.1.1. Pre-Processing Phase
The main idea behind the preprocessing phase of the Quick Search algorithm is to collect information about the pattern which known in advance, and use this information during the searching phase. The pattern needs to be skipped a specific amount of characters whenever a match or a mismatch is taking place during the searching process. The Quick Search algorithm use a particular structure known as a bad character table (qsBc) carries the shift information.
Starting with the rightmost character of the pattern, each character placement (i) subtracts from the value of pattern length (m) and stores in the (qsBc) table. In case there is duplicating the same character several times in the pattern the first rightmost occurrence for every character that takes place in the pattern is stored in (qsBc). According to the equation providing below, the (qsBc) table stores the minimum value of the differences between pattern length m and the rightmost locations of each repeated character in that pattern.
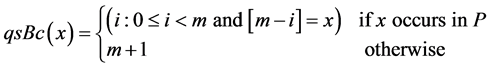
3.1.2. Searching Phase
In this phase, the Quick Search algorithm beginning the matching process from the leftmost character of the pattern with its corresponding character in the text window. If a match or mismatch occur the pattern shift to the right side depending on the value stored in (qsBc) table of the character positioned after the rightmost character of the text window, if the character that immediately follow the rightmost character in the text
![]()
Figure 1. Quick search algorithm overview flowchart.
window is takes place in the pattern, the pattern shifts to align its own character with the character that located immediately after the rightmost character of the text window. However, in the case the character that positioned after the text window is not occurred in the pattern, the whole pattern shifts to the right side of the character that follow the rightmost character of the text window, and start a new matching process.
3.2. Parallel Quick Search Algorithm Evaluation
This section discusses the main objective of this study, which is the parallelization method of Quick Search algorithm. The Quick Search algorithm is implemented on a multi-core environment platform. The OpenMP library programming interface is used to implement the code.
According to the analysis of the sequential Quick search algorithm in previous section, the most expensive section of a string matching algorithm is to examine if the character of the pattern matches the character of the text window [11] . To avoid this cost the searching phase which contains the matching process between the characters of the pattern and the text window will parallelize using OpenMP directive.
The searching phase in the Quick Search string matching algorithm is carried out using multi-core environments platform, as well as the OpenMP which is the programming environments. The OpenMP platform executed the program by divided the entire input data into subdivided parts through fork and join operations, the master thread distributed the works to the worker threads. The parallel Quick Search algorithm start execution the program in sequential fashion conducted by the master thread until the algorithm reach the searching phase function, at this moment slave threads generated for searching phase function, the number of threads is seven because our experiment was conducted using laptop with Core™ with 7 cores and 8 GB RAM The operating system used is Microsoft Windows 8.1. The slave threads executing the searching phase functions and return the partial result to the master thread, the master thread will assemble all the result with the help of join operation and show the output, this operation performed in sequential fashion, the slave threads will terminate itself automatically after send the results to the master thread as shown in Figure 2.
![]()
Figure 2. The proposed searching phase of the quick search algorithm.
4. Experimental Results and Discussion
The main idea behind parallelization the Quick Search algorithm is to enhance its performance, to measure the improvement in the performance of parallel Quick Search algorithm over its sequential version there is the execution time factor to evaluate the performance gain. In order to examine the performance of parallel algorithm, a standard benchmark data is used which is represented the common used of string matching algorithm, which are English text, Proteins sequence and DNA sequence. These different data types that have been downloaded from (http://pizzachili.dcc.uchile.cl/texts.html) are differences in the size of alphabets, as a way to analyze the algorithm behaviors with various alphabet sizes. The sequential and parallel program of Quick search algorithm was run with data size 200 MB. Moreover, various pattern lengths were used to assess the behaviors of the algorithm. These lengths are: 10, 20, 30, 40, 50, 60, 70, 80, 90 and 100 characters that are chosen randomly from words inside the text, the sequential and parallel program executed 5 times and the average time for all the attempts is selected [12] .
4.1. Parallel Performance Evaluation
4.1.1. English Text Data Type
The execution time of the sequential and parallel Quick Search algorithm using English text data type which compose of more than 100 different alphabet types is shown in Table 1 and Table 2 respectively.
Figure 3 shows the execution time (average time) of the sequential and parallel of Quick Search algorithm using English text data type. The Quick Search algorithm show unstable behavior when compared to the proteins and DNA data types, this is due to the size of the alphabet used where the English text it consist more than 100 characters, which considered a large alphabet. The unstable behavior appear clearly in the pattern length 40 and 60, which gives the worst time and best time respectively. The execution time of parallel program show better performance compare to the execution time of sequential program.
![]()
Table 1. Sequential performance using English text data type.
![]()
Table 2. Parallel performance using English text data type.
![]()
Figure 3. Execution time using English text data type.
4.1.2. Protein Sequence Data Type
The execution time of the sequential and parallel Quick Search algorithm using Protein sequence data type which compose of 20 amino acids is shown in Table 3 and Table 4 respectively.
Figure 4 show the execution time (average time) of the sequential and parallel of Quick Search algorithm using Proteins sequence data type. The Quick Search algorithm show stable behavior when compared to the English text and DNA data types, this is due to the size of the alphabet used where the Proteins sequence data type it consist with 20 characters, which considered a medium alphabet. The execution time of parallel program show better performance compare to the execution time of sequential program.
![]()
Table 3. Sequential performance using protein sequence data type.
![]()
Table 4. Parallel performance using protein sequence data type.
![]()
Figure 4. Execution time using protein sequence data type.
4.1.3. DNA Sequence Data Type
The execution time of the sequential and parallel Quick Search algorithm using DNA sequence data type which compose of 4 characters that indicate the chemical foundations of the cell nucleus is shown in Table 5 and Table 6 respectively.
Figure 5 shows the execution time (average time) of the sequential and parallel of Quick Search algorithm using DNA sequence data type. The Quick Search algorithm show stable behavior when compared to the English text and Proteins sequence data types, this is due to the size of the alphabet used where the DNA sequence data type it consist only 4 characters, which considered a small alphabet. The execution time of parallel program show better performance compare to the execution time of sequential program.
![]()
Table 5. Sequential performance using DNA sequence data type.
![]()
Table 6. Parallel performance using DNA sequence data type.
![]()
Figure 5. Execution time using DNA sequence data type.
5. Conclusion
This study aims to parallelize the Quick Search exact string matching algorithm. Based on the design presented in Section 3, the parallelization method produced a parallel Quick Search algorithm using OpenMP directive. From the results in Section 4, we can note that when parallelizing the Quick Search algorithm by using OpenMP directive under multi-core environment, the parallel program shows better performance compared to the sequential program in terms of execution time when using different data types with different patterns length. In addition, the experimental results show that when using English text data type the Quick Search algorithm gives unstable results due to the size of the alphabet which is considered a large alphabet, but it gives a stable result when using medium and small alphabet as proteins and DNA data types. As a conclusion, we recommend the multi-core environment as the suitable platform for parallelizing the Quick Search string matching algorithm. For future work the parallel Quick Search algorithm could be enhanced by parallelizing the preprocessing phase with the searching phase.