Methods of Importance Evaluation for Information Subsystems in Manufacturing Enterprises Based on Centrality ()
1. Introduction
Manufacturing companies often cannot scientifically determine the priorities of information subsystems in ma- nagement activities such as information system planning, resource allocation and utilization or information system maintenance. As a result of these limitations, phenomena such as low customer satisfaction, low productivity and systematic failures frequently appear in enterprises [1] . Therefore, the evaluation of information subsystems is essential to be considered as an important management activity for manufacturing companies.
Most studies of an information system focus on internal structures and properties of approximation spaces [2] - [11] . Missing from the traditional information system, relevant research on the importance of information subsystems is neglected from previous literature. The evaluation in other domains relies mainly on a series of indexes to reflect the importance of objects. The index values are derived from expert evaluations or sample data. Based on expert evaluations, AHP, Delphi, fuzzy comprehensive evaluation and integrated models of them have rapidly penetrated into and are widely applied to many fields of engineering, economy and finance, transportation, ecosphere, energy and etc. [1] [12] - [21] . Given the prevalence of expert evaluations, an interesting question becomes whether or not other methods can objectively assess the importance of subjects. The regression model is one of the approaches in point, which is tested effectively to evaluate the importance of variables in theory and demonstrated its feasibility in practice [22] - [24] . Based on sample data, other evaluative methods including principal component analysis, grey relational analysis, entropy evaluation methods and factor analysis are available and widely used in the manufacturing, agricultural, communications and tourism industries [25] - [32] .
However, the evaluation methods of experts are subjective while the evaluation methods based on sample data are ex-post. These methods are difficult to objectively evaluate objects in advance. Centrality based evaluation methods take the nodes in systems or networks as evaluative subjects, and evaluate importance of the nodes by the real interactions between nodes. These centrality based methods provide new approaches for importance evaluation of information subsystems.
Centrality based evaluation methods are derived from social networks [33] . Until now, these methods have already extended to fields of physics, psychology, transportation, economy and finance, and etc. [34] . Some scholars have also demonstrated practicability and effectiveness of centrality in those fields [35] - [42] . Nevertheless, centrality based methods have not been applied to the information systems of firms. The information systems of manufacturing enterprises are composed of many subsystems and the interactions between all of the adjacent subsystems. Considering information subsystems as nodes or vertexes and interactions as edges between the nodes, the structures of information systems are then transformed into network structures. From the perspective of interactions, the centrality models are applied to determine the importance of each information subsystem. We will discuss the implementation of our model that uses the example of an elevator enterprise. Results can supply theoretical direction for specific practices in management activities of an information system.
The paper is organized as follows. The structure for a manufacturing enterprise information system is presented in Section 2. Centrality models that are used to evaluate the importance of information subsystems are shown in Section 3. The implementation of centrality based models for an elevator enterprise is shown in Section 4. Finally it is conclusions, acknowledgements.
2. Structure for Information Systems in Manufacturing Companies
Information systems in different manufacturing companies are varied. To facilitate our research, the article puts forward a typical and functional structure for the purpose of representing diverse information systems. The division standard of the proposed structure of the information system is in accord with the functions that are covered by the commercial software in current time. Its scope limits to the information system in applied layer, excluding operating system, security management system etc. ERP (Enterprise Resource Planning) System does not contain the systems of CRM (Customer Relationship Management) System, SCM (Supply Chain Management) System, HR (Human Resource) System, etc. As is shown in Figure 1, the combination of a line and an arrow stands for interaction between two subsystems. Arrow is the direction that information flows. Thus, the double- headed arrow means the information transmission between the two subsystems is bidirectional while the single arrow means unidirectional.
The networks include nodes and edges, in which nodes are subjects and edges are relations between subjects. In the network structure of the information system, nodes on behalf of subsystems while edges stand for information flow relationship between subsystems. Figure 2 shows the network structure of the information system. Nodes are adjacent if they are connected by an edge. The nodes arrows pointing to are downstream nodes, otherwise upstream nodes. There are two edges between nodes if a line has two arrows.
Figure 2 displays that some nodes have some obvious characteristics of strongly gathering or radioing information, and being close to others. All these apparent features indicate the importance of nodes. However, these visual features still cannot multi-dimensionally reflect the importance of nodes. From interactions perspective, the paper proposes centrality based methods to evaluate the importance of subsystems multi-dimensionally.
3. Centrality Models for Information Subsystems
Information systems are heterogeneous systems [43] [44] . The functions of each system are diverse. Conse-
![]()
Figure 1. The functional structure of the information system in the manufacturing enterprise.
![]()
Figure 2. The network structure of the information system presented in Figure 1.
quently, their importance for enterprise is not the same. The network structures of enterprise information systems are real network, and edges between subsystems are determined when enterprises planning their information systems. Hence, nodes are connected by defined laws, and the network structures of information systems are certain. Centrality is widely employed to analyze the properties in various networks, and different measures of centrality capture aspects of what it means for a node to be important to the network. Therefore, the paper applies several centrality models evaluate the importance of subsystems. In order to objectively evaluate the importance of subsystems before put into use, centrality models are established.
3.1. Model Assumptions
1) The route that information follows is path;
2) When information passing vi, it can stop at vi and also can flow to its downstream nodes;
3) The possibilities that information stop at vi or flow to each of its downstream nodes are the same;
4) The distance between any two adjacent nodes is 1;
5) The information capacity between any two adjacent nodes is infinite.
3.2. Model Establishment
The centrality models are constructed in the perspectives of the ability to gather or radio information to their neighborhood, the ability to control information, the ability to affect system function, information transmission efficiency and the amount of information. Among the diverse measures of centrality, degree centrality and semi- local centrality reflect the ability of a node to influence its surrounding nodes. Besides, betweenness centrality and flow betweenness centrality depict the ability of nodes to control information while closeness centrality shows information transmission efficiency of nodes. Finally, entropy centrality measures the amount of information of each node, and residual closeness centrality shows the influence of each node to system function.
3.2.1. The Ability to Influence Surrounding Nodes
1) Out-degree centrality and in-degree centrality
For directed network, degree centrality usually refers to out-degree centrality and in-degree centrality. Out- degree centrality and in-degree centrality of a vertex vi are respectively marked as Cd+(vi) and Cd−(vi). Cd+(vi) and Cd−(vi) indicate the number of downstream nodes and upstream nodes that directly influenced by vertex vi. The vertex vi with bigger values of Cd+(vi) and Cd−(vi) can influence more vertexes in its neighborhood. Therefore, the vertex vi is more important. On reference [45] , the expression of Cd+(vi) and Cd−(vi) are written as
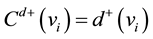 (1)
(1)
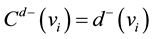 (2)
(2)
d+(vi) and d−(vi) denote the out-degree and in-degree of a vertex vi.
2) Semi-local centrality
To nodes with the same out-degree and in-degree, we cannot pick out which is more critical just through degree centrality method. In such a case, semi-local centrality is a valid approach. This method reflects the ability of a node to affect other nodes in its indirect neighborhood [46] . The node with bigger value of semi-local centrality is more important. The expression of semi-local centrality for each node is described by the equation
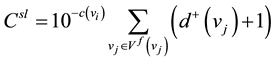 (3)
(3)
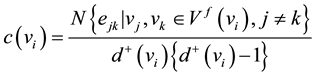 (4)
(4)
c(vi) is the clustering coefficient of a vertex vi. Let ejk as the edge between vertex vj and vertex vk, and information flows from vertex vj to vertex vk. Vf(vi) is the set of downstream vertexes of vertex vi, and N{ejk|vj,vk ∈ Vf(vi), j ≠ k} is the number of the edges that are composed by the downstream nodes of vertex vi. Let c(vi) = 0 if d+(vi) ≤ 1.
3.2.2. The Ability to Control and Transfer Information
1) Betweenness centrality
A vertex vi can control information to a great extent if there are many geodesics passing through it. Under the circumstances, the vertex vi has a big value of betweenness centrality. What’s more, the node with high value of betweenness is important [47] . Betweenness centrality calculates the number of geodesics passing by each node, and is denoted by Cb(vi). We need appropriately weight if there are multiple geodesics [48] . For example, from vertex v1 to vertex v3, there are two geodesics, they are geodesic g1(v1,v3) = {v1,e12, v2,e23, v3} and geodesic g2(v1,v3) = {v1,e14, v4,e43, v3}. However, geodesic g1(v1,v3) is the only geodesic via vertex v2, so Cb(v2) = 0.5.
2) Flow betweenness centrality
Betweenness centrality merely considers the ability to control information of each node in geodesics. However, information is not always transferring by geodesics [49] . Flow betweenness centrality counts the number of paths via each node [50] . The high value of flow betweenness centrality of a vertex vi means that vertex vi can strongly control information. The flow betweenness centrality of a vertex vi in directed network is expressed by following equations
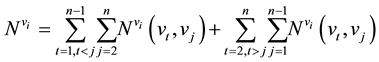 (5)
(5)
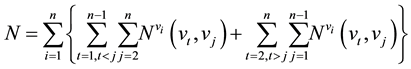 (6)
(6)
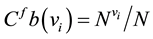 (7)
(7)
 is the number of paths that passing through vertex vi, and N is the total number of paths in the directed network.
is the number of paths that passing through vertex vi, and N is the total number of paths in the directed network.
3) Closeness centrality
Closeness centrality measures the efficiency of information transmission for each node. The closeness centrality of a vertex vi counts the total distance from vertex vi to the remaining vertexes in the network [45] . The vertex with short distance can transmit information efficiently. Closeness centrality in directed networks is defined as
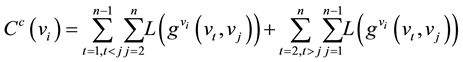 (8)
(8)
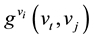 is the geodesic starting at vertex vt, ending at vertex vj and passing by vi.
is the geodesic starting at vertex vt, ending at vertex vj and passing by vi. 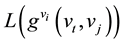 is the length of the geodesic
is the length of the geodesic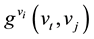 .
.
3.2.3. The Amount of Information and the Effect to System Function
1) Entropy centrality
In general, there are N(vi,vj) paths from vertex vi to vertex vj. Let gk(vi,vj) be such a path, and its length is L(gk(vi,vj)). The probability that a vertex vt transfers information to its downstream vertexes is given by:
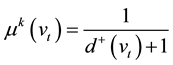 (9)
(9)
and the probability that information stops at vertex vt is
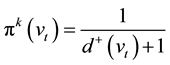 (10)
(10)
The vertexes between vertex vi and vertex vj, and travelling along the path gk (vi,vj) are vi=v0, v1, …, v (L(gk(vi,vj))) = vj. The information transfer probability from vertex vi to vertex vj in the path gk(vi,vj) is
![]() (11)
(11)
For all the paths from vertex vi and vertex vj, the ending and transfer probabilities of vertex vj are the same. Therefore, the transfer probabilities from vertex vi to vertex vj are summed as
![]() (12)
(12)
Finally, entropy centrality of a vertex vi is
![]() (13)
(13)
Entropy centrality [48] shows the quantity of information that each node contains, and the node with more information is more vital.
2) Residual closeness centrality
Residual closeness centrality reflects the significance of each node to the function of the information system. The node will be more important if removing this node leads the system more vulnerable [51] . Specifically, after the removal, the node with smaller value of residual closeness centrality can influence the system function more greatly and thus it is more important. The residual closeness centrality of a vertex vi in the directed networks is described as
![]() (14)
(14)
After removing the vertex vi, g(vt, vj) is one of the geodesics between vertex vt and vertex vj, and its length is![]() . Let
. Let ![]() if there is no path from vertex vi to vertex vj.
if there is no path from vertex vi to vertex vj.
4. Case Study: Application to an Elevator Manufacturing Enterprise
This section presents an application of the proposed methods in an elevator manufacturing enterprise. We use the elevator manufacturing enterprise as an example because: 1) it has a relatively long history of 30 years and it is the biggest elevator manufacturing enterprise in southern China; 2) driven by the advanced technology and dynamic requirements, the enterprise is going through a transformation; 3) the company spends a lot on constructing and perfecting its information system for its development highly relies on information system. However, with the relatively well-developed information system, some problems remain appear.
4.1. Problems Description
Since it set up, the enterprise has implemented a series of information subsystems, such as ERP System, Manufacturing Execution System (MES) and Knowledge Management (KM) System. In response to requirements, the enterprise devotes itself to developing new systems and improving the old systems. Now information systems have been widely applied in the company. Figure 1 shows the function structure of the information system in the enterprise. Although the function structure was relatively perfect, some unfavorable phenomena were still very serious. For example, the consumer satisfaction was still low in accordance with the report from the marketing department; the productivity was poor and the failures of the information system had not been improved. Under this situation, the enterprise thoroughly analyzed all the problems. They found that: 1) the implementation order of subsystems cannot meet the business requirements well, for the needed subsystems had not been well implemented while the running systems were not required much; 2) the resource distribution to subsystems was unreasonable when function structure of the information system was relatively completed, for example some subsystems occupied large number of resources of which other subsystems needed extremely; 3) in addition, when maintaining the information system, IT department treated subsystems equally so that the subsystems with bugs occurred frequently received insufficient attention before bugs occurred.
4.2. Results Analysis
The centrality models in the paper can be used to find out the vital subsystems. Results provide decision basis for management activities of information system, such as the step-by-step implementation, resource distribution and maintenance of the subsystems. As is shown in Figure 2, there may be more than one geodesics or paths between nodes for the directed relationships between subsystems, and it is difficult to find out all the geodesics or paths artificially. Therefore, software called Code Blocks is used to aid the computation of centrality for each node. Tables 1-3 show the centrality values and ranks of each node.
1) As is shown in Tables 1-3, the capability of ERP System (vertex v6) to influence its surrounding subsystems is strong. Moreover, its transmission efficiency of information, controlling ability of information and influence on system function all rank first. Besides, ERP System contains much information. ERP System shows the optimal combination for information since it integrates the information on main resources of purchase, production, inventory, distribution, finance and human resources etc. Thus, it contains abundant information and
![]()
Table 1. Statistics for the ability to influence surrounding nodes.
![]()
Table 2. Statistics for the ability to control and transfer information.
![]()
Table 3. Statistics for the amount of information and the effect to system function.
can strongly control information. In order to efficiently combine resources and roundly reflect its status, EPR System should strongly gather and radio information on a large scale. Furthermore, ERP System needs quickly transmit the integrated information to make timely decisions.
2) The E-commerce platform (vertex v1) has prominent influence on the information system function although it contains little information. It can efficiently transmit and strongly control, gather and radio the information. For businesses, E-commerce platforms play an important role in presenting enterprise image, advertising the product and increasing its trade opportunities. So the platform needs to interact with other subsystems as much as possible to promote the mutual understanding between consumers and enterprises themselves. Meanwhile, it should accurately transmit the external information to other internal subsystems in time to facilitate the lateral interaction and information sharing among subsystems. In fact, the E-commerce platform is a dynamic system which frequently transfers information to other systems in small batches. This transferring mode of information enables the enterprise to respond to requirements quickly and timely. E-commerce platform is the system with small amount of information, and it is the feature that makes it possible to accept the outside information. E-commerce platform is critical to system function for it is the most direct system to make profits.
3) MES (vertex v9) has the relatively strong ability to gather and radio information, to influence system function and to transmit information efficiently. The most notable is that MES contains the largest amount of information. As a workshop-oriented management information system, MES covers all the information involved in production activities, includes numerous models of resource distribution, status management, operation, assignment of production cells and control of file etc. The products output by MES are the profitable carriers for an enterprise. MES is the basic and special subsystem of the manufacturing enterprise, and other subsystems exist by assisting it to complete production. Therefore, MES must possess relatively strong ability to radio and transfer information. Only in this way can it be better to interact with other systems, then to guarantee the order of productive activities. In addition, due to its own features, KM System (vertex v11) is the most capable to collect information from its neighborhood. As the electronic library of an enterprise, KM System holds and manages the knowledge assets from other systems.
In conclusion, ERP System in the manufacturing company has the largest values of centrality in accordance with the case, and it is the core of the information system. The new features of consumer participation and network collaboration in supply chain in manufacturing enterprises attribute to the relatively high values of centrality for E-commerce platform. Besides, MES still possesses relatively high values of centrality when service accounts for a large proportion in the manufacturing enterprise. The importance of E-commerce platform and MES is only next to ERP System.
After distinguishing the key information subsystems, the enterprise gave preference to the critical subsystems in the subsequent activities of resource allocation, system improvement and maintenance. After the improvement, the information system operates more smoothly and the relationships between subsystems become more coordinated. From visual perspective, system failures strikingly decrease, productivity improves, and so does the customer satisfaction.
5. Conclusions
We construct centrality models to evaluate the importance of information subsystems mainly from three aspects. The paper uses an elevator manufacturing enterprise in Guangzhou as an example. Our analysis yields a number of managerial insights pertaining to the research questions posed in the introduction. First and foremost, the priorities of subsystems in manufacturing companies are not the same. In our study of a typical manufacturing enterprise, the importance of the 11 subsystems varies. Moreover, ERP System, E-commerce platform and MES are the top 3 subsystems in manufacturing enterprises. Second, when manufacturing firms are greatly influenced by the dynamic requirements and the rapid development of the Internet, E-commerce platform is increasingly critical to them. Therefore, manufacturing enterprises should pay special attention to the E-commerce platform in the management activities of information systems. Third, service is increasingly vital to manufacturing enterprises. Consequently, the status of MES has declined but it is still an important part of the information systems. Finally, let the key information subsystems be the decision basis in the activities of planning and maintenance, resource allocation and utilization etc for the information systems can reduce systematic failures, enhance productivity and increase customer satisfaction.
The proposed centrality based evaluation methods can objectively evaluate the importance of information subsystems in advance. The application of Code Blocks makes the calculation more scientific, accurate and rigor. Methods proposed can avoid numerous data collection, eliminate the influence of subjective factors and avert irremediable consequence that feedback control usually cannot make up for. The approaches applied are applicable for complex systems of enterprise information systems, transportation systems, management systems.
Acknowledgements
Authors would like to acknowledge the financial support from the National Natural Science Foundation of China (No. 50675069).