Empirical Likelihood Inference for Generalized Partially Linear Models with Longitudinal Data ()
1. Introduction
An important issue in statistical inference is to construct the confidence region for parameters of interest. The convention method is the normal approximation method which based on the asymptotic normal distribution of parameter estimators. The normal approximation (NA) method requires estimating the limiting variance of regression parameter, which is very complicated in some situation. Besides, the confidence region derived from the NA method is predetermined to be symmetric.
As a nonparametric data-driven technique, the empirical likelihood (EL) approach employs empirical likelihood function without specifically assuming a distribution for the data, while it can incorporate the side information through constraints, which maximizes the efficiency of the method. Compare with the NA method, EL approach does not involve a plug-in estimation for the limiting variance, and the shapes and the orientation of the confidence region obtained are automatically determined by the data. There has been a lot of literature in empirical likelihood, e.g., [1] - [12].
Longitudinal data often occurs in biomedical research where the repeated measurements form subjects are collected over times, and therefore the responses from same subjects are very likely to be correlated with an unknown structure. The challenge for longitudinal data lies in how to effectively utilize the within-cluster information. The early works in EL for longitudinal data ignored the correlations within subjects, e.g. [7] [8]. Some recent studies incorporate the correlation information by constructing the auxiliary random vector through the generalized estimating equations (GEEs) [9] [10]. The GEEs use a working correlated matrix to carry the correlation information. The working correlated matrix is decided by a small set of nuisance parameters
to avoid the specification of the whole correlation matrix [13]. The advantage of the GEEs is that the estimators of the regression parameter
are always consistent. However, GEEs estimator suffers a great loss in efficiency when the correlation structure is misspecified. The quadratic inference functions (QIFs) approach avoids estimating the nuisance correlation parameters
by assuming that the inverse of the working correlation matrix can be approximated by a linear combination of several known basis matrices, and solve the combined estimation functions by using the principle of the generalized method of moments [14] [15]. The QIFs can also take the within-cluster correlation into account and is more efficient than GEEs when the working correlation is misspecified. The QIFs approach has been applied to many models, including varying coefficient models, partially linear models, single-index models and generalized linear models. The recent related works include [16] - [21]. More recently, [11] [12] proposed generalized empirical likelihood method (GEL), which using a QIFs-based generalized log-empirical likelihood ratio statistics to construct the confidence region for the parameters in generalized linear models (GLMs) with longitudinal data and partially linear models with Longitudinal data.
Generalized partially linear models (GPLMs) can be regarded as a comprise between the GLMs and fully nonparametric models. The choice of a partial linear model is sometimes made to avoid nonparametric specification of high-dimensional covariates, and at other times the model arises naturally due to categorical covariates. In this article, we extend the GEL method to GPLMs with longitudinal data and the B-spline method is adopted to approximate the nonparametric component in the model. Our method incorporates the within-cluster correlation information into the auxiliary random vector. Our proposed method does not require the estimation of the variance of the proposed estimator and is not sensitive to the misspecification of the working correlation structure.
The rest of this article is organized as follows. We propose the QIF-based EL method for GPLMs in Section 2 and present the corresponding asymptotic results in Section 3. Simulation studies are provided in Section 4 and a real data is analysed in Section 5. The details of the proofs are provided in the Appendix.
2. Model and Generalized Empirical Likelihood
2.1. GPLMs with Longitudinal Data
In this article, we consider a longitudinal study with n subjects and
observations over time for the ith subject (
), for a total of
observations. Each observation consists of a response variable
and the covariate vectors
, where
and
is a scalar. We assume that the observations from different subjects are independent, but those from the same subject are dependent. The generalized partially linear model (GPLMs) with longitudinal data take the form
(1)
where
is a
vector of unknown regression coefficients,
is a known monotonic smooth link function,
is a unknown smooth function and
is a known function with
. Without loss of generality, we assume
.
Following [22], we replace
by its basis function approximations. More specifically, let
be the B-spline basis functions with the order of M, where
, and K is the number of interior knots. We use the B-spline basis functions because they often provide good approximations with a small number of knots. Besides, the B-spline basis functions have bounded support and are numerically stable. The spline approach also treats a non-parametric function as a linear function with the basis functions being the pseudo-design variables, thus any computational algorithm developed for the generalized linear models can be used for the generalized partially linear models.
Suppose
can be approximated by
, where
is a
vector of unknown regression coefficients. Then our regression model (1) becomes
(2)
Denote
, and write
in a similar fashion. Following the QIFs approach, the extend score
is defined to be
(3)
where
is the marginal covariance matrix of the ith subject and
are known matrices for approximating the inverse of the working correlation matrix
in GEEs. Then
is obtained by minimizing the following quadratic inference function
(4)
where
.
Hence,
is the QIF estimator of
, and the estimator of
can be obtained by
, where
is the QIF estimator of
. Details of the QIFs estimator for GPLMs with longitudinal data refers to [21].
2.2. GEL for GPLMs with Longitudinal Data
In most applications of GPLMs, the main interest is the statistical inference on the regression coefficient
. Similar with [5], we regard the nonparametric function
, i.e. the spline coefficient
as nuisance, and conduct a suitable estimator of it to make sure the efficient statistical inference for
. In this article, we take the QIF estimate
as the estimator of
.
Noticing
in (3) carries the within-cluster correlation information, in order to construct the empirical likelihood ratio function for , we introduce the auxiliary random vector
, we introduce the auxiliary random vector
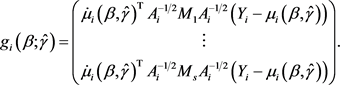 (5)
(5)
Note that 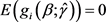 when
when , we define the generalized empirical log-likelihood ratio function as follows,
, we define the generalized empirical log-likelihood ratio function as follows,
 (6)
(6)
By the Lagrange multiplier method, we obtain that 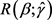 is maximized at
is maximized at
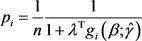 (7)
(7)
where 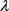 is a
is a 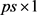 vector satisfies
vector satisfies
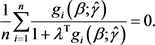 (8)
(8)
Then  can be represented as
can be represented as
 (9)
(9)
By minimizing  under the Equation constraints (8), we can obtain the maximum empirical likelihood estimator (MELE) of the parameter
under the Equation constraints (8), we can obtain the maximum empirical likelihood estimator (MELE) of the parameter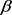 .
.
3. Asymptotic Properties
For convenience and simplicity, let C denote a positive constant that may have different values at each appearance throughout this paper and 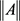 denote the modulus of the largest singular value of matrix or vector A. Before the proof of our main theorems, we list some regularity conditions that used in this paper.
denote the modulus of the largest singular value of matrix or vector A. Before the proof of our main theorems, we list some regularity conditions that used in this paper.
Assumption (A1): The spline regression parameter  is identifiable, that is,
is identifiable, that is,  is the spline coefficient vector from the spline approximation to
is the spline coefficient vector from the spline approximation to . In addition, there is a unique
. In addition, there is a unique ![]() satisfying
satisfying![]() , where S is the parameter space.
, where S is the parameter space.
Assumption (A2): The weight matrix ![]() converges almost surely to a constant matrix
converges almost surely to a constant matrix![]() , where
, where ![]() is invertible.
is invertible.
Assumption (A3): The covariate matrices ![]() satisfy that
satisfy that ![]() .
.
Assumption (A4): The error ![]() satisfies that
satisfies that ![]() , and there exists a postive constant
, and there exists a postive constant ![]() such that
such that ![]() .
.
Assumption (A5): All marginal variances ![]() and
and![]() .
.
Assumption (A6): ![]() is a bounded sequence of positive integers.
is a bounded sequence of positive integers.
Assumption (A7): ![]() is rth continuous differentiable on (0, 1), where
is rth continuous differentiable on (0, 1), where![]() .
.
Assumption (A8): The inner knots ![]() satisfy
satisfy
![]()
where
![]()
Assumption (A9): The link function ![]() is 2nd continuous differentiable and
is 2nd continuous differentiable and ![]() for some
for some![]() .
.
[Remark] (A1) is for the identification. (A2) holds when based on the weak law of large numbers when n goes to infinity and the maximum cluster size is fixed, i.e., when (A6) holds. (A3)-(A6) are the common regularity conditions in the longitudinal data analysis. (A7) is the usual assumption in spline approximation, it determines the convergence rate of spline estimate![]() . (A8) is the general condition for the knots in B-spline approximation. (A9) is the common condition in the study of GLMs.
. (A8) is the general condition for the knots in B-spline approximation. (A9) is the common condition in the study of GLMs.
We next study the asymptotic properties of the resulting GEL estimators. We first introduce some notations. Let ![]() denote the true values of
denote the true values of ![]() and
and ![]() be the MELE of
be the MELE of![]() . The following Theorem 1 shows that the
. The following Theorem 1 shows that the ![]() is asymptotically distributed as a Chi-square with ps degrees of freedom.
is asymptotically distributed as a Chi-square with ps degrees of freedom.
Lemma 1. Suppose that the regularity conditions of (A1)-(A9) hold and the numbers of knots![]() , then
, then
![]()
This is a direct result from Theorem 1 of [21].
Lemma 2. Suppose that the regularity conditions of (A1)-(A9) hold and the numbers of knots![]() , then
, then
![]() (10)
(10)
![]() (11)
(11)
The proof can be found in the Appendix.
Theorem 1. Assume that the conditions (A1)-(A9) hold and the numbers of knots![]() , then
, then
![]()
where ![]() represents the convergence in distribution.
represents the convergence in distribution.
The proof can be found in the Appendix.
Let ![]() be the
be the ![]() quantile of
quantile of ![]() for any
for any![]() . From Theorem 1, an approximate
. From Theorem 1, an approximate ![]() confidence region can be established by
confidence region can be established by
![]()
Denote
![]()
![]()
If the matrices ![]() and
and ![]() are invertible, we obtain the asymptotic normality of
are invertible, we obtain the asymptotic normality of![]() .
.
Theorem 2. Suppose that the conditions (A1)-(A9) hold and the numbers of knots![]() , then
, then
![]()
where![]() .
.
The proof can be found in the Appendix.
The confidence region interval of each component of ![]() is also worth concerning. Let
is also worth concerning. Let ![]() denote the unit vector with 1 at the rth entry, for
denote the unit vector with 1 at the rth entry, for![]() . The estimate of the rth component of
. The estimate of the rth component of ![]() is
is![]() , for
, for![]() . Let
. Let
![]()
where ![]() is the
is the ![]() identity matrix,
identity matrix, ![]() is the Kronecker product, and
is the Kronecker product, and ![]() is defined in (5). Then, the partial generalized empirical log-likelihood ratio for
is defined in (5). Then, the partial generalized empirical log-likelihood ratio for ![]() is defined as
is defined as
![]()
Theorem 3. Assume that the conditions (A1)-(A9) and the numbers of knots![]() , if
, if ![]() is the true parameter, then
is the true parameter, then
![]()
The proof of Theorem 3 is similar to that of Theorem 1, we hence omit here.
Applying Theorem 3, the approaximate ![]() confidence interval for
confidence interval for ![]() can be constructed by
can be constructed by
![]()
4. Simulation Studies
In this section, we conduct simulation studies to evaluate the finite sample performance of the proposed methods. We compare the GEL with the NA-based method in terms of the coverage probability and the lengths of the obtained confidence region.
In our non-parametric estimation implementation, we use the sample quantiles of ![]() as knots. Moreover, we use cubic splines and take the number of internal knots to be the integer around
as knots. Moreover, we use cubic splines and take the number of internal knots to be the integer around![]() . This particular choice is consistent with the asymptotic theory in Section 3 and performs well in the simulations.
. This particular choice is consistent with the asymptotic theory in Section 3 and performs well in the simulations.
4.1. Study 1
Consider a binomial response:
![]()
where ![]() and 150,
and 150,![]() . The clustered binary responses are generated as [23]. The correlation parameter
. The clustered binary responses are generated as [23]. The correlation parameter ![]() are taken to be 0.25, 0.5 and 0.75 which represent weak, medium and strong correlation respectively. We generated 500 data sets for each pair of (
are taken to be 0.25, 0.5 and 0.75 which represent weak, medium and strong correlation respectively. We generated 500 data sets for each pair of (![]() ).
).
Table 1 list the EL-based and NA-based confidence intervals of ![]() under CS structure. It shows that the GEL approach gives a slightly shorter confidence intervals than the NA method, while the former has a coverage probability more
under CS structure. It shows that the GEL approach gives a slightly shorter confidence intervals than the NA method, while the former has a coverage probability more
![]()
Table 1. The average length and the corresponding coverage probabilities of the 95% confidence region of ![]() for GEL and NA when the correlation structure is CS.
for GEL and NA when the correlation structure is CS.
closer to the nominal level. In addition, the coverage probability obtained by GEL approach tend to the nominal level and the average length decrease as n increases.
To study the influence of mis-specification to GEL approach, we derive the GEL confidence interval when the working correlation structure is specified to be CS and AR-1 respectively. Table 2 list the results when the true structure is CS. Table 3 list the results when the true structure is AR-1. It is known that the QIFs estimator is insensitive to mis-specification in correlation structure. Table 2 and Table 3 show that the QIFs-based GEL approach gives similar 95% confidence interval and coverage probability even the correlation structure is misspecified, which means the proposed GEL approach is robust.
![]()
Table 2. The average length and the corresponding coverage probabilities of the 95% confidence region of ![]() for GEL when the true correlation structure is CS.
for GEL when the true correlation structure is CS.
![]()
Table 3. The average length and the corresponding coverage probabilities of the 95% confidence region of ![]() for GEL when the true correlation structure is AR-1.
for GEL when the true correlation structure is AR-1.
4.2. Study 2
We consider a two-demensional logistic model with![]() , and
, and
![]()
where ![]() and
and ![]() are drawn independently from a uniform distribution on
are drawn independently from a uniform distribution on![]() . The clustered binary responses with exchangeable correlation structure are also generated as [23]. The correlation parameter
. The clustered binary responses with exchangeable correlation structure are also generated as [23]. The correlation parameter ![]() are taken to be 0.3 and 0.8.
are taken to be 0.3 and 0.8.
Carried out 200 simulation runs, the EL-based and NA-based 95% confidence intervals for ![]() when
when ![]() are reported in Figure 1. It shows that GEL approach gives a smaller confidence region than the NA method. As to the coverage probability, the GEL approach is more closer to the nominal level than NA (0.925 vs 0.90). The result of
are reported in Figure 1. It shows that GEL approach gives a smaller confidence region than the NA method. As to the coverage probability, the GEL approach is more closer to the nominal level than NA (0.925 vs 0.90). The result of ![]() is similar, we omit here.
is similar, we omit here.
5. Example: Infectious Disease Data
To investigate the performance of the proposed method, we analysis an infectious disease data. In this study, a total of 275 preschool children were examined every three months for 18 months. The outcome is the presence of respiratory infection (1 = yes, 0 = no). The primary interest is in studying the relationship of the risk of respiratory infection to Vitamin A deficiency, which is indicated by xerophthalmia variable (1 = yes, 0 = no). The other covariates included: age,
![]()
Figure 1. The 95% confidence region of ![]() based on GEL and NA approach when
based on GEL and NA approach when ![]() for Study 2.
for Study 2.
![]()
Figure 2. The 95% confidence region of ![]() based on GEL and NA approach under exchangeable correlation structure for infectious disease data.
based on GEL and NA approach under exchangeable correlation structure for infectious disease data.
gender (1 = female, 0 = male), height, stunting status (1 = yes, 0 = no), and the seasonal Cosine and seasonal sine variables which indicate the season when those examinations took.
This data set has been well analyzed by many authors, such as [24] [25] [26] [27] [28]. We here consider a simple logistic model:
![]()
where ![]() is the mean of the risk of respiratory infection,
is the mean of the risk of respiratory infection, ![]() and
and ![]() describe the effects of Vitamin A deficiency and the sex aspect. We use two methods: the NA method and QIFs-based GEL under the CS correlation. The confidence regions are reported in Figure 2. It shows that GEL gives smaller confidence regions than NA does.
describe the effects of Vitamin A deficiency and the sex aspect. We use two methods: the NA method and QIFs-based GEL under the CS correlation. The confidence regions are reported in Figure 2. It shows that GEL gives smaller confidence regions than NA does.
Acknowledgements
We thank the Editor and the referees for their comments. The research is funded by the National Natural Science Foundation of China (11571025) and the Beijing Natural Science Foundation (1182008). This support is greatly appreciated.
Appendix
Proof of Lemma 2
Proof. Consider the kth component of![]() :
:
![]() (12)
(12)
Note that
![]() (13)
(13)
Apply Taylor expansion to the first two terms in (13) at![]() , we obtain
, we obtain
![]() (14)
(14)
where ![]() is between
is between ![]() and
and![]() ,
, ![]() is between
is between ![]() and
and ![]() , and
, and
![]()
![]()
![]()
![]()
Substitute (14) into (12), we obtian
![]()
From conditions (A7), (A8) and theorem 12.7 in [29], we have ![]() and
and![]() . Then, invoking conditions (A3)-(A5), by a simple calculation, we have
. Then, invoking conditions (A3)-(A5), by a simple calculation, we have ![]() and
and ![]() .
.
Invoking conditions (A4)-(A9), by lemma 1 , we have ![]() and
and![]() .
.
Denote
![]()
![]()
we have
![]()
Follow [11], we obtain
![]()
i.e.
![]()
Similarly, (11) can be proved. Thus we complete the proof of the Lemma 2.
Follow the argument of [4], we can prove
![]() (15)
(15)
Proof of Theorem 1
Proof. Applying Taylor expansion to![]() , we obtain
, we obtain
![]()
Recall (8), it follows that
![]()
This together with Lemma 1 and (15) proves that
![]()
and
![]()
Therefore, we have
![]()
Together with Lemma 2, we complete the proof of Theorem 1.
Proof of Theorem 2
Proof. We first define bivariate functions ![]() and
and ![]() respectively as
respectively as
![]()
![]()
Under the condition (A1), if ![]() is the MELE of
is the MELE of ![]() and
and ![]() is the root of (8), following Lemma 1 of [3], we have
is the root of (8), following Lemma 1 of [3], we have
![]()
Expanding ![]() and
and ![]() at
at![]() , together with conditions (A6)-(A9) and Lemma 2, we have
, together with conditions (A6)-(A9) and Lemma 2, we have
![]()