Rough Sets for Human Resource Competence Evaluation and Experiences ()
Received 17 May 2016; accepted 23 July 2016; published 26 July 2016

1. Introduction
The evaluation of labor competencies is an important activity for proper management of human resources. It depends on the successful completion of other activities such as recruitment, training, performance evaluation, promotion, compensation and training [1] .
However, the organization of production in projects is a style of work continuously used today for various spheres of society (construction, information technology, health, etc.). Human resources and decisions involving their management are two of the key factors that influence the success of projects [2] [3] . On the stage of project development, a key variable is time; in contracts with clients, scheduled tasks are signed and the team must accomplish them. It is therefore necessary to support important activities such as labor competences assessment, to be performed with agility and ease by team members and project managers [4] [5] .
Competence assessment, as a part of the performance evaluation involves a comparison between the competences demonstrated by the individual in his work and competences required for successful performance in the position he occupies Thus, in this context, these proven competences are precisely the evidence possessed by the individual who endorse their job performance over a period of time, and are stored in different ways so that they can serve as input to the process of competences assessment [1] [6] .
In the literature on this subject, there are different techniques for the evaluation of labor competences. In Table 1, you can see a classification of these techniques, taking as a criterion the type of information on which to focus. The selection of each depends on the capabilities of the organization and its goals.
From the techniques that are based on practical experience, scales systems are favored, because they do not propose an absolute evaluation of yes or no, but offer a range of possible levels to achieve. Instruments based on critical incidents are also presented as a wise option, because they store and assess the events that occurred during a period of time. Practical exercises and simulation techniques have the disadvantage that this research wants to avoid, that is interruptions in productive activities of the organization.
When the evaluation is carried out in organizations where the role of evaluators is played by the members of the organization, interpersonal relations between workers and those in charge of evaluating may determine the assessment made. It is possible to mitigate this problem is possible when efforts are made to systematize the evaluation processes and establish procedures that include the collection of data and evidence on which any value judgment are supported [1] [5] .
In this sense, the evaluator must analyze each individual evidence to identify which is related to competences that the human resource should have based on his role. Then, it must define the weight that such evidence has in one or more competences. Then the evaluator should make an analysis of these elements, and emit an assessment [6] [7] .
The use of time and effort assessors in this task, ―greater than planned―is another of the problems that occur. The analysis of the evidence is strongly characterized by a cumbersome identification of the relationship between the evidence and the competences, and the allocation of a certain weight, because of the large number of evidences [8] .
The aim of this paper is to propose two alternative algorithms to recover the evidences of performance of human resources by identifying their relationship with labor competences, using rough sets and text distances. The purpose of these algorithms is to improve the efficiency of competences assessment process.
Next, the organization of this work is described. Section two shows a brief analysis of rough sets associated concepts. In the third section two algorithms are introduced to recover information about tasks assigned to project members. First algorithm applies rough sets theory to discover the relationships whereas second algorithm applies distance between texts. Section four compares different algorithms to evaluate human resource competences. Algorithm 1, Algorithm 2, Numerical Scale Method and 360 Grade Method [4] are compared. Finally the conclusions of the investigation are presented.
![]()
Table 1. Techniques for the evaluation of labor competencies [1] .
2. Brief Analysis of Rough Sets Concepts
There are different forms to solve problems with uncertainty, authors as Lotfi A. Zadeh, Yager and others propose different strategies to understand and solve these problems. Some strategies are based on treat the uncertainty by considering the origin of data whereas others strategies focus in data inconsistent [9] . In 1982 professor Zdzislaw Pawlak published a paper [10] introducing the new concepts lower approximation and higher approximation creating a new theory called rough sets (RST). The Pawlak’s theory introduces a new method with applications in feature selection, in outliers detection, data selection and many others situations. About rough sets, Lotfi A. Zadeh, in [11] , explain that rough sets theory is a strong methodology to solve many problems with uncertainty. To understand the Pawlak’s theory it’s necessary to introduce some concepts:
Information system (S): is a system that organizes data about a specific topic. In these systems, information is usually represented by table where each row is an object and each column is an attribute.
Frequently, A denotes a set of attributes that represents the objects information.
Decision System (DS): is any information system with decision attribute for each object, which means that takes decision in specific object.
Let’s see the following resume:
・ We have a pair DS = (U, A U {d}, where d Ì A).
・ U is a non-empty and finite set of objects called the universe.
・ A is a non-empty and finite set of conditional attributes.
・ d is a decision attribute.
・ Let A ∩ {d} = Φ.
Lower and upper approximations were introduced from the inseparability relation, which is the equivalent relation.
Given an information system S = (U, A È {d}), let X Í U be a set of objects and B Í A, an selected set of attributes, B define the equivalent relation and the subset X Í U. From the information contained in B, X can be approximate like following:
The lower approximation of X with respect to B is:
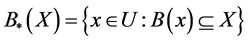 (1)
(1)
The upper approximation of X with respect to B is:
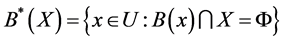 (2)
(2)
The boundary region we can define as:
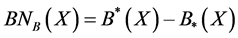 (3)
(3)
Indiscernibility relation: Let S = (U, A U {d}) be an information system, every subset B of A defines an equivalence relation INDB, [10] called an indiscernibility relation, and this relation is denoted by:
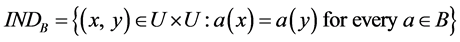 (4)
(4)
The positive region of decision d with respect to B is:
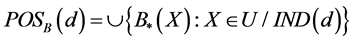 (5)
(5)
The negative region of decision d with respect to B is:
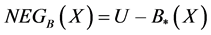 (6)
(6)
Another useful concept is grade k dependence that we explain in next paragraph.
Intuitively, a set of decision attributes D, depends totally on a set of attributes B, denoted by B Þ D, if all the values of the D attributes are univocally determined by the values of the attribute in B.
In other words, D depends totally on B, if there is a functional dependency between the values of D and B [10] . The following definition explains the concept of dependency in k grade between the sets of attributes B and D.
D depends on B in a k grade (0 ≤ k ≤ 1), denoted by B Þk D, by the k value, and defined by the expression 5. If k = 1 then D depends totally on B, while if k < 1 then D depends partially on B.
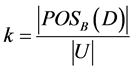 (7)
(7)
Rough sets theory defines different metrics to evaluate the consistency of information and the quality of rough sets classification.
・ The precision of the approximation of a set of objects X, is defined as (8):
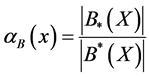 (8)
(8)
・ The quality of the approximation of a set of objects X, which represents the relative frequency of objects that belong to class X and are correctly classify.
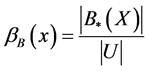 (9)
(9)
・ The consistency of the decision system, one system is inconsistent when at least exist two objects indiscernible that belongs to different classes simultaneously; see the equation (10). Values near 1 represents high consistence.
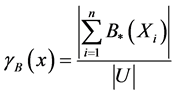 (10)
(10)
In problems where domain attributes B is not discrete, inseparability relation cannot be applied. The equivalence relation is very strict for continuous domain cases. The Pawlak’s model does not consider any tolerance of errors. The positive region is those equivalence classes which completely belong to a finite set; the negative region is the union of those equivalence classes which don’t completely belong to a finite set. In order to solve this situation, RST methods usually apply two alternatives: to discreet the data or to use an extension theory [9] [12] . In the first case, the original information system was transformed in another where the RST classic is applied. In the second case, the RST classic is extended where object are not inseparability but they can stay in a same class if they are similarities [13] - [17] .
Then, the development of rough sets, extensions and generalizations has continued evolving. Initial developments focused on the relationship with fuzzy sets. While some works contending these concepts are different, other works consider that rough sets are a generalization of fuzzy sets. Pawlak considered that fuzzy and rough sets should be treated as being complementary to each other, addressing different aspects of uncertainty and vagueness [12] . Three notable extensions of classical rough sets are: dominance-based rough set approach (DRSA) which is an extension of rough set theory for multi-criteria decision analysis (MCDA), decision-theoretic rough sets (DTRS) which is a probabilistic extension of rough set theory, and game-theoretic rough sets (GTRS) that is a game theory-based extension of rough set.
Authors by considering the alternatives explained before, usually introduce a data preparation’s methods that deal with attributes data types [9] :
1) Analysis of numeric data and not numeric data by separate, then take decision according to obtained partial results;
2) To discreet numeric data;
3) To codify not numerical data;
4) Work with merged data description.
In this paper, we apply concepts of RST extended theory and we work with merged data, qualitative and quantitative, provided by projects data based.
3. Two Methods for Human Resource Competence Evaluation
In this section, two algorithms to evaluate human resource competences are introduced. As a necessary condition to apply these algorithms, should exists a project management information system which contains information about tasks assigned to each project member.
The proposed algorithms recover information about tasks assigned to project members, afterwards they discover relationship between tasks and each human resource’s competence and finally estimate the competence level associated to each person. First algorithm applies rough sets theory to discover the relationships whereas second algorithm applies distance between texts. Finally two algorithms use a case base reasoning method to evaluate the competences of each human resource.
3.1. Algorithm 1 Based on Rough Sets for Human Resource Competence Evaluation
In order to estimate the competence level for each project member we propose the following steps:
Step 1. Define the human resource competences required by a specific project.
Step 2. Recover all tasks assigned to each project member from project management information system.
Step 3. Apply algorithm based on rough sets to discover the relationships between tasks and competences.
Step 4. For each competence and each human resource, calculate the human resource performance indicators by considering the associated tasks previously discovered. Some indicators are based on rough sets theory.
Step 5. Classify the competence level by using a case base reasoning system.
Step 1 bisection:
In this step we should define the competences required by project, an example of these competences are the following:
・ Documenting of requirements, using the language and templates defined between the client and the development team.
・ Managing the server database ensuring consistency, availability and security of hosted databases in it.
Step 2 bisection:
For each project member, the algorithm executes a sql query and recovers all tasks associated to him.
Step 3 bisection:
In this step we need to the following actions:
1) To define the indiscernibility relation between objectswith Equation (11).
2) To discover lower approximation by using Equation (1), represents set of tasks associated to each competence clearly.
3) To calculate positive region by Equation (5). We combine with concept “grade k dependence” to evaluate the consistence of a group of tasks.
4) POSB represents all consistent elements, like we said before. The k dependency grade in Equation (7) permits to evaluate the quality of the universe’s elements. High level of k represents sets which tasks keep a strong relationship with competence.
5) To discover boundary region by Equation (3), contains inconsistence tasks. Some of these tasks represent the uncertainty and the weak relationships between tasks and competences. These tasks will not be considered during the competence evaluation step.
Previously in section 2 we showed that rough sets theory introduce the indiscernibility relation concept in order to identify similar objects, in this sense, one equivalence relation was established in Equation (4). But in our case, information of each task contains non discreet attributes. For example each task is representing by the following fields:
・ Field “name” as text type.
・ Field “description” as text type.
・ Field “start date” as date type.
・ Field “end date” as date type.
・ Field “priority” as integer type.
・ Field “type task” as text type that can be discreet.
・ Field “assigned to” as text type representing one project member.
・ Field “spi” as float type representing the performance on task execution.
・ Field “evaluation” as text type representing the qualitative evaluation of task’s quality.
・ Field “estimated time” as integer type representing the amount of hours estimated to do the task.
・ Field “dedicated time” as integer type representing the amount of hours dedicated by human during tasks execution.
In this case the equivalence relation is very strict. For this reason, in this case we introduce a similarity function Equation (8) by considering just the following fields:
・ x1 field “name” as text type.
・ x2 field “description” as text type.
・ x3 field “priority” as integer type.
・ x4 field “type task” as text type that can be discreet.
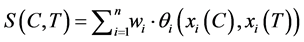 (11)
(11)
where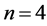 ,
,  , C is competence, T is task and S is indiscernibility
, C is competence, T is task and S is indiscernibility
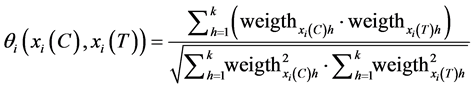 (12)
(12)
![]() (13)
(13)
![]() (14)
(14)
![]() (15)
(15)
![]() (16)
(16)
Equation (12) should be applied for fields x1 and x2, based on cosine text distance, where k represent the amount of terms including in each text.
Step 4 bisection:
We introduce different indicators in order to evaluate efficiency and the efficacy of project members during the task execution [4] . The efficacy deal with the quality of task execution and efficiency evaluate the task execution process respect to the time and the resources used.
1)![]() (17)
(17)
2)![]() (18)
(18)
3)![]() (19)
(19)
4) ![]()
5) ![]()
In equations all indicators RHj means the j project member.
Step 5 bisection:
We use a Case base reasoning system to classify in different levels each competence by considering the indicators calculated before [18] - [20] .
・ Knowledge base was built by the experts with indicators and competence evaluations.
・ We use the similarity function in Equation (20).
![]() (20)
(20)
![]() (21)
(21)
・ The adaptation method was the Majority rule.
3.2. Algorithm 2 Based on Text Distance for Competence Evaluation
In order to estimate the competence level for each project member we propose the following steps:
Step 1. Define the human resource competences required by a specific project, same as before algorithm.
Step 2. Recover all tasks assigned to each project member from project management information system, same as previous algorithm.
Step 3. Select tasks associated to each competence by using the cosine distance between texts.
Step 4. For each competence and each human resource, calculate the indicators just like previous algorithm but the two last indicators are different.
Step 5. Classify the competence level by using a case base reasoning system.
Steps 1, 2 and 5 are similar to the algorithm explained in section 3.1 for this reason its bisection is not explained.
Step 3 bisection:
In this step we use the cosine distance between texts to calculate the similarity between each task with each competence. See Equation (12)-(14) we compare the task name with the competence name. We define a threshold to determine the relationship between tasks and competences.
Step 4 bisection:
In this step, we use the same indicators than in rough sets algorithm except by consistency of decision system indicator.
![]() (22)
(22)
In the Equation (22), cosine is the coefficient often used to determine the similarity between documents and it is based on the cosine of the angle between them [21] .
4. Comparisons between Different Algorithms to Evaluate Human Resource Competences
In this section, we shall compare different algorithms to evaluate human resource competences. We compare algorithm 1, algorithm 2, numerical scale method and 360 grade method [4] .
We compare the algorithms by considering two criteria: first criterion related with efficiency (time and resources used) and second criterion associated to efficacy (quality of classification results). The efficacy of algorithms is compared considering the human experts classification.
4.1. Comparisons Considering Efficiency between Four Algorithms
Table 2 presents experiment results of comparing the algorithms 360 grade, numerical scale, algorithm 1 based on rough sets and algorithm 2 based on cosine distance. We apply four algorithms in Software Production Centers of the University of Information Sciences in Havana; specifically we evaluate the human resources of Center of Consulting and Enterprise Architectures [4] [22] .
![]()
Table 2. Experimental results in efficiency comparisons between 360 grades algorithm, numerical scale, algorithm 1 and algorithm 2.
![]()
Table 3. Experimental results in efficacy variable and comparisons of algorithm 1 and algorithm 2.
Table 2 shows that, although method numerical scale needs less personal than the rest of algorithms, it requires more time than proposed algorithms 1 and 2 proposed in this paper. The 360 degrees method maintains constant the number of evaluators, but always requires a significant amount of experts to evaluate the human resources. This characteristic increases the global evaluation time.
Algorithms 1 and 2 proposed in this paper always require evaluators in the initial moment in order to create the knowledge database. Afterwards only one person can evaluate to all project members. The number of tasks, to be evaluated, does not affect significantly the algorithms 1 and 2 performance.
4.2. Algorithms Comparisons by Considering Efficacy in Competence Evaluation
We compare the correctness percentages of classification among algorithm 1 (based on rough sets + CBR), algorithm 2 (based on cosine distance + CBR). We selected 494 cases of competence evaluations. Each case corresponds to a project member with all his competences previously evaluated by experts considering the five indicators defined in section 3.1. An experiment database with all selected cases is created.
A random cross-validation technique is applied; also 20 partitions from experiment database are created: 70% of cases were used for train and the rest for testing. Afterwards we apply the following statistical test:
1) Shapiro-Wilkstatistical test to check normal distribution of data. We probe that data have not a normal distribution.
2) To compare the two algorithms the Wilcoxon test is used; we used the Monte-Carlo method for computing the significance level and considered 99% as confidence interval.
We find significant differences between the two algorithms results, as shown in Table 3.
As a conclusion of the above tables: the algorithm based on Rough Sets + CBR got better results, the algorithm error is small for the case and the benefits associated to efficiency are satisfactory.
5. Conclusions
It is shown that the proposed algorithms, compared to methods like 360 degrees and Numerical Scales, offer greater efficiency, reducing the number of people involved and the time required to perform the process.
The proposed algorithms facilitate the automation of the process of labor competences evaluation through the identification of the relation of the evidences of the production process and labor competences, avoiding the use of invasive techniques for estimating the performance.
The algorithm based on Rough Sets + CBR got better results. The algorithm error is small for the case and the benefits associated to efficiency are satisfactory.