Oil-Price Forecasting Based on Various Univariate Time-Series Models ()
Received 31 March 2016; accepted 15 May 2016; published 18 May 2016

1. Introduction
Forecasting is the process of developing hypotheses about future events [1] , and forecasting models that predict future events are used in numerous fields such as economics and science because they are useful tools in decision making. A perfect forecast provides insight into the implications of an action or inaction and serves as a metric to judge one’s ability to influence future events [2] [3] . The task of forecasting or modelling has conventionally been performed either by developing a model or by implementing techniques developed to assess time series [4] . Different models have been applied to forecast data over particular periods [5] [6] .
Reliable estimates are required to judge the accuracy of a forecast. Therefore, assessing the quality of a model in terms of historical data is unacceptable. In contrast, the precision of a forecast should be analysed in terms of how the model handles new data that were not previously used to determine the quality of the model [7] . Researchers also compare the accuracies of forecasts to evaluate particular aspects of competing economic hypotheses [8] . The best metric to judge a model is determined by eliminating the fitting errors involved with classical data forecasting. Indistinguishable linked-predictive let-downs suggest the inadequacy of a model. Therefore, a good forecasting model should result in the fewest fitting errors while maximizing accuracy.
Two types of time-series-based forecasting models exist: univariate and multivariate. Univariate forecasting involves using historical data to predict the value of a continuous variable that serves as the response or output variable [9] . Because it supplies a quantitative statistical evaluation, univariate analysis requires separate analysis of the results for each relevant variable in a given set of data [10] . Moreover, univariate analysis does not consider possible relationships between independent variables [11] . According to [12] , a univariate time series can provide a more accurate forecast than a multivariate model. The exponential smoothing (ES), Holt-Winters (HW) and autoregressive intergrade moving average (ARIMA) techniques are some of the methods that use univariate time series.
The last two decades have seen significant developments in ES, which has become one of the most noteworthy forecasting strategies. ES was established as a classical method of analysis for forecasting different econometric and financial real-time data prospects [13] . The results obtained from data smoothing are operative, simple, accurate and easy to communicate and understand [14] . [15] posited that the resulting forecasts are comparable to those of more complex models. This success is attributable to the clarity, computational effectiveness, flexibility to changes in the forecast procedures and rational precision of ES [16] . The basic notion of ES is to “level” the proceeding series in the same manner as does the moving typical value, because ES uses the smoothed series to forecast the value of interest. Conversely, ES is considered to be less sensitive to infrequent occurrences, such as ramp shifts, level shifts, impulses and changes in related probability functions [17] .
The HW approach, which is a variant of ES, is a method commonly used to forecast recurring time series [18] . Thus, various analytical methods continue to be used to make predictions to highlight specific changes and seasonal patterns and to explore their specific applicability. [19] suggested that ES provides dependable forecasts that are fairly close to the predictions obtained from more sophisticated, costly procedures. HW models are sensitive to irregular events and/or outliers. Forecasting methods are affected by outliers in two ways: smoothed values are influenced by the fact that the equations express the present and previous values of a series involving outliers, and the outliers affect the selection of constraints [20] .
The ARIMA approach, also known as the Box?Jenkins method, has been one of the most widely applied linear frameworks in time-series forecasting over the past three decades [21] . The popularity of ARIMA arose from its analytical ability, which is valuable in the process of model building, and the quality of its forecasts [22] . The ARIMA forecasting model differs from other approaches in that it assumes no particular forecasting pattern based on historical data [23] . The ARIMA model is used to forecast a value with respect to a time series in the form of a linear combination of previous values and their associated errors (otherwise referred to as shocks or innovations) [24] . Furthermore, various ES models can be used with ARIMA models [25] , which imply that the attributes of an ES model can be incorporated into an ARIMA model because of the simplified nature of the former.
Conversely, studies by [26] and [27] demonstrated that ARIMA models can provide better forecasts than ES models. In contrast, [28] identified the ES model as a better approach because it provides plausible predictions, in contrast with ARIMA models. In another contribution to this debate, [29] and [30] determined that the ARIMA methodology performs fairly well compared to the HW model, although the latter yields higher-quality forecasts. To counter these results, [31] demonstrated that the ARIMA model provides better results than the HW model. Furthermore, [32] and [33] showed that HW provides higher-quality forecasts than ES. The ranking of these three models is based on their applicabilities and the accuracies of their forecasts.
This study focuses on the major tools of decision making; namely, time-series-based models. We present analyses of the accuracies of the ES, HW and ARIMA approaches in forecasting crude oil prices for the first time and also discuss the significances of the error terms in these forecasting models and the importance of achieving minimal errors. The remainder of the paper is organized as follows: Section 2 describes the data source, methodology and means of quantifying forecasting accuracy. The results from real data sets and a discussion are presented in Section 3. Finally, Section 4 gives our concluding remarks.
2. Materials and Methods
West Texas Intermediate (WTI) oil prices from October 2011 and March 2016 served as the central time series used in this study. This time series was chosen because the fluctuating nature of the data endows it with extreme nonlinearity, which means that chaos might pose challenges in forecasting future prices. The datasets consisted of daily data collected from the official websites of the United States Energy Information Administration (EIA). WTI was also chosen because of its geographical location and cost of transport; these are the major factors influencing the oil market at the local and international levels [34] . In addition, crude oil prices have challenged the forecasting abilities of previous models. In the present study, we focused on an in-sample period, which means that the time series between October 2011 and September 2015 served to generate the forecasts of the three models, whereas the time series between October 2015 and March 2016 served as out-of-sample data against which the accuracies of the forecasts were measured.
The in-sample series contributed approximately 90% of the data, whereas the out-of-sample series contributed approximately 10% (this division was arbitrary). The accuracies of the oil-price forecasts of the three models were determined and interrelated based on six metrics. The next section presents both the respective models both mathematically and theoretically, as well as the mathematical expressions and applications of the six metrics to quantify the forecast accuracies.
2.1. Exponential Smoothing Model
ES is a formalization of the familiar learning method, which is a practical basis for forecasting. Typically, the use of ES is significant in cases in which the data pattern is nearly horizontal, particularly when no particular trend or seasonal variation exists in previous data sets. The ES framework for time series 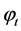 is given by
is given by
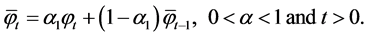
For ES, the h-step-ahead forecast equation for time series 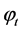 is
is
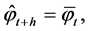
where 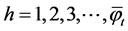 is the forecast based on period t, and
is the forecast based on period t, and 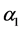 is the smoothing parameter.
is the smoothing parameter.
2.2. Holt-Winters Model
The HW model is equally important in its own distinct ways. This model is an extension of the ES framework, but it employs a different set of parameters, unlike those used in rudimentary time series, to smooth the inclination of values. HW-based forecasting can be performed by using three smoothing elements. The HW model is applied to data characterized by seasonality and trend. Its equations are
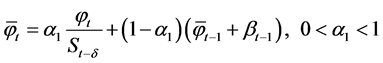 ,
,
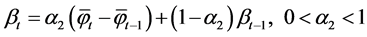 ,
,
and
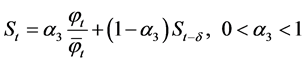 .
.
In the HW model, an h-step-ahead forecast of 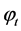 is given by
is given by
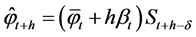 ,
,
where 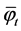 is the smoothed value for period t,
is the smoothed value for period t, 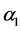 is the smoothing parameter,
is the smoothing parameter, 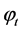 is the actual value at period t,
is the actual value at period t, 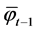 is the average experience of the series of smoothed values in period
is the average experience of the series of smoothed values in period![]() ,
, ![]() and
and ![]() are the trend estimates,
are the trend estimates, ![]() is the smoothing parameter for the trend estimate,
is the smoothing parameter for the trend estimate, ![]() is the seasonality estimate,
is the seasonality estimate, ![]() is the smoothing parameter for the seasonality estimate, h is the number of periods in the forecast lead period and
is the smoothing parameter for the seasonality estimate, h is the number of periods in the forecast lead period and ![]() is the number of periods in the seasonal cycle.
is the number of periods in the seasonal cycle.
2.3. Autoregressive Intergrade Moving Average Model
The ARIMA model involves a series transformation to a state of stationary covariance, followed by identification, approximation, diagnosis and prediction. The “I” in ARIMA implies that the dataset undergoes differentiation and that, upon completion of the modelling, the results undergo an integration process to produce final predictions and estimates [35] . The function representing the ARIMA model is denoted ARIMA (p, d, q), which produces a stationary function ARMA (p, q) upon differentiation with respect to time. The origin of the ARMA model is the autoregressive AR model of order p; MA, the moving average framework of order q; and the expressions for MA, AR and ARMA are
AR model:![]() ,
,
MA model:![]() ,
,
and
ARMA model:![]() ,
,
where ![]() is the autoregression parameter at time t,
is the autoregression parameter at time t, ![]() is the error term at time t and
is the error term at time t and ![]() is the moving-average parameter at time t.
is the moving-average parameter at time t.
2.4. Model-Selection Criteria
Although one model can occasionally be suitable for any set of data, the correctness of a forecasting model requires that various models be evaluated to identify the one that provides the best results with minimal errors [36] [37] . Different methods of computing, quantifying and reducing errors exist [38] . Determining metrics to correct forecasting errors is often a major problem, given that no single metric can provide a clear-cut indication of forecast performance, and the application of multiple metrics complicates the comparison of forecasting models and makes them unmanageable [39] . Thus, we applied six model-selection criteria (i.e. metrics) and chose the appropriate time series to which to apply the ES, HW and ARIMA models. From the wide range of applicable model-selection criteria that exists, the following criteria were deemed suitable: mean squared error (MSE), root-mean-square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE) and Theil’s U-statistic. Both of Theil’s U-statistics were applied and were defined as U1 and U2. These criteria exhibited particular advantages and disadvantages, as well as specific conditions of applicability. Table 1 illustrates how each criterion is calculated.
The first assessment criterion, MSE, is the mean value of the squared error of the overall forecasts. MSE assigns more weight to significant errors. The major limitation of this approach is that it overstates substantial er-
Note:![]() , where
, where ![]() is the actual value at time i,
is the actual value at time i, ![]() is the forecast value at time i and n is the number of observation used in the calculation.
is the forecast value at time i and n is the number of observation used in the calculation.
rors. This evaluation criterion also provides limited information regarding whether the framework is an overestimation or underestimation of the actual forecast value. RMSE is the second evaluation criterion. It preserves the units of the estimation variable. This approach is more sensitive and minimizes large errors. Nevertheless, the ability to compare different time series is limited with this criterion. Conversely, MAE, the third fourth criterion, determines the error magnitude for a precise set of forecasts. MAE defines how close forecasts are to the actual outcomes. This metric does not consider the direction of the forecasts. Moreover, these criteria determine the precisions of continuous variables. MAPE, the fourth criterion, enables comparison of distinct time-series data without defining the relation or percent error. This metric is significant in instances in which the measured variables are very large.
The fifth and sixth criteria are U1 and U2, respectively. The former enables different predictions to be compared, which implies that actual values are compared with predicted values. U1 provides a range of values on a zero-to-one scale. The nearer U1 is to zero, the more accurate the prediction is. When faced with alternative predictions, the forecast with the smallest value of U1 is regarded as the best and is thus selected. Conversely, U2 performs relative comparisons based on random walk models and prediction models (naïve model). The naïve model may be described as the actual predetermined forecast model applied based on an indiscriminate-walk process. When U2 levels off at unity, the naïve method is considered to be equally useful for forecasting. U2 < 1 indicates that the forecasting model would work better than the naïve approach. Note that U1 and U2 are more difficult metrics to use than the MAPE metric.
3. Results and Discussion
We implemented the ES, HW and ARIMA models in MATLAB (R2014a), which is a powerful mathematical software package used internationally by engineers and scientists. MATLAB contains built-in functions that allow the user to determine model parameters spontaneously; the only requirement in this system is the time series to be analysed. The quality of the parameter set used in this approach is defined by whether it lead to minimal errors between the forecast and actual values. To determine the quality of the parameter set used in this work, we compared the forecast values obtained from the three above-mentioned models with the actual WTI crude oil prices from October 2015 and March 2016. The results of this exercise that were obtained using the ES, HW and ARIMA methods are shown in Figures 1-3, respectively. These three figures show the forecast trends with a confidence interval of 95% and the actual data. The results of the different models are consistent regardless of which of the six different metrics is used to quantify their performances.
The ES model uses a single parameter![]() . The appropriate value for this parameter is determined by minimizing the error with respect to
. The appropriate value for this parameter is determined by minimizing the error with respect to![]() . The results indicate that
. The results indicate that ![]() is the best parameter value for this forecasting model. The equation for this model thus takes the form
is the best parameter value for this forecasting model. The equation for this model thus takes the form![]() .
.
Figure 1 clearly exemplifies the accuracy of the ES forecasting model. Note that the forecast (red dashed line) is consistently above the actual value (blue solid line). Given that the lower edge of the 95% confidence interval for two-thirds of the forecast results hovers around the actual values, it can be concluded that the results of the ES model do not satisfactorily predict the actual data.
Compared with the ES model forecasts, those of the HW model are relatively accurate. The performance of the HW model relies heavily on the choice of parameters, as shown in Figure 2. The parameter values used to produce Figure 2 were ![]() and
and![]() .
.
The forecast presented in Figure 2 is better than that of the ES model: the forecast prices fluctuate close to the actual prices. The actual prices also consistently fall well within the 95% confidence interval of the forecast from the time-series data. These results demonstrate that the HW model provides more accurate predictions than the sophisticated ES model. As a result, the following equations constituted the HW for forecasting WTI prices:
![]() ,
,
![]() ,
,
and
![]() .
.
![]()
Figure 1. Results of ES model for predicting daily WTI oil prices.
![]()
Figure 2. Results of HW model for predicting daily WTI oil prices.
The ARIMA model consists of four steps: The first step is model selection, wherein the parameters p and q are selected by using the prediction-accuracy method of minimizing the error upon recognition of a variable’s fixed degree. The second step involves estimating the model and its viability. Finally, the chosen and estimated frameworks are replicated forward to obtain the forecast values for the variables in question. We found that ARIMA (2, 1, 2) was the best-fitting model with respect to the WTI data.
Note, however, that ARIMA is a fairly sophisticated model for accurate forecasting. Figure 3 from the observation, together with the forecasts, show that the ARIMA (2, 1, 2) results fit the actual time-series data considerably better than do those of the previous two models. The ARIMA model selects the parameters using a significance level 5%. As a result, the parameters found to be significant are AR (1), AR (2), MA (1) and MA (2) (see Table 2).
The ARIMA (2, 1, 2) model equation can be written as
![]()
Analysis of Forecast-Model Selection
The preceding section outlined three time-series models that were used to generate forecasts for crude oil prices. Every prediction was compared with the actual value of the respective time series of crude oil prices. The accuracy of each forecast was evaluated by using six metrics, as discussed in the preceding section. Each approach was applied to determine and rank the performances of the models for the given time series. Table 3
![]()
Figure 3. Results of ARIMA model for predicting daily WTI oil prices.
![]()
Table 2. Estimate of ARIMA (2, 1, 2).
Note: *p value < 0.05.
![]()
Table 3. Criteria for selecting the best of the three models used in this study (ES, HW, ARIMA).
Note: *significance < 1.
summarizes the three models and their forecasting performances. The results demonstrate that the ARIMA model performs better than either of the other models for the given time series. Note, however, that although the HW model exhibits the second best forecast after that of the ARIMA model, the performance of each model relies on the data used. In addition, specific ES models perform inadequately and thus provide poor forecasts, in contrast to the HW and ARIMA models.
Despite all three models being black boxes, the differences between their performances are related to the differences between the methods of determining forecasts in the ES and HW models and in the ARIMA model. The forecasting method in the ES and HW models relies on a weighted average of the past observed values in which the weights decline exponentially, which basically implies that the data for more recent observations contribute significantly more than do previous data. The ARIMA model, however, has three parts: autoregression, integration and moving average, with the future value of a variable being a linear combination of the past values and the associated errors.
Forecasting plays a vital role in the entire process of advising policy makers. Perfect decision making is achieved when changes are viewed from two perspectives: current events and what is likely to occur in the future. However, uncertain a forecast might seem, policy makers are compelled to consider its validity in their decision making. Ideally, policy makers would base their decisions on accurate forecasts to tighten their policies and to achieve ultimate outcomes that differ from those forecasted. In addition, marketing strategists use information acquired from various forecasting models and consider the most accurate models for developing, formulating and implementing marketing strategies. Therefore, the organisations and entities whose main activities rely on the oil industry find such forecasts especially useful for formulating their policies and marketing strategies to adapt to future changes forecasted by the models. With accurate forecasts, entities affiliated with oil production can use the information to make prudent decisions regarding the prices they attach to oil. As a result, with accurate knowledge of the flow of public money and of the regular patterns in oil consumption and demand, they can modify oil prices in such a way as to avoid damaging the financial capability or otherwise affecting their organizations’ objectives.
4. Conclusion
This paper explored the natures of statistical predictors by presenting time series analyses for oil prices data. Three types of univariate time-series models were investigated: ES, HW and ARIMA. We determined the qualities of their forecasts by comparing the results of the given models with actual data. The ARIMA (2, 1, 2) model provided forecasts that were more accurate than those of the ES or HW models. The six selection criteria used to quantify the qualities of the forecasts yielded their smallest values for the ARIMA forecast, indicating clearly that it is the best of the three methods. As a result, we were able to not only conclude that the ARIMA model provided the most accurate forecasts but also discuss the sophistication and robustness of the competing models in crude oil market. Ultimately, the best decision-making process will be the most effective. Predicting future events based on an appropriate time-series model will help policy makers and marketing strategists make decisions and devise suitable strategic plans in oil industry. To extend this work, future research should examine and compare complex univariate models, such as the autoregressive conditional heteroscedasticity model (ARCH), the generalized ARCH model (GARCH) and the ARIMA/GARCH model.