An Intonation Speech Synthesis Model for Indonesian Using Pitch Pattern and Phrase Identification ()
1. Introduction
Modeling emotions in speech synthesis are made based on a number of parameters such as place, the level of the fundamental frequency , voice quality, articulation or accuracy. A different speech synthesis technique aimed for parameters in the different levels Schroder 2001. Formant synthesis, also known as the rule-based synthesis, creates the sound of speech based on the rules alone. No people’s voice recording is involved in it. The result is a speech sound like a robot voice.
, voice quality, articulation or accuracy. A different speech synthesis technique aimed for parameters in the different levels Schroder 2001. Formant synthesis, also known as the rule-based synthesis, creates the sound of speech based on the rules alone. No people’s voice recording is involved in it. The result is a speech sound like a robot voice.
In the concatenation synthesis, voice recording from speaker strung together to produce synthetic speech. In this process, diphone which cuts the signal in mid phoneme until next mid phoneme is often used. Diphone is recorded with a monotonous tone. At the synthesis, required contour  is constructed with signal processing techniques that result in a slight distortion. But the final result is more natural than formant synthesis [1] . In most diphone synthesis systems, only
is constructed with signal processing techniques that result in a slight distortion. But the final result is more natural than formant synthesis [1] . In most diphone synthesis systems, only 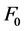 and duration can be controlled, while intensity for each segment is not easy to control.
and duration can be controlled, while intensity for each segment is not easy to control.
Emotions of speaker such as neutral, joy, boredom, anger, sadness, fear, and indignation are reflected in the duration and intonation of speech from a person [2] . By copying pitch and duration of the original utterances to a monotonous one, it can be proved that both factors are sufficient to express various emotions. Research results show that emotion can be expressed simply by manipulating pitch and duration. Intonation is a set of syntactic prosody inherent in the utterance sentence [2] . The intensity of sound is not manipulated.
Contour tones containing duration and pitch are calculated by converting an intonation plan into a sequence of prosodic tone and highly dependent on the model of the speaker [3] . Contour patterns derived from the speaker’s voice are applied at the time of speech synthesis.
Research on Indonesian speech synthesis which makes the coupling phoneme based speech synthesis has been done [4] . In general, the results can pronounce words in Indonesian quite fluently and can be understood by most listeners. However, speech synthesis has not produced intonation patterns (prosody) as the original speech [4] . Still there are some inaccuracies in the assembly of phonemes [4] .
In Indonesian, utterance position on word stress does not depend on the number of syllables, but the stress falls on the penultimate syllable [5] . Prosodic type is characterized by  and intensity. The pressure of nouns group on preverb position will be marked by the duration instead of the frequency. In this group, two peaks of
and intensity. The pressure of nouns group on preverb position will be marked by the duration instead of the frequency. In this group, two peaks of 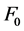 are found.
are found.
2. Speech Synthesis Model Using Pitch Pattern and Phrase Identification
Speech synthesis is built to converts the input text into speech. Conversion of text into speech considering a sentence structure, intonation patterns, as well as a normalization. The results are in the form of text that qualifies as input of voice generator.
Prosodic rules which determine the frequency, duration, and intonation was compiled from the results of studying materials about intonation in Indonesian [6] . This rule is encoded to ease the implementation later. Speech synthesis parameters are grouped into four categories, namely pitch, duration, quality and articulation. The pitch parameter determines the value of  [7] . The duration parameter determines the duration of rhythm control and rate of speech. Usually the pitch and duration parameters are associated with the phenomenon of linguistic (words or phrases) [3] [8] . The sound quality of speech is a parameter that determines the overall sound quality. The articulation parameter determines clearance of speech. Based on these parameters the model of speech synthesis is composed and shown in Figure 1.
[7] . The duration parameter determines the duration of rhythm control and rate of speech. Usually the pitch and duration parameters are associated with the phenomenon of linguistic (words or phrases) [3] [8] . The sound quality of speech is a parameter that determines the overall sound quality. The articulation parameter determines clearance of speech. Based on these parameters the model of speech synthesis is composed and shown in Figure 1.
The text comes from standard input or the file is read by the text normalization module in order to obtain text which is free of numbers and signs so that the whole text can be pronounced. The output of a normalization module text-norm will be used by the selector pattern, syntax analyst, and synthesis module. The selector pattern module will produce a pattern based on text-norm and an existing pattern database. This module is responsible for the pitch of each phoneme. Syntax analyst module will generate sentence syntax structure of the text-norm with the phrases and words interval duration information.
The synthesis module combined text-norm from normalization module, phonemes with prosody information in it based on the pattern from pattern selector, and attributes of sentence structure from syntax analysts into phonemes and prosody form. This module is responsible for the articulation and the quality of speech. Finally, this form will be voiced by DSP module.
2.1. Normalization Module
The text is a phrase that came from the standard input or files that may be contains numbers or punctuation

Figure 1. The proposed model of speech synthesis.
marks that can be pronounced. If there are numbers then this module will convert it into text. For example, in the text there is a number “12345” then it will be converted to “dua belas ribu tiga ratus empat puluh lima”. Similarly, if there is an abbreviation, like “UGM” then it will be changed to “u-ge-em”. Symbols need to be changed too, e.g. “ ”, “
”, “ ”, or “
”, or “ ”.
”.
2.2. Fundamental Frequency Pattern Module
Intonation patterns in the form of pairs of time 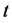 and fundamental frequency
and fundamental frequency  obtained by extraction
obtained by extraction  of radio announcer voice. Based on the previously defined parameters the intonation pattern chose from a set of intonation patterns. The selection is done by paying attention on the pattern duration and length of the text. The duration of the speech text can be calculated to about sum of the duration of all phonemes. Results of pattern selector are
of radio announcer voice. Based on the previously defined parameters the intonation pattern chose from a set of intonation patterns. The selection is done by paying attention on the pattern duration and length of the text. The duration of the speech text can be calculated to about sum of the duration of all phonemes. Results of pattern selector are  for time from 0 to
for time from 0 to . The pattern have been adapted to the text by interpolation method.
. The pattern have been adapted to the text by interpolation method.
2.3. Syntactic Module
This module perform the text-parsing norm based standard grammatical structures. An important outcome of this module is the determination of the duration of phonemes and duration of pauses between phrases or between words.
Syntax analysis that will be used is Bahasa Indonesia structure rules [9] -[11] . The rules are converted into a context-free grammar structure (CFG). One notation is often used to write the CFG is Backus-Naur Form—BNF. Here are the example segments of Bahasa Indonesia BNF:
 (1)
(1)
 (2)
(2)
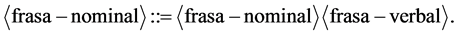 (3)
(3)
 (4)
(4)
 (5)
(5)
 (6)
(6)
 (7)
(7)

 (8)
(8)
Noun phrase (“frasa-nominal”) can be construct from noun (“nomina”) or noun phrase followed by another phrase. For example, noun phrase and verb phrase (“frasa-verbal”). In another segment verb phrase can be construct from verb (“verba”) and another phrase. Completed BNF for Bahasa Indonesia has been made.
2.4. Synthesis Module
Sentence in the text is converted into the format of pho with attention to intonation patterns and phoneme duration and duration of pauses between phrases. Intonation patterns derived from the module selector pattern, while the duration of phonemes and pause duration is derived from syntax analyst module. The pho format is ready to be fed to the DSP module to be voiced.
From pattern selector module resulting array of phonemes, includes spaces, and pho notation for the corresponding phonem. On the other hand, analyst module generates duration of pauses between words from the input sentence. The length of this pause is then used to correct the lag length of the pattern selector module output. It is expected the end result is in accordance with the intonation patterns and also in accordance with the structure of the sentence.
Illustration of the results of output from the intonation pattern module, the sentence structure analyst module, and synthesis module are shown in Figure 2. Output of intonation patterns module focused on intonation while sentence analyst module more focused on the pause duration between words.
3. Results
Fist, a pattern that contents of series of  is got from a recorded voice by Praat application. Then, the input text was normalized by a normalized module written in PHP. Its output is called as text-norm. The analyst syntax running on text-norm gets the sentence structure with duration of phrases and words. The synthesis module composed a series of phonemes and prosody from the norm-text, the
is got from a recorded voice by Praat application. Then, the input text was normalized by a normalized module written in PHP. Its output is called as text-norm. The analyst syntax running on text-norm gets the sentence structure with duration of phrases and words. The synthesis module composed a series of phonemes and prosody from the norm-text, the 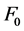 pattern, and the sentence structure. Finally, a voice will be generated by MBROLA application from this series of phonemes and prosody.
pattern, and the sentence structure. Finally, a voice will be generated by MBROLA application from this series of phonemes and prosody.
In this research some tools are used e.g. a Praat and an MBROLA applications. The Praat application is used to get  from voice files while MBROLA application used to generate voice from phonemes + prosody form. MBROLA is not a speech synthesis complete software. MBROLA requires input of phonemes and prosody in a form that matches to the MBROLA form called pho. That is why the text to be synthesized must be converted first into MBROLA form (pho). MBROLA made by TCTS Lab of Facult? é Polytechnique de Mons Belgium [12] .
from voice files while MBROLA application used to generate voice from phonemes + prosody form. MBROLA is not a speech synthesis complete software. MBROLA requires input of phonemes and prosody in a form that matches to the MBROLA form called pho. That is why the text to be synthesized must be converted first into MBROLA form (pho). MBROLA made by TCTS Lab of Facult? é Polytechnique de Mons Belgium [12] .
Table 1 shows the result of normalization module. Symbols, numbers, and abbreviation converted correctly. The punctuation marks: comma , period
, period , and hyphenation
, and hyphenation  are still unchanged.
are still unchanged.
 of sentence “Empat LSM lembaga swadaya masyarakat diantaranya ICW indonesia corruption watch PSHK pusat studi hukum dan kebijakan menyampaikan aspirasi kepada panitia ad hock PAH empat DPD di
of sentence “Empat LSM lembaga swadaya masyarakat diantaranya ICW indonesia corruption watch PSHK pusat studi hukum dan kebijakan menyampaikan aspirasi kepada panitia ad hock PAH empat DPD di

Figure 2. Relation between selector pattern and syntax analyst (sentence structure) modules. Top: result of intonation pattern, bottom: result of syntax analyst.
komplek parlemen senayan Jakarta hari ini” is shown in Table 2 but there are only partial results. A full result contained about 1200 data. The  table obtained by Praat application [7] [13] .
table obtained by Praat application [7] [13] .
If a sentence “DPD kemudian tetap melakukan uji kepatutan dan kelayakan” fed into the syntax analyst module, a sentence structure diagram obtained as shown in Figure 3.
Voice synthesis module in this study is part of the pho file processing module according to the rules of normalization followed the general tone combined with syntax analysts and intonation patterns. For comparison, the results will be presented waveform synthesis with flat intonation, intonation with the general rule, and intonation pattern.

Table 1. Result of normalization module for complete sentences.
Table 2. Excerpts F0 results for sentence.

Figure 3. Example of sentence structure.
Firstly, the sentence “Wimar tidak dapat mengikuti pemakaman Gus Dur di Jombang” is synthesized with flat intonation. The results of the graph  are shown in Figure 4. Secondly, for the same sentence but intonation synthesized according to the general rules, the results of the graph
are shown in Figure 4. Secondly, for the same sentence but intonation synthesized according to the general rules, the results of the graph 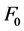 are shown in Figure 5. And, Figure 6 shows the synthesis of the same as the second but improved by incorporating elements of intonation pattern. The selected intonation pattern has
are shown in Figure 5. And, Figure 6 shows the synthesis of the same as the second but improved by incorporating elements of intonation pattern. The selected intonation pattern has  as shown in Figure 7.
as shown in Figure 7.
Similarity checking beetween synthesis result and original voice can be done by quantity approach. In this study, the checking similarity uses the PESQ method [14] [15] . The result of PESQ for several sentences is shown in Table3
4. Discussion
Table 1 shows that the integer number of year (2013) and the amount of money (179) can be converted correctly. Likewise fractions (182,57) can be converted to text correctly. Because 57 is a fraction, so it is converted into a “lima tujuh” (five seven) instead of “lima puluh tujuh” (fifty seven). The comma in 182,57 is decimal separator instead of thousand separator. Abbreviations and acronyms can be converted correctly. KJRI, BPS, and AS are converted to “ka je er i”, “be pe es”, and “a es”. The “ybs.” and “Sdri.” acronyms are converted to “yang bersangkutan” and “Saudari”.
Praat application output has 2 columns i.e time and fundamental frequency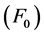 . In this study, the time has 0.01 seconds interval so there are 100 data in every second of voice. See Table 2, a graph like Figure 7 can be obtained from this table. The graph shows that it has 2 peaks in
. In this study, the time has 0.01 seconds interval so there are 100 data in every second of voice. See Table 2, a graph like Figure 7 can be obtained from this table. The graph shows that it has 2 peaks in 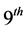 second and
second and  second. During the first 7.5 seconds, there are several small peaks. Those peaks can be dominated when combination of general rules and intonation patterns has made.
second. During the first 7.5 seconds, there are several small peaks. Those peaks can be dominated when combination of general rules and intonation patterns has made.
A flat intonation was obtained from MBROLA when the frequency was set in one value for a long of speech

Figure 4. Graph F0 with flat intonation.

Figure 5. Graph F0 with intonation according to general rules.

Figure 6. Graph F0 with the general rules and intonation patterns.
synthesis. Figure 4 shows the result of flat intonation graph when the frequency set to 115 Hz. Although several small peaks were shown in a flat intonation, it happened because of MBROLA characteristic.
In gerenal rules of intonation according to [5] the peaks of  appeared at the syllables of nouns. For nouns before a verb
appeared at the syllables of nouns. For nouns before a verb  peak occur in a syllable before the last syllable called the penultimate. In a sentence “Wimar tidak bisa mengikuti pemakaman Gus Dur di Jombang” “Wimar” is a noun before the verb “mengikuti”. In that case
peak occur in a syllable before the last syllable called the penultimate. In a sentence “Wimar tidak bisa mengikuti pemakaman Gus Dur di Jombang” “Wimar” is a noun before the verb “mengikuti”. In that case  peak occur in syllable “Wi” from the word “Wimar”. That is in the start of sentence. See the first seconds of graph in Figure 4. For nouns after a verb
peak occur in syllable “Wi” from the word “Wimar”. That is in the start of sentence. See the first seconds of graph in Figure 4. For nouns after a verb  peak occur in the first syllable of the first noun. In the sentence the first syllable of the first noun is “Gus”. This syllable is the
peak occur in the first syllable of the first noun. In the sentence the first syllable of the first noun is “Gus”. This syllable is the  syllable of 19 syllables in the sentence. We can calculate that this syllable occur in about
syllable of 19 syllables in the sentence. We can calculate that this syllable occur in about
 (9)
(9)
Table 3. Values of PESQ for several sentences.
This peak can be seen at the fourth second of the graph in Figure 5. After that the values of  continues to fall until the end of the sentence.
continues to fall until the end of the sentence.
The pattern has  graph as shown in Figure 7. It has two peaks that occur at
graph as shown in Figure 7. It has two peaks that occur at  and
and  second from 17.5 s speech synthesis a long. We can calculate the segments of its value
second from 17.5 s speech synthesis a long. We can calculate the segments of its value
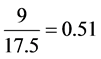 (10)
(10)
 (11)
(11)
This selected pattern then combined to speech voice that has  as Figure 5 obtained a speech voice that has
as Figure 5 obtained a speech voice that has  as Figure 6. The
as Figure 6. The  peaks of the syntesis result can be predict from Equation (9) occur at
peaks of the syntesis result can be predict from Equation (9) occur at

This results is not match with the graph second peak in Figure 6. There is no peak in this value. If we used Equation (10) and (11) we get

and
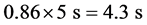
There are peaks that match with peaks in Figure 6. The second peak can take a place the wrong result as Equation (9). Thus Figure 6 is combination of Figure 5 and Figure 7.
From Table 3, we get that the average value of PESQ is 1.096. This value can be converted to MOS-LQO scale by the following formula [14]
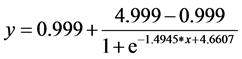
where  is MOS-LQO in the range 1.02 to 4.56,
is MOS-LQO in the range 1.02 to 4.56,  is PESQ value in the range
is PESQ value in the range 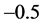 to 4.5. The value of MOS-LQO is
to 4.5. The value of MOS-LQO is
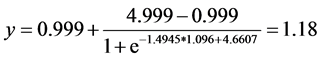
5. Conclusion
Speech synthesis model with a combination of general rules and intonation patterns of the fundamental frequency 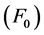 can be implemented. The peaks of
can be implemented. The peaks of 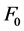 determined by general rules or intonation patterns are dominant. Indonesian has intonation general rules, but should not be adhered strictly. Similarity test with the PESQ method shows that the synthesis results are about 1.18 at MOS-LQO scale. A speech synthesis based on the announcer voice intonation patterns is expected to be used as an alternative method of Indonesian speech synthesis refinement.
determined by general rules or intonation patterns are dominant. Indonesian has intonation general rules, but should not be adhered strictly. Similarity test with the PESQ method shows that the synthesis results are about 1.18 at MOS-LQO scale. A speech synthesis based on the announcer voice intonation patterns is expected to be used as an alternative method of Indonesian speech synthesis refinement.