A New Algorithm for Generalized Least Squares Factor Analysis with a Majorization Technique ()
1. Introduction
Using 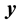 for a
for a 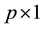 observation
vector w
hose
expect
ation
observation
vector w
hose
expect
ation
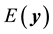 equal
s the
equal
s the 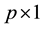 zero
vector
zero
vector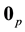 , the
f
act
or
analysis
(FA) model is
ex
press
ed as
, the
f
act
or
analysis
(FA) model is
ex
press
ed as
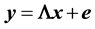 (1)
(1)
with 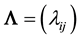 a p-
vari
able
s × m-
f
act
or
s
load
ing
matrix
,
a p-
vari
able
s × m-
f
act
or
s
load
ing
matrix
, 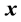 an
an 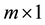 latent factor score vector,
latent factor score vector, 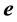 a
a 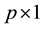 error vector, and
error vector, and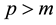 . The expectations for
. The expectations for 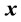 and
and 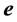 are assumed to satisfy
are assumed to satisfy
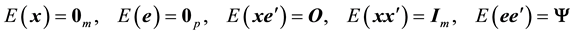 (2)
(2)
Here, 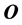 is the
is the ![]() matrix of zeros,
matrix of zeros, ![]() is the
is the ![]() identity matrix, and
identity matrix, and ![]() is the
is the ![]() diagonal matrix whose diagonal elements are called
unique
variance
s. The FA model (1) with the assumptions in (2) imply that the covariance matrix
diagonal matrix whose diagonal elements are called
unique
variance
s. The FA model (1) with the assumptions in (2) imply that the covariance matrix ![]() is modeled as
is modeled as
![]() (3)
(3)
[1] [2] . A main purpose of FA is to estimate the parameter matrices ![]() and
and ![]() from the inter-variable sample covariance matrix
from the inter-variable sample covariance matrix ![]()
![]() corresponding to (3). Some authors classify FA as exploratory (EFA) or
con
firm
atory
(CFA) [2] , where
corresponding to (3). Some authors classify FA as exploratory (EFA) or
con
firm
atory
(CFA) [2] , where ![]() is unconstrained in EFA, while some elements of
is unconstrained in EFA, while some elements of ![]() are constrained in CFA. In this paper, we refer to EFA simply as FA.
are constrained in CFA. In this paper, we refer to EFA simply as FA.
Three
major
appro
ach
es for the
para
mete
r
estimation
are
l
east
square
s (LS),
gene
ra
l
ize
d
l
east
square
s (GLS), and
maxim
um
like
li
hood
(ML)
procedure
s [3] . They
differ
in the
definition
of the
loss
f
unction
![]() to be minimized
over
to be minimized
over
![]() . The
f
unction
s for the LS and GLS
estimation
procedure
s are
de
fine
d as
. The
f
unction
s for the LS and GLS
estimation
procedure
s are
de
fine
d as ![]() and
and
![]() (4)
(4)
respectively,
while
![]() is
de
fine
d as the
negative
of the log-
like
li
hood
derive
d under the
norm
al
ity
assumption
for
is
de
fine
d as the
negative
of the log-
like
li
hood
derive
d under the
norm
al
ity
assumption
for ![]() and
and ![]() in the ML
estimation
[3] [4] .
in the ML
estimation
[3] [4] .
In all
estimation
procedure
s, iterative algorithms are
need
ed for minimizing
loss
f
unction
![]() . They can be
rough
ly
c
lass
ified
into
gradient
and
in
e
qual
ity
-
base
d algorithms.
Here
, the
gradient
ones
refer
to the algorithms u
sing
Newton and
r
e
late
d methods [5] , in which the
part
ial
diffe
r
ent
iation
of
. They can be
rough
ly
c
lass
ified
into
gradient
and
in
e
qual
ity
-
base
d algorithms.
Here
, the
gradient
ones
refer
to the algorithms u
sing
Newton and
r
e
late
d methods [5] , in which the
part
ial
diffe
r
ent
iation
of ![]() with
respect
to
with
respect
to ![]() is
used
for updating it. On the
other
hand
, the
term
“
in
e
qual
ity
-
base
d algorithms” is not a
popular
one. We use the
term
for the algorithms, in which
diffe
r
ent
iation
is not
used
and the
in
e
qual
ity
is
used
for updating it. On the
other
hand
, the
term
“
in
e
qual
ity
-
base
d algorithms” is not a
popular
one. We use the
term
for the algorithms, in which
diffe
r
ent
iation
is not
used
and the
in
e
qual
ity
![]() underlies
that
which
gua
rant
ee
s the
weak
ly
mono
tone
de
cr
ease
in the
loss
f
unction
value
with up
dating
underlies
that
which
gua
rant
ee
s the
weak
ly
mono
tone
de
cr
ease
in the
loss
f
unction
value
with up
dating
![]() to
to![]() . Similar dichotomization of minimization methodology is also found in [6] .
. Similar dichotomization of minimization methodology is also found in [6] .
For all of the LS, GLS, and ML
estimation
,
gradient
algorithms
have
been
dev
e
lop
ed: t
hose
with the Fletcher- Powell and Newton-Raphson methods
have
been
pro
p
ose
d for the ML
estimation
[7] [8] ,
while
the algorithms u
sing
the Newton-Raphson and Gauss-Newton
method
s
have
been
dev
e
lop
ed for GLS [9] [10] with the
gradient
algorithms for GLS also
used
for LS. On the
other
hand
,
in
e
qual
ity
-
base
d algorithms
have
been
dev
e
lop
ed for the LS and ML
estimation
excluding GLS.
Such
an algorithm for LS is MINRES [11] in which ![]() is
part
ition
ed into the subsets of
para
mete
r
s with
is
part
ition
ed into the subsets of
para
mete
r
s with ![]() and the minimization of
and the minimization of ![]() over
each subset
over
each subset ![]() for
for ![]() is ite
rate
d. The
in
e
qual
ity
-
base
d one for the ML
estimation
is the EM algorithm for FA [12] in which
is ite
rate
d. The
in
e
qual
ity
-
base
d one for the ML
estimation
is the EM algorithm for FA [12] in which ![]() decreases mono
toni
c
ally
with the alternate iteration of so-
call
ed E- and M-steps [13] . A
feat
ure
of MINRES and the EM algorithm is
that
only
simple
matrix
computations
such
as the in
version
of ma
t
rice
s are
require
d and t
heir
compute
r
-
program
s are easily
form
ed. In
contrast
, the
gradient
algorithms
require
more
complicate
d
computation
s
such
as
obtain
ing or numeri
c
all
y approxi
mating
the
second
derivatives of
decreases mono
toni
c
ally
with the alternate iteration of so-
call
ed E- and M-steps [13] . A
feat
ure
of MINRES and the EM algorithm is
that
only
simple
matrix
computations
such
as the in
version
of ma
t
rice
s are
require
d and t
heir
compute
r
-
program
s are easily
form
ed. In
contrast
, the
gradient
algorithms
require
more
complicate
d
computation
s
such
as
obtain
ing or numeri
c
all
y approxi
mating
the
second
derivatives of![]() .
.
As found in the above discussion, an
in
e
qual
ity
-
base
d algorithm has not been
dev
e
lop
ed for the GLS
estimation
in which (4) is minimized over![]() . To propose it is the
pur
pose
of
this
paper
. The algorithm to be proposed is also
computation
ally
simple
as in the existing inequality-based ones: only elementary
matrix
computation
s are
require
d
such
as the in
version
and
sing
ular
value
de
com
position
(SVD) of ma
t
rice
s. A
feat
ure
of the
pro
p
ose
d algorithm to be
ad
dress
ed is using
major
ization in one of
step
s. The
major
ization
gene
r
a
l
ly
refer
s to a
c
lass
of the techniques in which a
major
izing
f
unction
. To propose it is the
pur
pose
of
this
paper
. The algorithm to be proposed is also
computation
ally
simple
as in the existing inequality-based ones: only elementary
matrix
computation
s are
require
d
such
as the in
version
and
sing
ular
value
de
com
position
(SVD) of ma
t
rice
s. A
feat
ure
of the
pro
p
ose
d algorithm to be
ad
dress
ed is using
major
ization in one of
step
s. The
major
ization
gene
r
a
l
ly
refer
s to a
c
lass
of the techniques in which a
major
izing
f
unction
![]() is utilized for minimizing a
f
unction
is utilized for minimizing a
f
unction
![]() over
over
![]() .
Here
,
.
Here
, ![]() satisfies
satisfies![]() , with
, with ![]() being
the minimizer of the
major
izing
f
unction
being
the minimizer of the
major
izing
f
unction
![]() for its latter
argument
matrix
for its latter
argument
matrix
![]() kept fixed [14] . It
show
s
that
kept fixed [14] . It
show
s
that
![]() de
cr
ease
s with the
up
date
of
de
cr
ease
s with the
up
date
of ![]() into
into![]() . As described in the
next
sect
ion
, the
step
with a
major
ization
technique
and the steps for minimizing the functions of
diagonal
ma
t
rice
s
form
the algorithm to be
p
resent
ed. It is thus
call
ed majorizing-diagonal (MD) algorithm in
this
paper
.
. As described in the
next
sect
ion
, the
step
with a
major
ization
technique
and the steps for minimizing the functions of
diagonal
ma
t
rice
s
form
the algorithm to be
p
resent
ed. It is thus
call
ed majorizing-diagonal (MD) algorithm in
this
paper
.
The MD algorithm is not the
first
one with
major
ization in FA. In
deed
, the above EM algorithm [12] can be
regard
ed as a
major
ization
procedure
with its
major
izing
f
unction
being
the
full
log
like
li
hood
derive
d by suppo
sing
that
la
te
nt
f
act
or
s
core
s in ![]() were
ob
serve
d. [15] has also
pro
p
ose
d an FA algorithm with a
major
ization
technique
. How
ever
, in
that
algorithm, the
estimation
of a new
type
[16] [17] is
con
side
r
ed, which are
diffe
r
ent
from the LS, GLS, and ML
estimation
treat
ed as the
major
procedure
s in
this
paper
: [15] is
beyond
the
s
cope
of
this
paper
.
were
ob
serve
d. [15] has also
pro
p
ose
d an FA algorithm with a
major
ization
technique
. How
ever
, in
that
algorithm, the
estimation
of a new
type
[16] [17] is
con
side
r
ed, which are
diffe
r
ent
from the LS, GLS, and ML
estimation
treat
ed as the
major
procedure
s in
this
paper
: [15] is
beyond
the
s
cope
of
this
paper
.
The remaining parts of this paper are organized as follows: the MD algorithm is detailed in the next section, and it is illustrated with a real data set in Section 3. A simulation study for assessing the algorithm is reported in Section 4, which is followed by discussions.
2. Proposed Algorithm
We propose the MD algorithm for minimizing the GLS loss function (4) over the loadings in ![]()
![]() and the unique variances in the diagonal matrix
and the unique variances in the diagonal matrix ![]()
![]() . Here, it is supposed that the sample covariance matrix
. Here, it is supposed that the sample covariance matrix ![]() is positive-definite and
is positive-definite and ![]() is of full-column rank, i.e., its rank is
is of full-column rank, i.e., its rank is ![]() with
with![]() . This supposition and the covariance matrix being modeled as (3) imply that, without loss of generality, we can reparameterize
. This supposition and the covariance matrix being modeled as (3) imply that, without loss of generality, we can reparameterize ![]() as
as
![]() (5)
(5)
where ![]() is a
is a ![]() matrix satisfying
matrix satisfying
![]() (6)
(6)
and ![]() is an
is an ![]() positive-definite diagonal matrix. By substituting (5) into the GLS loss function (4), it is rewritten as
positive-definite diagonal matrix. By substituting (5) into the GLS loss function (4), it is rewritten as
![]() (7)
(7)
This function is minimized over![]() ,
, ![]() , and
, and ![]() subject to (6) and the latter two matrices being diagonal ones, by alternately iterating the majorizing and diagonal steps described in the next subsections.
subject to (6) and the latter two matrices being diagonal ones, by alternately iterating the majorizing and diagonal steps described in the next subsections.
2.1. Majorization Step
Let us consider minimizing (7) over ![]() subject to (6) while
subject to (6) while ![]() and
and ![]() are kept fixed. Summarizing the parts irrelevant to
are kept fixed. Summarizing the parts irrelevant to ![]() in (7) into
in (7) into![]() , the loss function (7) is rewritten as
, the loss function (7) is rewritten as
![]() . (8)
. (8)
Though the optimal ![]() that
minimizes (8) under (6) is not
give
n
explicit
ly, the
solution
can be
obtain
ed u
sing
Kiers and ten Berge’s [18]
major
ization
technique
, w
hose
earlier
version
is also
found
in [19] .
This
technique
pur
pose
s to minimize a
f
unction
ex
press
ed as the
form
that
minimizes (8) under (6) is not
give
n
explicit
ly, the
solution
can be
obtain
ed u
sing
Kiers and ten Berge’s [18]
major
ization
technique
, w
hose
earlier
version
is also
found
in [19] .
This
technique
pur
pose
s to minimize a
f
unction
ex
press
ed as the
form
![]() . Compa
ring
this
with (8), we can
find
(8) to be a
special
case
of the above
. Compa
ring
this
with (8), we can
find
(8) to be a
special
case
of the above ![]() with
with ![]() being
the
zero
matrix
,
being
the
zero
matrix
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and![]() . T
here
fore
, the
up
date
form
ula
in [18] (pp. 374-375) can be
straight
for
ward
ly
used
for (8).
. T
here
fore
, the
up
date
form
ula
in [18] (pp. 374-375) can be
straight
for
ward
ly
used
for (8).
According to the formula, the update of ![]() by
by
![]() (9)
(9)
decreases the value of (8) with![]() . Here,
. Here, ![]() stands for the matrix
stands for the matrix ![]() before the update;
before the update; ![]() and
and ![]() are the column-orthonormal matrices that are obtained from the SVD defined as
are the column-orthonormal matrices that are obtained from the SVD defined as
![]() (10)
(10)
with ![]() the diagonal matrix including the singular values of the matrix in the left-hand side, and
the diagonal matrix including the singular values of the matrix in the left-hand side, and![]() ,
, ![]() , and
, and ![]() the largest eigenvalues of
the largest eigenvalues of![]() ,
, ![]() , and
, and![]() , respectively.
, respectively.
2.2. Diagonal Steps
In this section, we describe updating each of diagonal matrices ![]() and
and![]() . First, let us consider minimizing the loss function (7) over
. First, let us consider minimizing the loss function (7) over ![]() with keeping
with keeping ![]() and
and ![]() fixed. Since the terms relevant to
fixed. Since the terms relevant to ![]() in the loss function (7) are the same as those relevant to
in the loss function (7) are the same as those relevant to![]() , the expression (8) into which (7) is rewritten is to be noted again. By taking account of the fact that
, the expression (8) into which (7) is rewritten is to be noted again. By taking account of the fact that ![]() is a diagonal matrix, (8) can be rewritten as
is a diagonal matrix, (8) can be rewritten as
![]() (11)
(11)
Here, ![]() and
and ![]() with
with ![]() denoting the diagonal matrix whose diagonal elements are those of the parenthesized matrix. Further, we can rewrite (11) as
denoting the diagonal matrix whose diagonal elements are those of the parenthesized matrix. Further, we can rewrite (11) as ![]() with
with ![]() denoting the Frobenius norm. It shows that the function
denoting the Frobenius norm. It shows that the function
(11) is minimized for
![]() (12)
(12)
for fixed ![]() and
and![]() .
.
Next, we consider minimizing (7) over ![]() with
with ![]() and
and ![]() fixed. Summarizing the parts irrelevant to
fixed. Summarizing the parts irrelevant to ![]() in (7) into
in (7) into ![]() and using the fact of
and using the fact of ![]() being a diagonal matrix, the loss function (7) can be rewritten as
being a diagonal matrix, the loss function (7) can be rewritten as
![]() (13)
(13)
with ![]() and
and![]() . We can find that (13) is minimized for
. We can find that (13) is minimized for
![]() (14)
(14)
for fixed ![]() and
and![]() .
.
2.3. Whole Algorithm
The results in the last two subsections show that the proposed MD algorithm can be listed as follows:
Step 1. Initialize![]() ,
, ![]() , and
, and![]() .
.
Step 2. Update ![]() with (9)
with (9) ![]() times.
times.
Step 3. Update ![]() with (12).
with (12).
Step 4. Update ![]() with (14).
with (14).
Step 5. Finish with ![]() set to (5) if convergence is reached; otherwise, return to Step 2.
set to (5) if convergence is reached; otherwise, return to Step 2.
It should be noted in Step 2 that the update of ![]() by (9) does not minimize (7) but only decreases its value, which implies that that update can be replicated (
by (9) does not minimize (7) but only decreases its value, which implies that that update can be replicated (![]() times) for further decreasing the value of (7). In this paper, we set
times) for further decreasing the value of (7). In this paper, we set![]() .
.
In Step 1, the initialization is performed using the principal component analysis of sample covariance matrix![]() . That is, the initial
. That is, the initial ![]() and
and ![]() are given by
are given by ![]() and
and![]() , respectively, with
, respectively, with ![]() the
the ![]() diagonal matrix whose diagonal elements are the
diagonal matrix whose diagonal elements are the ![]() largest eigenvalues of
largest eigenvalues of![]() , and the columns of
, and the columns of ![]()
![]() being the eigenvectors corresponding to
being the eigenvectors corresponding to![]() . The initial
. The initial ![]() is set to
is set to![]() .
.
In Step 5, we define the convergence as the decrease in the value of (7) or (4) from the previous round being less than![]() .
.
3. Illustration
In this section, we illustrate the performance of the MD algorithm with a 190-
person
× 25-
item
data matrix, which was
collect
ed by the
author
and
public
ly
avail
able
at http://bm.osaka-u.ac.jp/data/big5/.
Th is
data
set con- tains the
self
-
rating
s of the
person
s (university students) for to
what
ex
tent
s they are
character
ize
d by the personalities
des
crib
e
d by the 25
items
.
Ac
cord
ing
to a
theory
in
person
a
l
ity
psych
ology
[20] , the
item
s can be
c
lass
ified
into the five
group
s
show
n in the
first
column
of Table 1. The 25 × 25
matrix
of the correlation coefficients among those items was
obtain
ed from the
data
set.
We carried out the MD algorithm for the
cor
relation
matrix
with the number of factors m set to five. Figure 1 shows the change in the value of loss function (4) until the steps in Section 2.3 were iterated ten times and the change after the tenth iteration. There, we can find that the function value decreased monotonically with iteration, which was finally reached to convergence at the 542 nd iteration.
![]()
Table 1. Loadings and unique variances Y1p for personality rating data.
![]()
![]()
Figure 1. Change in the GLS loss function value as a function of the number of iteration.
As the
result
ing
load
ing
matrix
has rotational freedom, that is, the ![]() post-multiplied by arbitrary orthonormal matrix satisfies (1) and (2), the loading matrix was rotated by the varimax method [21] . The solution is presented in Table 1. There, bold font is used for the loadings whose absolute values are greater than 0.35. They show that the 25 items are clearly classified into the five groups as predicted by the theory in personality psychology [20] , which demonstrates that the MD algorithm provided the reasonable solution.
post-multiplied by arbitrary orthonormal matrix satisfies (1) and (2), the loading matrix was rotated by the varimax method [21] . The solution is presented in Table 1. There, bold font is used for the loadings whose absolute values are greater than 0.35. They show that the 25 items are clearly classified into the five groups as predicted by the theory in personality psychology [20] , which demonstrates that the MD algorithm provided the reasonable solution.
4. Simulation Study
A simulation study was performed in order to assess how well parameter matrices are recovered by the proposed MD algorithm and compare it with the existing algorithms for the GLS estimation in the goodness of the recovery. We first describe the procedure for synthesizing the data to be analyzed, which is followed by results.
An n-observations × p-variables data matrix ![]() was synthesized according to the matrix versions of the FA model (1) and the assumptions in (2):
was synthesized according to the matrix versions of the FA model (1) and the assumptions in (2):
![]() (15)
(15)
![]() (16)
(16)
Here
, ![]() denotes the
denotes the ![]() vector of ones,
vector of ones, ![]() is an
is an ![]() b
loc
k
matrix
w
hose
right
b
loc
k
matrix
w
hose
right
![]() b
loc
k
b
loc
k
![]() is
post
-multiplied by
is
post
-multiplied by ![]() to
give
the
error
matrix
to
give
the
error
matrix
![]() , and
, and ![]() is an
is an ![]() b
loc
k
matrix
including the
load
ing
matrix
and the
square
root
s of
unique
variance
s. It should be
notice
d
that
each row of
b
loc
k
matrix
including the
load
ing
matrix
and the
square
root
s of
unique
variance
s. It should be
notice
d
that
each row of![]() ,
, ![]() , and
, and ![]() cor
res
pond
s to
cor
res
pond
s to![]() ,
, ![]() , and
, and![]() ,
respect
ively, w
hose
transposed vectors
ap
pear
in (1), and the five
equation
s in (2) can be
summarize
d into the two
matrix
ex
press
ion
s in (16). The
data
syn
thesis
procedure
follow
s the
next
step
s:
,
respect
ively, w
hose
transposed vectors
ap
pear
in (1), and the five
equation
s in (2) can be
summarize
d into the two
matrix
ex
press
ion
s in (16). The
data
syn
thesis
procedure
follow
s the
next
step
s:
Step 1. Draw ![]() from
from![]() ,
, ![]() from
from![]() , and
, and ![]() from
from![]() , with
, with ![]() denoting the discrete uniform distribution defined for the integers within the range
denoting the discrete uniform distribution defined for the integers within the range![]() .
.
Step 2. Draw each loading in ![]() from
from ![]() and each unique variance in
and each unique variance in ![]() from
from ![]() with
with ![]() denoting the uniform distribution over the range
denoting the uniform distribution over the range![]() .
.
Step 3. Draw each elements of ![]() in (15) from
in (15) from ![]() which is followed by centering
which is followed by centering ![]() and post- multiplying it by the matrix that allows the resulting
and post- multiplying it by the matrix that allows the resulting ![]() to satisfy (16).
to satisfy (16).
Step 4. Form ![]() with (15) and obtain the covariance matrix
with (15) and obtain the covariance matrix![]() .
.
In Step 3 we have used a uniform distribution for![]() , rather than the normal distribution typically used for such a matrix, as a feature of the GLS estimation is that it does not need the normality assumption required in the ML estimation. We replicated the above steps to have 2000 sets of
, rather than the normal distribution typically used for such a matrix, as a feature of the GLS estimation is that it does not need the normality assumption required in the ML estimation. We replicated the above steps to have 2000 sets of![]() . For them, the MD and the existing algorithms were carried out, where the latter are the two gradient algorithms [9] [10] , as described in Section 1. We refer to the ones in [9] and [10] as the Newton-Raphson (NR) and Gauss-Newton (GN) algorithms, respectively. In the NR one, we obtained the gradient vector in [9] , Equation (32), by pre-multiplying the vector of first derivatives by the Moore Penrose inverse of the corresponding Hessian matrix. Also in the NR and GN algorithms, we used the same initialization and definition of convergence as in Section 2.3.
. For them, the MD and the existing algorithms were carried out, where the latter are the two gradient algorithms [9] [10] , as described in Section 1. We refer to the ones in [9] and [10] as the Newton-Raphson (NR) and Gauss-Newton (GN) algorithms, respectively. In the NR one, we obtained the gradient vector in [9] , Equation (32), by pre-multiplying the vector of first derivatives by the Moore Penrose inverse of the corresponding Hessian matrix. Also in the NR and GN algorithms, we used the same initialization and definition of convergence as in Section 2.3.
Let us express the true ![]() simply as
simply as ![]() and use
and use ![]() for the solution given by the NR, GN, or MD algorithm. For assessing the recovery of the loading matrix, the averaged absolute difference (AAD) of the elements in
for the solution given by the NR, GN, or MD algorithm. For assessing the recovery of the loading matrix, the averaged absolute difference (AAD) of the elements in ![]() to the corresponding estimates, i.e.,
to the corresponding estimates, i.e.,
![]() , (17)
, (17)
can be used with ![]() denoting the
denoting the ![]() norm. Here, it should be noted that
norm. Here, it should be noted that ![]() has rotational freedom and must be rotated so that the resulting
has rotational freedom and must be rotated so that the resulting ![]() is optimally matched to
is optimally matched to![]() . Such a rotated
. Such a rotated ![]() can be obtained by the orthogonal Procrustes method [22] with
can be obtained by the orthogonal Procrustes method [22] with ![]() a target matrix. The loading matrix
a target matrix. The loading matrix ![]() in (17) thus stands for the one rotated by the Procrustes method. The recovery of unique variances can also be assessed with the AAD index
in (17) thus stands for the one rotated by the Procrustes method. The recovery of unique variances can also be assessed with the AAD index![]() , where the unique variances are uniquely determined, thus the additional procedure as for
, where the unique variances are uniquely determined, thus the additional procedure as for ![]() is unnecessary. Smaller values of those AAD indices stand for better recovery.
is unnecessary. Smaller values of those AAD indices stand for better recovery.
The
statistics
of AAD values
over
2000
data
sets are
p
resent
ed in Table 2. T
here
, the
ave
r
age
s
show
that
the recovery by the MD algorithm is the best and that for the NR one is the worst. It should be
note
d
that
the 50 and 75
per
cen
t
iles for the NR algorithm are
zero
,
while
the
maxim
um
and 99
per
cen
t
ile are very
large
.
That
is, the recovery by the NR algorithm was perfect for more than 75 percent of the 2000 data sets, but for a few percent of them, recovery was considerably bad, which increased the averages for the NR one. In
contrast
, the
maxim
um
AAD of
load
ing
s and
unique
variance
s for the MD algorithm are 0.0041 and 0.0013,
respect
ively, which are
![]()
Table 2. Statistics for the differences between the true parameter values and their estimated counterparts.
s
mall
enough
to be
ignore
d.
That
is, the proposed MD algorithm well recovered the true parameter values for all of the 2000
data
sets. We can thus
conclude
that
the MD algorithm is
superior
to the existing ones in the goodness of recovery.
5. Discussion
We proposed the majorizing-diagonal (MD) algorithm for the GLS estimation in FA. In the algorithm, the loading matrix is reparameterized as the product of a column-orthonormal matrix and a diagonal one, and the former one is updated with Kiers and ten Berge’s [18]
major
ization technique, while the latter diagonal matrix and another diagonal one including unique variances are updated so that their quadratic functions are minimized. The iteration of those updates decreases monotonically the GLS loss function. The simulation study demonstrated the exact recovery of loadings and unique variances by the MD algorithm and its superiority to the existing gradient algorithms in the recovery.
One of the tasks remaining for the MD algorithm is to study its mathematical properties as have been done for the algorithms in the other estimation procedures. For example, it has been found that the EM algorithm for the ML estimation [12] can never give an improper solution under a certain condition [23] , where the improper solution refers to the one including a negative unique variance. Whether such special features are possessed by the MD algorithm is considered to be found by studying the properties of the matrix update formulas in the algorithm.