Implicit Hypotheses Are Hidden Power Droppers in Family-Based Association Studies of Secondary Outcomes ()
1. Introduction
The aim of genetic epidemiological studies is to identify the genetic factors influencing the development of common diseases. Genetic epidemiology combines classical epidemiological data (assessment of risk factors known to affect the expression of the phenotype studied) and genetic information (familial relationships, typing of genetic marker) and proposes a large range of tools to address the initial question, the use of one depending on the nature of your sample and the size of your wallet. Over the past ten years, however, our understanding of the pattern of genetic variation at the genome scale, coupled to an unprecedented decrease in the cost of measuring this variation, has put (genome-wide) association studies at the front. Although the vast majority of genetic association study designs are derived from usual case-control retrospective epidemiological studies (i.e. that compare the distribution of allelic/genotypic frequencies between a group of cases and a group of controls), one is quite specific to the field of genetic epidemiology and relies on the collection and analysis of families. Such family-based tests of association between a genetic item (allele, genotype...) and the disease under study offer interesting features as compared to case-control designs (Laird and Lange [1] ; Chen and Abecasis [2] ). They are robust against population stratification, allow the inference of both haplotype phase and missing genotypes (Chen and Abecasis [2] ; Burdick et al. [3] ), and can identify peculiar allelic segregation, for example, due to imprinting effect (Vincent et al. [4] ).
The Transmission Desequilibrium Test (TDT) has emerged as the first popular family-based test of associa- tion (Spielman et al. [5] ). It tests whether the transmission of a given allele from a heterozygote parent to an affected child is different from what is expected in the absence of any association between the genetic marker and the disease under study. The null hypothesis is written as p = 0.5 where p is the proportion of a given allele that has been transmitted to affected children by heterozygote parents. Whereas the TDT could only analyze binary traits in samples of pure trios (i.e. two parents and a single affected child), Laird et al. [6] proposed a more comprehensive approach designed to handle binary, quantitative or censored traits, multiple genetic models (e.g. additive, dominant or recessive) and more complex family structures (e.g. families with multiple children). This approach uses a natural measure of association between two variables, i.e. the covariance between phenotypes and genotypes, and relies on a score-test. It has been implemented in the popular Family Based Association Test software (FBAT, Laird et al. [6] ; Rabinowitz and Laird [7] ; Lange and Laird [8] ). In this context of familial samples, FBAT has proved very efficient in identifying alleles associated with many phenotypes, whether binary or quantitative (e.g. Mira et al. [9] ; Cobat et al. [10] ).
Although developed to handle a large variety of tests according to the nature of both the traits and their genetic determinants, it is intrinsically designed to test primary outcomes (e.g. affected vs. unaffected) as the null hypothesis is based on the same underlying principles as the TDT (i.e. p = 0.5). However, in many cases researchers are interested in the genetic contribution to a more specific phenotype (e.g. severe vs. non-severe form), here denoted as a secondary outcome. Here, what we demonstrate is the limited power of the classical formulation of the FBAT statistic to detect the effect of genetic variants that influence a secondary outcome, in particular when these variants also impact on the onset of the disease, the primary outcome. We prove that this loss of power is driven by an implicit hypothesis and we propose a derivation of the original FBAT statistic, free from this implicit hypothesis. Finally, we demonstrate analytically that our new statistic is robust and more powerful than FBAT for the detection of association between a genetic variant and a secondary outcome.
2. Original FBAT Statistic
For sake of simplicity and without major loss of generality, we consider the analysis of a diallelic marker in a sample of trios with no missing parental data under an additive genetic model. Using the same notations as in the original FBAT paper (Laird et al. [6] ),
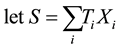
in which 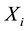 represents the genotype at the locus being tested and
represents the genotype at the locus being tested and 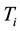 the phenotype of the child of family
the phenotype of the child of family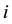 . The expectation of
. The expectation of 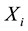 is calculated conditioned on the parental genotypes under the null hypothesis of no association.
is calculated conditioned on the parental genotypes under the null hypothesis of no association.
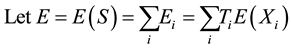
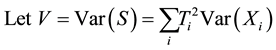

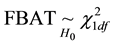
Under an additive model, 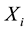 is the number of copy of the allele under study (0, 1 or 2). As the most common way to code the phenotype is
is the number of copy of the allele under study (0, 1 or 2). As the most common way to code the phenotype is  for affected individuals and
for affected individuals and 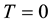 for unaffected ones. In a sample with no missing parental data, unaffected individuals do not contribute to the statistic; however, in the presence of missing parental data, such unaffected individuals will indirectly impact on the statistic as they can be used to infer missing parental genotypes under some conditions (Knapp [11] ). S is generally written as:
for unaffected ones. In a sample with no missing parental data, unaffected individuals do not contribute to the statistic; however, in the presence of missing parental data, such unaffected individuals will indirectly impact on the statistic as they can be used to infer missing parental genotypes under some conditions (Knapp [11] ). S is generally written as:
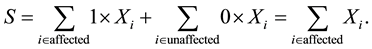
The null hypothesis of no association between the phenotype and a given allele is the random transmission of this allele from heterozygote parents to (affected) children. By noting 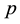 the transmission probability of this allele, the null
the transmission probability of this allele, the null 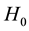 and alternate
and alternate 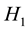 hypotheses can be written as:
hypotheses can be written as:
![]()
![]()
The tested allele will be considered “at risk” or “protective” for the disease, if ![]() or
or![]() , respec- tively1.
, respec- tively1.
3. FBAT Statistic to Test Secondary Outcomes
It is common practice to study a “primary” phenotype (e.g. disease yes/no) but as stated in the introduction, researchers are often interested in the genetic contribution to a “secondary” phenotype (e.g. severe vs. non-severe form of the disease). At first glance, FBAT could be used to test this hypothesis by computing the original statistic independently in the two modalities of the secondary outcome (e.g. severe and non-severe). Denoting ![]() and
and ![]() the two modalities of the secondary outcome,
the two modalities of the secondary outcome, ![]() and
and ![]() the transmission probabilities of the tested allele to
the transmission probabilities of the tested allele to ![]() and
and ![]() children, respectively, we have:
children, respectively, we have:
![]()
![]()
![]()
![]()
![]()
![]()
However, because of the bivariate nature of the phenotype under study (i.e. disease AND severe form or disease AND non-severe form), rejection of the null hypothesis cannot distinguish between alleles associated with the disease per se (i.e. independently of its severity) or alleles specifically associated with the severity of the disease. FBAT offers no immediate solution to study such secondary outcomes, i.e. to distinguish between alleles impacting the primary (e.g. disease per se) or the secondary (e.g. severe vs. non-severe) outcome. Below we propose two new tests denoted as FBAThet and FBAThet free that can be used to directly assess the association between a marker allele and a secondary outcome.
3.1. The FBAThet Test
A first straightforward idea is to perform a homogeneity test of the allelic transmission rate between the two subgroups ![]() and
and![]() .
.
![]()
![]()
FBAThet = FBAT with the phenotypes coded as ![]() for individuals D1 and
for individuals D1 and ![]() for individuals D2.
for individuals D2.
![]()
![]()
and
![]()
: the software then calculates, for each allele, an offset
![]()
used to transform the phenotypic values in
![]()
and
![]()
that minimizes the variance of the statistics. We show in Appendix B that using the offset option is equivalent to coding
![]()
and
![]()
, thus testing for secondary outcome. Here, one should not code unaffected individuals as 0 but as missing to avoid that the controls interfere in the calculation of the statistics. FBAT software can be downloaded from: http://www.biostat.harvard.edu/fbat/fbat.htm.
Indeed,
![]()
![]()
![]()
The two hypotheses can then be written as:
![]()
![]()
Note that under an additive genetic model and in a sample of trios with no missing parental data, coding
![]() and
and ![]() is equivalent to coding
is equivalent to coding ![]() and
and ![]() , where
, where ![]() and
and ![]() are the number
are the number
of heterozygote parents of children with phenotype ![]() and
and ![]() (see Appendix A)2.
(see Appendix A)2.
3.2. The FBAThet free Test
A somewhat hidden/under evaluated constraint of FBAThet is that the null hypothesis forces the transmission probabilities in both groups to be 0.5. Although valid and likely efficient in quite a number of practical situations, this can dramatically impact the power of the test in the study of a secondary outcome. A simple example being that carrying one copy of the allele is sufficient to develop the disease per se but that carrying two alleles will be associated with developing a severe form of the disease.
We propose a new statistic denoted as FBAThet free that relaxes this 0.5 constraint. Consider a diallelic locus (A and![]() ) and denote
) and denote ![]()
![]() the number of transmissions of allele A from
the number of transmissions of allele A from ![]() heterozygote parents to
heterozygote parents to
their children with phenotype ![]()
![]() . Then
. Then ![]() is the mean number of transmission of allele A
is the mean number of transmission of allele A
from ![]() heterozygote parents to affected children (whether
heterozygote parents to affected children (whether ![]() or
or![]() ).
).
Whereas in the above-mentioned FBAT and FBAThet tests the expected transmission of the allele of interest
under the null hypothesis of no association is 0.5, in FBAThet free it is![]() . We can calculate
. We can calculate![]() ,
, ![]() and
and ![]()
for FBAT, FBAThet and FBAThet free. The contribution to ![]() of each transmission of an allele
of each transmission of an allele ![]() from any
from any
![]() parent is 1/2 in FBAT and FBAThet, and
parent is 1/2 in FBAT and FBAThet, and ![]() in FBAThet free. Similarly, its contribution to
in FBAThet free. Similarly, its contribution to ![]() is 1/4 in FBAT and FBAThet, and
is 1/4 in FBAT and FBAThet, and ![]() in FBAThet free (Figure 1). Note that for all three statistics, the expectancy
in FBAThet free (Figure 1). Note that for all three statistics, the expectancy
and variance of a trio including two heterozygote parents are twice those of a trio with only one heterozygote
parent. Symmetrically, ![]() heterozygote parents transmitting allele
heterozygote parents transmitting allele ![]() each contributes for 1/2 and
each contributes for 1/2 and ![]() to
to![]() , and for 1/4 and
, and for 1/4 and ![]() to
to ![]() in FBAT or FBAThet and FBAThet free, respectively. Then with
in FBAT or FBAThet and FBAThet free, respectively. Then with ![]() and
and![]() , we have:
, we have:
![]()
It is shown in Appendix C that FBAThet free is a Pearson’s chi-squared test. In summary, the hypotheses of the FBAThet free test can be written as:
![]()
![]()
As opposed to FBAT and FBAThet, the implicit/hidden 0.5 constraint has disappeared.
3.3. Comparison of FBAThet and FBAThet free
To illustrate the magnitude of the differential power of FBAThet and FBAThet free, we could have gone for large simulation studies. However, we show analytically in Appendix D that:
![]()
The distribution of ρ according to ![]() is shown in Figure 2. As an example, consider a sample of 300 trios
is shown in Figure 2. As an example, consider a sample of 300 trios
with an affected child (150 ![]() and 150
and 150![]() ), all with one herterozygote parent. Consider the mean transmis-
), all with one herterozygote parent. Consider the mean transmis-
sion of allele A is 0.7 in ![]() and 0.8 in
and 0.8 in![]() . Then
. Then![]() ,
, ![]() ,
, ![]() and
and![]() ,
,
![]() and.
and.
When there is an equivalent number of transmissions of alleles ![]() and
and ![]() from
from ![]() heterozygote parents
heterozygote parents
to their children, ![]() and
and![]() . In practice, this is observed when the mean transmission of allele
. In practice, this is observed when the mean transmission of allele
![]() among all affected individuals
among all affected individuals ![]() is 0.5. In that particular case,
is 0.5. In that particular case,![]() . In all other cases,
. In all other cases, ![]() and
and ![]() as shown in Figure 3.
as shown in Figure 3.
4. Discussion
Family-based association studies have gained popularity to dissect the genetic architecture of complex traits and FBAT is likely the most popular tool to perform such studies. We have shown that at first glance it can be conveniently used to test for secondary outcomes, e.g. genetic heterogeneity between severe and non-severe forms of a disease. As an example, in a sample of trios, one can weight each “sub-phenotype” (severe and non-severe) by the inverse of the variance of each statistic. We called this test FBAThet, for which the null and
alternative hypotheses are ![]() and
and ![]() or
or![]() , respectively.
, respectively.
However, in the previous test, the transmission probabilities under the null hypothesis are fixed to 0.5 in both groups. This may not be optimal in the context of secondary outcomes when the transmission of the tested allele has already been found to significantly differ from 0.5 with respect to the primary outcome. We show that it is possible to relax this constraint by modifying the expectation in the FBAThet statistic so that the test is defined as ![]() and
and![]() , which are the classical hypotheses in the vast majority of homogeneity tests. This new test, FBAThet free, is proven to be equivalent to a classical test for homogeneity. FBAThet free is the most powerful test when the mean transmission to affected children (
, which are the classical hypotheses in the vast majority of homogeneity tests. This new test, FBAThet free, is proven to be equivalent to a classical test for homogeneity. FBAThet free is the most powerful test when the mean transmission to affected children (![]() , primary outcome) is not 0.5. Stated differently, each time an allele is found associated with the disease per se, FBAThet free will be the most powerful to detect heterogeneity between the transmission rates of this allele across the modalities of the secondary outcome.
, primary outcome) is not 0.5. Stated differently, each time an allele is found associated with the disease per se, FBAThet free will be the most powerful to detect heterogeneity between the transmission rates of this allele across the modalities of the secondary outcome.
For sake of simplicity, we have derived our main statistic FBAThet free in the context of the analysis of a diallelic marker under an additive genetic model in a sample of trios with no missing parental data. However, generalization to other genetic models and more complex family structures should be possible by using, for a given marker, the estimated mean transmission of the allele under study among affected individuals, in preference to the actual 0.5 that prevents testing![]() . By doing so, one will be able to take advantage of all the features of FBAT ranging from the analysis of all kinds of phenotypes to the simultaneous testing of several alleles either in a classic multivariate way or taking into account the phase through haplotypic analysis.
. By doing so, one will be able to take advantage of all the features of FBAT ranging from the analysis of all kinds of phenotypes to the simultaneous testing of several alleles either in a classic multivariate way or taking into account the phase through haplotypic analysis.
Acknowledgements
We thank Laurent Abel, Jean-Laurent Casanova and all members of the Epidemiological Group for their support
![]()
Figure 3. Power of FBAThet vs. FBAThet free according to the mean transmission rate of the tested allele among the affected children.
and constructive criticism. JG is funded by the Fondation pour la Recherche Médicale, and QV by the Institut Imagine. This work was supported by the Programme Blanc de l’Agence National de la Recherche.
Appendix A. Proof That Coding ![]() and
and ![]() Is Equivalent to
Is Equivalent to ![]() and
and ![]() under an Additive Genetic Model
under an Additive Genetic Model
Let ![]() and
and ![]() be the number of trios with phenotype
be the number of trios with phenotype ![]() and
and![]() , and
, and ![]()
![]() the number of trios with double
the number of trios with double ![]() or single
or single ![]() heterozygote parent
heterozygote parent![]() . Let
. Let ![]() be the number of heterozygote parents. Then
be the number of heterozygote parents. Then
![]()
Let ![]() and
and ![]() be the unitary variance for trios with 1 or 2 heterozygote parents.
be the unitary variance for trios with 1 or 2 heterozygote parents.
For FBAT and FBAThet, ![]() and
and![]() . Then
. Then
![]()
Given that![]() , coding
, coding ![]() and
and ![]() is equivalent to
is equivalent to ![]() and
and ![]() for FBAT and FBAThet.
for FBAT and FBAThet.
For FBAThet free, ![]() and
and![]() . Then
. Then
![]()
Then coding ![]() and
and ![]() is also equivalent to
is also equivalent to ![]() and
and ![]() for FBAThet free.
for FBAThet free.
Appendix B. Proof That ![]() Is the Offset That Minimizes the Variance under an Additive Genetic Model
Is the Offset That Minimizes the Variance under an Additive Genetic Model
Let ![]() be the offset.
be the offset.
![]()
With the same notations as in Appendix A,
![]()
For FBAT, ![]() ,
, ![]() and
and
![]()
and ![]() is obtained for
is obtained for ![]()
For FBAThet free, ![]() ,
, ![]() and
and
![]()
and ![]() is also obtained for
is also obtained for ![]()
Appendix C. Proof That FBAThet free Is a Pearson’s ![]()
With the notations of the manuscript, let us write the table of contingency of the transmission of alleles A and a in two phenotypic groups.
![]()
Appendix D. Proof That FBATfree = ρFBAThet free
With the notations used in the main text, for FBAThet ,
![]()
![]()
![]()
with ![]()
NOTES
*Corresponding author.
![]()
1More precisely, in the general case, the null hypothesis of FBAT is “no association OR no linkage” and therefore the alternate hypothesis is “association AND linkage”. H0 can be written as a composite hypothesis: “no association AND no linkage” ∪ “no association AND linkage” ∪ “association AND no linkage”. In the particular case of a sample limited to trios, there is no linkage information, and the hypotheses are: H0 = association, H1 = no association.
2FBAThet can be implemented in FBAT by using the offset option “-o” while coding