Global Convergence Property with Inexact Line Search for a New Hybrid Conjugate Gradient Method ()

1. Introduction
In unconstrained optimization, we minimize an objective function that depends on real variables with no restrictions at all on the value of these variables. The unconstrained optimization problem is stated by:
(1)
where
is a real vector with
component and
is a smooth function and its gradient g is available [1]. A nonlinear conjugate gradient method generates a sequence
Starting from an initial guess
Using the recurrence
(2)
where
is the positive step size obtained by carrying out a one dimensional search, known as the line searches [2]. Among them, the so-called strong wolf line search conditions require that [3] [4].
, (3)
(4)
where
, is to find an approximation of
where the descent property must be satisfied and no longer searching in the direction when
is far from the solution. Thus by strong Wolfe line search conditions we in herit the advantages of exact line search with inexpensive and low computational cost [5].
The search direction
is generated by:
(5)
where
and
is the gradient and conjugate gradient coefficient of f(x) respectively at the point
. The different choices for the parameter
correspond to different conjugate gradient methods. The most popular formulas for
is Hestenes Stiefel method (HS), Fletcher-Reeves method (FR), Polak-Ribiere- Polyak method (PR), conjugate―Descent method (CD), Liu―Storey method (LS), and Dai-Yuan method (DY), etc
These methods are identical when f is a strongly convex quadratic function and the line search is exact, since the gradient are mutually orthogonal, and the parameters
in these methods are equal. When applied to general nonlinear function with inexact line searches, however, the behavior of these methods is marked different [1]. We are going to summarize some well known conjugate gradient method in Table 1.
An important class of conjugate gradient methods is the hybrid conjugate gradient algorithms. The hybrid computational schemes perform better than the classical conjugate gradient methods. They are defined by (2) and (5) where the parameter
is computed as projections or as convex combinations of different conjugate gradient methods [14].
We are going to summarize some well known hybrid conjugate gradient method in Table 2.
We propose a new hybrid CG method based on combination of MMWU [24] and RMAR [25] conjugate gradient methods for solving unconstrained optimization method with suitable conditions. The corresponding conjugate gradient parameters are
(6)
and
(7)
![]()
Table 1. Some well known conjugate gradient coefficients.
![]()
Table 2. Hybrid conjugate gradient methods.
We defined the parameter
in the proposed method by:
(8)
Observe that if
, then
, and if
, then
.
By choosing the appropriate value of the parameter
In the convex combination, the search direction
of our algorithm not only is the Newton direction, but also satisfies the famous DL conjugate condition proposed by Dai and Liao [26]. Under the strong Wolfe line search conditions, we prove the global convergence of our algorithm. The numerical results also show the feasibility and effectiveness of our algorithm.
This paper is organized as follows. Section 2 we introduce our new hybrid conjugate gradient method (HFG), and we obtain the parameter
using some approaches and give us a specific algorithm. Section 3, we prove that it generates direction satisfying the sufficient descent condition under strong Wolfe line search conditions. The global convergence property of the proposed method is established in Section 4. Some numerical results are reported in Section 5.
2. A New Hybrid Conjugate Gradient Method
In this section, we will describe a new proposed hybrid conjugate gradient method. In order to obtain the sufficient descent direction, we will compute
as follows. We combine
and
in a convex combination in order to have a good algorithm for unconstrained optimization.
The direction
is generated by the rule
(9)
where
defined in (8), the iterates
of our method are computed by means of the recurrence (2), where the step size
Is determined according to the strong Wolf conditions (3) and (4).
The scale parameter
satisfying
, which will be determined in a specific way to be described later. Observe that if
, then
, and
If
, then
. On the other hand, if
, then
is a convex combination of
and
.
From (8) and (9) it is obvious that:
, (10)
Our motivation to select the parameter
in such a manner that the defection
given in (10) is equal to the Newton direction
. There for
(11)
Now multiplying (11) by
from the left, we get
Therefore, in order to have an algorithm for solving large scale problems we assume that pair
satisfies the secant equation
(12)
From (12), we get
Denoting
we get
after some algebra, we get
(13)
Now, we specify a complete hybrid conjugate gradient method (HFG) which posses some nice properties of conjugate gradient and Newton method.
Algorithm HFG
Step 1: Select
,
, set
. Compute
and
, set
.
Step 2: Test the stopping criteria, i.e. if
, then stop.
Step 3: Compute
by strong Wolfe line search conditions in (3) & (4).
Step 4: Compute
,
. Compute
And
Step 5: If
then set
. If
, then set
, otherwise compute
as (13).
Step 6: Compute
by (8).
Step 7: Generate
Step 8: If the restart criteria of Powell
, is satisfied, then set
, otherwise define
Step 9: Set
, and continue with step 2.
3. The Sufficient Descent Condition
In this section, we are going to apply the following theorem to illustrate that the search direction
Obtained by hybrid FG satisfies the sufficient descent condition which plays Avit of role in analyzing the global convergence.
For further considerations we need the following assumptions
3.1. Assumption
The level sets
are bounded.
3.2. Assumption
In a neighborhood N of S, the function f is continuously differentiable and its gradient is Lipschitz continuous, i.e., there exists a constant
, such that
Under these assumptions of if there exists a positive constant (
&
) & such that
[27].
Theorem.
Let the sequences
and
be generated by a hybrid FG method. Then the search direction
satisfies the sufficient descent condition:
(14)
where
, with
.
Proof. We shall show that
satisfies the sufficient descent condition holds for
, the proof is a trivial one, i.e.
and so
. Now we have
i.e.
We can rewrite the above direction by the following manner:
.
So,
,
After some arrangement, we get
(15)
Multiplying (15) by
from the left, we get
Firstly, if
, then
, we are going to prove that the sufficient descent condition holds for MMWU method in the presence of the strong Wolfe line search condition, because in [24] they proved this method satisfied the sufficient descent condition with exact line search.
i.e.
(16)
Since,
and
(17)
Applications (17) in (16), we get
(18)
where
, with
.
So, it is proved that
satisfies the sufficient descent condition.
Now let
then
, we are going to prove that the sufficient descent condition holds for RMAR method in the presence of the strong Wolfe line search condition because in [25] they proved this method satisfied the sufficient descent condition with exact line search.
Multiplying the above equation from left by
we get
.
In [25], they proved that
(19)
Used (17), and (19) the direction become
(20)
where
with
and
.
So, it is proved that
satisfied the sufficient descent condition.
Now, we are going to prove the direction satisfy the sufficient descent condition when
, firstly for
We have from Lipschitz condition
and
with a mathematical calculation, we get
Let
(21)
Now, secondly for
From (19), Lipschitz condition
and
, we get
Since
, so
where
(22)
From (18), (20), (21) and (22) we get
with
and
.
So, it is proved that
Satisfied the sufficient descent condition.
4. Converge Analysis
Let Assumption 2.1 and 2.2 hold. In [26] it is proved that for any conjugate gradient method with strong Wolfe line search conditions, it holds:
4.1. Lemma
Let Assumption 2.1 and 2.2 holds. Consider the method (2) and (5) where the
Is a descent direction and αk is received from the strong wolf line search. If
.
Then
.
4.2. Theorem
Suppose that assumption 2.1 and 2.2 holds. Consider the algorithm HFG were
and
is obtained by the strong Wolfe line search and
is the descent direction. Then
.
Proof. Because the descent condition holds, we have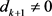 . So using lemma 3.1, it is sufficient to prove that
. So using lemma 3.1, it is sufficient to prove that 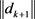 is bounded above. From (10).
is bounded above. From (10).
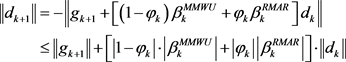
They proved that in [24] and [25].
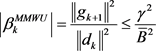 ,
,
And
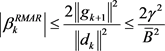 .
.
Now for
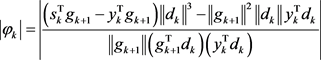 ,
,
By (4), we have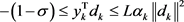 .
.
Since 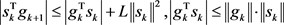 and
and
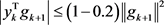 ,
,
with some mathematical calculation, we get
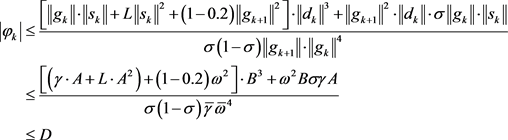
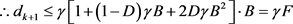
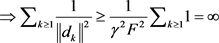
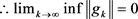
5. Numerical Experiments
In this section we selected some of test functions in Table 3 from CUTE library, along with other large scale optimization problems presented in Andrei [28] [29] and Bongartz et al. [30].
All codes are written in double precision FORTRAN Language and compiled Visual F90 (default compiler settings) on a Workstation Intel Pentium 4. The value of 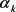 is always computed by cubic fitting procedure.
is always computed by cubic fitting procedure.
We selected 26 large scale unconstrained optimization problems in the extended
![]()
Table 4. The percentage performance of the proposed methods.
![]()
![]()
Figure 1. The comparison between the three methods.
or generalized form. Each problem was tested three times for a gradually increasing number of variables: N = 1000, 5000 and 10,000, all algorithms implemented the strong Wolfe line search (3) and (4) conditions with ![]() and
and ![]() and the same stopping criterion
and the same stopping criterion ![]() is used.
is used.
In some cases, the computation stopped due to the failure of the line search to find the positive step size, and thus it was considered as a failure denoted by (F).
We record the number of iteration calls (NOI), the number of function evaluations calls (NOF), and the dimensions of test problems calls (N), for the purpose of our comparisons.
Table 3 gives the comparison depending in the NOI and NOF between![]() ,
, ![]() and the proposed method
and the proposed method![]() .
.
Table 4 gives the percentage performance of the proposed methods ![]() against
against ![]() and
and![]() . We have seen that
. We have seen that![]() . Method saves (NOI 0.8%), (NOF 7.6%), and
. Method saves (NOI 0.8%), (NOF 7.6%), and ![]() method saves (NOI 28.7%), (NOF 40.0%) compared with
method saves (NOI 28.7%), (NOF 40.0%) compared with ![]() method.
method.
While Figure 1 gives the comparison between![]() ,
, ![]() and
and![]() , using a well-known Wood test function.
, using a well-known Wood test function.