Approximation Maintenance When Adding a Conditional Value in Set-Valued Ordered Decision Systems ()
1. Introduction
For the three cases of dynamic changes, the study of attribute values mainly focuses on the problem of coarsening and refining, which is the result of a certain change of an attribute value, and the attribute value domain does not change. However, when a condition value has changed, it will cause more than one attribute value to change. Luo [1] proposed a strategy and algorithm to quickly update approximations in set-valued ordered information systems for adding new condition values and removing old condition values to attribute values when the attribute value domain is changed. Each traversal in this approach requires a lookup of all objects. We find that we can preclassify all objects to reduce the time required for each traversal, and then consider the changes in the knowledge grains separately on the basis of classification.
The rest of the paper is organized as follows: in Section 2 some basic concepts about set-valued dominance relations rough set models are introduced. Section 3 describes dynamic update strategies for dominance sets and approximations in set-valued ordered decision systems when attribute values are changed. Section 4 introduces dynamic update algorithms in set-valued ordered decision systems when the attribute value is changed. In Section 5 the algorithms are evaluated experimentally by selecting some suitable datasets. In section 6 the paper concludes with conclusions and topics for further research.
2. Literature Survey
In 1982, Pawlak first proposed Rough Set Theory (RST) [2] , a new mathematical tool mainly used to solve uncertain and imprecise mathematical problems. Set-valued information systems [3] are an extended model of traditional single-valued information systems, which can be used to handle missing values in incomplete information systems.
When attribute values change dynamically, Chen [4] first proposed the definition of coarsening and refining for dynamic changes in attribute values, and studied approximations maintenance when attribute values are coarsened and refined. Chen [5] divided attribute values into horizontal refining and vertical refining, proposed the definition of horizontal refining and vertical refining of attribute values, and discussed the principle of approximation updating under variable precision. Luo [6] proposed an incremental algorithm to formalize the dynamic characteristics of knowledge granules in hierarchical multi-criteria decision systems by refining and coarsening the dynamic characteristics of knowledge granules with the help of attribute value taxonomies. Chen [7] studied the approximation updating of attribute values during coarsening and refining with the help of extended feature dominance links in incomplete information systems. Li [8] performed approximation maintenance of dominance rough set with variation in the dominance matrix.
Luo [8] analyzed the approximation update problem caused by attribute value changes in set-valued ordered decision systems. Wang [10] investigated the problem of simultaneous changes in object sets and attribute values in multidimensional dynamics, and proposed an incremental algorithm for approximation maintenance using the dominance-feature matrix approach. Luo [1] solved the knowledge updating problem caused by dynamic changes in condition values in set-value decision systems, and has given updated theories and algorithms for dynamically updating approximations of condition values with time.
3. Methods and Materials
3.1. Description of the Dataset
In this section, we briefly review some fundamental conceptions of set-valued ordered decision systems [11] .
Definition 1 [11] . Let
be an information decision system, where
is a set of all objects, known as the universe.
, where C is the collection of conditional attributes with preference relations, d is the decision attribute, and
.
, where
is a collection of conditional attributes C for all values and
is a collection of decision attributes d for all values.
is an object attribute mapping, which is a set value mapping. If all conditional attributes are in increasing or decreasing preference, then S is said to be a set-valued ordered decision system.
Example 1. Table 1 shows a set-valued ordered decision system
, where
,
,
,
.
In Table 1,
indicates that x2 will be read in English, French, and German, and
indicates that x1 will be read in French only. It can be concluded that x1 does not read as much language as x2. That is, in the attribute a1, object x2 is at least dominant to object x1. This type of set-valued ordered decision system is called conjunctive set-valued ordered decision system (C-SODS) [11] .
In C-SODS, the conjunctive dominance relation can be defined based on the set inclusion relation.
Definition 2 [11] . Let
be a C-SODS.
, the
![]()
Table 1. A set-value ordered decision system.
conjunctive dominance relation RB on the domain U is defined as
,
It is clear that the conjunctive dominance relation satisfies reflexive, transitive, and not symmetry.
Definition 3 [11] . Let
be a C-SODS.
,
two knowledge granules of x are called B-dominating set and B-dominated set, which are respectively defined as follows
,
.
Definition 4 [11] . Let
be a C-SODS. If the U can be divided into m equivalence sets, the equivalence sets are called decision sets. It can be expressed as:
, where
.
Definition 5 [11] . Let
be a C-SODS. If the U can be divided into m decision sets according to the decision attribute d, upward union
and downward union
can be defined as:
,
,
.
where
means “x belongs to at least
”;
means “x belongs to at most
”.
Definition 6 [11] . Let
be a C-SODS, for any
, the lower and upper approximations of
are respectively defined as follow:
Definition 7 [11] . Let
be a C-SODS, for any
, the lower and upper approximations of
are respectively defined as follow:
Example 2. Continuing from Example 1, we can use the above definition to further compute the dominating and dominated sets, as well as the upper and lower approximations of the set-valued ordered decision system.
Dominating and dominated sets:
,
,
,
,
.
,
,
,
,
.
Decision classes:
,
Upward and downward unions of decision classes:
,
,
Approximations:
3.2. Incremental Approximations Updating Method When Adding a Conditional Value
With the variation of an information system, the structure of information granules in the information system may vary over time which leads to the change of knowledge induced by RST. In a dynamic decision system, the attribute value domain can be updated due to different requirements, such as adding new conditional values, removing old conditional values, or correcting errors. Changes in the attribute value domain can directly lead to changes in the preference relation between any pair of attributes of two objects, resulting in corresponding changes in knowledge granules.
Example 3. From Table 1, we consider
. If we add Chinese to VB, we will also use Chinese as a language criterion to judge Reading and Writing. Then, the attribute value domain will be updated to
. At this point, Table 1 is updated to Table 2. x1 is updated to {F, C} under a1 in Table 2, so after updating, x1 and x2 are not comparable in Reading.
When the preference relation changes, the discovered knowledge may become invalid, or some new implicit information may emerge in the whole updated information system. Rather than restarting from scratch by the non-incremental
![]()
Table 2. The condition value added into the set-value ordered decision system.
or batch learning algorithm for each update, developing an efficient incremental algorithm to avoid unnecessary computations by utilizing the previous data structures or results is thus desired.
In this section, we discuss the variation of approximations in the dynamic C-SODS when the conditional value evolves over time while the object set and attribute set remain constant. For convenience, we assume the incremental learning process lasts two periods from time t to time t + 1.
and
represent the set-valued ordered decision system at time t and time t + 1, respectively.
denotes adding a conditional value.
In the following,
is denoted the updated attribute value domain of attribute a at t + 1, and
is the conditional value that is added to
, where
.
Definition 8. For any
,
, where
denotes the set of all objects with condition values added, and
denotes the set of objects without condition values added. If
, then
; if
, then
.
When
changes, the dominating sets and dominated sets of y need to be updated. If x at time t dominates y, when y adds
at time t + 1, and x does not contain
. Thus, x no longer dominates y.
Property 1. If any
, then
.
Proof. If
,
, then
. If
,
.
The approximation sets are close to the dominating sets and dominated sets. According to Property 1, only the dominating sets have changed, thus we just need to update
and
.
Proposition 1. (1) If
, and
,
, then
.
(2) If
, and
,
, then
.
Proof. (1) According to the Property 1, let
. Clearly, if
, and
, then
.
(2) According to Property 1, if
, then
.
Similarly to y, if y is dominated by x at time t, then it is no longer dominated by x when y adds
at time t + 1 and x does not contain
. Thus, y is no longer dominated by x.
Property 2. If any
, then
.
Proof. This Property can be proved by the same method as employed in Property 1.
Similar to Proposition 1, only the dominated sets changed in Property 4. We just need to discuss the updating theories for the
and
.
Proposition 2. (1) If
, and
,
, then
.
(2) If
, and
,
, then
.
Proof. This proposition can be proved by the same method as employed in Proposition 1.
Example 4. Continuing from Example 3, we can use Properties 1 - 4 and Propositions 1 - 4 to update the dominating sets and dominated sets, and approximations.
Updating dominating sets and dominated sets:
,
,
.
,
,
,
,
,
.
Updating approximations:
,
,
,
.
,
,
,
.
3.3. Static and Incremental Algorithms for Adding a Conditional Value in Dynamic C-SODS
3.3.1. Static Algorithm in C-SODS
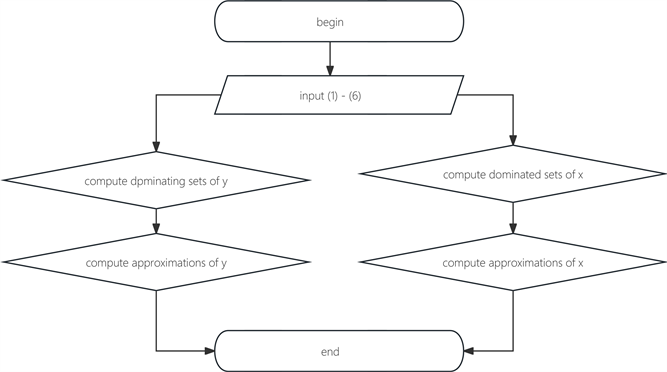
In this section, we propose a static algorithm in C-SODS, namely Algorithm 1.
3.3.2. Incremental Algorithm When Adding a Conditional Value in C-SODS
In this section, we propose an approximation updating algorithm in C-SODS based on adding a conditional value, namely Algorithm 2.
4. Experimental Results
In this section, we perform the following experiments to test the performance of the proposed incremental algorithm for approximations when adding a conditional value. However, datasets cannot be found the set-valued in existing databases, we selected 6 datasets with missing values as shown in Table 3 in UCI [12] , and used the set of all missing values as a special case. All experiments are conducted on a personal computer with 11th Gen Intel(R) Core(TM) i5-11400H
2.69 GHz processor, 16.0 GB of RAM, and Windows 10 Home Edition. Algorithms based on python 3.9.12.
The purpose of the experiments in this section is to show the computation time of the static algorithm and the incremental algorithm for approximation maintenance when adding a conditional value on different number of object sets, and to prove that our proposed incremental algorithm is faster at updating approximations by comparing the computation time of the two algorithms. To better compare the time consumption of the two algorithms, we divide each dataset into ten equal parts. The first part is treated as dataset 1, the first and second parts are treated as dataset 2, the first, second and third parts are treated as dataset 3, …, and the data of all parts are treated as dataset 10. All datasets obtained from these reorganizations will be used to calculate the time consumption of the two algorithms.
In this subsection, when a conditional value is added, the attribute value changes accordingly. We compare the time consumption of the static algorithm and the incremental algorithm on approximation updating for the 6 datasets in Table 4. First, for each dataset, we execute the static algorithm to compute dominating sets, dominated sets and approximations, and save all these results. Then, when a conditional value is added, we randomly select 10% attribute values in each dataset to add the conditional value, and execute the static algorithm and incremental algorithm procedures to update the approximations, respectively.
The specific time taken by the two algorithms to add condition values for approximation updating with the change in dataset size is shown in Table 4, and the unit of experimental results is second (s).
The experimental results in Table 4 show that when a conditional value is added, both static and incremental algorithms show an upward trend in the time taken to compute approximations when the base of the object sets increases. The time consumption of the static algorithm is significantly higher than the incremental algorithm, and the time difference becomes larger with the increase of
![]()
Table 4. Time consumption of static and incremental algorithms when adding a conditional value with different sizes of data.
the data set. Therefore, our proposed incremental method is more efficient than the static algorithm in terms of computational efficiency.
To compare the difference in computational efficiency between the two algorithms, based on Table 4, we draw two trend lines to represent the changes in the two methods. Figure 1 shows a more detailed trend for both algorithms. In each subplot of Figure 1, the x coordinate is related to the size of the dataset (starting from the once dataset to the tenth dataset), and the y coordinate is related to the running time of computing the approximations. Diamond marking and circular marking indicate the computational efficiency of incremental and static methods, respectively. From Figure 1, it can be seen that the computation time of the two algorithms increases as the amount of data increases. However, the incremental algorithm is much faster than the static algorithm due to the additional learning of the original information, which effectively reduces the time consumption of repeated computation. The more data sets vary, the greater the difference. To summarize, incremental algorithms are more efficient than static algorithms in terms of computation time when adding a conditional value.
5. Conclusion
In rough set theory, approximations plays a vital role in the processes of knowledge acquisition and decision-making. With the advent of the big data era, the volume of information is growing at an unprecedented rate, leading to dynamic changes in the knowledge obtained from rough sets over time. Using incremental methods for approximation maintenance can avoid redundant comparisons
![]()
Figure 1. Comparison of static and incremental algorithms when adding a conditional value in different sizes of data.
of the original information and reduce computation time. In this paper, we extend the traditional single-valued information system to a set-valued ordered decision system, investigate the problem of updating approximations when adding a conditional value from an attribute value domain, and propose corresponding updating theories and algorithms. In this paper, we specifically consider changes which adding a conditional value in set-valued ordered decision systems. In future research, we plan to consider the change which removing a conditional value in set-valued ordered decision systems.
Acknowledgements
This work was supported by Open Fund of Sichuan Provincial Key Laboratory of Artificial Intelligence (2018RYJ02), Talent Introduction Project of Sichuan University of Science and Engineering (2019RC08) and University Student Innovation and Entrepreneurship Training Program Project, Sichuan University of Science and Engineering (cx2022147).
Appendix
Algorithmic 1. Flow Chart
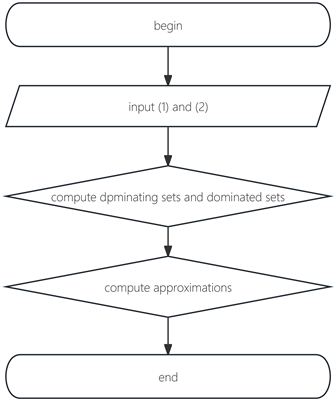
Algorithmic 2. Flow Chart