Research on the Teaching of the Character Non-Formation Components of Commonly-Used Characters in Modern Chinese and Related Problems ()
1. Introduction
The word-formation unit composed of strokes with the function of assembling Chinese characters, referred to as “components”, such as: 口、氵、亻 (according to Chinese Information Processing-Vocabulary GB/T 12200.2). Components are the basic units of Chinese characters, and they carry the phonetic and semantic information of Chinese characters and have the functions of representing the form and sound, etc. Components combine characters according to different Chinese structures, reflecting the rules of word formation, and components are the most important part of the research on Chinese character formation (Ning Wang, 1997). The number, function and combination of components (position, placement direction, way of connection) are the most important attributes that distinguish each Chinese character. The information content of Chinese characters is mainly reflected by the components.
The component teaching method has been proved to be a more practical and effective method in current Chinese character teaching practice. There are many Chinese characters, but the components that make up Chinese characters are limited. It is much easier to master the components and then learn the hundreds of Chinese characters composed of them. Therefore, whether it is for the Chinese character teaching or Chinese character research, components are a part that cannot be ignored.
Based on the existing research, components can be divided into different categories from different angles. According to whether the components are used as an independent character or not: components can be divided into character formation components and character non-formation components.
(Yonghe Fu, 1991) The components that can be used as single-element characters are called character formation components; the components which are soundless and meaningless are called character non-formation components. (Ning Wang, 2015) Character formation components refer to a component that can not only be an independent character, but also be a part of a character, reflecting the meaning of the structure; Non-character components refer to components that can only be attached to other components to express the meaning, and cannot be used independently to record language; Chinese Character Component Standard of GB 13000.1. Character Set for Information Processing: Character formation components are those which can be used as independent characters, such as “口”、“可”; Character non-formation components are those which cannot be use as independent characters, such as “冂”、“疒” (GF 3001-1997).
Due to various reasons, non-characterized components have not attracted much attention in Chinese character research and practical teaching. This paper takes character non-formation components as the research object, and conducts research from several aspects such as the classification, naming and characters-building ability of character non-formation components, hoping to be a supplement to the teaching and research of Chinese character components.
2. Character Non-Formation Components
2.1. Existing Research on Character Non-Formation Components
Because of the importance of components in teaching, in the formation of structure and in the meaning of Chinese characters, there have been many research results on the naming, division, quantity, function, and teaching of components. However, there are some shortcomings: First, although component teaching is widely used as a method of teaching Chinese characters in practice, the focus of teaching is on character formation components or the character non-formation components which can be used as indexing components (such as: 扌、艹、宀, etc.), but less on other character non-formation components. Second, compared with research on component splitting, component naming, and teaching of character formation components, special research on character non-formation components is relatively weak.
There are three main reasons for the above two problems: Firstly, there are a considerable number of character non-formation components that are not capable of expressing the form, meaning, and the sound, they can only exist as symbolic component (e.g. 丷、 、
、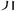 ); Secondly, there are a considerable number of character non-formation components that have not had a unified and fixed name for a long time (e.g. “彳” can be called “双立人”、”双人旁” and some other names, “丷” doesn’t have a commonly used name); The third and more critical point is that many character non-formation components cannot be displayed on the computer through common Chinese character input methods like character formation components do. Therefore, it is difficult for both ordinary teachers and researchers who do not know information processing technology to display or print them in texts and slides (such as:
); Secondly, there are a considerable number of character non-formation components that have not had a unified and fixed name for a long time (e.g. “彳” can be called “双立人”、”双人旁” and some other names, “丷” doesn’t have a commonly used name); The third and more critical point is that many character non-formation components cannot be displayed on the computer through common Chinese character input methods like character formation components do. Therefore, it is difficult for both ordinary teachers and researchers who do not know information processing technology to display or print them in texts and slides (such as: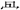 、
、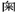 、
、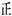 ), even if in officially published journals, many places involving character non-formation components can only be left blank, this will easily cause confusion and confusion to readers, and also hinder further research on character non-formation components.
), even if in officially published journals, many places involving character non-formation components can only be left blank, this will easily cause confusion and confusion to readers, and also hinder further research on character non-formation components.
Character non-formation components are also an important part of Chinese characters. According to Yonghe Fu (1991), the non-formation components (excluding the components which are single element characters) used in the 11,834 standard forms in Ci Hai account for 49.54% of the total number of components used in Ci Hai; According to Hongbing Xing (2005), 515 basic components are used in the 2905 Chinese characters in the Chinese Character Outline, and the proportion of non-formation components (non-basic formation components) also accounts for 44.66%. In his article, Xing Hongbing suggests that there should be different strategies for teaching character non-formation components and character formation components. For formation components, it is necessary to make full use of their characteristics like characterization and independence, but unfortunately there is no research focusing on these aspects. According to Specification of Common Modern Chinese Character Components and Component Names (hereinafter referred to as the “Components Specification”), there are 3500 commonly used characters in modern Chinese. Among them, there are 514 basic components, and 203 non-formation components (commonly used characters that cannot be used independently as Chinese characters) account for 39.49% of all components. Among these non-formation components, 87 of them can be used as indexing components. It can be seen that character non-formation components also play an important role in the composition of Chinese characters. Therefore, making full use of the rationale and systematic nature of non-formation characters to convey the functions and roles of non-formation components can enable foreign learners to better understand the Chinese characters they are learning, which is conducive to increasing their interest in learning and effectively reducing the difficulty of learning Chinese characters.
2.2. Classifications of Character Non-Formation Components
Ning Wang (2015) divides character non-formation components (called “non-character components” in his text) into four categories:
1) A single stroke or group of strokes used as a sign or to indicate a distinction.
These parts cannot exist independently and do not correspond to independent words, and their meaning can only be reflected in the specific context of the word they are used for. For example, “丶” in “刃” means “knife edge”.
2) Non-character pictographic symbols preserved from ancient script.
For example, “果” and “番” were originally pictographs of fruit and animal feet respectively, and they are just the same shape as the “田” in “田地”. From the point of view of the meaning of Chinese characters, they are still non-character components.
3) Act as displacement variants of the indexing components.
For example: “刀” is written as “刂” on the right, “水” is written as “氵” on the left, “火” is written as “灬” on the bottom, and “肉” is written as “月” on the left. Most of these non-character components, which were frequently used in the Shuo Wen Jie Zi, were character formation components, but later, for reasons of writing economy and aesthetics, their forms changed and became non-character components. Although they became unable to record the Chinese independently, they corresponded very neatly to the components of the character and had exactly the same conceptual meaning as the corresponding Chinese characters.
4) The symbolic components that have been mutated or glued together and lost their function as proof of something.
For example, the upper part of “夂” in “冬” is the ancient character “终”, which was originally a character. Now, the standard script character becomes a symbolic component. The upper part of “春” is originally from “艹” and “屯”, but after they are glued together, it becomes a character non-formation components.
The above classification summarizes the evolution of character non-formation components from the perspective of the character source and historical development. Through analysis, we recognize that: first, it is very important to identify the components of Chinese characters, both character non-formation components and character formation components, which always assumed certain responsibilities at the beginning of the formation of Chinese characters, either referring to things, or pictographs, or sound or meaning… We should try to uncover such associations, respect history, and maintain the scientific and systematic nature of Chinese characters; Secondly, since modern Chinese characters have changed a lot compared with their ancient forms, which makes it very difficult for us to trace their sources and some Chinese teachers do not always have such knowledge and ability, this paper, from the perspective of teaching practice and based on the principle of “respecting the character source and the graphic form”, integrates the above four categories and divides the character non-formation components of modern commonly used characters into the following three categories, in order to apply them to the teaching of modern commonly used characters.
1) Semantic character non-formation components include non-character pictograms inherited from ancient scripts and the displacement variants that act as indexing components. For example, “刂” in “削” means “刀”, which is a component of indexing component displacement variant; however, “刂” is a variant of “水” in the ancient character “俞”, and “刂” is also a component of non-character pictographic symbols. For people without a graphology background, it is not easy to distinguish the differences, and because both kinds of components can imply the meaning of the character, they are classified into one category. According to statistics, there are 50 such components in 203 components. Another example: “疒” (病bìng), “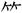 ” (竹 zhú).
” (竹 zhú).
2) Symbolic character non-formation components include components that serve as signs or indicate distinctions, and symbolic components that have been mutated or bonded and have lost their function of justification. According to statistics, there are 100 such components among 203 components. For example: “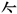 ” (upper right corner 临), “
” (upper right corner 临), “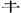 ” (the bottom of举jǔ).
” (the bottom of举jǔ).
3) There is a category of components which are independent characters in ancient scripts, but became character non-formation components in modern times, and are no longer used as independent characters in modern commonly used characters. They are now character non-formation components. According to statistics, there are 53 of these parts in 203 parts. For example, “弋” (in 弋yì/代dài), “厶” (in 厶sī/私sī).
3. The Naming of Character Non-Formation Components
According to Danling Peng (1991), the memory effect of language elements is related to the ability of their components to be pronounced, and the success rate of memory is high if the components can be pronounced. (Yonghe Fu, 1991) The benefit of having standardized names for components is even greater for Chinese character teaching. This is because words that can be named after disassembling can make Chinese character teaching both auditory and visual, thus helping to memorize Chinese characters and reducing reading and writing errors. (Yonghua Cui, 1997) The more mnemonic units that can be named after Chinese characters being disassembled, the better it is for learning Chinese characters. Therefore, having fixed and standardized names is very important for component teaching.
The long-term lack of unified and standardized names is also one of the important reasons why character non-formation components are not taken seriously in teaching and research, and why they are difficult to teach and study. According to Yonghe Fu (1991), of the 11,834 standardized Chinese characters in Ci Hai, 43 of the 321 stroke groups(called character non-formation components)without sound and meaning have commonly used names, while the other 278 parts have no names and cannot be described. Among these 43 character non-formation components that have names, based on a statistical analysis of eight kinds of data, there are 30 components that have more than two names at the same time. Therefore, he believes that “there are a considerable number of character non-formation components whose names are not yet fixed, and there are also some character non-formation components without names. For the character non-formation components that do not have fixed names, they should be standardized, and for the character non-formation components that do not yet have names, they should be named with the benefit of collective wisdom”.
Until the promulgation and implementation of the “Components Specification”, the components finally have a unified, standard naming. In the “Components Specification”, the principle of the naming of the components is based on the pronunciation of their single words (for polyphonic characters, the more commonly used pronunciation is chosen). For the naming of character non-formation components, it is relatively complex, in order to be more intuitive, please see Table 1.
For the naming principles, there are two points need special attention (the last two, marked with “*”).
1) The difference between “×头” and “×字头”.
“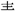 ” is called “青字头”, “爫” is called “爪头”. The difference between these two names is whether the component itself is a character non-formation component. “
” is called “青字头”, “爫” is called “爪头”. The difference between these two names is whether the component itself is a character non-formation component. “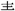 ” itself cannot be used as a free character, but only as a component, and it only locates in the upper part of a certain word, so it is called “青字头”, the “头 (head)” of “青”. “爫” itself is transformed from the Chinese character “爪”, which is equivalent to the character “爪”. When used as a free character, it is “爪”, but when it locates in the upper part of a certain word, it is “爫”, so it is “爪头”, not the “头 (head)” of the Chinese character “爪”.
” itself cannot be used as a free character, but only as a component, and it only locates in the upper part of a certain word, so it is called “青字头”, the “头 (head)” of “青”. “爫” itself is transformed from the Chinese character “爪”, which is equivalent to the character “爪”. When used as a free character, it is “爪”, but when it locates in the upper part of a certain word, it is “爫”, so it is “爪头”, not the “头 (head)” of the Chinese character “爪”.
“×头” and “×字头” are confusing, so we need to clarify the reason for the naming in order to use them better.
2) So far, using “×省” to name components is the first time in Components Specification. There are six components named in this way: “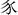 ” in “毅” is “豕省”, “
” in “毅” is “豕省”, “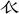 ” in “表” is “衣省”, “
” in “表” is “衣省”, “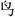 ” in “岛” is “鸟省”, “
” in “岛” is “鸟省”, “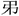 ” in “第” is “弟省”, “耂” in “考” is “老省”, “
” in “第” is “弟省”, “耂” in “考” is “老省”, “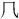 ” in “凤” is “风省”. This way of naming has not been covered in previous Chinese character teaching and research, so many people are not aware of it, and I hope this new way of naming will be gradually accepted and applied.
” in “凤” is “风省”. This way of naming has not been covered in previous Chinese character teaching and research, so many people are not aware of it, and I hope this new way of naming will be gradually accepted and applied.
4. Characters-Building Ability of Character Non-Formation Components
Bisong Lv (1994) points out that “commonly used and strong word formation ability” are the criteria for word selection; Hesheng Zhang (2006): In language teaching, there are two main criteria for word selection: commonly used and strong word formation ability. The so-called “word formation ability” is the ability
![]()
Table 1. The principle of the naming of character non-formation components
of a word or Chinese character to form a new word with other words. The more words it creates, the stronger word formation ability it has. In his analysis of all the Chinese characters in the Xiandai Hanyu Pinlv Cidian, Baoru Chang (1988) take the “word formation ability” as one of his research objects. According to how many new words a word can create, he called the first 1000 words with the strongest word formation ability “the backbone of the 31,000 words in Pinlv Cidian”.
For components, there is also such a measurement standard, that is “characters-building ability”, the statistical data of which we call “character formation quantity”. (Hongbing Xing, 2005) The characters-building ability of components is measured by how many characters they can form. A high number of “character formation quantity” indicates a strong “characters-building ability”. Therefore, the “characters-building ability” can be one of the important reference indicators for selecting components that are commonly used.
Components Specification gives a table about the number of characters created by common modern Chinese character components. The number of how many characters, which are within the range of 3,500 commonly used characters, are formed by 514 components, including character non-formation components and character formation components, are included in that table. In order to know the “characters-building ability” of character non-formation components, we chose 203 character non-formation components and categorized them according to the number of characters they can form, please see Table 2.
Based on Table 2, this paper organizes the character non-formation components into the following four categories:
1) There are 20 character non-formation components which can form greater than or equal 50 characters, we call them “first-level character non-formation components”, as follows (the number in parentheses after each component is the number of how many characters, which are within the range of 3,500 commonly used characters, are formed by the component, and the components which can form the same amount of characters are putted together):
氵(204),扌(197),艹(167),亻(156),宀(104),辶(79),讠(79), 、纟(77),亠(72),冖(70),阝(70),忄、厶、刂(64),钅、夂(59),勹、攵(55)、乂(58)
、纟(77),亠(72),冖(70),阝(70),忄、厶、刂(64),钅、夂(59),勹、攵(55)、乂(58)
These 20 character non-formation components have the strongest characters-building ability and they are the most commonly used ones. 19 of them are radical components (except “乂”), which are mostly indexing component displacement variants of Chinese characters. Except for “ ” and “乂”, these components are all ideographic components and carry the meaning of Chinese characters, such as “宀 (
” and “乂”, these components are all ideographic components and carry the meaning of Chinese characters, such as “宀 (![]() )” which resembles the shape of a house, and most of the characters with this radical are related to houses. For example, “室、宫、家、宽、宅、寝、宿、客、寓、安、宝、宇、宗、容、寒, etc. In teaching, the names of these character non-formation components, the relationship between radical variants and characters need specially explanation, They can not only help understanding and remembering the characters, but also help people use tool books.
)” which resembles the shape of a house, and most of the characters with this radical are related to houses. For example, “室、宫、家、宽、宅、寝、宿、客、寓、安、宝、宇、宗、容、寒, etc. In teaching, the names of these character non-formation components, the relationship between radical variants and characters need specially explanation, They can not only help understanding and remembering the characters, but also help people use tool books.
2) There are 63 character non-formation components which can form more than 10 and less than 49 characters, we call them “second-level character non-formation components”, for example:
![]() (45),
(45),![]() (45),隹(43),
(45),隹(43),![]() (42),丶(39),丷(36),疒(35),
(42),丶(39),丷(36),疒(35),![]() (32),爫、彳、
(32),爫、彳、![]() 、冫(30),囗、犭(29),彡、廾、
、冫(30),囗、犭(29),彡、廾、![]() 、灬(28),
、灬(28),![]() 、卩、
、卩、![]() (12),丬、廴、乛、缶、(11)
(12),丬、廴、乛、缶、(11)
There are semantic components (e.g. 犭), phonetic components (e.g. 隹),
![]()
Table 2. “Characters-building ability” of character non-formation components.
and symbolic components (e.g. ![]() ). There are 47 radical components, and although these components do not enter into the first-level character non-formation components in terms of the number of characters they form, they are very commonly used, e.g., “乛” in “买” which is used very frequently. So, it is important to learn these character non-formation components since they are the component of commonly used Chinese characters.
). There are 47 radical components, and although these components do not enter into the first-level character non-formation components in terms of the number of characters they form, they are very commonly used, e.g., “乛” in “买” which is used very frequently. So, it is important to learn these character non-formation components since they are the component of commonly used Chinese characters.
3) There are 101 character non-formation components which can form more than 2 and less than 9 characters, we call them “third-level character non-formation components”, for example:
The character non-formation components which can form 9 characters:
戋、![]() 、丿、廿
、丿、廿
The character non-formation components which can form 8 characters:
![]() 、
、![]() 、韦、癶
、韦、癶
The character non-formation components which can form 7 characters:
聿、![]() 、
、![]() 、乚
、乚
The character non-formation components which can form 6 characters:
![]() 、
、![]() 、禺、尹
、禺、尹
The character non-formation components which can form 5 characters:
![]() 、
、![]() 、
、![]() 、奂
、奂
The character non-formation components which can form 4 characters:
![]() 、豸、
、豸、![]() 、冘
、冘
The character non-formation components which can form 3 characters:
![]() 、卂、
、卂、![]() 、
、![]()
The character non-formation components which can form 2 characters:
豖、![]() 、
、![]() 、囟
、囟
The main feature of these components is that when we see a certain component, it is easy to associate it with a single character it forms, and the characters in its “character formation quantity” are basically the composite characters formed by the initial single character. For example, we generally associate “![]() ” with “扁”, which is then combined to 8 characters, namely “编、蝙、匾、遍、偏、篇、翩、骗”, so we can regard “
” with “扁”, which is then combined to 8 characters, namely “编、蝙、匾、遍、偏、篇、翩、骗”, so we can regard “![]() ” as the “typical character” of “扁”.This shows us that it is a very systematic and scientific way to link the corresponding Chinese characters through the “typical character” of character non-formation components in teaching.
” as the “typical character” of “扁”.This shows us that it is a very systematic and scientific way to link the corresponding Chinese characters through the “typical character” of character non-formation components in teaching.
4) There are 19 character non-formation components which can form 1 characters, we call them “fourth-level character non-formation components”, for example:
![]() (姊字边)、
(姊字边)、![]() (制字旁)、戉(越字心)、
(制字旁)、戉(越字心)、![]() (殷字旁)、
(殷字旁)、![]() (颐字旁)、彑(彝字头)、曳(拽字边)、
(颐字旁)、彑(彝字头)、曳(拽字边)、![]() (养字头)、
(养字头)、![]() (焉字底)、
(焉字底)、![]() (舞字头)
(舞字头)
These character non-formation components can be considered as “uncommon”components. Components that can only form one Chinese character are quite uneconomical from the economic point of view. This is because, on the one hand, the characters they form are not commonly used characters, on the other hand, these characters are mainly multi-stroke characters, which increases the burden of learners to a certain extent, and on the third hand, they are mainly symbolic components that no longer contribute to the graphic form, pronunciation, and meaning of modern Chinese characters. Therefore, when teaching these components, it is not necessary to emphasize their function; their position in the structure of the Chinese character is more important, so combining names of components to remember the place where the components locate in Chinese characters is more worthy of attention.
5. Conclusion
Character non-formation components are an important part of Chinese character components and should be taken seriously in both Chinese character teaching and character research. This paper sorts out and explores the character non-formation components of common modern Chinese characters from the perspectives of classification, naming and characters-building ability. On the one hand, it can help you understand the historical evolution of non-characterized components and the rationale for their functions; on the other hand, the non-characterized components can be better combined with phonetic appellations to facilitate learners to remember and understand Chinese characters; What’s more, this paper finds out the level of “word formation ability” of non-characterized components. According to this standard, the key teaching points can be given more attention and the teaching efficiency can be improved. In short, I hope this paper can provide some meaningful references for Chinese character teaching research.
Founding
This paper is funded by the general teaching reform project “Research on the Teaching of the Character Non-formation Components of Commonly-used Characters in Modern Chinese and Related Problems” of the Chinese Academy of Beijing International Studies University.