Hierarchical Representations Feature Deep Learning for Face Recognition ()
1. Introduction
Face recognition (FR) is one of the main areas of investigation in biometrics and computer vision. It has a wide range of applications, including access control, information security, law enforcement and surveillance systems. FR has caught the great attention from large numbers of research groups and has also achieved a great development in the past few decades [1] [2] [3]. However, FR suffers from some difficulties because of varying illumination conditions, different poses, disguise and facial expressions and so on [4] [5] [6]. A plenty of FR algorithms have been designed to alleviate these difficulties [7] [8] [9]. FR includes three key steps: image preprocessing, feature extraction and classification. Image preprocessing is essential process before feature extraction and also is the important step in the process of FR. Feature extraction is mainly to give an effective representation of each image, which can reduce the computational complexity of the classification algorithm and enhance the separability of the images to get a higher recognition rate. While classification is to distinguish those extracted features with a good classifier. Therefore, an effective face recognition system greatly depends on the appropriate representation of human face features and the good design of classifier [10].
To select the features that can highlight classification, many kinds of feature selection methods have been presented, such as: spectral feature selection (SPEC) [11], multi-cluster feature selection (MCFS) [12], minimum redundancy spectral feature selection (MRSF) [13], and joint embedding learning and sparse regression (JELSR) [14]. In addition, wavelet transform is popular and widely applied in face recognition system for its multi-resolution character, such as 2-dimensional discrete wavelet transform [15], discrete wavelet transform [16], fast beta wavelet networks [17], and wavelet based feature selection [18] [19] [20].
After extracting the features, the following work is to design an effective classifier. Classification aims to obtain the face type for the input signal. Typically used classification approaches include polynomial function, HMM [21] [22], GMM [23], K-NN [23], SVM [24], and Bayesian classifier [25]. In addition, random weight network (RWN) is proposed in some articles [26] [27] and there are also other kinds of neural networks used as the classifier for FR [28] [29].
In this paper, we first make image preprocessing to eliminate the interference of noise and redundant information, reduce the effects of environmental factors on images and highlight the important information of images. At the same time, in order to compensate the deficiency of geometric features, it is well known that the original face images often need to be well represented instead of being input into the classifier directly because of the huge computational cost. So PCA and 2D-PCA are used to extract geometric features from preprocessed images, reduce their dimensionality for computation and attain a higher level of separability. At last, we propose a novel deep learning algorithm combining unsupervised and supervised learning named deep belief network embedded with Softmax regress (DBNESR) to learn hierarchical representations for FR; as a comparison with the algorithms only based on supervised learning, again design many kinds of other classifiers and make experiments to validate the effectiveness of the algorithm.
The proposed DBNESR has several important properties, which are summarized as follows: 1) Through special learning, DBNESR can provide effective hierarchical representations [30]. For example, it can capture the intuition that if a certain image feature (or pattern) is useful in some locations of the image, then the same image feature can also be useful in other locations or it can capture higher-order statistics such as corners and contours, and can be tuned to the statistics of the specific object classes being considered (e.g., faces). 2) DBNESR is similar to the multiple nonlinear functions mapping, which can extract complex statistical dependencies from high-dimensional sensory inputs (e.g., faces) and efficiently learn deep hierarchical representations by re-using and combining intermediate concepts, allowing it to generalize well across a wide variety of computer vision (CV) tasks, including face recognition, image classification, and many others. 3) Further, an end system making use of deep learning hierarchical representations features can be more readily adapted to new domains.
The analysis and experiments are performed on the precise rate of face recognition. The conducted experiments validate: Firstly, the proposed DBNESR is optimal for face recognition with the highest and most stable recognition rates; Second, the deep learning algorithm combining unsupervised and supervised learning has better effect than all supervised learning algorithms; Third, hybrid neural networks has better effect than single model neural network; Fourth, the average recognition rate and variance of these algorithms in order of largest to smallest are respectively shown as DBNESR, MCDFC, SVM, HRBFNNs, RBF, HBPNNs, BP and BP, RBF, HBPNNs, HRBFNNs, SVM, MCDFC, DBNESR; At last, it reflects hierarchical representations of feature by DBNESR in terms of its capability of modeling hard artificial intelligent tasks.
The remainder of this paper is organized as follows. Section 2 reviews the images preprocessing. Section 3 introduces the feature extraction methods. Section 4 designs the classifiers of supervised learning. Section 5 gives and designs the classifier combining unsupervised and supervised learning proposed by us. Experimental results are presented and discussed in Section 6. Section 7 gives the concluding remarks.
2. Images Preprocessing
Images often appear the phenomenon such as low contrast, being not clear and so on in the process of generation, acquisition, input, etc. of images due to the influence of environmental factors such as the imaging system, noise and light conditions so on. Therefore it needs to make images preprocessing. The purpose of the preprocessing is to eliminate the interference of noise and redundant information, reduce the effects of environmental factors on images and highlight the important information of images [31]. Images preprocessing usually includes gray of images, images filtering, gray equalization of images, standardization of images, compression of images (or dimensionality-reduced) and so on [32]. The process of images preprocessing is as following.
1) Face images filtering
We use median filtering to make smoothing denoising for images. This method not only can effectively restrain the noise but also can very well protect the boundary. Median filter is a kind of nonlinear operation, it sorts a pixel point and all others pixel points within its neighborhood as the size of grey value, sets the median of the sequence as the gray value of the pixel point, as shown in Equation (1).
(1)
where, s is the filter window. Using the template of 3 × 3 makes median filtering for the experiment in the back.
The purpose of histogram equalization is to make images enhancement, improve the visual effect of images, make redundant information of images after preprocessing less and highlight some important information of images.
Set the gray range of image
as
, image histogram for
, Therefore, the total pixel points are:
(2)
Making normalization processing for the histogram, the probability density function of each grey value can be obtained:
(3)
The probability distribution function is:
(4)
Set the gray transformation function of histogram equalization as the limited slope not reduce continuously differentiable function
, input it into
to get the output
.
is the histogram of output image, it can get
(5)
(6)
where,
. Therefore, when the difference between the molecular and denominator of
is only a proportionality constant,
is constant. Namely
(7)
(8)
In order to make the scope of s for
, can get
. For discrete case the gray transformation function is as following:
(9)
where,
is the kth grayscale,
is the pixel number of
, n is the total pixels number of images, the scope of k for
.
We make the histogram equalization experiment for the images in the back.
It is well known that the original face images often need to be well represented instead of being input into the classifier directly because of the huge computational cost. As one of the popular representations, geometric features are often extracted to attain a higher level of separability. Here we employ multi-scale two-dimensional wavelet transform to generate the initial geometric features for representing face images.
We make the multi-scale two-dimensional wavelet transform experiment for the images in the back.
3. Feature Extraction
There are two main purposes for feature extraction: One is to extract characteristic information from the face images, the feature information can classify all the samples; The second is to reduce the redundant information of the images, make the data dimensionality being on behalf of human faces as far as possibly reduce, so as to improve the speed of subsequent operation process. It is well known that image features are usually classified into four classes: Statistical-pixel features, visual features, algebraic features, and geometric features (e.g. transform-coefficient features).
Suppose that there are N facial images
,
is column vector of M dimension. All samples can be expressed as following:
(10)
Calculate the average face of all sample images as following:
(11)
Calculate the difference of faces, namely the difference of each face with the average face as following:
(12)
Therefore, the images covariance matrix C can be represented as following:
(13)
Using the theorem of singular value decomposition (SVD) to calculate the eigenvalue
and orthogonal normalization eigenvector
of
, through Equation (14) the eigenvalues of covariance matrix C can be calculated.
(14)
Making all the eigenvalues
order in descend according to the size, through the formula as following:
(15)
where, usually set
, can get the eigenvalues face subspace
. All the samples project to subspace U, as following:
(16)
Therefore, using front t principal component instead of the original vector X, not only make the facial features parameter dimension is reduced, but also won’t loss too much feature information of the original images.
Suppose sample set is
, i is the category, j is the sample of the ith category, N is the total number of category, M is the total number of samples of each category,
is the number of all samples.
Let
be average of all samples as follows:
(17)
Therefore, the images covariance matrix G can be represented as follows:
(18)
and the generalized total scattered criterion
can be expressed by:
(19)
Let
be the unitary vector such that it maximizes the generalized total scatter criterion
, that is:
(20)
In general, there is more than one optimal solution. We usually select a set of optimal solutions
subjected to the orthonormal constraints and the maximizing criterion
, where, t is smaller than the dimension of the coefficients matrix. In fact, they are those orthonormal eigenvectors of the matrix G corresponding to t largest eigenvalues.
Now for each sub-band coefficient matrix
, compute the principal component of the matrix
as follows:
(21)
Then we can get its reduced features matrix
,
.
We extract features respectively with PCA and 2D-PCA and compare their effects for the images in the back experiment.
4. Designing the Classifiers of Supervised Learning
Usually the classifiers based on supervised learning are often used for FR, in the paper we design two types of classifiers. One is the type of supervised learning classifiers and the other is the classifiers combining unsupervised and supervised learning [33].
1) BP neural network
BP neural network is a kind of multilayer feed-forward network according to the back-propagation algorithm for errors, is currently one of the most widely used neural network models [34]. Recognition and classification of face images is an important application for BP neural network in the field of pattern recognition and classification.
The network consists of L layers as shown in Figure 1. Its training algorithm consists of three steps, illustrated as follows [35].
2) Hybrid BP neural networks (HBPNNs)
When the number scale of human face images isn’t big, generalization ability and operation time of single model BP neural network are ideal, and with the increase of numbers of identification species, the structure of BP network will become more complicated, which causes the time of network training to become longer, slower convergence rate, easy to fall into local minimum and poorer generalization ability and so on.
In order to eliminate these problems we design the hybrid BP neural networks (HBPNNs) composed of multiple single model BP networks to replace the complex BP network for FR. Hybrid networks have better fault tolerant and generalization than single model network, and can implement distributed computing to greatly shorten the training time of network [36].
The core idea of designing hybrid networks classifier is to divide a K-class pattern classification into K independent 2-class pattern classification. That is to make a complex classification problem decomposed into some simple classification problems. In the paper multiple single model BP networks are combined into a hybrid network classifier, namely make K BP networks of multiple inputs single output integrated, a BP network is a child network only being responsible for identifying one of K-class model category and parallel to each other between
![]()
Figure 1. Single model BP neural network.
different subnets. In reference of Figure 1 the model figure of HBPNNs is shown in Figure 2.
BP neural network only having a hidden layer and with sufficient hidden neurons is sufficient for approximating the input-output relationship [37]. Therefore, it selects standard three-layer BP neural network as the subnets for hybrid networks. For each subnets of hybrid networks, the number of neurons of input layer corresponds to the dimensions of face feature extraction, the number of neurons of output layer is 1. The number of neurons of hidden layer is calculated by the following empirical formula:
(22)
where, m are the number of neurons of output layer, n are the number of neurons of input layer, a is constant between 1 - 10 [38]. If the dimensions of face feature extraction are X, the structure of each subnets of the hybrid networks is as following:
(23)
The structure of BP neural network is as following:
(24)
The structure of subnets is simpler than the structure of single model BP neural network. When the structure of networks is complex, every increasing a neural
![]()
Figure 2. Hybrid BP neural networks (HBPNNs).
the training time will greatly increase. In addition, with the size of networks gradually becoming larger, more and more complex network structure is easy to have slow convergence, prone to fall into local minimum, to have poor generalization ability and so on. By contrast, the hybrid networks based on some subnets can obtain more stable and efficient classifiers in the shorter period of time of training.
Radial Basis Function (RBF) simulates the structure of neural network of the adjustment and covering each other of receiving domain of human brain, can approximate any continuous function with arbitrary precision. With the characteristics of fast learning, won’t get into local minimum.
The expression of RBF is as following [39]:
(25)
where,
, Euclidean distance of x to c is
. The radial basis function most commonly used is the Gaussian function for RBF neural network as following:
(26)
where,
is the width of the function. Radial basis function is often used to construct the function as following:
(27)
There are some different for
of each radial basis function and the weight
. The concrete process of training RBF is as follows.
For the set of sample data
, we use Equation (27) with M hidden nodes to classify those sample data.
The number of hidden nodes is chosen to be a small integer initially in applications. If the training error is not good, we can increase hidden nodes to reduce it. Considering the testing error simultaneously, there is a proper number of hidden nodes in applications. The model figure of RBF is shown in Figure 3.
The hybrid RBF neural networks (HRBFNNs) are composed of multiple RBF networks to replace RBF network for FR. Hybrid networks have better fault tolerant, higher convergence rate and stronger generalization than a single model network, and can implement distributed computing to greatly shorten the training time of network [40].
If the dimensions of face feature extraction are n, the structure of each subnets of the hybrid networks is as following:
(29)
The structure of RBF neural network is as following:
(30)
The structure of subnets is simpler than the structure of RBF neural network. In addition, when the structure of networks is complex, every increasing a neural the training time and amount of calculation will greatly increase. The model figure of the HRBFNNs is shown in Figure 4.
SVM is a novel machine learning technique based on the statistical learning theory that aims at finding the optimal hyper-plane among different classes (usually to solve binary classification problem) of input data or training data in high dimensional feature space, and new test data can be classified by the separating hyper-plane [41] [42].
Supposing there are two classes of examples (positive and negative), the label
![]()
Figure 4. Hybrid RBF neural networks (HRBFNNs).
of positive example is +1 and negative example is −1. The number of positive and negative examples respectively is n and m. The set
are given positive and negative examples for training. The set
are the labels of
, in which
and
. SVM is to learn a decision function to predict the label of an example. The optimization formulation of SVM is:
(31)
where,
is the slack variables and G controls the fraction on misclassified training examples. This is a quadratic programming problem, use Lagrange multiplier method and meet the KKT conditions, can get the optimal classification function for the above problems:
(32)
where,
and
are to the parameters to determine the optimal classification surface.
is the dot product of two vectors.
For the nonlinear problem SVM can turn it into a high dimensional space by the nonlinear function mapping to solve the optimal classification surface. Therefore, the original problem becomes linearly separable. As can be seen from Equation (32) if we know dot product operation of the characteristics space the optimal classification surface can be obtained by simple calculation. According to the theory of Mercer, for any
if:
(33)
The arbitrary symmetric function
will be the dot product of a certain transformation space. Equation (32) will be corresponding to:
(34)
This is SVM. There are a number of categories of the kernel function
:
l The linear kernel function
;
l The polynomial kernel function
,where s, c and d are parameters;
l The radial basis kernel function
,where,
is the parameter;
l The Sigmoid kernel function
, where, s and c are parameters.
The model figure of SVM [43] [44] [45] is shown in Figure 5.
SVM is essentially the classifier for two types. Solving multiple classification problems needs to make more appropriate classifier. There are two main methods
for SVM to structure the classifier for multiple classifications. One is the direct method, namely modify the objective function to use an optimization problem to solve the multiple classification parameters. This method is of high computational complexity. Another method is the indirect method. Combining multiple two-classifier constructs multiple classification classifiers. The method has two ways:
l One-Against-One: Build a hyper-plane between any two classes, to the problem of k classes needing to build
classification planes.
l One-Against-the-Rest: The classification plane is built between one category and other multiple categories, to the problem of k classes only needing to build k classification planes.
We will use two methods of “One-Against-One” and “One-Against-the-Rest” for the experiment and choose the method with better effect to construct the multiple classification classifiers of SVM.
The different classifiers have different performance. Fusion of multiple classifiers integrating their respective characteristics can make classification effect and robustness further improvement.
Feature fusion and decision-making fusion are of two main methods of classifier fusion. Feature fusion has large computation to be not easy to achieve, therefore, we adopt the decision-making fusion. The model figure of MCDFC is shown in Figure 6.
We use the weighted voting for decision fusion of each classifier:
(35)
where,
is the weight of each classifier for the vote of classification result,
is variable. The final classification result is concluded by each classifier according to the following weighted voting formula:
![]()
Figure 6. Multiple classification decision fusion classifier (MCDFC).
(36)
where,
is the final classification result and corresponding to the category y with the maximum,
is the classification result of the ith classifier, x is the input,
and Y is the category set.
indicates that the classification result of the ith classifier meeting the conditions is the category y and combines with the voting weight
of the classifier.
5. Designing the Classifier Combining Unsupervised and Supervised Learning
Supervised learning systems are domain-specific and annotating a large-scale corpus for each domain is very expensive [46]. Recently, semi-supervised learning, which uses a large amount of unlabeled data together with labeled data to build better learners, has attracted more and more attention in pattern recognition and classification [47]. In the paper we design a novel classifier of semi-supervised learning, namely combining unsupervised and supervised learning—deep belief network embedded with Softmax regress (DBNESR) for FR. DBNESR first learns hierarchical representations of feature by greedy layer-wise unsupervised learning in a feed-forward (bottom-up) and back-forward (top-down) manner [48] and then makes more efficient classification with Softmax regress by supervised learning. Deep belief network (DBN) is a representative deep learning algorithm, has deep architecture that is composed of multiple levels of non-linear operations [49], which is expected to perform well in semi-supervised learning, because of its capability of modeling hard artificial intelligent tasks [50]. Softmax regression is a generalization of the logistic regression in many classification problems.
1) Problem formulation
The dataset is represented as a matrix:
(37)
where, N is the number of training samples, M is the number of test samples, D is the number of feature values in the dataset. Each column of X corresponds to a sample X. A sample which has all features is viewed as a vector in
, where the jth coordinate corresponds to the jth feature.
Let Y be a set of labels correspond to L labeled training samples and is denoted as:
(38)
where, C is the number of classes. Each column of Y is a vector in
, where, the jth coordinate corresponds to the jth class:
(39)
We intend to seek the mapping function
using all the samples in order to determine Y when a new X comes.
2) Softmax regression
Softmax regression is a generalization of the logistic regression in many classification problems [51]. Logistic regression is for binary classification problems, class tag
. The hypothesis function is as following:
(40)
Training model parameters vector
, which can minimize the cost function:
(41)
Softmax regression is for many classification problems, class tag
. It is used for each given sample X, using hypothesis function to estimate the probability value  for each category j. The hypothesis function is as following:
for each category j. The hypothesis function is as following:
 (42)
(42)
where,  denote model parameters vector, the cost function is as following:
denote model parameters vector, the cost function is as following:
 (43)
(43)
where, 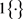 denotes:
denotes:
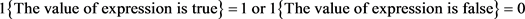 (44)
(44)
There are no closed form solutions to minimize the cost function Equation (43) at present. Therefore, we use the iterative optimization algorithm (for example, gradient descent method or L-BFGS). After derivation we get gradient formula is as following:
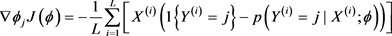 (45)
(45)
Then make the following update operation:
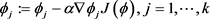 (46)
(46)
where,  denotes learning rate.
denotes learning rate.
3) Deep belief network embedded with Softmax regress (DBNESR)
DBN uses a Markov random field Restricted Boltzmann Machine (RBM) [52] [53] of unsupervised learning networks as building blocks for the multi-layer learning systems and uses a supervised learning algorithm named BP (back propagation) for fine-tuning after pre-training. Its architecture is shown in Figure 7. The deep architecture is a fully interconnected directed belief nets with one input layer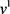 ,
, 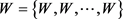 hidden layers
hidden layers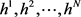 , and one labeled layer at the top. The input layer
, and one labeled layer at the top. The input layer ![]() has D units, equal to the number of features of samples. The label layer has C units, equal to the number of classes of label vector Y. The numbers of units for hidden layers, currently, are pre-defined according to the experience or intuition. The seeking of the mapping function, here, is transformed to the problem of finding the parameter space
has D units, equal to the number of features of samples. The label layer has C units, equal to the number of classes of label vector Y. The numbers of units for hidden layers, currently, are pre-defined according to the experience or intuition. The seeking of the mapping function, here, is transformed to the problem of finding the parameter space ![]() for the deep architecture [54].
for the deep architecture [54].
The semi-supervised learning method based on DBN architecture can be divided into two stages: First, DBN architecture is constructed by greedy layer-wise unsupervised learning using RBM as building blocks. All samples are utilized to find the parameter space W with N layers. Second, DBN architecture is trained
![]()
Figure 7. Architecture of deep belief network embedded with Softmax regress (DBNESR).
according to the log-likelihood using gradient descent method. As it is difficult to optimize a deep architecture using supervised learning directly, the unsupervised learning stage can abstract the hierarchical representations feature effectively, and prevent over-fitting of the supervised training. The algorithm BP is used pass the error top-down for fine-tuning after pre-training.
For unsupervised learning, we define the energy of the joint configuration ![]() as [50]:
as [50]:
![]() (47)
(47)
where, ![]() are the model parameters:
are the model parameters: ![]() is the symmetric interaction term between unit i in the layer
is the symmetric interaction term between unit i in the layer ![]() and unit j in the layer
and unit j in the layer![]() ,
,![]() .
. ![]() is the ith bias of layer
is the ith bias of layer ![]() and
and ![]() is the jth bias of layer
is the jth bias of layer![]() .
. ![]() is the number of units in the kth layer. The network assigns a probability to every possible data via this energy function. The probability of a training data can be raised by adjusting the weights and biases to lower the energy of that data and to raise the energy of similar, confabulated data that
is the number of units in the kth layer. The network assigns a probability to every possible data via this energy function. The probability of a training data can be raised by adjusting the weights and biases to lower the energy of that data and to raise the energy of similar, confabulated data that ![]() would prefer to the real data. When we input the value of
would prefer to the real data. When we input the value of![]() , the network can learn the content of
, the network can learn the content of ![]() by minimizing this energy function.
by minimizing this energy function.
The probability that the model assigns to a ![]() is:
is:
![]() (48)
(48)
![]() (49)
(49)
where, ![]() denotes the normalizing constant. The conditional distributions over
denotes the normalizing constant. The conditional distributions over ![]() and
and ![]() are given as:
are given as:
![]() (50)
(50)
![]() (51)
(51)
The probability of turning unit j is a logistic function of the states ![]() and
and![]() :
:
![]() (52)
(52)
The probability of turning unit i is a logistic function of the states of ![]() and
and![]() :
:
![]() (53)
(53)
where, the logistic function been chosen is the sigmoid function:
![]() (54)
(54)
The derivative of the log-likelihood with respect to the model parameter ![]() can be obtained from Equation (48):
can be obtained from Equation (48):
![]() (55)
(55)
where, ![]() denotes an expectation with respect to the data distribution and
denotes an expectation with respect to the data distribution and ![]() denotes an expectation with respect to the distribution defined by the model [55]. The expectation
denotes an expectation with respect to the distribution defined by the model [55]. The expectation ![]() cannot be computed analytically. In practice,
cannot be computed analytically. In practice, ![]() is replaced by
is replaced by![]() , which denotes a distribution of samples when the feature detectors are being driven by reconstructed
, which denotes a distribution of samples when the feature detectors are being driven by reconstructed![]() . This is an approximation to the gradient of a different objective function, called the contrastive divergence (CD) [56] [57] [58] [59]. Using Kullback-Leibler distance to measure two probability distribution “diversity”, represented by
. This is an approximation to the gradient of a different objective function, called the contrastive divergence (CD) [56] [57] [58] [59]. Using Kullback-Leibler distance to measure two probability distribution “diversity”, represented by![]() , is shown in Equation (56):
, is shown in Equation (56):
![]() (56)
(56)
where, ![]() denotes joint probability distribution of initial state of RBM network,
denotes joint probability distribution of initial state of RBM network, ![]() denotes joint probability distribution of RBM network after n transformations of Markov chain Monte Carlo(MCMC),
denotes joint probability distribution of RBM network after n transformations of Markov chain Monte Carlo(MCMC), ![]() denotes joint probability distribution of RBM network at the ends of MCMC. Therefore,
denotes joint probability distribution of RBM network at the ends of MCMC. Therefore, ![]() can be regarded as a measure location for
can be regarded as a measure location for ![]() between
between ![]() and
and![]() . It constantly assigns
. It constantly assigns ![]() to
to ![]() and gets new
and gets new ![]() and
and![]() . The experiments show that
. The experiments show that ![]() will tend to zero and the accuracy is approximate of MCMC after making slope for r times for correction parameter
will tend to zero and the accuracy is approximate of MCMC after making slope for r times for correction parameter![]() . The training process of RBM is shown in Figure 8.
. The training process of RBM is shown in Figure 8.
We can get Equation (57) by training process of RBM using contrastive divergence:
![]() (57)
(57)
where, ![]() is the learning rate. Then the parameter can be adjusted through:
is the learning rate. Then the parameter can be adjusted through:
![]() (58)
(58)
where, ![]() is the momentum.
is the momentum.
The above discussion is based on the training of the parameters between hidden layers with one sample x. For unsupervised learning, we construct the deep architecture using all samples by inputting them one by one from layer![]() , train the parameters between
, train the parameters between ![]() and
and![]() . Then
. Then ![]() is constructed, the value of
is constructed, the value of ![]() is calculated by
is calculated by ![]() and the trained parameters between
and the trained parameters between ![]() and
and![]() . We also can use it to construct the next layer
. We also can use it to construct the next layer ![]() and so on. The deep architecture is constructed layer by layer from bottom to top. In each time, the parameter space
and so on. The deep architecture is constructed layer by layer from bottom to top. In each time, the parameter space ![]() is trained by the calculated data in the
is trained by the calculated data in the ![]() layer. Accord to the
layer. Accord to the ![]() calculated above, the layer
calculated above, the layer ![]() is obtained as below for a sample x fed from layer
is obtained as below for a sample x fed from layer![]() :
:
![]() (59)
(59)
For supervised learning, the DBM architecture is trained by C labeled data. The optimization problem is formulized as:
![]()
Figure 8. Training process of RBM using contrastive divergence.
![]() (60)
(60)
namely, to minimize cross-entropy. Where, ![]() denotes the real label probability and
denotes the real label probability and ![]() denotes the model label probability.
denotes the model label probability.
The greedy layer-wise unsupervised learning is just used to initialize the parameter of deep architecture, the parameters of the deep architecture are updated based on Equation (58). After initialization, real values are used in all the nodes of the deep architecture. We use gradient-descent through the whole deep architecture to retrain the weights for optimal classification.
6. Experiments
1) Face Recognition Databases
We selected some typical databases of images, for example ORL Face Database, which consists of 10 different images for each of the 40 distinct individuals. Each people is imaged in different facial expressions and facial details under varying lighting conditions at different times. All the pictures are captured with a dark background and the individuals are in an upright and frontal position; the facial gestures are not identical, expressions, position, angle and scale are some different; The depth rotation and plane rotary can be up to 20˚, the scale of faces also has as much as 10% change. For each face database as above, we randomly choose a part of images as training data and the remaining as testing data. In this paper, in order to reflect the universality and high efficiency of all classification algorithms we randomly choose about 50% of each individual image as training data and the rest as testing data. At first all images will be made preprocessing and feature extraction.
All the experiments are carried out in MATLAB R2010b environment running on a desktop with IntelÒ CoreTM2 Duo CPU T6670 @2.20GHz and 4.00 GB RAM.
2) Relevant experiments
Experiment 1. In this experiment, we use median filtering to make smoothing denoising for images preprocessing and get the sample Figure 9 as following:
Seeing from the comparison of face images, the face images after filtering eliminate most of noise interference.
Experiment 2. In this experiment, we make histogram equalization for the images preprocessing and get the sample figures as following:
From Figure 10 and Figure 11 we can see: After histogram equalization, the distribution of image histogram is more uniform, the range of gray increases some and the contrast has also been stronger. In addition, the image after histogram equalization basically eliminated the influence of illumination, expanded the representation range of pixel gray, improved the contrast of image,
![]()
Figure 9. Face images with median filtering versus no median filtering.
![]()
Figure 10. Face images before histogram equalization versus after histogram equalization. (a) Original image; (b) Image after histogram equalization.
![]()
![]()
Figure 11. Histogram of original image versus histogram of image after histogram equalization. (a) Histogram of original image; (b) Histogram of image after histogram equalization.
made the facial features more evident and is conducive to follow-up feature extraction and FR.
Experiment 3. In this experiment, we employ multi-scale two-dimensional wavelet transform to generate the initial geometric features for representing face images. By the experiment we get the sample figures as following:
From Figure 12 we can see: Although for compression of images (or dimensionality-reduced), LL sub-graph information capacity has decreased some, but still has very high resolution and the energy of wavelet domain did not decrease a lot. LL sub-graph can be well made for the follow-up feature extraction.
Experiment 4. In this experiment, we extract features respectively with PCA and 2D-PCA and compare their effects as following:
From Figure 13 we can see that the first several principal components contribution rates extracted with 2D-PCA are higher than the first several principal components contribution rates extracted with PCA. From Figure 14 we can see when the principal components are extracted for 20, the principal component
![]()
Figure 12. Multi-scal two-dimensional wavelet transform.
![]()
Figure 13. Principal component energy figure. Abscissa: principal components; ordinate: energy value.
![]()
Figure 14. Principal component accumulation contribution rate. Abscissa: principal components; ordinate: total energy value.
contribution rate of 2D-PCA is greater than 90%, while the principal component contribution rate of PCA is less than 80%. Accordingly, 2D-PCA can use less principal component to better describe the image than PCA.
Figure 15 is the comparing results image of reconstruction with the feature respectively extracted with PCA and 2D-PCA. We can see that the images of reconstruction by 2D-PCA are clearer than the images of reconstruction by PCA when extracting same number of principal components. The reconstruction face extracted 50 principal components by 2D-PCA is almost same clear with the original image. 2D-PCA has better effect than PCA.
Experiment 5. In this experiment, we compare the recognition rate of the methods respectively based on PCA + BP, WT + PCA + BP, PCA + HBPNNs and WT + PCA + HBPNNs. The experiment is repeated many times and takes the average recognition rate. The experimental results are shown in Table 1.
As shown in Table 1, Recognition rates of HBPNNs are improved very greatly being compared to BP, in the same classifier (BP or HBPNNs) recognition rates of the methods based on WT + PCA are higher than them based on PCA.
Experiment 6. This experiment compares the recognition rate of the methods respectively based on WT + 2D-PCA + RBF and WT + 2D-PCA + HRBFNNs. The experiment is repeated for many times and takes the average recognition rate. The experimental results are shown in Table 2.
As shown in Table 2, Recognition rates of HRBFNNs are improved very greatly being compared to RBF. Therefore, HRBFNNs being used for FR is more feasible.
Experiment 7. Because SVM is essentially the classifier for two types, solving
![]()
Figure 15. Reconstructed images with 2D-PCA and PCA versus original image (t: principal component number). (a) Original image; (b) PCA principal component reconstruction images; (c) 2D-PCA principal component reconstruction images.
![]()
Table 1. Average recognition rates of different recognition methods.
![]()
Table 2. Average recognition rates of different recognition methods.
the multiple classification problems needs to reconstruct more appropriate classifier. We will use two methods of “One-Against-One” and “One-Against-the Rest” for the experiment and choose the method with better effect to construct the multiple classification classifiers of SVM. The experiment is repeated for 20 times and takes the average recognition rate. The experimental results are shown in Table 3.
As shown in Table 3, “One-Against-One” SVM has higher recognition rate than “One-Against-the-Rest” SVM and at the same time has lower wrong number. Therefore, we use the way of “One-Against-One” to reconstruct the SVM classifier to realize FR.
Experiment 8. In the paper we construct the multiple classification decision fusion classifier (MCDFC)—hybrid HBPNNs-HRBFNNs-SVM classifier. In this experiment, in order to show the efficiency of MCDFC, we first make recognition experiment respectively based on HBPNNs, HRBFNNs and SVM, then use the decision function to make fusions for classification results of three classifiers and get classification results of MCDFC. The experiment is repeated for 20 times and the experimental results are shown in Table 4 and in Figure 16.
As shown in Figure 16, the recognition effect of MCDFC is always not lower than the average level of other three kinds of classifiers and in almost all cases the effect of MCDFC is optimal.
To eliminate the error of single experiment and greatly reduce the random uncertainty, Table 5 lists the average recognition rates of each classifier for 20 times and the variance of each classifier. It can be seen from the experimental results that the multiple classification decision fusion classifier (MCDFC)—hybrid HBPNNs-HRBFNNs-SVM classifier has the best effect for FR, has the minimum variance, can effectively improve the generalization ability and has high stability.
Experiment 9. In this experiment, in order to validate the performance of our proposed algorithm—DBNESR is optimal for FR, we compare our proposed algorithm with some other methods such as BP, HBPNNs, RBF, HRBFNNs, SVM and MCDFC.
![]()
Table 3. Average recognition rates of different recognition methods.
![]()
Table 4. Recognition rates of different recognition methods for 20 times.
![]()
Table 5. Average recognition rates and variances of different recognition methods.
![]()
Figure 16. The curve figures of recognition rates of different recognition methods.
In the experiment we set up different hidden layers and each hidden layer with different neurons. The architecture of DBNESR is similar with DBN, but with a different loss function introduced for supervised learning stage. For greedy layer-wise unsupervised learning we train the weights of each layer independently with the different epochs, we also make fine-tuning supervised learning for the different epochs. All DBNESR structures and learning epochs used in this experiment are separately shown in Table 6. The number of units in input layer is the same as the feature dimensions of the dataset.
Almost all the recognition rates of these DBNESR structures are more than 90%, in particular the effects of the models of 500-1000-40 and 1000-500-40 are
![]()
Table 6. Different hidden layers of DBNESR and learning epochs used in this experiment.
![]()
Table 7. Recognition rates of different recognition methods for 20 times.
![]()
Table 8. Average recognition rates and variances of different recognition methods.
best and most stable. Therefore, the DBNESR structures used in this experiment are 1000-500-40, which represents the number of units in output layer is 40, and in 2 hidden layers are 1000 and 500 respectively. The learning rate is set to dynamic value, which the initial learning rate is set to 0.1 and becomes smaller as the training error becoming smaller. The experimental results are shown in Table 7, Table 8 and in Figures 17-19.
![]()
Figure 17. The curve figures of recognition rates of different recognition methods.
![]()
Figure 18. The bar charts of average recognition rate of different recognition methods.
![]()
Figure 19. The bar charts of variance of different recognition methods.
As shown in Table 7, Table 8 and in Figures 17-19, our proposed algorithm—DBNESR is optimal for FR, in almost all cases the recognition rates of DBNESR is highest and most stable, namely there is the largest average recognition rate and the smallest variance.
7. Conclusion
The conducted experiments validate that the proposed algorithm DBNESR is optimal for face recognition with the highest and most stable recognition rates, that is, it successfully implements hierarchical representations’ feature deep learning for face recognition. You can also be sure that it reflects hierarchical representations of feature by DBNESR in terms of its capability of modeling other artificial intelligent tasks, which is also what we’re going to do in the future.
Acknowledgements
This research was funded by the National Natural Science Foundation (Grand 61171141, 61573145), the Public Research and Capacity Building of Guangdong Province (Grand 2014B010104001), the Basic and Applied Basic Research of Guangdong Province (Grand 2015A030308018), the Main Project of the Natural Science Fund of Jiaying University (grant number 2017KJZ02) and the key research bases being jointly built by provinces and cities for humanities and social science of regular institutions of higher learning of Guangdong province (Grant number 18KYKT11), the cooperative education program of Ministry of Education (Grant number 201802153047), the college characteristic innovation project of Education Department of Guangdong province in 2019 (Grant number 2019KTSCX169), the authors are greatly thanks to these grants.
Compliance with Ethical Standards
1) (In Case of Funding) Funding
This study was funded by the National Natural Science Foundation (grant number 61171141, 61573145), the Public Research and Capacity Building of Guangdong Province (grant number 2014B010104001), the Basic and Applied Basic Research of Guangdong Province (grant number 2015A030308018), the Main Project of the Natural Science Fund of Jiaying University (grant number 2017KJZ02) and the key research bases being jointly built by provinces and cities for humanities and social science of regular institutions of higher learning of Guangdong province (grant number 18KYKT11), the cooperative education program of ministry of education (grant number 201802153047), the college characteristic innovation project of education department of guangdong province in 2019 (grant number 2019KTSCX169).
2) (If Articles Do Not Contain Studies with Human Participants or Animals by Any of The Authors, Please Select One of The Following Statements) Ethical Approval:
This article does not contain any studies with human participants or animals performed by any of the authors.