Unified Asymptotic Results for Maximum Spacing and Generalized Spacing Methods for Continuous Models ()
1. Introduction
Let
be a random sample from a continuous parametric family with a distribution function which belongs
,
is the vector of parameters and instead of fitting distribution using maximum likelihood (ML) method, Cheng and Amin [1] , Ranneby [2] proposed the maximum product of spacings method which is also called maximum spacing (MSP) method which makes use of spacings which are gaps between order statistics of the sample instead of using directly the observations of the sample. The method consists of maximizing or equivalently minimizing the following objective function to obtain the MSP estimators,
where
are the spacings and we define
with the order statistics of the sample given by
It is quite obvious that it is not more difficult to obtain the GSP estimators than the ML estimators and it has been proven that the MSP estimators are as efficient as the ML estimators in general and can be consistent when ML estimators might fail to be consistent. MSP method can be used as an alternative to ML method as ML method might encounter numerical difficulties when used for fitting some models with shifted origin which are often encountered in loss models and extreme value models. We shall examine a few examples for illustrations. Anatolyev and Kosenok [3] have discussed the model of example 1 below where they find the MSP estimators have better finite sample properties than ML estimators and notice that the method has not received much attention in econometrics; it has received even less attention in actuarial science.
Example 1 (Pareto)
The Pareto model considered by Anatolyev and Kosenok [3] has density function given by
and distribution function given by
.
The model is a sub-model of the larger model with two parameters α and θ, density function
,
where θ is a shift parameter,
. The distribution function is given by
,
see Klugman et al. [4] (p. 465) for the larger model which is a shifted origin model and used in actuarial science.
The following example gives the Fréchet model which is an extreme value model and it is also a shifted origin model, see more properties and details in the book by Castillo et al. [5] (p. 63-64) for the Fréchet model.
Example 2(Fréchet)
The Fréchet model has three parameters
with density function and distribution function given by
and
,
where λ is as shift parameter,
.
Ghosh and Jammalamadaka [6] have generalized the MSP method by considering objective functions of the form
with
being a convex function and twice differentiable, we shall call methods based on this class generalized spacings methods (GSP) and give more details in the next section where we restrict
being the commonly used convex functions and introduce the GJ class named after Ghosh and Jammalamadaka [6] and by GSP methods we refer to GSP methods but with
belongs to this GJ class.
As we have seen that despite the GSP methods are powerful methods for univariate continuous models but they are not used as often as they should be. It might be due to the asymptotic results are scattered in the literature and in particular previous approaches for asymptotic normality have been based on distribution of spacings and order statistics which make further results such as the distributions of counterparts of Wald test statistic, Score statistic and likelihood ratio test statistics of likelihood theory difficult to establish which prevent the use of these methods for applications. In this paper, a different approach is taken for establishing asymptotic normality. The approach is a based on using uniform weak law of large numbers (UWLLN) for establishing consistency of the GSP estimators and central limit theorem for α-mixing sequences as given by White and Domowitz [7] to establish asymptotic normality for the GSP estimators, asymptotic distributions for the trinity test for hypothesis testing for parameters for GSP methods are also obtained by relating the GSP methods to quasi-likelihood methods so that robustness of the GSP methods can also be studied. With a unified and simpler presentation, we hope to put the GSP methods parallel to likelihood methods and by doing so we hope to encourage more use of these methods by practitioners for their applied works in various fields.
The paper is organized as follows. Section 2 gives the preliminary results already established by Ranneby [2] but needed for further results. The notions of mixing sequences are also introduced to facilitate the developments in subsequent sections. Section 3 gives the asymptotic properties of the GSP methods using UWWLN and CLT; robustness properties are established. Parameter hypothesis testing is treated with results obtained for the trinity test for the GSP methods which are related to quasi-likelihood methods and parallel to ML methods. Results which are available for M-estimation theory are also used to investigate the asymptotic distributions for the trinity test for the GSP methods.
2. Preliminaries
For further study the class of generalized spacing (GSP) methods, we shall present the GJ class being considered by Ghosh and Jammalamadaka [6] and define some notations. We shall make use of some results already established by Ranneby [2] so that subsequently we shall use a different approach for studying asymptotic properties of the GSP methods; the approach is based on uniform law of large numbers (ULLN) and central limit theorem as given by White and Domowitz [7] for α-mixing sequences. The approach seems to give results in a more unified way than approaches using results on spacings and order statistics; see Pyke [8] , Shorack and Wellner [9] for results on spacings and David and Nagaraja [10] for results on order statistics.
The GSP methods can be seen to be closely related to quasi-likelihood methods and M-estimation theory can be used to study estimation, robustness and parameter testing via Wald test, Lagrange multiplier test or score test and quasi-likelihood ratio test but with a GSP version for each of these tests forming the classical trinity. The results appear to be natural and parallel to maximum likelihood methods (ML) given that the vector of MSP estimators which belong to the class of GSP is as efficient as the vector of ML estimator and therefore it is natural to establish inference methods based on this class which parallel ML methods. It is also worth to note that this class can be used for robust estimation which parallel Hellinger distance methods given by Beran [11] and like the class of pseudo-distance studied by Broniatowski [12] there is no need of density estimate to implement GSP methods. We try to reduce technicalities for the methods introduced subsequently so that practitioners might find that it is not so difficult to follow and make use of the results and it is quite clear that it is relatively simple to implement GSP methods just as in the case for ML methods.
Now we shall use the set up as given by Ghosh and Jammalamadaka [6] and Ranneby [2] by assuming a random sample of size n where we have observations
which are independent and identically distributed (iid) as X with density function and distribution function given respectively by
and
.The vector of parameters is denoted by
. The vector of the true parameters is
.
The order statistics are denoted by
and the spacings
which can be viewed as transforms of the order statistics and they are given by
with
and
by definitions.
Ghosh and Jammalamadaka [6] studied the class of estimators namely GSP estimators obtained by minimizing a criterion function of the following form which make use of a class of convex function
, i.e.,
(1)
or equivalently,
. (2)
The class considered include the following functional form for
which is a convex function with domain
an range being the real line. With
we have the MSP method and the function
is optimum in term of efficiency of statistical methods generated but for robustness other choices for
might include
for
,
for
,
,
for
. (3)
Note that for all these choices the first and second derivatives
,
exist and since
is a convex function
, see Lehmann and Casella [13] (p. 45-47) for properties of convex function and Jensen’s inequality which is based on the property of convexity of a function.
We shall call the class defined by using functions given by expression (3) and including
, the GJ class as it was introduced by Ghosh and Jammalamadaka [6] . The GJ class includes the commonly used
, see expression (6) given by Ghosh and Jammalamadaka [6] (p73).
For this class, we can see that the sub-class with
for
and up to an additive and multiplicative constant, it can be expressed equivalently as
and as
which is the optimum
as using
will generate the MSP estimators which are the most efficient within this class and asymptotically equivalent to maximum likelihood(ML) estimators.
Ghosh and Jammalamadaka [6] establish consistency and asymptotic normality for this class of GSP estimators and make use of limit theorems for spacings which are based on order statistics. We shall use another approach which bypass limit theorems for spacings and order statistics and obtain consistency and asymptotic normality for the multi-parameter case for this class of GSP methods and based on these results, robustness properties for this class can be studied and parameter testing can be developed in Section 4 and we shall be able to consider GSP methods as quasi-likelihood methods and hence unify the asymptotic theory with M-estimation theory.
We shall also make use of the following results and notions introduced by Ranneby [2] to overcome the need of using spacings or order statistics in expression (1) and expression (2). With a sample of size n; for each observation
, it can be associated to a random variable
where
is random variable which represents the distance from
to the nearest observation to the right of
and this distance is defined to be infinity if
.
It is clear that if we use
to re-express
or an asymptotic equivalent expression for
can be given with the use of
instead of
in expression (2).
Now if we define
(4)
and
(5)
then
defined as above is asymptotically equivalent to
defined using expression (2) as only the first term in the summation of expression (2) is left out for the summation of expression (5) and we focus on asymptotic theory here. Also, expression (5) is asymptotically equivalent to the expression denoted by
given by Ranneby [2] (p. 98).
We shall see that most of limit theorems such as the uniform weak law of large numbers(UWLLN) or Central limit theorem (CLT) are stated using the form given by expression (5) and we need to subject
to these limit theorems; it is more convenient to use
as given by expression (5) with a factor
as it simplifies the notations.
Now we can note that if
is a sequence of independent identically distributed (iid) terms, then there is no problem to apply UWLN and CLT but we will see that
is a dependent sequence but with a weak form of dependency so that we can apply a dependent version of UWLN then we can draw the same conclusion just as assuming
are iid.
Clearly, we need to make use of the distribution of
and the dependence of the sequence
to study the sequence
. Ranneby [2] (p. 99-100) has shown that
for
has a common bivariate distribution which depends on n and given by
(6)
As
,
with the bivariate density function given by
, (7)
see Ranneby [2] (p. 98) for the expression for the bivariate density function
. The density
, with respect to x, has
as marginal density function.
Let
and its bivariate density is as given by expression (7) and to derive asymptotic results subsequently we let
, then we have the equalities in distribution for
.
. (8)
Furthermore, we have pairwise asymptotically independent of
for
in the sense that the joint distribution of
and
which is denoted by
as
, (9)
see Ranneby [2] (p. 100). Intuitively, it makes sense that we can assume a similar form of asymptotically independent for the pair
based on expression (4) and as UWLLN is often stated using sequences with a weak form of dependency of a sequence defined as α-mixing sequence as given by White and Domowitz [7] in the econometric literature, we shall examine the notion of α-mixing sequence and show that we can assume the sequence
is α-mixing as we can assume that
is ρ-mixing using property given by expression (9). We shall discuss first the notion of ρ-mixing which makes use of the correlation of a pair of random variables as it is more intuitively appealing than the notion α-mixing which makes use of two sets of two separate sigma algebras.
We shall define some more notations.
Let
. As they have a common distribution let
be one of them, its bivariate density function is given by
. (10)
From the mean value theorem, we have
(11)
for each i as
which is also given by Ranneby [2] (p. 99); therefore, we also have the equality in distribution
as
and we define
, let
be one of the 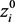 's as they have a common distribution. Consequently, for establishing asymptotic properties as we let
's as they have a common distribution. Consequently, for establishing asymptotic properties as we let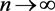 , we can make use of the distribution of
, we can make use of the distribution of 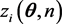 which converges in distribution to the distribution of
which converges in distribution to the distribution of 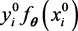 and to simplify the notations, let
and to simplify the notations, let
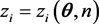 and
and 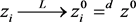 (12)
(12)
for all i and the property given by expression (12) can be used to establish asymptotic results subsequently.
It is not difficult to see that the following covariance relationships hold,
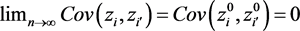 (13)
(13)
as 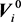 and
and 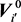 are independent for
are independent for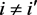 . Equivalently, if we use correlation,
. Equivalently, if we use correlation,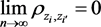 . The notion of ρ-mixing makes use of the correlation of two random variables and appears to be easier to grasp, so we shall define this notion first and verify that indeed we can assume the sequence
. The notion of ρ-mixing makes use of the correlation of two random variables and appears to be easier to grasp, so we shall define this notion first and verify that indeed we can assume the sequence 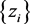 is ρ-mixing which in turn implies α-mixing which allows us to use available limit theorems results which are stated either using α or ф mixing.
is ρ-mixing which in turn implies α-mixing which allows us to use available limit theorems results which are stated either using α or ф mixing.
Define two sets of random variables which are apart of a distance m as follows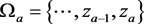 and
and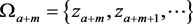 . Pick
. Pick 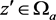 and
and 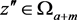 and form the covariance
and form the covariance 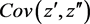 and the correlation coefficient
and the correlation coefficient
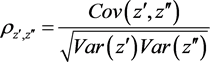
and since ![]() and
and ![]() have the same distribution
have the same distribution![]() .
.
Now we can define the ρ-mixing coefficient for the sequence ![]() as
as ![]() and the sequence
and the sequence ![]() will be ρ-mixing if
will be ρ-mixing if ![]() as
as![]() . Note that Ranneby [2] (p. 99) has pointed out that for finite n, the random variable
. Note that Ranneby [2] (p. 99) has pointed out that for finite n, the random variable ![]() are exchangeable in the proof for Lemma (2.1) and from the existing results already established, it appears that
are exchangeable in the proof for Lemma (2.1) and from the existing results already established, it appears that ![]() forms a covariance stationary sequence.
forms a covariance stationary sequence.
Now ![]() will imply
will imply ![]() and using expression (13), we might conclude that the sequence
and using expression (13), we might conclude that the sequence ![]() is ρ-mixing using the inequality
is ρ-mixing using the inequality ![]() with
with ![]() as given by expression (5.39) in Hall and Heyde [14] (p. 147).
as given by expression (5.39) in Hall and Heyde [14] (p. 147).
The coefficient ![]() for α-mixing sequence will be defined subsequently. Note that from the above inequality,
for α-mixing sequence will be defined subsequently. Note that from the above inequality, ![]() implies
implies ![]() so that
so that ![]() is also α-mixing. The coefficient
is also α-mixing. The coefficient ![]() is defined using two sets from two sigma algebras which are of a distance m apart is more abstract but nice results follow. If we can establish a sequence is α-mixing then we can form a new mixing sequence using a transformation applied on a finite number of elements of the original mixing sequence; for example if
is defined using two sets from two sigma algebras which are of a distance m apart is more abstract but nice results follow. If we can establish a sequence is α-mixing then we can form a new mixing sequence using a transformation applied on a finite number of elements of the original mixing sequence; for example if ![]() is α mixing and define
is α mixing and define ![]() then
then ![]() is again an α-mixing sequence and furthermore if
is again an α-mixing sequence and furthermore if ![]() for
for ![]() is
is![]() , i.e.,
, i.e., ![]() at the rate as
at the rate as![]() , the same rate is preserved for
, the same rate is preserved for ![]() of the new sequence
of the new sequence![]() , see Lemma 2.1 given by White and Domowitz [7] (p. 146) and discussions as given by Martin et al. [15] (p. 38). This property facilitates the use of limit theorems for establishing consistency and asymptotic normality for estimators obtained by minimizing a nonlinear objective function.
, see Lemma 2.1 given by White and Domowitz [7] (p. 146) and discussions as given by Martin et al. [15] (p. 38). This property facilitates the use of limit theorems for establishing consistency and asymptotic normality for estimators obtained by minimizing a nonlinear objective function.
Now we shall define the coefficient ![]() for the sequence
for the sequence![]() . Let
. Let ![]() and
and ![]() be two sigma algebras. Choose a set
be two sigma algebras. Choose a set ![]() and another set
and another set ![]() and define
and define ![]() using the following probability,
using the following probability,
![]()
The coefficient ![]() for the sequence
for the sequence ![]() can be defined as
can be defined as
![]()
using ![]() and
and ![]() which denote respectively the sigma algebras generated by
which denote respectively the sigma algebras generated by ![]() and
and![]() .
.
3. Asymptotic Properties
For establishing asymptotic results for the GSP methods which include the MSP method we do not aim to obtain the results with a minimum amount of regularity conditions as by doing so the technicalities will be increased and might discourage practitioners to use the methods. The regularity conditions used are comparable to regularity conditions for maximum likelihood methods under usual circumstances in order to put GSP methods parallel to ML methods. The aims are to put the GSP methods as equally practical as ML methods for univariate continuous models and to show that it is not more difficult to use these methods than ML methods. Furthermore, by related this class of estimators with to the class of M-estimators, it will be shown that this class can offer more flexible choices for robust estimators should the MSP estimators which are equivalent to ML estimators are not robust and they share similarities with the class of estimators considered by Broniatowski et al. [12] . We will treat consistency and asymptotic normality for the GSP estimators in the next two sections.
3.1. Consistency
The objective function to be minimized to obtain the GSP estimators which is denoted by the vector ![]() is
is
![]() .
.
The following Theorems can be used to establish consistency for ![]() and they are listed below as Theorem 1 and Theorem 2. Theorem 1 is the basic consistency Theorem (2.1) given by Newey and McFadden [16] (p. 2121-2122) for estimators obtained by minimizing an objective function
and they are listed below as Theorem 1 and Theorem 2. Theorem 1 is the basic consistency Theorem (2.1) given by Newey and McFadden [16] (p. 2121-2122) for estimators obtained by minimizing an objective function ![]() in general and clearly applicable for
in general and clearly applicable for![]() as defined by expression (5). Theorem 2 is essentially Theorem 2.3 given by White and Domowitz [7] (p. 147), Their Theorem 2.3 is a Theorem on uniform weak law of large numbers (UWLLN) but we shall restate it so that it is more suitable for our purposes. The proofs have been given by the authors and for related Theorems on UWLLN, see Davidson [17] (p. 340-344).
as defined by expression (5). Theorem 2 is essentially Theorem 2.3 given by White and Domowitz [7] (p. 147), Their Theorem 2.3 is a Theorem on uniform weak law of large numbers (UWLLN) but we shall restate it so that it is more suitable for our purposes. The proofs have been given by the authors and for related Theorems on UWLLN, see Davidson [17] (p. 340-344).
Theorem 1(Consistency)
Assume that:
1) The parameter space θ is compact, the true vector of parameters is denoted by![]() ,
,
2) ![]() uniformly and
uniformly and ![]() is a non-random and continuous function of
is a non-random and continuous function of![]() ,
,
3) ![]() is uniquely minimized at
is uniquely minimized at![]() ,
,
Then![]() , i.e., we have the convergence in probability which implies consistency for
, i.e., we have the convergence in probability which implies consistency for![]() , where
, where ![]() is the vector which minimizes
is the vector which minimizes![]() .
.
To apply this Theorem condition 2) is a condition on uniform convergence, conditions which ensure UWWLN can be applied will imply condition 2 for ![]() as given by expression (5) and
as given by expression (5) and ![]() is an average over n terms, this makes it easier to follow the notations for applying the following Theorem 2 on UWLLN. For a detail proof of UWLLN, see Bierens [18] (p. 187).
is an average over n terms, this makes it easier to follow the notations for applying the following Theorem 2 on UWLLN. For a detail proof of UWLLN, see Bierens [18] (p. 187).
Implicitly, we assume that ![]() is a α-mixing sequence with mixing coefficient
is a α-mixing sequence with mixing coefficient ![]() which imply the new sequence created using the transformation
which imply the new sequence created using the transformation ![]() is again a α-mixing sequence, i.e.,
is again a α-mixing sequence, i.e., ![]() is also a α-mixing sequence with the same order for
is also a α-mixing sequence with the same order for![]() .
.
Theorem 2 (UWLLN)
Assume that:
1) ![]() is measurable and continuous for each θ Î θ, θ is compact.
is measurable and continuous for each θ Î θ, θ is compact.
2) There exists a function ![]() such that
such that ![]() for all θ Î θ.
for all θ Î θ.
3) For ![]() and any
and any![]() , the expectation
, the expectation ![]() for all i.
for all i.
4)![]() ,
, ![]() is as defined earlier.
is as defined earlier.
Then we have:
1) ![]() is continuous as a function of θ for all i.
is continuous as a function of θ for all i.
2) ![]() uniformly as
uniformly as ![]() on θ.
on θ.
Applying Theorem 1 and Theorem 2 will show consistency for the GSP estimators given by the vector ![]() which minimizes expression (5). We can say that with
which minimizes expression (5). We can say that with ![]() being an α-mixing sequence, the regularity conditions of Theorem 1 and Theorem 2 can be assumed to be satisfied in general with
being an α-mixing sequence, the regularity conditions of Theorem 1 and Theorem 2 can be assumed to be satisfied in general with ![]() uniformly,
uniformly, ![]() is continuous and given by
is continuous and given by
![]()
and since the ![]() are identically distributed as z, z being
are identically distributed as z, z being ![]() for example. We then have
for example. We then have ![]() with
with ![]() using expression (11) and Dominated Convergence Theorem (DCT). For expressions expressible as a sequence of integrals, the Dominated Convergence Theorem (DCT) might be useful for finding their limits; details and proof of the DCT can be found in standard real analysis books. The joint density function for
using expression (11) and Dominated Convergence Theorem (DCT). For expressions expressible as a sequence of integrals, the Dominated Convergence Theorem (DCT) might be useful for finding their limits; details and proof of the DCT can be found in standard real analysis books. The joint density function for ![]() is as given by expression (8). Consequently, we can express
is as given by expression (8). Consequently, we can express ![]() as
as
![]() (14)
(14)
which is more general but similar to the expression given by Ranne by [2] (p. 97) for the MSP case. We can also express ![]() as
as
![]() .
.
If we consider the inner integral and make a change of variables with ![]() which implies
which implies![]() , this allows to re-express
, this allows to re-express
![]() . (15)
. (15)
Therefore,
![]() . (16)
. (16)
For consistency based on Theorem 1, we need to show that ![]() or
or![]() . We shall make similar assumptions as in the case of ML methods as given by Theorem 2.5 of Newey and McFadden [16] (p. 2131) and use Jensen’s inequality to show
. We shall make similar assumptions as in the case of ML methods as given by Theorem 2.5 of Newey and McFadden [16] (p. 2131) and use Jensen’s inequality to show![]() . The assumptions are:
. The assumptions are:
1)![]() , i.e., identification assumption for the parametric family.
, i.e., identification assumption for the parametric family.
2) The vector ![]() is an interior point of the compact parameter space θ.
is an interior point of the compact parameter space θ.
3) ![]() is continuous with respect to
is continuous with respect to![]() .
.
The conditions (1 - 3) as given above hold in general, it has been shown that conditions for MSP estimators to be consistent are more relaxed than the condition
![]() (17)
(17)
as given by Theorem 2.5 of Newey and McFadden [16] for ML estimators to be consistent but the proofs are very technical and might discourage practitioners to use MSP method or GSP methods in general, see Shao and Hahn [19] and Ekström [20] . We can also compare expression (17) with condition 2 of Theorem 2. In fact, the MSP method originally proposed by Cheng and Amin [1] is for circumstances where ML estimators fail to be consistent and the method was called maximum product of spacings method. Anatolyev and Kosenok [3] also found in many parametric families MSP estimators perform better than ML estimators in finite samples yet being as efficient as ML estimators in large samples. These findings make this class of GSP methods interesting and it is not more complicated to implement GSP methods than ML methods. Now having the entire class defined using a convex function![]() , it also allows the flexibility to choose a robust method within this class.
, it also allows the flexibility to choose a robust method within this class.
Since ![]() is obtained from a limit operation as
is obtained from a limit operation as![]() , we work with the limit density as given by expression (10) with
, we work with the limit density as given by expression (10) with ![]() for the expression
for the expression![]() . By making the change of variables using
. By making the change of variables using![]() ,
, ![]() , the joint density using expression (10) for u and v can be seen to be
, the joint density using expression (10) for u and v can be seen to be
![]() and
and![]() . (18)
. (18)
It is not difficult to see that:
1) ![]() and
and ![]() are independent,
are independent,
2) the marginal density of W is standard exponential, i.e., the density for W is![]() ,
,
3) the marginal density for ![]() is simply
is simply![]() .
.
We shall see subsequently in the next sections that these properties allow many asymptotic results to be obtained in a unified way and simplify proofs for some results which already appeared in the literature and allow asymptotic normality to be established for the GSP estimators for multi-parameters estimation which have been established in the paper by Ghosh and Jammalamadaka [6] but the approach is different in this paper. This also facilitates the establishment of asymptotic distribution theory for the parametric tests such as the Wald, score and quasi-likelihood ratio tests for the GSP methods. These tests have their counterparts in likelihood theory or quasi-likelihood theory.
In fact, for asymptotic properties we essentially work with ![]() and
and![]() ;
; ![]() have a common distribution and are pairwise independent as discussed earlier.
have a common distribution and are pairwise independent as discussed earlier.
We shall see in the next sections by considering ![]() as an iid sequence, we still have the same asymptotic statistical results for estimators and parametric tests as considering the terms of the sequence
as an iid sequence, we still have the same asymptotic statistical results for estimators and parametric tests as considering the terms of the sequence ![]() has a common distribution and they are pairwise independent. This shows that the assumption of an iid sequence provides a close enough approximation to the true sequence so that asymptotic results for efficiency on estimation and asymptotic distributions for parameter test statistics are unaffected.
has a common distribution and they are pairwise independent. This shows that the assumption of an iid sequence provides a close enough approximation to the true sequence so that asymptotic results for efficiency on estimation and asymptotic distributions for parameter test statistics are unaffected.
For establishing![]() , it suffices to show that
, it suffices to show that![]() . Using expression (16) we can see that
. Using expression (16) we can see that
![]() (19)
(19)
and using expression (16) with a change of order of integration,
![]() .
.
The inner integral can be expressed as
![]()
and since ![]() is convex, we can use Jensen’s inequality, see Lehmann and Casella [19] (p. 46-47) for example to conclude
is convex, we can use Jensen’s inequality, see Lehmann and Casella [19] (p. 46-47) for example to conclude
![]()
since![]() .
.
Therefore,
![]() .
.
This completes the proof for the inequality.
Furthermore, by making a change of variable we can put
![]() (20)
(20)
which is the expression used by Ghosh and Jammalamadaka [6] (p. 80) to justify consistency for GSP estimators. In the next section, we turn our attention to asymptotic normality and we shall see that GSP methods can be viewed as quasi-likelihood methods and M-estimation theory can be used to establish asymptotic results.
3.2. Asymptotic Normality and Robustness
For asymptotic normality, often we work with an expression with n being finite then passing to the limit to get the asymptotic results by letting ![]() and to make the presentation of the proof easier to follow, we define some notations. For finite n, we have seen
and to make the presentation of the proof easier to follow, we define some notations. For finite n, we have seen ![]() and to alleviate the notations we also use
and to alleviate the notations we also use ![]() and since they have the same distribution we let
and since they have the same distribution we let ![]() to denote one of them and to emphasize the dependence on n if necessary.
to denote one of them and to emphasize the dependence on n if necessary.
When passing to the limit by letting ![]() we end up working with the sequence
we end up working with the sequence ![]() and again since the terms of this sequence have the same distribution we let
and again since the terms of this sequence have the same distribution we let ![]() to denote one of them. For establishing asymptotic normality under standard conditions which are similar to the ones for ML estimators, we make some assumptions on differentiability on the term
to denote one of them. For establishing asymptotic normality under standard conditions which are similar to the ones for ML estimators, we make some assumptions on differentiability on the term ![]() which plays a similar role for
which plays a similar role for ![]() for likelihood theory.
for likelihood theory.
The asymptotic normality results might continue to hold with less stringent conditions for some parametric families but the proofs would be technical and similar to proofs for maximum likelihood estimators under the nonstandard conditions as in M-estimation theory which are given by Huber [21] (p. 43-51). Fist we state a Theorem for CLT for an α-mixing sequence which is Theorem2.4 by White and Domowitz [6] (p. 147-148) but restated as Theorem 3 below.
Theorem 3 (CLT)
Let ![]() be an α-mixing sequence and define the partial sums
be an α-mixing sequence and define the partial sums ![]() and
and
![]() ,
,
Assume that:
1)![]() .
.
2) There exists K finite and nonzero such that ![]() as
as ![]() for all a, a is a positive integer.
for all a, a is a positive integer.
3) ![]() for all t and some
for all t and some![]() .
.
4) The mixing coefficient ![]() with
with![]() .
.
Then![]() .
.
Often, we need to apply Theorem 3 in a multivariate context, Cramer-Wold devices can be used together with Theorem 3, see Davidson [17] (p. 405-407) for these devices. We also define the following notations.
Let
![]()
be the first, second and third derivatives of the function ![]() with respect to the elements of the vector
with respect to the elements of the vector ![]() and we shall assume that:
and we shall assume that:
1) The above partial derivatives are continuous with respect to elements of![]() .
.
2) The expectations ![]() and
and ![]() .
.
3) ![]() and
and![]() .
.
4) Interchanging order of integration and differentiation is allowed as in likelihood theory so that
![]() ,
,
and the Fisher information ![]() can also be expressed as
can also be expressed as
![]() .
.
5) The convergence of ![]() as
as ![]() needs to be strengthened to uniform convergence so that
needs to be strengthened to uniform convergence so that
![]() .
.
These functions are with respect to![]() .
.
6) The vector ![]() is an interior point of the parameter space θ, θ assumed to be compact.
is an interior point of the parameter space θ, θ assumed to be compact.
For condition (5), a sufficient condition to have uniform convergence is the sequence of functions with respect to![]() ,
, ![]() is equicontinuous, see Rudin [22] (p. 152-158, p. 168) for these related properties and Davidson and Donsig [23] (p. 54) for the Lipchitz property as it can be used to show equicontinuity for a sequence of functions and the Lipchitz property is related to the partial derivatives of the sequence of functions.
is equicontinuous, see Rudin [22] (p. 152-158, p. 168) for these related properties and Davidson and Donsig [23] (p. 54) for the Lipchitz property as it can be used to show equicontinuity for a sequence of functions and the Lipchitz property is related to the partial derivatives of the sequence of functions.
Now we can state the following Theorem which is Theorem 4 which give the asymptotic normality results for the GSP estimators in general, i.e., for the multi parameters case and we also verify the result given by expression (9) obtained by Ghosh and Jammalamadaka [6] (p. 76).
Theorem 4 (Asymptotic Normality)
Under Assumptions (165) as given above, then we have the following convergence in distribution for the vector of GSP estimators ![]() to a multivariate normal distribution,
to a multivariate normal distribution,
![]() ,
, ![]() ,
,
1)![]() ,
,
2) ![]() being the covariance matrix of the vector of
being the covariance matrix of the vector of ![]() under
under![]() .
.
3) ![]() is the vector of partial derivatives of
is the vector of partial derivatives of ![]() and
and ![]() is the second derivative matrix of
is the second derivative matrix of ![]() with respect to the elements of the vector
with respect to the elements of the vector![]() ,
,![]() ,
, ![]() as given by expression (23).
as given by expression (23).
Proof.
Under differentiability assumptions made, the vector of GSP estimators ![]() is given as roots of the following system of equation as
is given as roots of the following system of equation as ![]() minimizes
minimizes![]() , i.e.,
, i.e.,
![]() .
.
Using a Taylor expansion around the true vector of parameters ![]() of the above system allows us to express
of the above system allows us to express
![]() (21)
(21)
with ![]() is an expression which converges to 0 in probability faster than
is an expression which converges to 0 in probability faster than![]() .
.
From expression (21), we have the following representation using equality in distribution
![]() .
.
We can proceed by using ![]() first but for asymptotic property we let
first but for asymptotic property we let![]() , so the same conclusion is reached by assuming we have the model as
, so the same conclusion is reached by assuming we have the model as ![]() or alternatively, if we derive asymptotic results we can consider
or alternatively, if we derive asymptotic results we can consider ![]() and the bivariate observations which form the sequence follow the common bivariate density as given by expression (10); also they are pairwise independent or it turns out the same asymptotic results can be obtained as the sequence is an iid sequence as it does not affect the asymptotic results that we aim to have. By doing so, we do not need to carry the notation
and the bivariate observations which form the sequence follow the common bivariate density as given by expression (10); also they are pairwise independent or it turns out the same asymptotic results can be obtained as the sequence is an iid sequence as it does not affect the asymptotic results that we aim to have. By doing so, we do not need to carry the notation![]() . For asymptotic properties with
. For asymptotic properties with![]() , simply we can let
, simply we can let![]() , and use the properties which states that
, and use the properties which states that ![]() and
and ![]() are independent,
are independent, ![]() follows a standard exponential distribution.
follows a standard exponential distribution.
It is not difficult to see that:
1) ![]() being the average of α-mixing random variables with a common distribution so that the law of large numbers can be applied and therefore,
being the average of α-mixing random variables with a common distribution so that the law of large numbers can be applied and therefore,![]() .
.
2) Similarly, ![]() with
with ![]() being the covariance matrix of the vector of
being the covariance matrix of the vector of ![]() under
under![]() .
.
We shall show that![]() , see expression (23) given below so that
, see expression (23) given below so that
![]() . (20)
. (20)
Now applying Slutzky’s Theorem if needed as in likelihood theory, we have![]() ,
, ![]() is similar to the result obtained for quasi-likelihood estimators or M-estimators, see expression (12.18) given by Woolridge [24] (p. 407) for the asymptotic covariance matrix of M-estimators. Consequently, using the similarities with M-estimators, M-estimation theory can be used if needed to investigate the GSP estimators. This ends the proof.
is similar to the result obtained for quasi-likelihood estimators or M-estimators, see expression (12.18) given by Woolridge [24] (p. 407) for the asymptotic covariance matrix of M-estimators. Consequently, using the similarities with M-estimators, M-estimation theory can be used if needed to investigate the GSP estimators. This ends the proof.
Subsequently, we shall display the matrices ![]() and after simplifications made. First, we consider the matrix
and after simplifications made. First, we consider the matrix
![]()
and with expectation taken will give
![]() .
.
Note that
![]() (22)
(22)
by letting
![]() ,
,
![]() and
and ![]() to denote the first and second derivatives of
to denote the first and second derivatives of![]() . Clearly,
. Clearly,
![]() (23)
(23)
using the independence of ![]() and x. This property is similar to the unbiasedness of the quasi-scores of quasi-likelihood methods or in M-estimation theory. This property also justifies the equality given by expression (20).
and x. This property is similar to the unbiasedness of the quasi-scores of quasi-likelihood methods or in M-estimation theory. This property also justifies the equality given by expression (20).
The elements of the matrix ![]() are given by taking expectations of the following elements,
are given by taking expectations of the following elements,
![]()
Note that the second term of the RHS of the above equality can be expressed as
![]()
and upon taking expectation, it is reduced to 0 as
![]() and
and![]() . (24)
. (24)
Let
![]()
which implies
![]()
using ![]() which follows a standard exponential distribution; W and x are independent and properties from expression (18). Using these properties if necessary, the matrix
which follows a standard exponential distribution; W and x are independent and properties from expression (18). Using these properties if necessary, the matrix![]() ,
, ![]() is the Fisher information matrix as commonly defined in likelihood theory.
is the Fisher information matrix as commonly defined in likelihood theory.
For comparison with results given by Ghosh and Jammalamadaka [6] , ![]() coincides with the corresponding result given as the limit in probability of the
coincides with the corresponding result given as the limit in probability of the
expression ![]() by Ghosh and Jammalamadaka [6] (p. 81) for the one parameter set-up.
by Ghosh and Jammalamadaka [6] (p. 81) for the one parameter set-up.
It is not difficult to see that the elements of ![]() with
with
![]()
are
![]() ,
,
using the independence of ![]() and x which implies the independence of
and x which implies the independence of ![]() and
and
![]()
for ![]() and expression (23).
and expression (23).
Therefore, ![]() and
and ![]() which implies
which implies![]() ,
,
![]() . (25)
. (25)
The expression for ![]() is very similar to the one in M-estimation theory, see expression (12.18) given by Woolridge [24] (p. 407).
is very similar to the one in M-estimation theory, see expression (12.18) given by Woolridge [24] (p. 407).
The asymptotic covariance for ![]() is given as
is given as
![]() . (26)
. (26)
At this point, we would like to make some remarks which are given below.
Remark 1
It appears that a minor adjustment is needed for expression (9) given by Ghosh and Jammalamadaka [6] (p. 76) which gives
![]() (27)
(27)
It appears that the term ![]() which appears in the numerator of the above expression for
which appears in the numerator of the above expression for![]() ,
, ![]() is not needed and can be removed, using the properties based on expression (18), also see expression (23) and the derivations of the elements of
is not needed and can be removed, using the properties based on expression (18), also see expression (23) and the derivations of the elements of ![]() for the proof of Theorem 4.
for the proof of Theorem 4.
An interpretation of asymptotic relative efficiency of the GSP method versus the MSP method can be given to![]() . Also, using the gamma function
. Also, using the gamma function![]() , we can obtain for k being a real number and
, we can obtain for k being a real number and![]() ,
,![]() from the moment generating function of the log-gamma distribution which gives
from the moment generating function of the log-gamma distribution which gives
![]() .
.
For the moment generating function of the log-gamma distribution, see Chan [25] .
Remark 2
By relating with M-estimators, we can study the efficiency and robustness for GSP estimators based on a function ![]() used to generate the estimators. It can be seen from the asymptotic results established earlier, the GSP estimators are asymptotically equivalent to M-estimators defined be the following estimating equations
used to generate the estimators. It can be seen from the asymptotic results established earlier, the GSP estimators are asymptotically equivalent to M-estimators defined be the following estimating equations
![]() ,
, ![]()
is the vector of quasi-score functions.
From M-estimation theory, we already know that for efficiency ![]() must be proportional to the score functions
must be proportional to the score functions
![]() clearly
clearly ![]() with
with ![]()
is optimal as in this case,
![]()
which shows that MSP method is efficient as ML method. This finding has been reported by Ghosh and Jammalamadaka [6] (p. 76) and within the class considered, this is the only optimum choice but the question of robustness has not been discussed. If
![]()
is not bounded as a function of x, the MSP estimators might not be robust despite they are efficient.
For robustness we might want to choose ![]() will
will ![]() but near 0, such choices of
but near 0, such choices of ![]() are suboptimal within the GJ class but they can balance efficiency and robustness. With these choices, the corresponding quasi-score functions are given by
are suboptimal within the GJ class but they can balance efficiency and robustness. With these choices, the corresponding quasi-score functions are given by
![]() (27)
(27)
and clearly ![]() will be bounded as in general having the component
will be bounded as in general having the component ![]() will be able to keep
will be able to keep ![]() bounded as
bounded as ![]() is a density function and assuming
is a density function and assuming ![]() only when
only when ![]() and we have
and we have ![]() as
as![]() . Clearly, with
. Clearly, with![]() , we reobtain the true score functions. The class of pseudo-distance methods as introduced by Broniatowski et al. [12] also share the same type of properties as members of the class can generate quasi-score functions which can approximate the true score functions. One interesting feature of the GJ class is the class also includes the member that generates the true score functions.
, we reobtain the true score functions. The class of pseudo-distance methods as introduced by Broniatowski et al. [12] also share the same type of properties as members of the class can generate quasi-score functions which can approximate the true score functions. One interesting feature of the GJ class is the class also includes the member that generates the true score functions.
Remark 3
Only for the MSP case that we have![]() ,
, ![]() and
and ![]() are as given in Theorem 4 with
are as given in Theorem 4 with ![]() and only in this case all three tests with their asymptotic distributions as given in section 4 can be used, for other GSP methods we no longer have
and only in this case all three tests with their asymptotic distributions as given in section 4 can be used, for other GSP methods we no longer have ![]() only the Wald test and score test can be used for hypothesis testing with the asymptotic distributions are established and given in section 4, this situation is similar to the one encountered for quasi-likelihood estimation. These three classical tests form the trinity test and the versions for GSP methods will be presented in the next section.
only the Wald test and score test can be used for hypothesis testing with the asymptotic distributions are established and given in section 4, this situation is similar to the one encountered for quasi-likelihood estimation. These three classical tests form the trinity test and the versions for GSP methods will be presented in the next section.
4. Parameter Hypothesis Testing
Now having the asymptotic results for![]() , we can turn to the question of testing hypothesis and construction of the classical tests such as the Wald test, Lagrange multipliers or Rao’s score test and test based on the change of the objective function for the GSP methods. These tests do not seem to have been discussed in the literature for the GSP methods and they are parallel to the tests used for likelihood or quasi-likelihood methods. For these tests using maximum likelihood methods, see Gallant [26] (p. 178-182); also see Woolridge [24] (p. 420-429). For these tests, implicitly we assume that
, we can turn to the question of testing hypothesis and construction of the classical tests such as the Wald test, Lagrange multipliers or Rao’s score test and test based on the change of the objective function for the GSP methods. These tests do not seem to have been discussed in the literature for the GSP methods and they are parallel to the tests used for likelihood or quasi-likelihood methods. For these tests using maximum likelihood methods, see Gallant [26] (p. 178-182); also see Woolridge [24] (p. 420-429). For these tests, implicitly we assume that ![]() is an interior point of the restricted parameter space. The original parameter space is restricted by the conditions imposed by the null hypothesis
is an interior point of the restricted parameter space. The original parameter space is restricted by the conditions imposed by the null hypothesis![]() .
.
4.1. Wald Test
Often, we are interested to test the null hypothesis which specifies that ![]() belongs to a subset of the parameter space
belongs to a subset of the parameter space![]() , this is phrased as restrictions imposed on
, this is phrased as restrictions imposed on ![]() via a vector functions
via a vector functions ![]() which satisfies
which satisfies ![]() under the null hypothesis
under the null hypothesis ![]() and we assume that
and we assume that![]() . With
. With![]() , we then have the Jacobian matrix
, we then have the Jacobian matrix
![]() and let
and let![]() .
.
These matrices are assumed to have rank q. With an application of the delta method, we can say that the asymptotic covariance matrix of![]() , as
, as ![]() is simply
is simply![]() .
.
Applying Wald’s method to construct chi-square statistic using ![]() will lead to the following quadratic form with a chi-square asymptotic distribution with q degree of freedom using standard results for distribution of quadratic forms.
will lead to the following quadratic form with a chi-square asymptotic distribution with q degree of freedom using standard results for distribution of quadratic forms.
Therefore, we have an asymptotic chi-square distribution with q degree of freedom as given below, ![]() is used to denote convergence in distribution and
is used to denote convergence in distribution and ![]() is used to denote an expression which converges to 0 in probability,
is used to denote an expression which converges to 0 in probability,
![]() .
.
Replacing ![]() by
by![]() , we can estimate
, we can estimate ![]() by
by ![]() and the Wald test statistic is given by
and the Wald test statistic is given by
![]() (28)
(28)
4.2. Score Test or LM Test
The score test is also called Lagrange multiplier (LM) test, it can be derived using the Lagrange multipliers but they do not need to be calculated explicitly as they can be expressed using the quasi-score function of the GSP methods. We only need to fit the restricted model which is specified by the null hypothesis. The vector for restricted estimators is denoted by ![]() obtained by minimizing under the constraints
obtained by minimizing under the constraints![]() . The vector for the unrestricted estimators is denoted by
. The vector for the unrestricted estimators is denoted by![]() .
.
For minimizing under q constraints, we introduce the vector of Lagrange multipliers ![]() and form the Lagrangian function
and form the Lagrangian function ![]() , also let
, also let
![]()
which can be viewed as the quasi-score of the GSP methods, this will parallel GSP methods with quasi-likelihood methods or likelihood methods. The first order conditions using ![]() will give us the following two systems of equations so that
will give us the following two systems of equations so that ![]() and
and ![]() should satisfy
should satisfy
![]() , (29)
, (29)
![]() . (30)
. (30)
A Taylor series expansion on the system (29) and (30) around![]() , with
, with ![]() and assuming
and assuming ![]() under
under ![]() coupled with multiplying by a factor
coupled with multiplying by a factor ![]() yields the following two systems of equations which are given by
yields the following two systems of equations which are given by
![]()
as![]() ,
, ![]() ,
, ![]() is an expression which converges to 0 in probability.
is an expression which converges to 0 in probability.
Multiply the first system by ![]() and using the second system gives the following system of equation expressed using equality in distribution,
and using the second system gives the following system of equation expressed using equality in distribution,
![]()
with
![]()
as in the proof of Theorem 4. Therefore, using expression (29), we then have
![]() .
.
Let
![]()
then ![]() with
with![]() , Wald’s method applying on
, Wald’s method applying on ![]() leads to
leads to
![]()
and replacing ![]() by
by ![]() leads to the Rao’s score test or LM test statistic defined as
leads to the Rao’s score test or LM test statistic defined as
![]() (31)
(31)
R is with an asymptotic chi-square distribution with q degree of freedom.
Equivalently, if we can assume that ![]() as indicated by Woolridge [24] (p. 425), we can let
as indicated by Woolridge [24] (p. 425), we can let
![]() , (32)
, (32)
using a result established by Wooldrige [24] (p. 424) and expression (12.69) which is based on optimization theory and linear algebra which states that for this type of minimization under constraints, we have with the assumption ![]() i.e., only for the MSP case that we have:
i.e., only for the MSP case that we have: ![]() and a matrix
and a matrix ![]() with
with ![]() and
and
![]()
such that![]() .
.
The proof is involved and requires preliminary results for linear algebra, we shall not reproduce here, see Wooldrige [24] (p. 424) instead. Now pre and post multiply the RHS of the above expression by
![]()
will give the expression (32) for R. Note that expression (31) holds in general without the additional assumption ![]() and suitable for GSP methods other than MSP method.
and suitable for GSP methods other than MSP method.
Note that for the use of the score test, only the reduced model under ![]() needs to be fitted to obtain
needs to be fitted to obtain![]() . This test is of interest under the circumstance when fitting the reduced model is less problematic than fitting the full model without the restrictions. The first test which is the Wald test, one needs to work with the full model. For Wald test and score test, the asymptotic covariances of some expressions need to be obtained.
. This test is of interest under the circumstance when fitting the reduced model is less problematic than fitting the full model without the restrictions. The first test which is the Wald test, one needs to work with the full model. For Wald test and score test, the asymptotic covariances of some expressions need to be obtained.
The following test which is the quasi-likelihood ratio test, we do not need the expressions for asymptotic covariance matrices where partial derivatives are involved but we need to fit the reduced model and the full model to obtain both ![]() and
and ![]() and the quasi-likelihood likelihood ratio test is only applicable for the MSP method.
and the quasi-likelihood likelihood ratio test is only applicable for the MSP method.
4.3. Quasi-Likelihood Ratio Test
The quasi-likelihood ratio test makes use of a statistic which is based on the change of the objective function obtained by fitting the full model and the reduced model, it can be expressed as
![]()
and we shall see that again we have a chi-square asymptotic distribution for the QLR statistic with ![]() assuming
assuming![]() . Without this condition, the score test as given by expression (31) and Wald test can be used but not the QLR test with an asymptotic chi-square distribution with q degree of freedom. These two tests are asymptotic equivalent under
. Without this condition, the score test as given by expression (31) and Wald test can be used but not the QLR test with an asymptotic chi-square distribution with q degree of freedom. These two tests are asymptotic equivalent under![]() .
.
We justify the asymptotic distribution as given above for the QLR statistic by expanding ![]() around the vector of unrestricted estimators
around the vector of unrestricted estimators ![]() and using
and using
![]() ,
, ![]() to express
to express
![]()
with ![]() converges to
in probability faster than
converges to
in probability faster than ![]() which gives
which gives
![]() .
.
But with a Taylor expansion again around![]() ,
,
![]()
with
![]() ,
, ![]()
This implies
![]()
and using the quasi-score functions,
![]()
which is equivalent to the score statistic,
![]() . (33)
. (33)
We end this section by noting that GSP methods for multivariate models have been introduced by Kuljus and Ranneby [27] with consistency properties established for the GSP estimators. The approach used in this paper might also be used for a multivariate set up for asymptotic normality results and might lead to similar results as the ones obtained for the univariate case.
5. Conclusion
Asymptotic results for the GSP methods are obtained and presented in a unified way with fewer technicalities which parallel likelihood methods. The implementation of the methods is not more complicated than the implementation of likelihood or quasi-likelihood methods, and the GJ class is large enough to allow more choices for robustness if needed for some parametric models, and at the same time the MSP method within this class is as efficient as likelihood method for continuous univariate models. With all these properties of the GSP methods and simple presentation, we hope to show that these methods are indeed very powerful and useful for continuous univariate models but appear to be under used. Practitioners might want to implement these methods in various fields which include actuarial science for their applied works as they are not more complicated than quasi-likelihood methods.
Acknowledgements
The helpful and constructive comments of reviewers which lead to an improvement of the presentation of the paper and support from the editorial staffs of Open Journal of Statistics to process the paper are all gratefully acknowledged.