Paper Menu >>
Journal Menu >>
 Int. J. Communications, Network and System Sciences, 2009, 2, 742-745 doi:10.4236/ijcns.2009.28085 blished Online November 2009 (http://www.SciRP.org/journal/ijcns/). Copyright © 2009 SciRes. IJCNS Pu A Perceptual Approach to Reduce Musical Noise Using Critical Bands Tonality Coefficients and Masking Thresholds Ch. V. Rama Rao1, M. B. Rama Murthy2, K. Srinivasa Rao3 1Department of ECE, Gudlavalleru Engineering College, Gudlavalleru, India 2Jayaprakash Narayan College of Engineering, Dharmapur, Mahabubnagar, India 3TRR College of Engineering, Pathancheru, India Email: chvramaraogec@gmail.com Received August 18, 2009; revised September 27, 2009; accepted October 19, 2009 Abstract Traditional noise reduction techniques have the drawback of generating an annoying musical noise. A new scheme for speech enhancement in high noise environment is developed by considering human auditory sys- tem masking characteristics. The new scheme considers the masking threshold of both noisy speech and the denoised one, to detect musical noise components. To make them inaudible, they are set under the noise masking threshold. The improved signal is subjected to extensive subjective and objective tests. It is ob- served that the musical noise is appreciably reduced even at very low signal to noise ratios. Keywords: Noise Reduction, Musical Noise, Masking Threshold 1. Introduction In many speech communication systems, enhancing the corrupted speech is a challenging task especially at high noise level. A large number of noise reduction tech- niques have been proposed in the past. They are based on spectral subtraction [1] and Wiener filtering [2] tech- niques. The main drawback of these methods is the ap- pearance of an annoying residual noise, often referred to as musical noise. Later techniques developed rely on psychoacoustical considerations. Mainly they exploit the masking properties of the human auditory system. For example according to the enhancement scheme proposed in [3], only audible noise components are estimated and suppressed. Other approaches introduce a perceptual mo- dification on traditional denoising systems [4,5]. In the present paper a new speech enhancement tech- nique is developed for reducing the musical noise. In this work, the auditory masking threshold is estimated for musical noise detection and reduction. Musical noise is detected based on fact that musical noise components present in the enhanced signal lie above the noise mask- ing threshold. On the other hand, the frequency compo- nents of noisy speech lie below the noise masking threshold. Hence, by using some comparison rules musi- cal noise is detected. The detected musical noise com- ponents are set under the noise masking threshold and their closet neighbours are smoothed resulting in musical noise reduction. 2. Basic Speech Enhancement System Let the corrupted speech signal be represented as ()yn () ()()yn sn dn (1) where is the clean speech signal and is the noise signal. The processing is done on a frame-by-frame basis. The Short Time Fourier transform (STFT) is used and the previous model is re-written as )( ns ()dn ),(),(),( fmDfmSfmY (2) where m indicates the frame index and f is the frequency index. The denoised speech short time magnitude (,)Smf is obtained using a spectral denoising ap- proach. In this paper, modified Wiener filter [6] is used to denoise the speech signal. The denoised speech is ob- tained as follows  C. V. R. RAO ET AL. 743 ),().,(),( fmYfmWfmS (3) where is the modified Wiener filter gain [6], obtained by including the cross correlation between clean speech signal and noise signal. is given by ),( fmW ),( fmW 2 2 .( ,)( ,) (,) (,) (,) .(, )(, ) (,)12 (,) Ymf Dmf mf ED mf Wmf Ymf Dmf mf ED mf (4) where is apriori signal to noise ratio (SNR). 22 (,)(,)/(,)mfESmfED mf ),( fm is calculated ac- cording to the decision directed approach reported in [7]. is the cross correlation coefficient for estimating the correlation between the noisy speech and noise signal in a frame [6]. The modified wiener filter gain function is not only controlled by ),( fm as for conventional Wiener filter but also by . When is zero noise and clean speech signals are uncorrelated and is reduced to conventional Wiener filter gain function. The proposed approach consists on reducing musical noise existing in denoised speech signal spectrum denoted by ),( fmW 2 ),( ˆfms . The temporal domain enhanced speech is obtained with the following relationship )),(arg( .),( ˆ )( ˆfmYj efmSIFFTns (5) 3. Proposed Enhancement Technique The proposed enhancement technique consists of differ- ent steps described below. Modified Wiener filter gain function is applied to get denoised speech. The noise masking threshold NMT is calculated for both noisy speech and denoised one. A musical noise detector is used. For each fre- quency, it gives a Boolean flag M which indicates the presence or absence of musical noise. The musical noise is reduced when present. 3.1. Musical Noise Detection In order to detect musical noise in denoised speech, per- ceptual properties of human auditory system are used. There are two steps in detecting musical noise: calcula- tion of noise masking threshold, detection of tonal com- ponents in both noisy speech and denoised speech. 3.1.1. Noise Masking Threshold Calculation The NMT is obtained through modelling the frequency selectivity of the human ear and its masking property. By using masking threshold we distinguish “tone masking noise” and “noise masking tone”. In our context of mu- sical noise detection, we consider only the situation of “noise masking tone”. In fact, the musical noise is a tone signal which is audible during noise components. The NMT is calculated according to principle explained in [8]. 3.1.2. Tonal Components Detection Tonal and non tonal components are identified because their masking models are different. The power spectrum and noise masking threshold of both noisy speech and denoised speech are calculated. Components above noise masking threshold in noisy speech are treated as tonal and belong to speech components. Components above noise masking threshold in denoised speech are marked as tonal and belong to either speech components or mu- sical noise components. Hence, musical noise compo- nents can be detected and they are the marked tonal components appearing in denoised speech and not ap- pearing in noisy speech. Figure 1 shows locations of Sound Pressure Level (dB) Frequenc y ( Hz ) 100 0200300 400 500 600 700 800 0 5 10 15 20 25 (a) Sound Pressure Level (dB) Frequency (dB) 100 0200 300400 500 600 700800 18 16 14 12 10 8 6 4 2 0 Musical noise components (b) Figure 1. Location of tones in (a) noisy speech (b) denoised speech. C opyright © 2009 SciRes. IJCNS 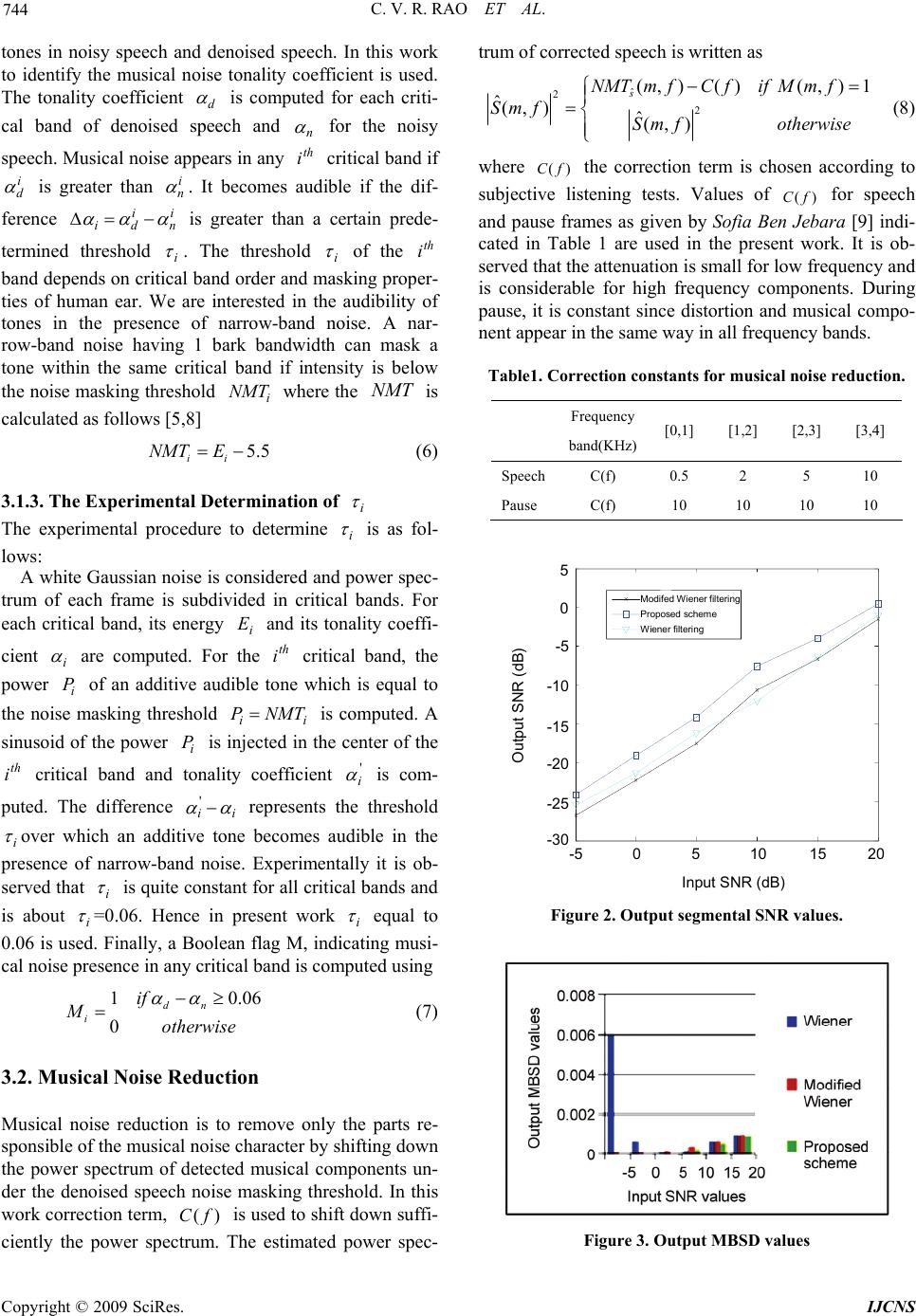 C. V. R. RAO ET AL. 744 .06 tones in noisy speech and denoised speech. In this work to identify the musical noise tonality coefficient is used. The tonality coefficient is computed for each criti- cal band of denoised speech and for the noisy speech. Musical noise appears in any critical band if is greater than . It becomes audible if the dif- ference is greater than a certain prede- termined threshold . The threshold of the band depends on critical band order and masking proper- ties of human ear. We are interested in the audibility of tones in the presence of narrow-band noise. A nar- row-band noise having 1 bark bandwidth can mask a tone within the same critical band if intensity is below the noise masking threshold where the is calculated as follows [5,8] d n th i i d i n i n i i di i th i i NMT NMT 5.5 ii NMT E (6) 3.1.3. The Experimental Determination of i The experimental procedure to determine is as fol- lows: i A white Gaussian noise is considered and power spec- trum of each frame is subdivided in critical bands. For each critical band, its energy and its tonality coeffi- cient are computed. For the critical band, the power of an additive audible tone which is equal to the noise masking threshold is computed. A sinusoid of the power is injected in the center of the critical band and tonality coefficient is com- puted. The difference represents the threshold over which an additive tone becomes audible in the presence of narrow-band noise. Experimentally it is ob- served that is quite constant for all critical bands and is about =0.06. Hence in present work equal to 0.06 is used. Finally, a Boolean flag M, indicating musi- cal noise presence in any critical band is computed using i E i P i i i P th i NMTi i P i ' th i i ' i i i i 10 0 dn i if Motherwise (7) 3.2. Musical Noise Reduction Musical noise reduction is to remove only the parts re- sponsible of the musical noise character by shifting down the power spectrum of detected musical components un- der the denoised speech noise masking threshold. In this work correction term, is used to shift down suffi- ciently the power spectrum. The estimated power spec- trum of corrected speech is written as )( fC ˆ 2 2 (,)()(,) 1 ˆ(,) ˆ(,) s NMTmfCfif Mmf Sm fSmf otherwise (8) where the correction term is chosen according to subjective listening tests. Values of for speech and pause frames as given by Sofia Ben Jebara [9] indi- cated in Table 1 are used in the present work. It is ob- served that the attenuation is small for low frequency and is considerable for high frequency components. During pause, it is constant since distortion and musical compo- nent appear in the same way in all frequency bands. )( fC )( fC Table1. Correction constants for musical noise reduction. Frequency band(KHz) [0,1] [1,2] [2,3] [3,4] SpeechC(f) 0.5 2 5 10 Pause C(f) 10 10 10 10 5 0 Input SNR ( dB ) Output SNR (dB) Modifed Wiener filtering Proposed scheme Wiener filtering -5 5 10 15 20 0 -5 -10 -15 -20 -25 -30 Figure 2. Output segmental SNR values. Figure 3. Output MBSD values Copyright © 2009 SciRes. IJCNS  C. V. R. RAO ET AL. Copyright © 2009 SciRes. IJCNS 745 musical noise imposed by a modified Wiener filtering is proposed. The masking characteristics of the human ear are used to detect and to reduce musical noise. Simula- tion results show that this scheme provides better results in terms of temporal, spectral and perceptual criteria. 6. References [1] S. F. Boll, “Suppression of acoustic noise in speech using spectral subtraction,” IEEE Transaction Acoustics, Speech and Signal Processing, Vol. ASSP-27, No. 2, pp. 113–120, April 1979. Figure 4. Spectrograms of (a). Noisy speech (b). Denoised speech (c). Enhanced speech by proposed scheme. [2] Y. Ephraim and D. Mallah, “Spectral enhancement using optimal non-linear spectral amplitude estimation,” on Proceedings of International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, pp. 1118–1121, 1983. 4. Results and Discussions [3] A. Akbari-Azrani, R. Le bouquin Jannes, and G. Faucon, “Optimizing speech enhancement by exploiting masking properties of the human ear,” on Proceedings Interna- tional Conferences on Acoustic, Speech and Signal Proc- essing ICASSP, IEEE, pp. 800–803, 1995. The proposed technique is evaluated using temporal, spectral and perceptual criteria. Segmental signal to noise ratio (SNRSEG) is used as quantitative temporal criteria. For spectral criteria, spectrograms are used and the Modified Bark spectral Distance (MBSD) is used as perceptual criteria [10]. [4] N. Virag, “Single channel speech enhancement based on masking properties of human auditory system,” IEEE Transactions on Speech and Audio Processing, Vol. 7, No. 2, pp. 126–137, February 1999. In our simulations, recorded speech samples are used and corrupted with white Gaussian noise and simulations are performed on MATLAB platform. Figure 2 and Fig- ure 3 shows the comparison of performance results of the classical Wiener filtering, modified Wiener filtering and the proposed scheme for different values of signal to noise ratio in terms of SNRSEG and MBSD values respec- tively. Figure 4 shows spectrogram plots. [5] K. A. Sheela, CH. V. R. Rao, K. S. Prasad, and A. V. N. Tilak, “A new noise reduction pre-processor for mobile voice communication using perceptually weighted spec- tral subtraction method,” 3rd International Conferences on Mobile Ubiquitous and Pervasive Computing, VIT Uni- versity, 16-19 December 2006. [6] CH. V. R. Rao, M. B. R. Murthy, and K. S. Rao, “Speech enhancement using modified Wiener filter,” National Conference on Futuristic Advancements in Computing & Electronics, Deccan College of Engineering & Technol- ogy, 19-21 March, 2009. Interpretations from the Figures 2, 3 and 4 are as fol- lows: The proposed scheme leads to better performance in terms of quality and intelligibility speech signal for all criteria and also it is well noticeable for spectral and perceptual criteria which have good correlation with lis- tening tests. [7] Y. Ephraim and D. Mallah, “Speech enhancement using a minimum mean square error short-time spectral ampli- tude estimator,” IEEE Transaction on Speech Audio Processing, Vol. ASSP-32, pp. 1109–1121, 1984. Spectrograms are considered in Figure 4. The noisy speech signal is a speech corruptedby a white Gaussian noise whose SNR=10 dB. The denoised speech signal by a modified Wiener filtering is affected by a musical noise (isolated points randomly distributed in time and fre- quency). The amount of such noise is reduced by the proposed scheme. [8] J. D. Johnston, “Transform coding of audio signal using perceptual noise criteria,” IEEE, Journal on Selected Ar- eas of Communication, Vol. 6, pp. 314–323, 1988. [9] S. B. Jebara, “A perceptual approach to reduce musical noise phenomenon with wiener denoising technique,” proceedings of IEEE International Conference on Acous- tics, Speech and Signal Processing, ICASSP, 2006. [10] W. Yan, M. Dixon, and R. Yantorno, “A modified bark spectral distortion measure which uses noise masking threshold,” on Proceedings of the Speech Coding Work- shop IEEE, pp. 55–56, 1997. 5. Conclusions In this work, a new enhancement scheme for reducing |