Open Journal of Applied Sciences, 2013, 3, 65-67
Published Online March 2013 (http://www.scirp.org/journal/ojapps)
Copyright © 2013 SciRes. OJAppS
A Programmable High Speed Vision System with
Superscalar PE and Its Parallel Computing Language
Jie Yang, Cong Shi, Xitian Long, Nanjian Wu
Institute of Semiconductors, Chinese Academy of Sciences, Beijing, China
Email: yangjie@semi.ac.cn
Received 2012
ABSTRACT
Pixe l-parallel PE and SIMD architectures are widely used in high-speed image processing to enhance computing power.
With fully exploiting the data level parallelism of low- and middle-level image processing, SIMD architecture is able to
finish great amount of computation with much less instruction cycle thus satisfy the high-speed system requirement.
The main computation parts in those SIMD image processing hardware is known as PE (processing element) and it is
responsible for transferring, storing and processing the image data. This paper describes a high-speed vision system
with superscalar PE to enhance system performance and its dedicated parallel computing language specifically devel-
oped for this vision system. The vision system can achieve motion detection at more than 2000fps and face detection at
more than 100 fps which overwhelms some general serial CPUs in the same applications.
Keywords: High-Speed Vision System; SIMD; Superscalar; PE
1. Introduction
Researchers have been interested in high -speed vision
system for decades [1]. It can be applied in many fields,
such as real-time object-tracking, machine vision, indus-
try controls. Traditional machine vision systems which
are composed of image sensor and general-purpose pro-
cessor have heavy I/O load induced by large amount of
image data transfer and lack of computational power for
low- and middle-level processing. Our previous design [2]
using multi-level parallel processors to fully cover low-,
middle-, and high-level image processing and with dedi-
cated programming language this design can finish vari-
ous high-speed image processing tasks. However the
image sensor exposure and data transfer of every frame
consume large amount of time and instruction cycles thus
greatly reduce the processing rate of our vision system.
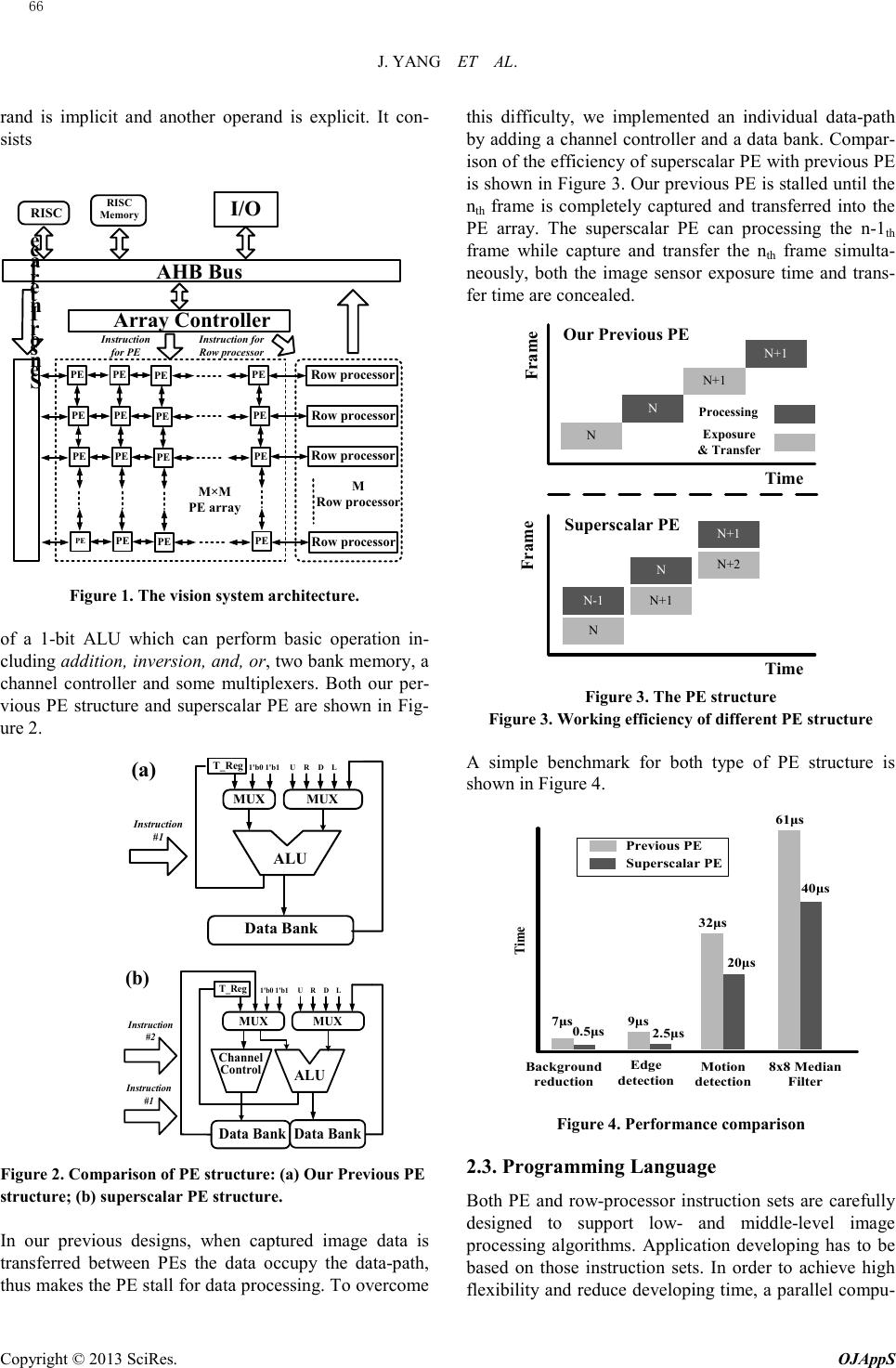
In this paper, we apply a superscalar PE to our pre-
vious architecture. The new PE structure is capable of
simultaneously executing an image transfer instruction
and an image processing instruction, thus frame pipeline
is achieved. A calculated PE performance improvement
is nearly 100% for some algorithms. A parallel compu-
ting language and its compiler and assembler are devel-
oped to support the new PE programming and related
further designs.
This paper proceeds as follows. In section II, we will
describe the architecture of our vision system, the new
PE structure and the parallel computing language. In sec-
tion III, the FPGA implementation is presented. And
finally we draw conclusion in section IV.
2. Architecture of the System
2.1. System Architecture
The architecture of the proposed vision system is pre-
sented in fig.1. It consists of a pixel-parallel PE array, a
row-parallel processor, a RISC core, an on-chip AHB
bus, a sensor controller and an I/O module. The sensor
interface is responsible for sub sampling the image plane.
The PE array is composed of M×M identical PEs, each
PE is a single bit processor connected with its up, down,
left, right PE neighborhoods. The row-parallel processors
serve as the interface of PE array with the RISC core and
carry out middle-level image processing. The RISC core
controls the whole system and performs high-level image
pro c e ssing.
In summary, the system architecture integrates three
different kinds of processors targets at different levels of
image processing. It is specifically designed for
high -speed image processing.
2.2. PE Structure
Every PE cell is connected to its nearest four neighbors
in four directions: up, right, down, left. All PEs receive
the same instructions and operate in an SIMD fashion.
PE is built in accumulator architecture [3] that one ope-