About Multichannel Speech Signal Extraction and Separation Techniques ()
1. Introduction
Most audio signals result from the mixing of several sound sources. In many applications, there is a need to separate the multiple sources or extract a source of interest while reducing undesired interfering signals and noise. The estimated signals may then be either directly listened to or further processed, giving rise to a wide range of applications such as hearing aids, human computer interaction, surveillance, and hands-free telephony [1].
The extraction of a desired speech signal from a mixture of multiple signals is classically referred to as the “cocktail party problem” [2,3], where different conversations occur simultaneously and independently of each other.
The human auditory system shows a remarkable ability to segregate only one conversation in a highly noisy environment, such as in a cocktail party environment. However, it remains extremely challenging for machines to replicate even part of such functionalities. Despite being studied for decades, the cocktail party problem remains a scientific challenge that demands further research efforts [4].
As highlighted in some recent works [5], using a single channel is not possible to improve both intelligibility and quality of the recovered signal at the same time. Quality can be improved at the expense of sacrificing intelligibility. A way to overcome this limitation is to add some spatial information to the time/frequency information available in the single channel case. Actually, this additional information could be obtained by using two or more channel of noisy speech named multichannel.
Three techniques of Multi Channel Speech Signal Separation and Extraction (MCSSE) can be defined. The first two techniques are designed to determined and overdetermined mixtures (when the number of sources is smaller than or equal to the number of mixtures) and the third is designed to underdetermined mixtures (when the number of sources is larger than the number of mixtures). The former is based on two famous approaches, the Blind Source Separation (BSS) techniques [5-7] and the Beamforming techniques [8-10].
BSS aims at separating all the involved sources, by exploiting their independent statistical properties, regardless their attribution to the desired or interfering sources.
On the other hand, the Beamforming techniques, concentrate on enhancing the sum of the desired sources while treating all other signals as interfering sources. While the latter uses the knowledge of speech signal properties for separation.
One popular approach to sparsity based separation is T-F masking [11-13]. This approach is a special case of non-linear time-varying filtering that estimates the desired source from a mixture signal by applying a T-F mask that attenuates T-F points associated with interfering signals while preserving T-F points where the signal of interest is dominant.
In the last years, the researches in this area based their approaches on combination techniques as ICA and binary T-F masking [14], Beamforming and a time frequency binary mask [15].
This paper is concerned with a survey of the main ideas in the area of speech separation and extraction from a multiple microphones.
The following sections of this paper are organized as follows: in Section 2, the problem of speech separation and extraction is formulated. In Section 3, we describe some of the most techniques which have been used in MCSSE systems, such as Beamforming, ICA and T-F masking techniques. Section 4 brings to the surface the most recent methods for MCSSE systems, where combined techniques, seen previously, are used. In Section 5, the presented methods will be discussed by giving some of their advantages and limits. Finally, Section 6 gives a synopsis of the whole paper and conveys some futures works.
2. Problem Formulation
There are many scenarios where audio mixtures can be obtained. This results in different characteristics of the sources and the mixing process that can be exploited by the separation methods. The observed spatial properties of audio signals depend on the spatial distribution of a sound source, the sound scene acoustics, the distance between the source and the microphones, and the directivity of the microphones.
In general, the problem of MCSSE is stated to be the process of estimating the signals from N unobserved sources, given from M microphones, which arises when the signals from the N unobserved sources are linearly mixed together as presented in Figure 1.
The signal recorded at the jth microphone can be modeled as:
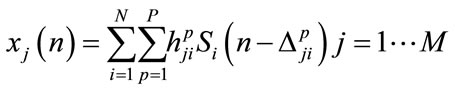 (1)
(1)
where  and
and  are the source and mixture signals respectively, hji is a P-point Room Impulse Response (RIR) from source i to microphone j, P is the number of paths between each source-microphone pair and
are the source and mixture signals respectively, hji is a P-point Room Impulse Response (RIR) from source i to microphone j, P is the number of paths between each source-microphone pair and  is the delay of the pth path from source j to microphone i [9-14]. This model is the most natural mixing model, encountered in live recordings called echoic mixtures.
is the delay of the pth path from source j to microphone i [9-14]. This model is the most natural mixing model, encountered in live recordings called echoic mixtures.
In free-reverberation environments (p = 1), the samples of each source signal can arrive at the microphones only from the line of sight path, and the attenuation and delay of source i would be determined by the physical position of the source relative to the microphones. This model, called anechoic mixing, is described by the following equation obtained from the previous equation:

Figure 1. Multichannel problem formulation.
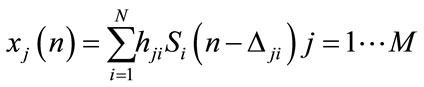 (2)
(2)
The instantaneous mixing model is a specific case of the anechoic mixing model where the samples of each source arrive at the microphones at the same time  with differing attenuations, each element of the mixing matrix
with differing attenuations, each element of the mixing matrix  is a scalar that represents the amplitude scaling between source i and microphone j. From the Equation (2), instantaneous mixing model can be expressed as:
is a scalar that represents the amplitude scaling between source i and microphone j. From the Equation (2), instantaneous mixing model can be expressed as:
 (3)
(3)
3. MCSSE Techniques
3.1. Beamforming Technique
Beamforming is a class of algorithms for multichannel signal processing. The term Beamforming refers to the design of a spatio-temporal filter which operates on the outputs of the microphone array [8]. This spatial filter can be expressed in terms of dependence upon angle and frequency. Beamforming is accomplished by filtering the microphone signals and combining the outputs to extract (by constructive combining) the desired signal and reject (by destructive combining) interfering signals according to their spatial location [9].
Beamforming for broadband signals like speech can, in general, be performed in the time domain or frequency domain. In time domain Beamforming, a Finite Impulse Response (FIR) filter is applied to each microphone signal, and the filter outputs combined to form the Beamformer output. Beamforming can be performed by computing multichannel filters whose output is  an estimate of the desired source signal as shown in Figure 2.
an estimate of the desired source signal as shown in Figure 2.
The output can be expressed as:
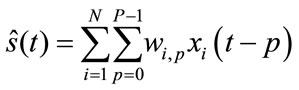 (4)
(4)
where P – 1 is the number of delays in each of the N filters.

Figure 2. MCSSE with Beamforming technique.
In frequency domain Beamforming, the microphone signal is separated into narrowband frequency bins using a Short-Time Fourier Transform (STFT), and the data in each frequency bin is processed separately.
Beamforming techniques can be broadly classified as being either data-independent or data-dependent. Data independent or deterministic Beamformers are so named because their filters do not depend on the microphone signals and are chosen to approximate a desired response. Conversely, data-dependent or statistically optimum Beamforming techniques are been so called because their filters are based on the statistics of the arriving data to optimize some function that makes the Beamformer optimum in some sense.
3.1.1. Deterministic Beamformer
The filters in a deterministic Beamformer do not depend on the microphone signals and are chosen to approximate a desired response. For example, we may wish to receive any signal arriving from a certain direction, in which case the desired response is unity over at that direction. As another example, we may know that there is interference operating at a certain frequency and arriving from a certain direction, in which case the desired response at that frequency and direction is zero. The simplest deterministic Beamforming technique is delay-and-sum Beamforming, where the signals at the microphones are delayed and then summed in order to combine the signal arriving from the direction of the desired source coherently, expecting that the interference components arriving from off the desired direction cancel to a certain extent by destructive combining. The delay-and-sum Beamformer as shown in Figure 3 is simple in its implementation and provides easy steering of the beam towards the desired source. Assuming that the broadband signal can be decomposed into narrowband frequency bins, the delays can be approximated by phase shifts in each frequency band.
The performance of the delay-and-sum Beamformer in reverberant environments is often insufficient. A more general processing model is the filter-and-sum Beamformer as shown in Figure 4 where, before summation, each microphone signal is filtered with FIR filters of order M. This structure, designed for multipath environments namely reverberant enclosures, replaces the simpler delay compensator with a matched filter. It is one of the simplest Beamforming techniquesbut still gives a very good performance.
As it has been shown that the deterministic Beamformer is far from being fully manipulated independently from the microphone signals, the statistically optimal Beamformer is tightly linked and tied to the statistical properties of the received signals.
3.1.2. Statistically Optimum Beamformer
Statistically optimal Beamformers are designed basing on the statistical properties of the desired and interference signals. In this category, the filters designs are based on the statistics of the arriving data to optimize some function that makes the Beamformer optimum in some sense. Several criteria can be applied in the design of the Beamformer, e.g., maximum signal-to-noise ratio (MSNR), minimum mean-squared error (MMSE), minimum variance distortionless response (MVDR) and linear constraint minimum variance (LCMV). A summary of several design criteria can be found in [10]. In general, they aim at enhancing the desired signals, while rejecting the interfering signals.
Figure 5 depicts the block diagram of Frost Beamformer or an adaptive filter-and-sum Beamformer as proposed in [16], where the filter coefficients are adapted using a constrained version of the Least Mean-Square (LMS) algorithm. The LMS is used to minimize the noise power at the output while maintaining a constraint