Continuous-Time Mean-Variance Portfolio Selection with Partial Information ()
1. Introduction
Mean-variance is an important investment decision rule in financial portfolio selection, which is first proposed and solved in the single-period setting by Markowitz in his Nobel-Prize-winning works [1] [2] . In these seminal papers, the variance of the final wealth is used as a measure of the risk associated with the portfolio and the agent seeks to minimize the risk of his investment subject to a given mean return. This model becomes the foundation of modern finance theory and inspires hundreds of extension and applications. For example, this leads to the elegant capital asset pricing model [3] .
The dynamic extension of the Markowitz model has been established in subsequent years by employing the martingale theory, convex duality and stochastic control. The pioneer work for continuous time portfolio management is [4] , in which Merton used dynamic programming and partial differential equation (PDE) theory to derive and solve the Hamilton-Jacobi-Bellman (HJB) equation, and thus obtains the optimal strategy. For cases when the underlying stochastic process is a Martingale, optimal portfolios could be derived [5] . In [6] , the authors formulated the mean-variance problem with deterministic coefficients as a linear-quadratic (LQ) optimal problem. As there is no running cost in the objective function, this formulation is inherently an indefinite stochastic LQ control problem. As extensions of [6] , for example, [7] dealt with random coefficients, while [8] considered regime switching market. For discrete time cases, [9] solved the multiperiod mean-variance portfolio selection problem completely. Analytical optimal strategy and an efficient algorithm to find the strategy were proposed. Comprehensive review of the mean-variance model can be found in [10] and [11] .
In [12] , in order to tackle the computational tractability and the statistical difficulties associated with the estimation of model parameters, Bielecki and Pliska introduced a model such that the underlying economic factors such as accounting ratios, dividend yields, and macroeconomic measures are explicitly incorporated in the model. The factors are assumed to follow Gaussian processes and the drifts of the stocks are linear functions of these factors. This model motivates many further researches (see, for example, [13] and [14] ). In practice, many investors use only the observed asset prices to decide his current portfolio strategy. The random factors cannot normally be observable directly. Therefore, the underlying problem falls into the category of portfolio selection under partial information [15] [16] . A significant progress in the realm of mean-variance concerning partial information is the work of [17] , in which a separation principle is shown under this partial information setting. Efficient strategies were derived, which involved the optimal filter of the stock drift processes. In addition, the particle system representation of the obtained filter is employed to develop analytical and numerical approaches. It is valuable to point out that backward stochastic differential equations (BSDEs) methodology is employed to tackle this problem.
This paper attempts to deal with the mean-variance portfolio selection under partial information based on the model of [12] . By exploiting the properties of the filtering process and the wealth process, we tackle this problem directly by the dynamic programming approach. We show that optimal strategy can be constructed by solving a deterministic forward Riccati-type ordinary differential equation (ODE) and a system of linear deterministic backward ODEs. Clearly, by reversing the time, a deterministic backward ODE can be converted to a forward one. Therefore, we can easily derive the analytic solutions of the ODEs, and thus the analytic form of the optimal strategies. This is the main contribution of the paper. The proposed procedure is different from that of [17] , where BSDEs are employed.
The rest of the paper is organized as follows. In Section 2, we formulate the mean-variance portfolio selection model under partial information, and an auxiliary problem is introduced. Section 3 gives the optimal strategy of the auxiliary problem by the dynamic programming method. Section 4 studies the original problem, while Section 5 gives some concluding remarks.
2. Mean-Variance Model
Throughout this paper 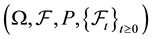 is a fixed filtered complete probability space on which a standard
is a fixed filtered complete probability space on which a standard 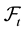 - adapted
- adapted 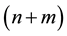 -dimensional Brownian motion
-dimensional Brownian motion 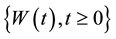 is defined, where
is defined, where 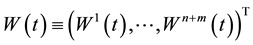 and
and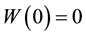 . Let
. Let 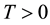 be the terminal time of an investment, and
be the terminal time of an investment, and 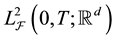 denotes the set of all
denotes the set of all 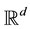 -valued,
-valued, 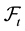 -adapted stochastic processes
-adapted stochastic processes 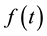 with
with 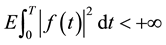 ; similarly
; similarly 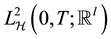 can be defined for any functions with domain in
can be defined for any functions with domain in 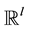 and filtration
and filtration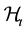 .
.
There is a capital market containing  basic securities (or assets) and
basic securities (or assets) and ![]() economic factors. The securities consist of a bond and
economic factors. The securities consist of a bond and ![]() stocks. The set of factors may include short-term interests, the rate of inflation, and other economic factors [14] . One of the securities is a risk-free bank account whose value process
stocks. The set of factors may include short-term interests, the rate of inflation, and other economic factors [14] . One of the securities is a risk-free bank account whose value process ![]() is subject to the following ordinary differential equation
is subject to the following ordinary differential equation
![]() (2.1)
(2.1)
where ![]() is the interest rate, a deterministic function of
is the interest rate, a deterministic function of![]() . The other
. The other ![]() assets are risky stocks whose price processes
assets are risky stocks whose price processes ![]() satisfy the following stochastic differential equations (SDEs)
satisfy the following stochastic differential equations (SDEs)
![]() (2.2)
(2.2)
where![]() ,
, ![]() are the drifts, and
are the drifts, and![]() ,
, ![]() are the deterministic volatility or dispersion rate of the stocks. In this paper, we assume that the drifts are affine functions of the mentioned economic factors,
are the deterministic volatility or dispersion rate of the stocks. In this paper, we assume that the drifts are affine functions of the mentioned economic factors,
and the factors are Gaussian processes. To be precise, denoting ![]() by
by![]() , we have
, we have
![]()
where the constant matrices ![]() are of
are of![]() ,
, ![]() ,
, ![]() , respectively.
, respectively.
Consider an agent with an initial endowment ![]() and an investment horizon
and an investment horizon![]() , whose total wealth at time
, whose total wealth at time ![]() is denoted by
is denoted by![]() . Assuming that the trading of shares is self-financed and taken place continuously, and that transaction cost and consumptions are not considered, then
. Assuming that the trading of shares is self-financed and taken place continuously, and that transaction cost and consumptions are not considered, then ![]() satisfies (see, e.g., [18] )
satisfies (see, e.g., [18] )
![]() (2.3)
(2.3)
where![]() ,
, ![]() denote the total market value of the agent’s wealth in the
denote the total market value of the agent’s wealth in the ![]() -th stock. We call the process
-th stock. We call the process![]() ,
, ![]() , a portfolio of the agent.
, a portfolio of the agent.
Let
![]()
As pointed out by [17] , practically, the investor can only observe the prices of assets. So, at time![]() , the information that available to the investor is the past and present assets’ prices, equivalently, the filtration
, the information that available to the investor is the past and present assets’ prices, equivalently, the filtration![]() . Thus, the investor’s strategy should be based on his/her available information. Therefore,
. Thus, the investor’s strategy should be based on his/her available information. Therefore, ![]() should be
should be ![]() - measurable. To be exact, we define the following admissible portfolio.
- measurable. To be exact, we define the following admissible portfolio.
Definition 2.1. A portfolio ![]() is said to be admissible if
is said to be admissible if ![]() and the SDE (2.3) has a unique solution
and the SDE (2.3) has a unique solution ![]() corresponding to
corresponding to![]() . The totality of all admissible portfolios is denoted by
. The totality of all admissible portfolios is denoted by![]() .
.
The agent’s objective is to find an admissible portfolio![]() , among all such admissible portfolios that his/her expected terminal wealth
, among all such admissible portfolios that his/her expected terminal wealth![]() , where
, where ![]() is given a priori, so that the risk measured by the variance of the terminal wealth
is given a priori, so that the risk measured by the variance of the terminal wealth
![]() (2.4)
(2.4)
is minimized. The problem of finding such a portfolio ![]() is referred to as the mean-variance portfolio selection problem. Mathematically, we have the following formulation.
is referred to as the mean-variance portfolio selection problem. Mathematically, we have the following formulation.
Definition 2.2. The mean-variance portfolio selection problem, with respect to the initial wealth![]() , is for-
, is for-
mulated as a constrained stochastic optimization problem parameterized by![]() :
:
![]() (2.5)
(2.5)
The problem is called feasible (with respect to![]() ) if there is at least one admissible portfolio satisfying
) if there is at least one admissible portfolio satisfying![]() . An optimal portfolio, if it exists, is called an efficient portfolio strategy with respect to
. An optimal portfolio, if it exists, is called an efficient portfolio strategy with respect to![]() , and
, and
![]() is called an efficient point. The set of all efficient points is obtained when the parameter
is called an efficient point. The set of all efficient points is obtained when the parameter ![]() varies between
varies between![]() .
.
We impose the basic assumption:
Assumption (PD). For any![]() ,
, ![]() , which is popular in the literatures about portfolio selection (see, for example, [12] - [14] [17] [19] ).
, which is popular in the literatures about portfolio selection (see, for example, [12] - [14] [17] [19] ).
Let
![]()
with ![]() being a
being a ![]() -dimensional row vector with all its entries being 1. Then, (2.3) can be rewritten as
-dimensional row vector with all its entries being 1. Then, (2.3) can be rewritten as
![]() (2.6)
(2.6)
By the definition of![]() , our problem falls into the category of stochastic control based on partial information. Here, the partial information means that we cannot know the process
, our problem falls into the category of stochastic control based on partial information. Here, the partial information means that we cannot know the process![]() , and thus
, and thus![]() . In order to design admissible strategy, we firstly need to derive the optimal estimation of
. In order to design admissible strategy, we firstly need to derive the optimal estimation of![]() . Let
. Let
![]()
By Itô’s formula we have
![]()
Define
![]() (2.7)
(2.7)
then ![]() is a Brownian motion under the original probability measure (Liptser and Shiryaev (2001)). The estimation of
is a Brownian motion under the original probability measure (Liptser and Shiryaev (2001)). The estimation of ![]() is given by (Theorem 10.3 of [20] )
is given by (Theorem 10.3 of [20] )
![]() (2.8)
(2.8)
By (2.7), a simple calculation shows that
![]() (2.9)
(2.9)
Substituting (2.9), we have an equivalent representation of the wealth process
![]() (2.10)
(2.10)
where
![]() (2.11)
(2.11)
This is the separation principle developed by [17] , which enables us to solve problem (2.5) as if the drifts ![]() were known, and then replace
were known, and then replace ![]() by its optimal estimation. So, (2.5) can be equivalently for- mulated as
by its optimal estimation. So, (2.5) can be equivalently for- mulated as
![]() (2.12)
(2.12)
By general convex optimization theory, the constrained optimal problem (12) with ![]() can be converted into an unconstrained one by introducing a Lagrange multiplier
can be converted into an unconstrained one by introducing a Lagrange multiplier![]() . To be concrete, for any fixed
. To be concrete, for any fixed![]() , we consider the following problem
, we consider the following problem
![]() (2.13)
(2.13)
which is equivalent to the following (denoting ![]() by
by ![]() for any fixed
for any fixed![]() )
)
![]() (2.14)
(2.14)
in the sense that two problems have exactly the same optimal strategy. In the following, we will call problem (2.14) the auxiliary problem of the original problem (2.12).
3. Optimal Policy for the Auxiliary Problem
The problem (2.14) can be viewed as an unconstrained special stochastic optimal control problem with random coefficients in system equation and zero integral term in the performance index. Different from existing results using BSDEs methodology, in this section, we derive the optimal portfolio strategy from dynamic programming directly. This enables us to derive the optimal policy by solving just two linear deterministic backward ODEs and a Riccati-type forward deterministic ODE.
3.1. Analysis of Hamilton-Jacobi-Bellman Equation
Let ![]() denote the performance of problem (2.14) at time
denote the performance of problem (2.14) at time![]() , with boundary condition
, with boundary condition ![]() . Then, it is evident that the following HJB equation is satisfied
. Then, it is evident that the following HJB equation is satisfied
![]() (3.1)
(3.1)
where ![]() is the infinitesimal generator operator of the closed system (2.8) (2.10) (2.11), and the independence of
is the infinitesimal generator operator of the closed system (2.8) (2.10) (2.11), and the independence of ![]() on policy
on policy ![]() is suppressed.
is suppressed.
To evaluate![]() , first of all, by (2.8) (2.10) we have
, first of all, by (2.8) (2.10) we have
![]()
By Itô’s formula, it follows that
![]()
where ![]() is the partial derivative of
is the partial derivative of ![]() with respect to
with respect to![]() ,
, ![]() is the second order partial derivative of
is the second order partial derivative of ![]() with respect to
with respect to![]() , and
, and ![]() are defined similarly. On the assumption that
are defined similarly. On the assumption that![]() , we get the following optimal strategy
, we get the following optimal strategy
![]() (3.2)
(3.2)
which makes ![]() minimal. Substituting (3.2) into (3.15) leads to
minimal. Substituting (3.2) into (3.15) leads to
![]() (3.3)
(3.3)
In this and the following PDEs and ODEs, the arguments ![]() are always suppressed to simplify the notations.
are always suppressed to simplify the notations.
Noticing that the terminal condition of ![]() is a nonhomogeneous function of
is a nonhomogeneous function of![]() , in order to make (3.3) homogeneous, we set
, in order to make (3.3) homogeneous, we set
![]() (3.4)
(3.4)
Simple calculation shows
![]()
Substituting ![]() and the above equalities into (3.3), we obtain that
and the above equalities into (3.3), we obtain that
![]() (3.5)
(3.5)
By the special structure of (3.5), the following separation form of ![]() is taken
is taken
![]() (3.6)
(3.6)
which will be proved in Theorem 3.1. Therefore, the optimal control (3.2) has the following structure
![]()
which is linear in![]() , and (3.5) is equivalent to
, and (3.5) is equivalent to
![]() (3.7)
(3.7)
Clearly, if ![]() solves the following PDE
solves the following PDE
![]() (3.8)
(3.8)
then ![]() has the explicit form of (3.6).
has the explicit form of (3.6).
3.2. Optimal Policy
Notice that the left hand side of the first equation in (3.8) is linear in![]() ,
, ![]() ,
, ![]() ,
, ![]() , and quadratic in
, and quadratic in![]() . Therefore, we assume that
. Therefore, we assume that ![]() has the following expression
has the following expression
![]() (3.9)
(3.9)
with![]() ,
, ![]() ,
, ![]() to be specified later. Here,
to be specified later. Here, ![]() denotes the set of all symmetric
denotes the set of all symmetric ![]() real matrices. The form (3.9) of
real matrices. The form (3.9) of ![]() enables us to get an equivalent equation that is independent of
enables us to get an equivalent equation that is independent of ![]() and is only a quadratic function of
and is only a quadratic function of![]() . Fixing the coefficients of the obtained equation to be zero, we can determine
. Fixing the coefficients of the obtained equation to be zero, we can determine![]() ,
, ![]() ,
, ![]() by solving several equations. Thus, we may prove that
by solving several equations. Thus, we may prove that ![]() given in (3.6) satisfied the HJB Equation (3.1), indeed. Therefore, we have the following theorem.
given in (3.6) satisfied the HJB Equation (3.1), indeed. Therefore, we have the following theorem.
Theorem 3.1. For problem (2.14), the optimal strategy is given by
![]() (3.10)
(3.10)
where![]() ,
, ![]() ,
, ![]() are the unique solutions to the second equation of (2.8) and following ODEs, res- pectively,
are the unique solutions to the second equation of (2.8) and following ODEs, res- pectively,
![]() (3.11)
(3.11)
![]() (3.12)
(3.12)
Proof. Bearing the form (3.9) of ![]() in mind, simple calculation shows that
in mind, simple calculation shows that
![]()
Therefore, (3.8) is equivalent to
![]() (3.13)
(3.13)
which is equivalent to
![]()
(3.14)
The left hand of above PDE can be decomposed into three terms:
1) the term that is irrespective of ![]()
![]()
2) the term that is linear in ![]()
![]()
3) the term that is quadratic in ![]()
![]()
So, if the ![]() satisfy the following three equations, respectively,
satisfy the following three equations, respectively,
![]() (3.15)
(3.15)
![]() (3.16)
(3.16)
![]() (3.17)
(3.17)
we can determine the function![]() . Firstly, we need to claim that the second equation of (2.8), (3.15), (3.16) and (33.17) have unique solution. In fact, it is known that the second equation of (2.8) has a unique nonnegative definite solution; see, for example, Theorem 10.3 of [20] . While for (3.17), (3.16) and (3.15), they are linear in
. Firstly, we need to claim that the second equation of (2.8), (3.15), (3.16) and (33.17) have unique solution. In fact, it is known that the second equation of (2.8) has a unique nonnegative definite solution; see, for example, Theorem 10.3 of [20] . While for (3.17), (3.16) and (3.15), they are linear in![]() , respectively; thus, the solutions exist uniquely. This means that
, respectively; thus, the solutions exist uniquely. This means that ![]() given in (3.9) exactly solves (3.8). Furthermore, by the analysis in the above subsection, we can conclude that
given in (3.9) exactly solves (3.8). Furthermore, by the analysis in the above subsection, we can conclude that ![]() defined in (3.6) solves (3.3). Notice that
defined in (3.6) solves (3.3). Notice that
![]()
Thus, ![]() defined in (3.6) satisfies HJB Equation (3.1). Clearly, (3.2) is equal to (3.10). In the end, we need only to confirm that (3.10) is admissible. By classic filtering theory,
defined in (3.6) satisfies HJB Equation (3.1). Clearly, (3.2) is equal to (3.10). In the end, we need only to confirm that (3.10) is admissible. By classic filtering theory, ![]() is equal to the
is equal to the ![]() -algebra generated
-algebra generated
by innovation process ![]() (see for example [21] ). Clearly, we have (3.10) is
(see for example [21] ). Clearly, we have (3.10) is ![]() -adapted, and thus it is admissible. Therefore, (3.10) is the optimal strategy, which make the
-adapted, and thus it is admissible. Therefore, (3.10) is the optimal strategy, which make the ![]() minimal. This
minimal. This
completes the proof. ![]()
We will give a brief discussion about the solvability in theory of (2.8) (3.11) (3.12). Clearly, ![]() satisfies
satisfies
![]()
with![]() . Let
. Let![]() ,
, ![]() , then it follows
, then it follows
![]()
with![]() . By known result (see for example Anderson and Moore (1971)),
. By known result (see for example Anderson and Moore (1971)), ![]() can be represented as
can be represented as
![]()
where![]() ,
, ![]() are defined as
are defined as
![]()
Therefore,
![]()
Clearly, (3.12) is a Lyapunov differential equation, which is solved by introducing the following operator
![]()
where ![]() is the transpose of
is the transpose of ![]() -th column of of
-th column of of![]() . Clearly,
. Clearly,
![]()
where
![]()
Let![]() . Then
. Then
![]() (3.18)
(3.18)
Therefore,
![]()
where ![]() is the fundamental matrix of (3.18). Thus
is the fundamental matrix of (3.18). Thus![]() . At last, (3.11) and (3.15) can be easily solved by the linearity of the equations.
. At last, (3.11) and (3.15) can be easily solved by the linearity of the equations.
4. Efficient Frontier
In this section, we proceed to derive the efficient frontier for the original portfolio selection problem under partial information. To begin with, we prove a lemma which shows the feasibility of the original problem.
Lemma 4.1. Problem (5) is feasible, and the minimal mean-variance of the terminal wealth process is finite.
Proof. The proof follows directly from results of Section 5 in [17] . In the language of [17] , (2.10) can be rewritten as
![]() (4.1)
(4.1)
where ![]() is defined by Theorem 5.4 in [17] satisfying
is defined by Theorem 5.4 in [17] satisfying![]() , and
, and
![]()
Clearly, ![]() is equivalent to the
is equivalent to the ![]() -algebra generated by innovation process
-algebra generated by innovation process![]() . By general BSDEs theory, (4.1) has a unique
. By general BSDEs theory, (4.1) has a unique ![]() -adapted, square integrate solution
-adapted, square integrate solution![]() . Therefore, problem (2.5) is feasible because
. Therefore, problem (2.5) is feasible because ![]() is a feasible strategy. On the other hand, by Theorem 5.6 of [17] , we know that the minimal mean-variance at the terminal time point is finite.
is a feasible strategy. On the other hand, by Theorem 5.6 of [17] , we know that the minimal mean-variance at the terminal time point is finite. ![]()
Now, we state our main theorem.
Theorem 4.1. The efficient strategy of Problem (2.5) with the terminal expected wealth constraint ![]() is given by
is given by
![]() (4.2)
(4.2)
Here, ![]() ,
, ![]() ,
, ![]() solve Equations (2.8) (3.11) (3.12), respectively, and
solve Equations (2.8) (3.11) (3.12), respectively, and ![]() is given by
is given by
![]()
where ![]() is given by
is given by
![]() (4.3)
(4.3)
and![]() ,
,![]() . Moreover, the efficient frontier is given by
. Moreover, the efficient frontier is given by
![]() (4.4)
(4.4)
Proof. By Lemma 4.1, we know that the constraint Problem (2.5) is feasible, and its minimal terminal mean- variance ![]() is finite. This means that
is finite. This means that
![]() (4.5)
(4.5)
where the equality is true by general convex constraint optimization theory (see, for example, [22] ). By Theorem 3.1, the wealth Equation (2.10) evolves as
![]()
In terms of![]() , this equation is
, this equation is
![]()
Clearly,
![]()
Thus
![]()
where ![]() is defined in (4.3). Notice that
is defined in (4.3). Notice that
![]()
For any fixed![]() ,
,
![]() (4.6)
(4.6)
To obtain the optimal mean-variance value and the optimal portfolio strategy of Problem (2.5), we should maximize (4.6) over ![]() within
within![]() , and the finiteness is ensured by (4.5). We easily show that (4.6) attains its maximum value
, and the finiteness is ensured by (4.5). We easily show that (4.6) attains its maximum value ![]() at
at
![]() (4.7)
(4.7)
And we can assert that
![]()
If this is not true, the optimal cost will be infinite, which contradicts (4.5). ![]()
5. Conclusion
In this paper, we have studied the continuous-time mean-variance portfolio selection problem with stochastic drifts. In particular, drifts are assumed to be linear functions of economic factor processes. Because the factor processes cannot be observed directly, partial information is assumed together with a filter process. Conse- quently, by dynamic programming technique and the method of separation of variables, we have derived the explicit optimal strategy via the solution of a system of ODEs. As a future extension, it would be of interest to study the solutions with real financial data and carry out appropriate economic analysis. Also, regime-switching model [23] and the scenario for no-bankruptcy can also be considered.
Acknowledgements
This work is supported by the PolyU grant G-YL05 and A-PL62, and the JRI of the Department of Applied Mathematics, The Hong Kong Polytechnic University.