Quantitative Structural Models to Assess Credit Risk on Individuals ()
1. Introduction
In the last 40 years, mathematics has become an integral part of the finance industry. Futures and options are traded actively on the many exchanges throughout the world. Recently, derivatives are added to bonds issues, used in executive compensation plans, embedded in capital investment opportunities, and so on. We have now reached a stage where anyone who works in finance needs to understand how financial mathematics works. In the last decade, there has also been a spot light on financial mathematics due to the 2007 economic meltdown, which has resulted in more stringent regulatory requirements. Since the global financial crisis regulators began to demand more transparency. Poor portfolio risk management, or a lack of attention to changes in economic or other circumstances that can lead to a deterioration in the credit standing of a bank’s counterparties. This also presents an opportunity to greatly improve overall performance and secure a competitive advantage in credit risk management.
In this paper, we will estimate a probability of default. Probability of default is the risk that the borrower will be unable or unwilling to repay its debt in full or on time. When an individual goes bankrupt, those that are owed by such individual file claims against the assets of such individual. There are times when there is a reorganization in which creditors agree to a partial payment of their claims. We will start by using the formulas originally published by Merton [1] in his original work on credit risk for companies and the original Black and Scholes [2] model for calculating an individual wealth scenario using the idea of companies equity prices to estimate default probability. In order to do this, we must consider the nature of an individual’s wealth and its distribution among risk free assets, risky assets, wages, and consumption subject to drift. Our discussion will also look at the default probabilities implied from bond prices and historical data that is, risk-neutral default probability and real world probability of default. This is paramount because it becomes legitimate to ask a natural question like in what scenarios do we use the risk neutral probability or real world default probability.
In Section 2, we did a literature review of scholarly sources most relevant to our model, followed by Section 3, where we looked at the GMB structure of individual wealth factoring in consumption and utility from the deterministic and stochastic approach. Also, in the concluding part of Section 3, we will compute individual default intensity, recovery rate and risk premium. The risk premium model is applied to the simplest form of corporate debt. The discounted bond where no coupons are made and a formula for putting the risk structure of interest rate is presented and in the later part of the paper, an individual formula for risk premium is also proposed.
Finally, in Section 4, we suggested further research in relation to this research.
2. Literature Review
This paper looks at “Valuation of a CDO and an n-th to Default CDS Without Monte Carlo Simulation” by John Hull and Alan White [3]. In this paper the authors develop two fast procedures for valuing tranches of collateralized debt obligations and n-th to default swaps. The procedures are used were based on a factor copula model of times to default and are alternatives to using fast Fourier transforms. One involves calculating the probability distribution of the number of defaults by a certain time using a recurrence relationship; the other involves using a “probability bucketing” numerical procedure to build up the loss distribution. We show how many different copula models can be generated by using different distributional assumptions within the factor model. We examine the impact on valuations of default probabilities, default correlations, the copula model chosen, and a correlation of recovery rates with default probabilities. Finally the paper looked at the market pricing of index tranches and conclude that a “double distribution” copula fits the prices reasonably well.
The paper “Option pricing when underlying stock returns are discontinuous” by Robert C. Merton [4]. This study analyzes the validity of the classic Black-Scholes [2] option pricing formula depends on the capability of investors to follow a dynamic portfolio strategy in the stock that replicates the payoff structure to the option. The critical assumption required for such a strategy to be feasible, is that the underlying stock return dynamics can be described by a stochastic process with a continuous sample path. In this paper, an option pricing formula is derived for the more-general case when the underlying stock returns are generated by a mixture of both continuous and jump processes. The derived formula has most of the attractive features of the original Black-Scholes [2] formula in that it does not depend on investor preferences or knowledge of the expected return on the underlying stock. Moreover, the same analysis applied to the options can be extended to the pricing of corporate liabilities.
In the paper “Optimum Consumption and Portfolio Rules in a continuous-Time Model,” by R. C. Merton [5] (J. Econ. Theory 3 (1971), 373-413). This is a good source for general information on solutions obtained in cases when marginal utility at zero consumption is finite are not feasible. While they do satisfy the Hamilton-Jacobi Bellman equations, they do not represent appropriate value functions because the boundary behavior near zero wealth is not satisfactorily dealt with. In this ,they specify the boundary behavior and characterize optimal solutions.
According to Merton, R.C. [1] On the Pricing of Corporate Debt: The Risk Structure Interest Rate. Journal of Finance, 449-470, the paper developed a method for pricing corporate liabilities which is grounded in solid economic analysis, requires inputs which are on the whole observable; can be used to price almost any type of financial instrument. The method was applied to risky discount bonds to deduce a risk structure of interest rates. The Modigliani-Miller theorem was shown to obtain in the presence of bankruptcy provided that there are no differential tax benefits to corporations or transactions costs. The analysis was extended to include callable, coupon bonds.
Black, F. and Scholes, M. [2], “The Pricing of options and Corporate Liabilities,” Journal of Political Economy (May-June 1973). Using the principle from this paper, a theoretical valuation formula for options is derived knowing that if options are correctly priced in the market, it should not be possible to make sure profits by creating portfolios of long and short positions in options and their underlying stocks. Since almost all corporate liabilities can be viewed as combinations of options, the formula and the analysis that led to it are also applicable to corporate liabilities such as common stock, corporate bonds, and warrants. In particular, the formula can be used to derive the discount that should be applied to a corporate bond because of the possibility of default.
As explained by Hull, J.C., and White, A. [6], in their paper “The Risk of Tranches Created from Mortgages,” Rotman School of Management, University of Toronto, 2010. Using the criteria of the rating agencies, the authors tested how wide the AAA tranches created from residential mortgages can be. They found that the AAA ratings assigned to ABSs were not totally unreasonable but that the AAA ratings assigned to tranches of Mezz ABS CDOs cannot be justified.
At a glance of Li, David X. [7], paper “On Default Correlation: A Copula Approach,” Journal of Fixed Income (2000). The paper studies the problem of default correlation. It introduces a random variable called “time-until-default” to denote the survival time of each defaultable entity or financial instrument, and define the default correlation between two credit risks as the correlation coefficient between their survival times. Then an arguement was made on why a copula function approach should be used to specify the joint distribution of survival times after marginal distributions of survival times are derived from market information, such as risky bond prices or asset swap spreads. The definition and some basic properties of copula functions are given. The paper went on to show that the current CreditMetrics approach to default correlation through asset correlation is equivalent to using a normal copula function. Finally, the author gives some numerical examples to illustrate the use of copula functions in the valuation of some credit derivatives, such as credit default swaps and first-to-default contracts.
Das, Sanjiv R., Laurence Freed, Gary Geng and Nikunj Kapadia [8], “Correlated DefaultRisk” Journal of Fixed Income (2006), 16, 2, 7-30. The authors looked at Moodys Corporate default and recovery rates and provide a comprehensive empirical investigation of how default probabilities covary using a database of issuer-level default probabilities for the period 1987-2000. This database provides a unique opportunity to understand how default risk behaves both in the cross-section of firms and in the time-series for almost all US public non-financial firms. More importantly from the standpoint of using the results, the data set lends quantitative expression to this behavior. For instance, the authors’ analysis allows for the understanding of the extent to which the record defaults of 2001. This paper also looked relating the co-variation in default probabilities to variation in debt, volatility, and their correlations, it also provide an economic understanding of why the economy-wide default rate varies over time. In short, they also examine the contribution of the correlation between default probabilities, i.e., the first part of the standard reduced-form structure of doubly stochastic processes, to joint default risk.
The presentation, Hong Chen Ting [9], (November, 2009). Credit Risk. Retrieved from http://slideplayer.com/slide/3396349/ did a detail analysis of Credit risk presenting the original results using excel solver.
G. M. Gupton, C. C. Finger, M. Bhatia [10], Risk Metric Group Inc. “Credit Grades Technical Document,” May, 2002. The authors acknowledges that most prior work has been on the estimation of the relative likelihoods of default for individual firms; Moody’s and S&P have long done this and many others have started to do so. They designed CreditMetrics to accept as an input any assessment of default probability which results in firms being classified into discrete groups (such as rating categories), each with a defined default probability. It is important to realize, however, that these assessments are only inputs to CreditMetrics, and not the final output. They also estimated the volatility of value due to changes in credit quality, not just the expected loss. In their own view, as important as default likelihood estimation is, it is only one link in the long chain of modeling and estimation that is necessary to fully assess credit risk (volatility) within a portfolio. Just as a chain is only as strong as its weakest link, it is also important to diligently address: 1) uncertainty of exposure such as is found in swaps and forwards, 2) residual value estimates and their uncertainties, and 3) credit quality correlations across the portfolio.
In the paper by Magill M.J., and Constantinides G.M. [11], “Portfolio selection with transaction cost”: Journal of Economics Theory (October 1976). One result in this paper is that it shows the direction trading costs can be shown to be an important factor explaining the existence of financial intermediaries such as mutual funds. The paper may also prove useful in determining the impact of trading costs on capital market equilibrium. Furthermore, the paper shows fundamental qualitative changes that arise in the portfolio behavior of an investor when trading opportunities on the capital market are no longer available costless. The most basic change is that the investor substantially modifies his concept of an optimal portfolio which now consists of a whole region in the portfolio space. A direct consequence of this is that the investor only seeks to make use of trading opportunities at randomly spaced instants of time. Both of these properties are likely to hold more generally for the class of concave utility and transaction cost functions. The wider economic significance of trading costs must now be sought in their impact on the capital market as a whole.
Davis and Norman [12] “Portfolio selection with transaction cost”: Mathematics of Operations research (Vol. 15, No. 4, November 1990) obtained closed-form solutions for a problem that maximizes the cumulative utility of consumption on an infinite horizon under proportional transaction costs.
Shreve, S.E. and Soner, H. M. [13], “Optimal Investment and Consumption with Transac-tion Costs” the authors provided a complete solution is provided to the infinite-horizon, discounted problem of optimal consumption and investment in a market with one stock, one money market (sometimes called a “bond”) and proportional transaction costs. The authors looked at the utility function, assumed that the interest rate for the money market is positive, the mean rate of return for the stock is larger than this interest rate, the stock volatility is positive and all these parameters are constant. The only other assumption is that the value function is finite. They implied that the liquidity premium associated with small transaction costs is also of the order of the transaction cost to the 2/3 power. The analysis of the paper and its Appendix relied on the concept of viscosity solutions to Hamilton-Jacobi-Bellman equations.
In the paper “Bond Prices, Default Probabilities and Risk Premium”: Journal of Credit Risk; (Issue: Vol. 1, No. 2; 2005), the authors Hull, J.C. and Mirela, P. and White, A. [14], looked at the difference between probabilities of default calculated from historical data and probabilities of default implied from bond prices (or from credit default swaps). The authors showed that the average probability of default backed out from the bond’s price is almost ten times as great as that calculated from historical data.
Moody’s Investors Services [15], “Corporate Default and Recovery Rates, 1920-2007”. Moody’s credit ratings have contributed to the efficient functioning of capital markets by providing independent opinions on the creditworthiness of many types of debt obligations and issuers. One primary purposes of Moody’s default study is to serve as a report on the historical performance of Moody’s ratings as predictors of default and loss severity. To providing useful data for investors and regulators, Moody’s default studies contribute to the transparency of the rating process and more importantly, directly address the meaning of Moody’s longterm debt ratings scale. The authors briefly summarize corporate default activity in 2006 and discuss Moody’s forecast for speculative-grade corporate defaults in 2007. The majority of the report is comprised of historical statistics on corporate defaults, ratings transitions, ratings performance metrics, and recovery rates. The study contains a number of revisions to the historical data relative to previous year’s reports, which are described in detail in a separate section at the end of the study. Most of the data revisions arise due to the inclusion of the year’s Moody’s rated corporate loan issuers to the universe of study, which previously consisted only of corporate bond issuers. Finally, the report includes several detailed methodologies used to generate the statistics as well as a guide to their reading and interpretation. Finger C.C., [16] “A Comparison of Stochastic Default Rate Models”, RiskMetric group, August, 2000, looked at the methodologies used by RiskMetric in market risk management applications using assumptions of the multivariate normal model and the empirical model for the distribution of risk factor returns. The author also looked at different pricing approaches on a wide set of asset types and finally created effective risk reports based on risk statistics.
3. Estimating Individual Default Probability
We start in this section by trying to look at Merton’s [5] showing that the optimal strategy for investment is to keep a constant fraction of total wealth in each asset and to consume at a rate proportional to wealth. Such a strategy leads to incessant trading, which is impracticable in a real market with transaction costs. There has been more work done on the transaction cost side, Magill and Constantinides [11] introduced proportional transaction costs to Merton’s model. They provided a fundamental insight that there exists a no-trading region and that trading only takes place along the boundary of the no-trading region.
Davis and Norman [12] first formulated the problem as a free boundary problem, where the boundary of the no-trading region is the socalled free boundary. They then studied the properties of the free boundary that reflect the optimal strategy. In terms of a viscosity solution approach, Shreve and Soner [13] entirely characterized the behaviors of the free boundary. But in this paper, our focus will be to do a more rigorous computation to Merton’s [1] work and try to show both the deterministic and stochastic case.
We start with the asset equation as seen in the case of a company, where the asset now represents the individuals wealth in this case from our derivation on the Geometric Brownian motion.
Consumption is the sole end and purpose of all production. As individual invest and save a constant fraction of their income, people also consume a constant fraction of potential output. Every individual choose consumption at each point in time to maximize a lifetime utility function that depends on current and future consumption. Individuals recognize that income in the future may differ from income today, and such differences influence consumption today.
We will start with the GMB derivation
(1)
using variation of parameters, where
= Individuals wealth at time T,
= Individuals wealth at time
, and
= consumption.
We take the derivative of
, we have
we apply Ito’s formula on the exponent to show the derivative of the exponent:
Recall
From Equation (1) above, we substitute for
into our equation we have
Let
, integrating both sides we have
thus
substituting now
into Equation (1) we have
(2)
Substitute
in
, then we have
where
in Equation (2) above is the solution of
, similar to the formula in Oksendal [17].
The real world is made up of minute random events yet a majority of real world systems are explained using deterministic models. Some such models include various population models and the modeling of action potentials in nerves. In mathematics, deterministic models are explained as a set of states which are predetermined depending on the initial conditions. Thus, as long as the initial conditions never change, the outcome will always be the same. In other words, deterministic models introduce no randomness into the system. A deterministic model assumes certainty in all aspects. Examples of deterministic models are timetables, pricing structures, a linear programming model, the economic order quantity model, maps, accounting.
Even though these models give seemingly correct outcomes, they go against the nature of real world systems. This is because the majority of real world systems are only affected by randomness in amounts small enough to not notice. This of course depending on the initial conditions.
In order to get an accurate portrayal of a system, the whole system must be modeled accurately, not just certain cases. This is where stochastic models come in. Stochastic models depend on some predetermined and random variables to transition from one state to another. With those random variables comes a way to represent the randomness involved in real world. Most models really should be stochastic or probabilistic rather than deterministic, but this is often too complicated to implement. Representing uncertainty is fraught. Some more common stochastic models are queueing models, markov chains, and most simulations.
In the deterministic case we don’t have
which is an stochastic white noise term. We will leave out
because it represents stochastic part of the equation and replace 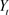 with
with
For debt to be repaid
, because y is an increasing function. The above equation is a solvable deterministic case O.D.E.
To show non stochastic case (i.e. deterministic case) we have a first order O.D.E.
Let
and
.
where
then,
is the integrating factor
which implies
Backward product rule on the left side equation
This is the solution of the deterministic case, considering the initial condition for no default for
so
3.1. Optimal Portfolio Selection and Consumption
Let us now consider a more general case of the individual wealth model. Robert Kohn [18] in his notes followed Robert Merton [5] by presenting the math in Merton’s [5] paper in an interesting finance scenario.
We consider a world with one risky asset and one risk-free asset. The risky asset grows at a constant rate r, that is its price per share satisfies
. The risky asset executes a geometric Brownian motion with constant drift
and volatility
, i.e. its price per share solves the stochastic differential equation
.
The control problem is this: an investor starts with initial wealth x at time t. His control variables are
= fraction of total wealth invested in risky asset at time s
= rate of consumption at time s
It is natural to restrict these controls by
and
. We ignore transaction cost. The state is the investor’s total wealth
as a function of time; it solves
(3)
so long as
. We denote by
the first time
if this occurs before time T, or
(a fixed horizon time) otherwise. The investor seeks to maximize the discounted total utility of his consumption. We therefore consider the value function
From Robert Kohn’s work Equation (3), we see that the real world S.D.E is given by
In the risk neutral world, we assume wealth is only subject to risk free rate i.e. we assume
, in this case we will follow the Hamilton-Jacobi-Bellman (HJB) partial differential equation, we will apply this result of this PDE later in this section, now we have
(4)
now the new volatility is
instead of
.
For us to have the probability of default for an individual, this condition has to be satisfied:
like the case of a company’s probability of default, individual probability of default follows the same model
The new
is now (because our new volatility is
instead of
)
where equity
and
we also have that
then we can find an approximate solution of
, which we will call
for
as
by letting
with this process we can approximate
and we can find the individual equity using Black-Scholes [2] and we estimate debt
since
, we will do that in the later part of this paper.
Back to approximating
,
is a normal distribution with mean 0 and standard deviation s and
where
and x is a standard normal
. Thus
next
then
Now completing the square on the second exponent we have
Imputing the computed exponent back into the equation we have
then combine exponents
We see that the equation in the bracket is the standard normal of mean 0 and standard deviation 1
Next we integrate with respect to ds
Using conclusions from Kohn’s [18] work, he used the choice that gave an autonomous Hamilton-Jacobi-Bellman (HJB) equation, in which time does not appear explicitly in the equation. He found the HJB equation by essentially applying the principle of dynamic programming on short intervals. Kohn’s [18] work also reflects the concavity of the utility function, this is not so obvious but it is easy to check in the explicit solution.
For the ease of understanding following Nagle, Saff, Snider [19], we will try to explain the utility function and risk appetite with an example. Would you rather have $500 with certainity or gamble involving 50% chance of receiving $100 and a 50% chance of recieving $1100? The gambler has a higher expected value of ($500); however, it also has a greater level of risk. Consumers behavior are modelled by economists facing risky decisions with the help of a (von Neumann-Morgenstern) utility function u and the criterion of expected utility. Rather than using expected values of the dollar payoffs, the payoffs are first transformed into utility levels and then weighted by probabilities to obtain expected utility. By Bernoulli, we can set
, we see that
which would result in sure thing being chosen in this case rather than the gamble. This utility function is strictly concave, which corresponds to being risk averse, or wanting to avoid gambles (unless of course the extra risk is sufficiently compensated by a high enough increase in the mean or expected payoff).
Alternatively, the utility function might be
, which is strictly convex and corresponds to the agent being risk loving. This agent would surely select the above gamble. The case of
, occurs when the agent is risk neutral and would select according to the expected value of the payoff. It is normally assumed that
at all payoff levels, x; in other words higher payoffs are desirable.
In addition to knowing if an agent is risk averse or risk loving, economics are often interested in knowing how risk averse (or risk loving) an agent is. Clearly this has something to do with the second derivative of the utility function. The measure of risk aversion of an agent with utility function
and payoff x is defined as
. Normally,
is a function of the payoff level. In our case, we will adopt a risk neutral stance in our utility function.
Back to Kohn’s [18] work on the reflection of concavity of the utility function.
We then see that the optimal
where
is the chosen utility function and, where
, while
We also have that
with the optimal
, here
is consumption. Also notice that the
is embedded in the optimal
. Because of this,
is not a constant and thus
cannot be evaluated easily.
Thus, we will leave the value of
as
So,
can now be approximated as
To find the individuals probability of default, the following condition has to be satisfied
Meaning that wealth has to be less that the debt for default to occur and then, the risk neutral probability of default is given by
. This condition must be satisfied for any default.
Then,
whenever,
Recall now that,
and
, Then,
In general we see that,
Finally, it should be that
where finally
is the probability that there will be a default at any time
. We just proved the following theorem:
Theorem 1: The individual risk neutral probability of default at any time
with volatility
, restricted controls
is given by
where
.
The individual risk neutral probability above will play an important role in determining the lending credit rate of an individual. We will discuss more on the new rate i.e. risk premium for individuals, recovery rate at default and default intensities for individuals in the later part of this section.
Before then, we refer back to Equation (3) (The state of investor’s total wealth equation) to look at the real (actual) world S.D.E and compare the result to the risk neutral world where we assume that
.
This time we will leave the S.D.E as
(5)
For sake of notation
we will denote wealth
, the volatility remains
and we see by computation that we can replace r with
Similar to Equation (4), from Equation (5) above we now have
(6)
To start this, we will incorporate the Expected default frequency (EDF) from KMV model (https://www.math.hkust.edu.hk) [20]. We will modify the EDF to suit individual case by changing asset (V) to wealth (Y). Expected default frequency (EDF) is a forward-looking measure of actual probability of default. Three steps to derive the actual probabilities of default:
1) Estimation of the wealth and volatility of the individual’s wealth (This is already included in the initial computation by Black-Scholes [2]).
2) Calculation of the distance to default, an index measure of default risk.
3) Scaling of the distance to default to actual probabilities of default using a default database.
Our focus is on the distance of default.
Distance to default
Default point,
Recall, equity
and
distance to default,
Now apply EDF to Equation (5) and replicating the process for the risk neutral process in the real world we have:
(7)
where
where
is the probability that there will be a default applying EDF using “distance to default” at any time
.
There is a formula that shows the relationship between the risk neutral and real world, this formula can switch between risk neutral and real world as shown below: From Equation (7) above we know
The risk neutral EDF is
Finally
(8)
We will stick with risk neutral (RN) world to complete the rest of the paper since we now know how to switch between risk neutral and real world using EDF Equation (8) above.
3.2. Individual Equations
We will follow the case of a company and try to see that there is also a call option on the value of the wealth with a strike price equal to the repayment of the debt. We will discount the wealth equation and try to do an estimation using the Black-Scholes [2] formula
We start the derivation with equity equation:
from the previous sub-section we know
for any
.
Recall
For an individual to pay his debt, this condition has to be satisfied
Next
Then
It is easy to see that
Note that:
Then we have
Like the case of a company in Hull [21] we will find that
Following the case of the company we have that the first time above is equal to
where
and
.
By following the same process as the company case and completing the square on the exponent and doing the necessary cancelations we have that the second term above is equal to
and the final term of that equation is equal to:
so finally we have this equation for individual equity:
(9)
We just proved the following theorem:
Theorem 2: Under these conditions with
and D above. The equity at time t is given by the following formula:
The second equation for individual scenario is practically like the first in the case of company:
We can thus regard
as a function of
. Since
is a GMB so is
, thus we have
Using Ito’s formula
(where
is other higher terms which we can ignore from Ito’s formula). We then replace
,
in the above
We then compare the left and right side of the equations we have
We already showed that
in the case of the company, replicating the same process we will find out the same equation is true as derived earlier that:
(10)
3.3. Incorporating Wages into the Wealth Equation
The last two sections have been mainly focusing on the individual and company wealth and equity derivations. In this section we will look at incorporating wage into the individual equation as wage is an integral part of an individuals wealth.
Now we will consider a new factor in the wealth equation
where
= wealth, r = risk neutral rate,
= volatility, and
= consumption.
We will now incorporate wage/salary (
) into the wealth equation, as wage is part of every individuals source of wealth. Then we have:
our new equation is now
Replicating the whole process of the individual probability of default we will replace
by
, we will have the new probability of default approximated by:
This represents the individual risk neutral probability of default factoring in the wage into this equation where
3.4. Default Probability at Any Time t
To estimate the probability of default within the life of a debt (D),
, the default probability at any time t is given by the formula
We have been considering the risk neutral probability of default by assuming that
(drift), but the if we consider the risky or real world probability of default by subjecting all rates to the drift μ = drift(returns on investment) we will have
This is the real world probability of default.
3.5. Individual Default Intensity
Recall that the equation of the default intensity of a company was computed as
and
Now we have
Next we have
Taking the log of both sides of the above equation
Taking now the derivative of both sides of the above equation we have
The derivative is
where
and
We just proved the following theorem for harzard rate
:
Theorem 3: The harzard rate of individual
with
and
defined above under our model, is given by the following formula:
3.6. Risk Premium on Corporate Debt and on an Individual
For an individual, a risk premium is the minimum amount of money by which the expected return on a risky asset must exceed the known return on a risk-free asset in order to induce an individual to hold the risky asset rather than the risk-free asset. It is positive if the person is risk averse. Thus it is the minimum willingness to accept compensation for the risk.
Value of asset at time T is given by
Equity at any time t is given by the formula
Recall that
and
, where
is the discounted debt at any time t in the risk neutral world
so
Recall,
where
and
.
We have that
Then we have
Next we factor out
Then
Next,
It follows that
We take ln of both sides to take care of the exponent
Hence we have that,
which is the corporate risk premium as required.
For the individual risk premium by following the same steps as above we have
That is
with
We just proved the following theorem:
Theorem 4: The individual risk premium is given by:
where
is the expected return on risky asset and r is the risk-free asset.
3.7. Recovery Rate at Default
The recovery rate if there is a default is the expected value of the asset given that the value of asset is less than the debt. From Hull [21] we see the definition of the recovery rate, we can compute the recovery rate at default of individuals in our case.
Recovery rate at default is the expected value of asset given that the asset is less than the debt (when value of asset is less than debt, this is the condition for default i.e.
)
where
is the condition to find the risk neutral
(
) recovery rate, hence we have
Recovery rate of
(risk neutral) is:
where
and
, we have
shown the computations of
and
earlier.
In the case of an individual with consumption and wages we have
where
is the condition for
risk neutral recovery rate, then we have
where
and
, for every
.
The recovery rate for an individual is now
The computations of
and
for individuals has been shown earlier in this chapter in pages 17 to 19.
The following theorem was proven above:
Theorem 5: The recovery rate at default under the conditions above is given by the formula
4. Conclusions
In this paper, we considered an extremely important tool for decision making within financial institutions—credit risk. Because of the risk of default on the part of depositors and customers, regulators have for many years required financial institutions to maintain a certain capital level to reflect the credit risk they bear.
We used the work originally published by Merton [1] and Black and Scholes [2] model used for computing the premium of an option. In our discussion, we also looked at replicating an individual scenario using equity prices to estimate default probability. To achieve this we incorporated Kohn’s [18] work on optimal portfolio selection and consumption, which involves the HJB equation, utility function. In order to do this, we considered the nature of an individual’s wealth and its distribution among risk free assets, risky assets, wages and consumptions.
In the concluding part of this paper, we computed individual default intensity, recovery rate and risk premium. The risk premium model is applied to the simplest form of corporate debt. The discounted bond where no coupons are made and a formula for putting the risk structure of interest rate is presented and in the later part of section four we proposed the individual formula for risk premium.
In practice, some of our conclusions have been in use and others are still in the pipeline, our submission is that individual risk premium and recovery rate would help to model mortgages pricing for individual and will minimize exposure to individual default rates.
Further Research Suggestions
One important idea that follows directly from this paper seems interesting for the future studies. We can redefine consumption and make it dynamic and dependent on wealth in the equation
we then re-adjust the consumption part and we will have
As such the value
will not be constant anymore.
So, there will be no need to approximate
as
This will make our computations easier and also change the situation with the version with the wages by making this also dynamic and subjecting it to
.
Then we will have
the new combination of equation with consumptions and wages becomes
This will subsequently make the computation easier.
Another very interesting topic to look at is the concept of default correlation. This topic is a critical concept in risk management for fixed income investment, bank management, insurance companies, working capital management and so on. The term default correlation is used to describe the tendency for two companies to default at about the same time. There are a lot of reasons why correlations exist. One good reason companies might be in the same geographical areas and another reason is that the companies might be in the same industry; these are driven by the overall economic happenings, events, policies and so on. A default by one company leads to default of another is called credit contagion. When there multiple risky bonds or assets in a given portfolio, a single default correlation between two firms can be extended to a correlation matrix.
Default model focuses on the event of default and we show it defined as follows: We denote the probability of default by an indicator variable
, which shows firm i defaulted as thus:
The variable
is the probability that the firm i defaults, while
is an indicator variable, the expected default as a variance is as follows
This is a non parametric approach. A non-parametric approach would involve the use of sample version of a dependence measure to calibrate the copula parameters.
We can define the default correlation of firm i andj as:
A simplification of this expression is the joint default probabilities shown below:
which follows the previous equation above.
This shows that the probability of joint default is linear in the correlation of joint default.
Default correlation is important in the determination of probability distributions for default losses from a portfolio of exposures to different counter parties. There is need for more research into Gaussian Copula which deals with individual probability functions into joint probability functions.
Two different types of default correlation models that have been suggested by researchers are referred to as reduced form models and structural models. Reduced form models assume that the default intensities for different companies follow correlated stochastic process, while Structural models are based on Merton’s [1] model, or one of its extensions, where a company defaults when the value of its assets falls below a certain level. Default correlation is introduced into a structural model by assuming that the assets of different companies follow correlated stochastic processes.
Unfortunately the reduced form model and the structural model are computationally time consuming for valuing instruments. This has led market participants to model correlations using factor copula model where the joint probability for the times of default of many companies is constructed from marginal distributions, we will not look at this in this paper.
This could then form the basis for utilization of a standard type done by Merton [1] with a view of incorporating individual default probability and further work for company default probability models.
In Merton’s structural models, further work could be done by adding stochastic volatility and/or statistical risk free rater (
) to the model. This model if researched will allow for flexibility and accuracy to capture environments where the firm’s asset volatility is stochastic, asset returns can jump, and asset shocks are non-normal. As a result, this model will also provide estimates of daily asset returns and asset volatility.
The issues of multiple defaults and default correlation are very relevant for risk management, financial mathematicians credit derivatives, and credit analysis. There will be need in the future to extend Merton [1] framework to accommodate multiple defaults. The aim is to present a simpler and unified framework for computing single and joint default probabilities for more than two firms in closed form. The results are relevant for various financial and credit applications. The Bivariate Normal Probability Integral can be seen as presented by Smith [15] as follows
X, Y both normal random variables with mean 0 and unit variance
Also
Some uses of this model is
European option on an asset with a known dividend payable before expiration (bivariate, Roll-Geske-Whaley). Explicit formulas, such as the two quoted immediately above, are useful as control variates for variance reduction in Monte Carlo simulations used to calculate the value of exotic options. Rainbow options (bivariate, trivariate, multivariate, Ouwehand-West). A rainbow option is exposed to two or more sources of risk, such as natural resource deposits (price and quantity are random). Often these are calls or puts on the best or worst assets in a portfolio of stocks and are heavily dependent on correlation.
Another area that should be considered for further research is the change of hazard rates (default intensities) from risk neutral to using equity (Merton’s) [4] to historical and vice versa. This is worth taking a closer look at as it will ease the transformation of calculations done on hazard rate using risk neutral, equity pricing, or historical data.
Finally, more work could be done on making debt stochastic and possibly defaulting before time T. Finger [16] in his paper proposed that the stochastic intensity model stipulates that in a given small time interval, assets default independently, with probability proportional to a common default intensity. In the next time interval, the intensity changes, and defaults are once again independent, but with the default probability proportional to the new intensity level. The evolution of the intensity is described through a stochastic process. In practice, since the intensity must remain positive, it is common to apply similar stochastic processes as are utilized in models of interest rates. This could is a very interesting work and could serve as basis for more work in the future.