A Gaussian Multivariate Hidden Markov Model for Breast Tumor Diagnosis ()
1. Introduction
Breast cancer remains the most common and deadliest cancer worldwide. Statistics show that it affects women much more than men [1] . With an upward trend over the past twenty years, the developed countries seem to be the most affected. Little information is available on the situation in underdeveloped countries [2] [3] .
In the case of Madagascar, the non-existence of official statistics does not allow an inventory to be made on breast cancer. Data from the Institute Pasteur de Madagascar (IPM) shows that the average age of patients is 48 years. Although the data from the IPM does not represent the whole of the Malagasy reality, they nevertheless show that the number of cases of breast tumor continues to increase; it has become the most frequently observed cancer. The most affected age group in the series is 36 to 55 years old, see Figure 1. The youngest patient is 22 years old and the oldest 90 years old. Of all the cases that could be typed histologically, 2/3 are in the grade 3 infiltrating ductal carcinoma stage of the Scar-Bloom-Richardson histoprognostic classification (SBR) [2] .
Usually the diagnosis is very late and most cases are seen clinically only at an advanced stage of the tumor [4] . In addition to socio-economic factors, the structure of the health system makes the early diagnosis of cancerous lesions impossible in all Malagasy territories. Support establishments are almost non-existent outside the main cities (Antananarivo, Fianarantsoa). Indeed, according to IPM data, 80% of the cases observed come from the two large hospitals in the capital Antananarivo. In these situations, the ability to quickly and unambiguously detect the nature of a tumor is of paramount importance. This makes it possible to help specialists in the choice and type of treatment to prescribe from the early stages of its development [5] [6] .
However, studies have shown that the diagnosis of the intrinsic nature of cancer is not necessarily reliable at a fairly early stage of its development [7] . Leading to inadequate treatment, this false diagnosis increases the death rate of the disease. The biggest challenge is therefore to provide tools for the rapid and reliable detection of the nature of tumors. In addition to mammographic exams, mathematical and computer modeling tools can help us in this process [8] [9] . Several models have already been proposed to describe the evolution of breast cancer [8] [10] [11] .
We are interested in so-called stochastic models to describe the evolution of
![]()
Figure 1. Age of observed breast cancer patients in Madagascar, according to IPM data.
the breast tumor [11] [12] [13] . Given the small amount of information available, these models seem the most appropriate. In [11] the authors use a Markov chain to model the metastatic course of lung cancer. Generally, these models assume that tumor types are unambiguously determined based on observations. This is not the case in reality, appearances are deceptive. Hence the interest to consider the dynamics behind the observed data. The hidden Markov chain is one of the tools used to study the dynamics of a latent phenomenon such as breast cancer. It has already shown its proof in various situations such as the characterization and prediction of the evolution of tumors [14] [15] .
For breast cancer, the biomarker provides information on the nature of a tumor: benign or malignant [16] . However, due to the complexity and quantity of data to be exploited, it is necessary to be able to count on an agent who judges the observations objectively and reliably. In this article, our objective is to provide a tool to help diagnose the nature of a breast tumor at a primary stage. By having observations of the biomarker, we consider that the nature of the tumor is a hidden variable. The observable variables consist of the geometric properties of the tumor located on the mammary area. With probabilistic techniques, we will characterize the true nature of the tumor according to the observations. Based on a series of observations, we will determine the probability that the tumor is malignant or benign. This information is important in a country like Madagascar where diagnostic instruments are still very expensive and inaccessible.
2. Gaussian Mixture Hidden Markov Chain Model
A Markov chain is a model which allows the study of sequences of a random quantity. It is based on a very strong assumption that current information is needed to predict the future [17] . Introduced by Rabiner [18] , in 1998, the hidden Markov chain is an extension of this model. In most cases, the phenomena that interest us are not observable. The hidden Markov model (HMM) takes into account observed data and hidden events. Consider a markovian process (
) in a discrete state space
(1)
Because we are working on a discrete-time Markov chain, it is necessary to introduce the transition matrix A such that
. (2)
With an initial condition
(3)
For all t, the evolution of (
) is unobservable. What we have instead is an observation (
) which can take its value in a finite set
(4)
which depends on these hidden variables.
We then have an observation function
(5)
which gives us the probability of the observation knowing the state.
The Equations (1)-(5) characterize a hidden Markov model. The aim of our modeling work is to determine the nature of a breast tumor in the first phase of its evolution.
We assume that the patient's condition at time t corresponds to a malignant tumor or benign tumor:
. (6)
The process
is considered as an unobservable finite state space Markov chain, see Figure 2. The variable
represents the observations corresponding to the geometric properties of the tumor. Our goal is to use the series of observations to estimate the different parameters of the process.
Different very powerful algorithms have been developed to do this [19] . The forward-backward algorithm calculates the probability of the current state knowing the sequence of observations
[20] .
Let us summarize in θ all the parameters of the model: transition matrix, parameter of the probability distribution (mean, variance) for each state. By defining the functions α and β such that
, (7)
. (8)
We have
![]()
Figure 2. HIdden Markov Model (HMM) for breast tumor. Top: transition graph of the included Markov chain. Bottom: distribution of observations: Gaussian mixture.
. (9)
α and β allow us compute respectively the probability of a given sequences of observations given the parameter θ and a starting time t.
These values will be used in the learning phase (modify the parameter given new observations). The implementation is described by Table 1.
In our case, we are interested in the sequence of hidden states knowing the sequence of observations it generated. The Viterbi algorithm, described in Table 2, solves this problem [21] .
Regarding breast cancer, the observable variable is not a singular value but a d-dimensional vector. This corresponds to the different measurements made on a patient during a diagnosis (temperature, concentration, etc.). Thus, we have
![]()
Table 1. Baum-Welch Algorithm for the implementation of the EM algorithm.
![]()
Table 2. Viterbi algorithm (generation of hidden state).
chosen a multivariate Gaussian density to model the probability of observation of each state [22] .
A multivariate Gaussian mixture is a function composed of the sum of several other functions (in most cases Gaussian functions) [23] . Given that our observations are multidimensional (several observed characters), we use a random vector
distributed according to a mixed Gauss distribution. Each component of the mixture has for average
, (10)
and a covariance matrix
, (11)
with
and
.
By associating to each component i a weight
with
, the expression of the Gaussian multidimensional distribution is
(12)
Thus, the Gaussian mixture
associated with the state k is characterized by:
1)
the weight of the component i of the mixture representing the density of the observable function of the states k,
2)
the mean vector of the random vector of the component i of the mixture k,
3)
the covariance matrix of the Gaussian density of the component i of the mixture k.
The parameters are estimated by implementing the Expectation-Maximization algorithm [22] described in Table 3.
3. Result and Discussion
As we do not have any database on breast cancer in Madagascar, we used the published database on breast cancer from Wisconsin to illustrate our model [24] . With a sample made up of 569 individuals, the authors measured 30 parameters which make it possible to determine the state of the tumor (malignant or benign). These 30 observations characterize the two types of cancer that we want to identify. Figure 3 represents the correlation matrix of the characteristic variables.
This figure shows that some of the variables are related. Going from light blue to dark blue, the figure shows the degrees of relationships between the covariates.
It is possible to reduce the number of variables by a principal component analysis. We have plotted the empirical distribution of the geometric characteristics according to the type of tumor, see Figure 4. In particular, we are finding that some of them are easy to distinguish between the tumor types, while others do not.
After switching to principal component analysis, we concluded that a 2-dimensional subspace is sufficient to keep 95% of the variance of the observed data. Figure 5 represents the projection of individuals on the two main.
The number of components of each mixture can be calculated using the Bayesian
![]()
Table 3. Expectation Maximization algorithm for a gaussian mixture multivariate model.
![]()
Figure 3. Correaltion of characteristics variables.
Information Criterion (BIC) on each of the data that we have for the different types of tumors [25] . For an observation, the point clouds are obtained by making a vector product on each of the two eigenvectors.
We thus have the number of optimal components for each mixture. Our results show that the number of suitable components for the benign type is k = 2 while that of the malignant type is k = 3. Which is quite logical because of the arrangement of the points in the Figure 5. The arrangement on the point clouds of malignant cases is quite dispersive, so it is logical that its mixture has more
![]()
Figure 4. Empirical distribution of geometric characteristics according to the type of tumor.
components than the other type. For each of the two states (malignant and benign), we estimate the parameters of their distribution using the Expectation Maximization algorithm. Learning is supervised because we already know for each observation the state that generated it. The parameters of the Gaussian distribution for each mixture are given in Table 4 and Table 5.
Thus, we have a probability density which makes it possible to associate a probability value for each observation, see Figure 6. For each observation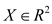 , we calculate its probability conditioned by all the parameters
, we calculate its probability conditioned by all the parameters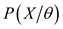 . The “+” sign represents the averages. Its size is proportional to the weight of the component
. The “+” sign represents the averages. Its size is proportional to the weight of the component
![]()
Figure 5. Projection of the sample on the principal axes after the principal component analysis.
![]()
Table 4. Parameters of the distribution of the state “malignant” tumor.
in the mixture.
With the estimated parameters, we performed a simulation on the model. The result of the principal component analysis of the simulated data are represented in the Figure 7.
By comparing this result with the real data in Figure 5, we can deduce that the result is reliable. This concerns the efficiency of the EM algorithm in estimating
![]()
Table 5. Parameter of the distribution of the state “benign” tumor.
![]()
Figure 6. Projection of the probability density of the two principal components after normalization.
![]()
Figure 7. Principal component analysis with simulated data.
the parameters of a Hidden Markov model.
Using a simulation, we illustrate the approximation of the real data by the simulated data from the model. Considering the two tumor states: malignant and benign, Figure 8 represents a realization of the Viterbi algorithm (Table 2).
The first red curve represents the actual condition of the tumor (1 for benign and 0 for malignant) and which is assumed to be hidden. The blue curve below corresponds to the state estimated by the algorithm and is the component most likely to have generated the observations. The estimate was made using the observation sequences projected onto the two eigenvectors and represented by the two lowest blue curves. According to this figure, the model manages to bring
closer the true natures of the tumors during its evolution.
This model is therefore a real additional tool which can help specialists in the diagnosis of breast tumors at an early stage. Simulations with breast cancer data show that inference with a Gaussian mixture hidden Markov model can help us characterize the internal nature of the disease.
![]()
Figure 8. Simulation of the model with the Viterbi algorithm.
4. Conclusions
Faced with the difficulties in diagnosing breast cancer, specialists need other decision-making tools. Especially in an underdeveloped country like Madagascar, patient reception structures remain insufficient. The cost of health examinations is very high and the support is done late. This article constitutes our contribution to the anticipation of decision-making according to the geometric characteristics of the tumor. As we do not have a database on breast cancer in Madagascar, the inference of our hidden Makov model was made with data on breast cancer from Wisconsin, available on the web. As the observations relate to several variables related to the geometric characteristics of the tumor, we chose the multivariate Gaussian distribution for the distribution of observations corresponding to each state.
By implementing the Viterbi algorithm, we succeeded in identifying the parameters of the distribution of observations corresponding to each state of the tumor: benign or malignant. With the estimated parameters, we reproduced the initial data set under the same conditions. The result is significant.
The interest of our modeling work is both to characterize the nature of tumors as early as possible and also to predict its evolution. This is important especially in the event that our health system is not yet ready for support. Even if the data from the Institut Pasteur de Madagascar (IPM) are not representative, the frequency of the observed cases shows that the situation is critical. To be able to carry out more in-depth studies, specialists recommend the establishment of a database on breast cancer in Madagascar.