Six-Element Yagi Array Designs Using Central Force Optimization with Pseudo Random Negative Gravity ()
1. Introduction
The Yagi-Uda array (Yagi) has been around for nearly one hundred years [1] [2], undoubtedly because of its ability to provide excellent performance across a wide range of antenna measures, always in a simple geometry and often in a compact one as well [3]. The basic Yagi comprises a single driven dipole element (DE) flanked by a single parallel parasitic reflector (REF) on one side and any number of parasitic parallel directors on the other (Di). A typical six-element geometry is shown in Figure 1 (red dot marking DE feedpoint). The X-axis is the Yagi’s “boom”, and the array’s elements are an arranged along it in the X-Y plane parallel to each other and to the Y-axis as shown. REF, the element that is closest to the Y-axis, is closer to DE than the first director and longer than DE while the Di are shorter, but these characteristics do not by any means constitute absolute design requirements, as they simply are typical geometry that produces appropriate phase and current relationships between the array elements.
A complete Yagi design must include the lengths and diameters of each element and the inter-element spacings. A six-element array thus has seventeen design parameters (six element lengths, six diameters, and five spacings). If the feedpoint input impedance is considered a design variable as well (discussed below), then the design/optimization (D/O) problem comprises eighteen dimensions. Many Yagis have far more than six elements, and every additional one adds three more design parameters (variables) to the problem.
There is no accurate analytical approach to Yagi array design using models that assume purely sinusoidal element current distributions and that neglect their mutual couplings. These assumptions lead to inaccuracies, and as a result many design approaches are inherently approximate or based entirely on empirical data [3] [4] [5]. The difficulty in analytically calculating a Yagi’s element currents is highlighted by the fact that there is no known formula for expressing the current distribution on even the simplest of radiating elements, a single center fed dipole in free space [6].
2. Methodology
2.1. Background
Over the past two decades or so, in response to the limitations described above, Yagi D/O largely has been done using metaheuristics, that is, algorithms that provide acceptable solutions in reasonable times without being exact or having a
mathematical proof that the optimal solution eventually will be found [7]. Many Global Search and Optimization (GSO) algorithms have been applied to the Yagi design problem against a variety of performance measures using various techniques, as examples: Gain, impedance, bandwidth using Particle Swarm Optimization (PSO) [8]; Yagi design using Multi-Objective Differential Evolution (DE) [9]; 6-Element array design based on Gain-Impedance Multiobjective Optimization [10]; Overview of Yagi design methods, many of them GSO’s [11]; Evolutionary methods for Yagi design [12]; Maximum gain optimization using Biogeography Based Optimization (BBO) variants [13]; Ultrawideband 6-element Yagi design using CFO/Variable Z0 [14]; 6-Element Yagi design using Dominating Cone Line Search (DCLS) [15]; Dipole array optimization using Fitness-Adaptive DE [16]; Yagi design using Genetic Algorithms [17]; Wideband 6-element Yagi design using Adaptive DE [18]. These are only a sampling of the dozens if not hundreds of GSO approaches to Yagi-Uda array design.
This paper reports results for a typical 6-element Yagi design developed with a basic Central Force Optimization (CFO) implementation that includes a small amount of pseudo randomly injected negative gravity. CFO is a deterministic evolutionary metaheuristic that analogizes gravitational kinematics (motion of masses under the influence of gravity) [19], and it has been applied to antenna D/O on a variety of structures, [20] - [28] being representative examples. CFO and modifications have been further developed and applied to a variety of other problems as well, [29] - [38] serving as examples. CFO is fundamentally deterministic, which in fact was a prime consideration in its formulation. Every CFO run with the same setup yields the same results, thereby eliminating the need for statistical analysis of possibly hundreds or even thousands of runs as required by fundamentally stochastic GSO’s. Determinism can be very important in dealing with “real world” antenna problems, and also others, because one of the unknowns in a real problem is defining a suitable fitness function. This task is made much simpler by using a metaheuristic whose results depend only on user input and not on the randomness of a stochastic algorithm. This issue is discussed in detail with examples in [39].
CFO explores a D/O problem’s landscape by flying through its decision space (DS) “probes” whose trajectories are governed by equations analogous to those governing gravitational kinematics. DS comprises vectors
whose components xi are the Nd Yagi array design (decision) variables (element lengths, spacings, diameters, and Z0) with their allowable ranges (min/max values for each). Each such vector represents a complete array design. A CFO run begins with an Initial Probe Distribution (IPD) whose configuration is determined by the algorithm designer. The possibilities are limitless, and some IPD’s work better than others. In many recent CFO implementations a “probe line” IPD has been used in which CFO’s probes are arranged uniformly on lines parallel to the DS axes and intersecting along DS’s principal diagonal. For the work reported here, however, a pseudo random π-fraction IPD was used because it is simpler. π-fractions also were used to determine the degree of injected negative gravity. As a result, and as expected, the target and actual levels of negative gravity are not precisely equal.
Even though CFO is deterministic, it is reasonable to speculate that CFO may benefit from the inclusion of a pseudo random component. A pseudo random variable (prv) is a number known precisely by enumeration or calculation, in contrast to a true random variable (rv) whose value is a priori unknowable because it must be calculated from a probability distribution. With respect to any D/O problem, the prv is “random” in the sense that it is uncorrelated with the problem’s topology (“landscape”). Additionally, the prv’s themselves must be uniformly distributed and uncorrelated. Pseudo randomness is included here using π-fractions generated by the Bailey-Borwein-Plouffe (BBP) algorithm. A detailed discussion of π-fractions and their use in a sample GSO algorithm, πGASR (Genetic Algorithm with Sibling Rivalry), appears in [40].
2.2. CFO Run Setup
A detailed description of the basic CFO algorithm is in the Appendix Part 2. Run parameters and the decision space boundaries for the basic CFO implementation used in this paper appear in Table 1 and Table 2 and are discussed in detail in the Appendix. For this particular problem the Yagi element radius was fixed at 0.00635 m (1/2 inch diameter to facilitate easier fabrication). This simplification results in eleven geometric variables instead of seventeen. The twelfth variable to be determined by CFO is Z0, the Yagi’s feedpoint impedance. Variable Z0 (VZ0) is a patented “product-by-process” technology in which the antenna’s feedpoint impedance is treated as an optimization variable rather than as a fixed parameter as usually is the case. At this time VZ0 is publicly available for use by anyone who wishes to use it (U.S. Patent No. 8,776,002). CFO pseudo code appears in Figure 2, and the source code used to generate the data presented here is available on request to the author (rf2@ieee.org).
![]()
Table 2. Decision space boundaries.
2.3. Exploration vs. Exploitation in CFO
Positive gravity causes CFO’s probes always to move toward greater fitnesses, never away, and consequently to some degree perhaps to impede CFO’s exploration. CFO often converges very quickly [42], which is a favorable attribute, but not if it is at the expense of under-sampling DS, which may be the case. This paper speculates that adding some negative gravity causing probes to fly away from each other may improve CFO’s exploration because probes that otherwise would coalesce will explore further by flying into DS regions that have been under-sampled or perhaps not sampled at all. The effect of negative gravity is well illustrated in the discussion and figures in Section 6 of [43], and parameter values that insure CFO’s convergence on maxima are discussed in [44].
With respect to G’s sign, + or ‒, the specific question is, Does making it negative benefit CFO’s performance, and if so, why? Or does it impede it, and if so, why? To quote:
“‘Exploration and exploitation are the two cornerstones of problem solving by search.’ For more than a decade, Eiben and Schippers’ advocacy for balancing between these twoantagonistic cornerstones still greatly influences the research directions of evolutionary algorithms (EAs)...” [45], emphasis added. This issue also is discussed in [46] [47] [48]. Like all GSO algorithms CFO is subject to the inescapable tension between exploration (adequately sampling DS) and exploitation (quickly converging on global maxima). The test case reported here shows that a small amount of negative gravity indeed does benefit CFO’s performance, ostensibly because it enhances CFO’s exploration while retaining the algorithm’s ability to exploit already located maxima.
At each step negative gravity was pseudo randomly injected into CFO using π-fractions whose values are input from an external file containing the BBP-computed fractions πk, 1 ≤ k ≤ 215829 (k is the π-fraction index). In order to avoid correlations between the π-fractions (see [40] ), k is incremented by 5 at each step. If k exceeds 215829 it is reset to max(k-215827,3). The parameter 0 ≤ Pneg ≤ 100 specifies the target amount of negative gravity in percent, for example, Pneg = 6.5 sets the target at 6.5%. At each step the then current value of πk is tested against Pneg to determine whether or not gravity is negative at that step. Specifically, if πk ≤ Pneg/100 then
(negative gravity), otherwise
(positive gravity). Because prv’s are used, the nature of gravity at each step is a priori known precisely and is uncorrelated with the outcome at any other step. Also because prv’s are used, the desired (target) level of negative gravity and the actual level will not be precisely equal. As the CFO run includes more and more steps the difference between actual and target levels of G ≤ 0 grows smaller with a limiting value of zero because the π-fraction prv’s are uniformly distributed. For this Yagi D/O problem runs were made with non-uniformly spaced values of Pneg in [0, 20%]. The actual vs. target levels of G ≤ 0 is plotted in Figure 3 and shows good agreement.
Every CFO run comprised 550 steps, a large enough number to meet several
![]()
Figure 3. Actual vs Target Neg. Gravity with 550 Steps.
objectives: 1) allow fitness evolution essentially to saturate (more steps resulting only in incremental improvement); 2) create actual an actual degree of G ≤ 0 close to the target value; and 3) reasonable runtimes (~8 min on Win7/HP 64-bit SP1; Intel Core i7 4700MQ 2.4 GHZ). Because there is no accurate analytical model of the six-element Yagi-Uda array, the performance of each candidate design evolved by CFO was modeled using the NEC-4 Method of Moments code [49] whose accuracy is well established. Another version of NEC was used in the program 4nec2 (below) to compute and visualize performance data for the two CFO-optimized arrays at 0% and 6% G < 0 over a very wide frequency range (data in Appendix Part 1).
2.4. Fitness Function
The performance of every candidate antenna design was measured by the following simple fitness function (of course, the choice of fitness function is entirely up to the algorithm designer):
(1)
where subscripts L, M, and U denote lower, mid and upper frequencies at which the Yagi’s power gain, g, and feedpoint voltage standing wave ratio, S (not to be confused with spacing), are computed. The weights
and
were chosen for simplicity while intentionally favoring midband performance, slightly, with L = 294.8 MHz, M = 299.8 MHz, U = 304.8 MHz. VSWR (Voltage Standing Wave Ratio) is computed relative to the feed point impedance Z0 and denoted VSWR//Z0. While Z0 usually is a fixed, user-supplied parameter, typically the industry standard value of 50 Ω, VZ0 treats it the same as any other decision space variable. This approach embraces array current distributions that otherwise would be excluded because they fail to adequately match a predetermined value of Z0. Whether or not the CFO-returned value is feasible and desirable is an engineering and economic judgment, and more often than not it is worth impedance-matching the “non-standard” Z0because the antenna’s performance is better, often much better [50]. At each of the three frequencies L, M, U, NEC-4 returned the Yagi’s maximum gain and feedpoint impedance. Appendix Part 1 contains additional performance data computed with the freely available program 4nec2 that facilitates visualization of its computed data [51].
3. Results
3.1. Fitness Evolution
The reference Yagi design for this study is, of course, the one that CFO generates with zero negative gravity, the usual CFO implementation. Figure 4(a) and Figure 4(b) plot CFO’s fitness evolution as a function of Step Number with zero and 6 percent negative gravity, respectively. The maximum fitnesses are 47.8932 (0% G < 0) and 49.1892 (6% G < 0). Not only does injecting a small amount of negative gravity result in a slightly better fitness, but the fitness evolves quite differently with the 6% curve rising far more quickly than the 0% curve and with saturation taking place faster. This CFO implementation does not employ elitism (always including the best global fitness), so that here the best fitness at each step is a function only of the then current probe distribution.
How the fitness varies with the amount of negative gravity is plotted in Figure 5. For values below about 6% the fitness drops appreciably from its 0% value, but then it quickly recovers reaching a value higher than at 0% G ≤ 0 and settling into a plateau-like region up to about 10% G ≤ 0. Thereafter the fitness decreases monotonically through the test range of about 20%. The fitness plateau between approximately 6% and 10% is marked the “~region of optimality” on the plot because in that range the fitness is more or less flat. Fitness varies from the maximum value of 49.1892 at 6% G < 0 to a minimum of 47.392 at 6.36% G < 0. All other values are in this range, and consequently very similar one to the next and also to the 0% G < 0 value.
![]()
Figure 4. (a). Fitness Evolution with Zero Neg. Gravity; (b) Fitness Evolution with 6% Neg. Gravity.
![]()
Figure 5. Fitness vs amount of injected negative gravity.
Returning to the fundamental question addressed in this paper, Has pseudo randomly adding a small amount of negative gravity improved CFO’s exploration of the six-element Yagi’s decision space? The fitness data clearly show that the answer is “yes.” However, adding too much G < 0 prevents CFO from exploiting the solutions it has found. How much negative gravity is appropriate no doubt is problem-specific, but this array design example strongly suggests that every CFO implementation should experiment with some measure of G < 0.
3.2. Average Probe Distance
Step-by-step the normalized average distance from the probe with the best fitness to all other probes, denoted Davg, is a good measure of CFO’s convergence (see Appendix Part 2 for details). In many cases it approaches zero meaning that all probes have very tightly coalesced around the probe with the best fitness (maximum value). In other cases, such as here, the probe distribution more or less stabilizes but on average at some distance from the best probe.
Figure 6 plots Davg for the cases of zero negative gravity, (a), and for 6% G < 0, (b). Both cases initially show an extreme oscillation that diminishes with increasing Step #. This oscillatory behavior in CFO’s Davg appears to be correlated with local trapping and is not entirely unexpected in view of CFO’s metaphor of gravitational kinematics. In fact, in the real Universe similar oscillatory behavior is seen in the trajectories of Near Earth Objects (NEO’s) that become gravitationally trapped by the Earth’s gravity and eventually break loose without any energy loss [52] [53] [54].
In order to investigate Davg’s behavior in very long runs, two were made, both with Nt = 10,000 steps, zero negative gravity and at a target value of G < 0 of 5%. As discussed in Section 2.3 the actual and target levels of negative gravity are not equal except in the limit of an infinite number of steps. While both the 550-step
![]()
Figure 6. (a) Average distance to best probe, zero neg. gravity; (b) Average distance to best probe, 6% neg. gravity.
and 10,000-step runs targeted G < 0 at 5%, in the first case the actual value was 6% and in the second a much closer 5.22%. The Davg results, which are quite interesting, are plotted in Figure 7. In both cases, zero and 5.22% G < 0, Davg settles down to what appears to be a stable, uniform magnitude oscillation with much smaller amplitude in the 5.22% case. In fact, at 5.22% G < 0 Davg does not oscillate at all, and from steps #676-10,000 it is equal to 0.2352928. CFO’s probe distribution is stable and no longer changes step-to-step. In contrast, for the zero gravity case Davg oscillates in an erratic but repetitive pattern as seen in the expanded plot for steps 9900 - 10,000, Figure 8. It is reasonable to expect that these behaviors for cases zero and 5.22% G < 0 will continue indefinitely with an increasing number of steps. It is evident from these data that pseudo randomly injecting a small measure of negative gravity indeed does improve CFO’s exploration and apparently eliminates the probe trapping seen in Figure 8 as well.
3.3. Maximum Yagi Gain
The variation of maximum Yagi gain with degree of negative gravity is plotted in Figure 9. The antenna’s maximum gain occurs along the direction of its boom (the +X-axis) at NEC angles θ = 90˚, φ = 0˚ in its right-handed spherical coordinate system (see [49] ). With zero negative gravity the gain is 11.37 dBi, but at 6% G < 0 it increases to 11.92 dBi, which is a significant improvement. The max gain curve mirrors the Figure 8 structure of the fitness curve in Figure 5. Their shapes are very similar, and the array’s maximum gain is highly correlated with the array’s fitness as measured by Equation (1). Figure 10 plots the relative frequency of maximum gain as the percentage deviation from the midband reference frequency of 299.8 MHz. Its shape is quite irregular showing no correlation with either the fitness or maximum gain curves. The frequency of maximum gain is close to 299.8 MHz only for actual G < 0 of ~1.3% and in two narrow bands near 6% and ~11.2%. Otherwise the deviations from midband show considerable variability, ranging as high as nearly +3% and as low as about −2.4%.
![]()
Figure 7. (a) Average Distance to Best Probe, Zero Neg. Gravity; (b) Average Distance to Best Probe, 5.22% Neg. Gravity.
![]()
Figure 8. Probe average distance oscillation, steps 9900-10000.
![]()
Figure 9. Max gain vs injected negative gravity.
![]()
Figure 10. Max gain frequency relative to band center.
The array’s relative gain bandwidth
~ region of
optimality
3.4. Voltage Standing Wave Ratio (VSWR)
~ region of
optimality
![]()
Figure 11. −3 dB Gain bandwidth relative to band center.
Figure 12 shows the 2:1 VSWR bandwidth in MHz. In the approximate region of optimality it ranges from about 14.5 MHz to just over 20 MHz with much higher values on either side. The tradeoff for increasing impedance bandwidth is maximum gain. The overall best performing arrays discovered by CFO lie in the region of optimality. Figure 13 shows the 2:1 VSWR as a percentage of the midband reference frequency of 299.8 MHz. In the region of optimality it ranges from about 5% to just under 7%, so it is not particularly sensitive to the level of injected negative gravity. Outside this region it does reach higher values, but, again, the tradeoff is with maximum array gain.
![]()
Figure 12. 2:1 VSWR bandwidth vs neg. gravity.
As a final measure of the optimized antennas’ performance Figure 14 plots the fractional 3:1 VSWR BW as a function of percentage G < 0. As expected, the 3:1 impedance bandwidth is much greater than its 2:1 counterpart, quite large in fact over much of the region of optimality But as a practical matter not many communication systems tolerate VSWR’s in the 3:1 range well, and it is a level generally to be avoided if at all possible.
4. Conclusion
This paper reports the results of the D/O of a six-element Yagi-Uda array using Central Force Optimization with pseudo randomly injected negative gravity. Adding 6% G < 0 results in an array that out performs its 0% G < 0 counterpart and also discovers a range of designs with similar fitnesses. Negative gravity was inserted using π-fraction pseudo random variables thereby preserving CFO’s determinism, which is an important consideration in real-world problems that require the formulation of a suitable fitness function. G < 0 has the effect of spreading apart CFO’s probes because negative gravity is repulsive in nature instead of attractive. This wider dispersal improves CFO’s exploration of the decision space without sacrificing the algorithm’s demonstrated high level of exploitation. Injecting some level of negative gravity likely will improve CFO’s exploration across the board, not only in the Yagi array D/O problem but in other applications as well. This particular problem is only one example of the benefit provided by injecting some small measure of negative gravity, and it does not (necessarily) provide specific guidance as to how much G < 0 should be used in any other particular case. The effect of negative gravity in CFO is a research area that should be pursued because the work reported here strongly suggests that there may be considerable benefit in doing so.
Appendix Part 1: Additional Yagi Performance Data
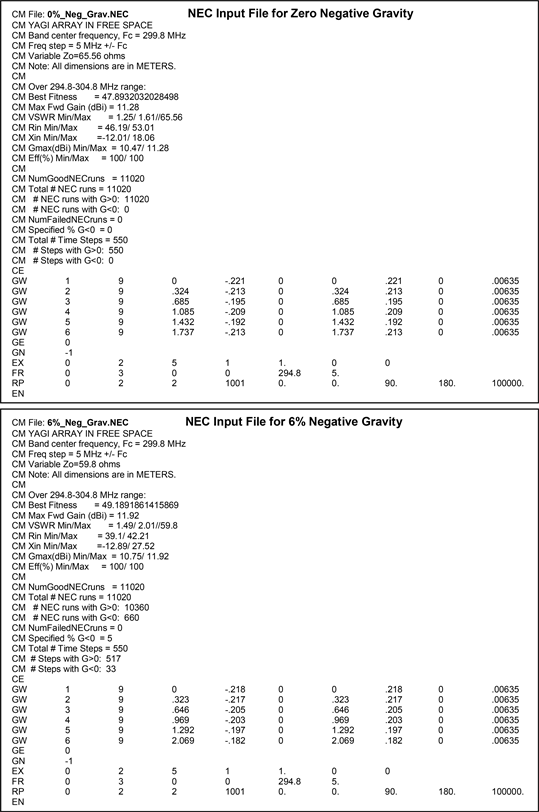
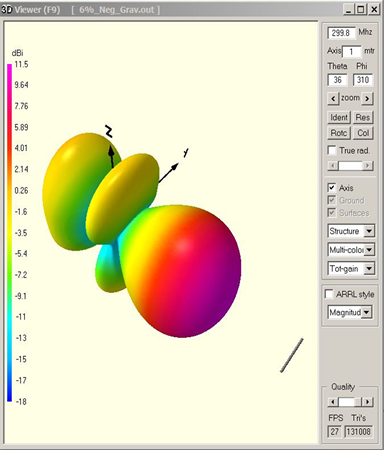
CFO’s best fitness NEC input files at zero and 6% G < 0 fully define the array geometry and Z0. NEC input files appear immediately below, 0% G < 0 first, followed by 6% G < 0. Dimensions are in meters, and since the wavelength, λ, at 299.8 MHz is 1 m the array dimensions also are in λ. The array can be scaled to any other frequency by scaling its dimensions by the wavelength ratio. Also in this Appendix are screenshots of the 4nec2 (ver. 5.8.17) output: 1) 3D radiation patterns @ 299.8 MHz; 2) power gain, VSWR//Z0, and feedpoint impedance for 250 - 350 MHz and for 294.8 - 304.8 MHz, and 3) NEC Average Gain Test at 299.8/250/350 MHz.
In the following screenshots 0% G < 0 is on the left, 6% G < 0 on the right.
3D Radiation Patterns (299.8 MHz)
![]()
4nec2 Summary Data, 299.8 MHz (with Average Gain Test, AGT, results)
![]()
![]()
Total Gain (dBi), 294.8 - 304.8 MHz (note: 4nec2 does not compute F/B if Gain is selected)
![]()
![]()
VSWR//Z0, 294.8 - 304.8 MHz (Z0 = 65.56Ω @ 0% G < 0; 59.8Ω @ 6% G < 0)
![]()
![]()
Feedpoint Impedance, 294.8 - 304.8 MHz
![]()
![]()
Total Gain (dBi), 250 - 350 MHz (note: 4nec2 does not compute F/B if Gain is selected)
![]()
![]()
VSWR//Z0, 250 - 350 MHz (Z0 = 65.56Ω @ 0% G < 0; 59.8Ω @ 6% G < 0)
![]()
![]()
Feedpoint Impedance, 250 - 350 MHz
![]()
![]()
4nec2 Summary Data, 0% G < 0, 250 & 350 MHz (including AGT results)
![]()
![]()
4nec2 Summary Data, 6% G < 0, 250 & 350 MHz (including AGT results)
![]()
![]()
Appendix Part 2: Basic Central Force Optimization
A2.1. The CFO Metaphor
Central Force Optimization (CFO) analogizes gravitational kinematics, the motions of real bodies in the real Universe under the influence of gravity. The fundamental law of physics is Newton’s Universal Law of Gravitation, according to which the magnitude of the force between the two masses
and
is given by [55]
(A1)
where r is the distance between them and
the “gravitational constant.” This force always is attractive, never repulsive, and mass in the real Universe always is positive, never negative. The force of gravity is a central force because it acts only along the line connecting the mass centers. Mass
experiences a vector acceleration due to mass
that is given by
(A2)
where
is a unit vector that points toward
along the line joining the masses.
A2.2. Problem Statement
The CFO metaheuristic solves the following problem: In a decision space (DS) defined by
where the
are decision variables, locate the global maxima of an objective function
possibly subject to a set of constraints
among the decision variables. The value of
is called the “fitness.” CFO explores DS by flying metaphorical “probes” whose trajectories are governed by equations of motion drawn from gravitational kinematics.
A2.3. Constant Acceleration
The vector location of a mass under constant acceleration is given by the position vector [56]
(A3)
where
is the position at time
.
and
, respectively, are the position and velocity vectors at time t, and the acceleration
is constant during the interval
. In standard three dimensional Cartesian coordinates
, where
are the unit vectors along the
axes, respectively. The CFO metaphor analogizes Equations (A1)-(A3) by generalizing them to a decision space of
dimensions.
A2.4. Probe Trajectory
CFO’s probes in a typical three-dimensional DS are shown schematically in FigureA1. The location of each probe at each time step is specified by its position vector
, in which p and j are the probe number and time step index, respectively.
In an
-dimensional DS the position vector is
, where the
are probe p’s coordinates at time step j, and following standard notation
is the unit vector along the
axis.
Consider a typical probe,p. It moves from position
at time step
to position
at time step j under the influence of the metaphorical “gravitational” forces that act on it. Those forces are created by the fitness at each of the other probes’ locations at time step
. The “time” interval between steps
and j is
.
At time step
at probe p’s location the fitness is
. Each of the other probes also has associated with it a fitness of
,
being the total number of probes. In this illustration, the value of the fitness is represented by the size of the blackened circle at the tip of the position vector. In keeping with the gravity metaphor, the blackened circles may be thought of as “planets,” say, in our Solar System. Larger circles correspond to greater fitness values, that is, bigger planets with correspondingly greater gravitational attraction. In FigureA1 the fitnesses ordered from greatest to least occur at
,
,
, and
, respectively, as shown by the relative size of the circles.
Probe p’s trajectory in moving from location
to
is determined by its initial position and by the total acceleration produced by the “masses” that are created by the fitnesses (or some function defined on them) at each of the other probes’ locations. In the CFO implementation used in this paper the “acceleration,” analogous to Equation (A2), experienced by probe p due to the single probe n is given by
(A4)
where G is CFO’s “gravitational constant” corresponding to
in Equation (A1). Note that in the real Universe
, always. In CFO space, however, G can be positive (attractive force of gravity) or negative (repulsive force of gravity). Returning to the forces acting on probe p, in a similar fashion to probe n’s effect, the acceleration of probe p due to a different probe s is given by
(A5)
Note that the minus sign in Equation (A2) has been included in the order in which the differences are taken in these acceleration expressions. “Mass” in Equation (A2) corresponds to the terms in the numerator involving the fitnesses. Importantly, it does not correspond to the fitness itself. In these equations
is the unit step function
. And following standard notation the vertical bars denote vector magnitude,
, where
are the scalar components of
.
There are no parameters in Equation (A2) corresponding to the “CFO exponents”
and
, nor to the unit step
. In real physical space
and
would take on values of 1 and 3, respectively. Note, too, that the numerators in Equations (A4) and (A5) do not contain a unit vector like Equation (A2). The exponents are included to give the algorithm designer a measure of flexibility by assigning, if desired, a different variation of gravitational acceleration with mass and with distance.
A2.5. Mass in CFO Space
Two other important differences between real gravity and CFO’s version are: 1) the definition of “mass,” which above is the difference of fitnesses, for example,
, not the fitness value itself; and 2) inclusion of the unit step
. The difference of fitnesses is used to avoid excessive
gravitational “pull” by other close by probes that presumably will have fitnesses with similar values. The unit step is included to avoid the possibility of “negative” mass. In the physical Universe, mass is positive, always, but in CFO-space the mass could be positive or negative depending on which fitness is greater. The unit step forces CFO to allow only positive masses, that is, attractive masses. If negative fitness differences were allowed, then some accelerations would be repulsive instead of attractive, thus forcing probes away from large fitness values instead of towards them. The algorithm designer is free to consider other definitions of mass as well. One possibility, for example, might be a ratio of fitnesses similar to the “reduced mass” concept in gravitational kinematics.
A2.6. Total Acceleration and Position Vector for a Single Probe
Taking into account the accelerations produced by each of the other probes on probe p, the total acceleration experienced by p as it “flies” from position
to
is given by the sum of the gravitational effects over all other probes, that is,
(A6)
Probe p’s new position vector at time step j is therefore given by
(A7)
which is the analog to Equation (A3),
being the probe’s “velocity” at the end of time step
. In Equation (A7) the coefficient 1/2, the velocity term, and the time increment
have been retained primarily as a formalism to highlight the analogy to gravitational kinematics, but they are not required. For the CFO implementation used here, as a matter of convenience,
and
were arbitrarily set to zero and unity, respectively. Of course, if desired, a constant value of
and the factor 1/2 can be absorbed into the gravitational constant G.
A2.7. Errant Probes
An important concern is how to handle an “errant” probe, that is, one that flies outside DS, because it is possible that the total acceleration experienced by a probe will fly it into regions of unfeasible solutions that are beyond the DS boundaries. There are many ways to deal with this contingency, and a simple one was implemented in the basic version of CFO used here, the use of a “repositioning factor,”
. This factor is used to reposition an errant probe according to the formulas
(A8)
(A9)
is assigned an initial value and incremented at each step by a fixed amount
, and if it exceeds unity is reset to the initial value. This simple approach guarantees that all probes will remain inside the decision space. Note that this procedure is pseudo random in nature, but numerical experiments have shown that it is not as effective as pseudo randomly injecting a small amount of negative gravity.
A2.8. Davg Convergence Metric
Perhaps the best measure of CFO’s convergence is the “Average Distance”
metric computed as
, where
is the number of the probe with the best fitness; the superscripts p and j denote, respectively, the probe and step numbers as above; and
is the length of the decision space principal diagonal. If every one of CFO’s probes has coalesced onto a single point, then
. How closely this metric approaches zero is a good indicator of how CFO’s probe distribution has evolved around a maxima.
also is useful in identifying potential local trapping because oscillatory behavior in a
plot appears to signal trapping at a local maxima.