1. Introduction
Let
be a time series of size n. Methods in literature consider stationary models in explaining the underlying data generating process. However, stationarity is arguably a very strong assumption in many real-world applications as process characteristics evolve over time. Reviewed literature reveals that the use of one model may not be appropriate to model a non-stationary series and as such various change-point estimation methods have been proposed. However, they are limited in different ways and their suitability depends on the underlying assumptions. Statistical research works have shown that with time, the underlying data generating processes undergo occasional sudden changes [1]. A change point is said to occur when there exists a time
such that the statistical properties of
and
are different. In its simplest form, change-point detection is the name given to the problem of estimating the point at which the statistical properties of a sequence of observations change [2]. The overall behavior of observations can change over time due to internal systemic changes in distribution dynamics or due to external factors. Time series data entail changes in the dependence structure and therefore modelling non-stationary processes using stationary methods to capture their time-evolving dependence aspects will most likely result in a crude approximation as abrupt changes fail to be accounted for [3]. Each change point is an integer between 1 and n − 1 inclusive. The process X is assumed to be piece-wise stationary implying that some characteristics of the process change abruptly at unknown points in time. The corresponding segments are then said to be homogeneous within but each of the subsequent segments is heterogeneous in characteristics. For a parametric model the parameters associated with the ith segment denoted
, are assumed to contain changes. Parametric tests for change point are mainly based on the likelihood ratio statistics and estimation based on the maximum likelihood method whose general results can be found in [4].
Detection of change points is critical to statistical inference as a near perfect translation to reality is sought through model selection and parameter estimation. Parametric methods assume models for a given set of empirical data. Within a parametric setting change, points can be attributed to change in the parameters of the underlying data distribution. Generally, change point methods can be compared based on general characteristics and properties such as test size, power of the test or the rate of convergence to estimate the correct number of change point and the change-point locations. Change point problems can be classified as off-line which deals with only a fixed sample or on-line which considers new information as it observed. Off-line change point problems deal with fixed sample sizes which are first observed and then detection and estimation of change points are done. [5] introduced the change point problem within the off-line setting. Since this pioneering work, methodologies used for change point detection have been widely researched on with methods extending to techniques for higher order moments within time series data. Ideally, it is desired to test how many change points are present within a given set of data and to estimate the parameters associated with each segment. If τ is known then the two samples only need to be compared. However, if τ is unknown then it has to be analyzed through change point analysis that entails both detection and estimation of the change point/change time. The null hypothesis of no change against the alternative that there exists a time when the distribution characteristics of the series changed is then tested. Stationarity in the strict sense, implies time-invariance of the distribution underlying the process.
The hypotheses would be stated as:
(1)
The null hypothesis postulates that the distribution remains unchanged throughout within the sample of size n whereas the alternative postulates no change as in the null up to time τ when change occurs. Then the change point problem is to test the hypotheses about the population parameter(s)
(2)
where τ is unknown and needs to be estimated. If
then the process distribution has changed and τ is referred to as the change point. We assume that there exists
such that τ satisfies
(3)
where n is the number of observations in a given data set. Then hypothesis 2 can be restated as
(4)
At a given level of significance, if the null hypothesis is rejected, then the process X is said to be locally piecewise-stationary and can be approximated by a sequence of stationary processes that may share certain features such as the general functional form of the distribution F. Many authors such as [6] - [11] have considered both parametric and non-parametric methods of change point detection in time series data. Ideally, change points cannot be assumed to be known in advance hence the need for various methods of detection and estimation.
This paper is organized as follows: Section 2 gives an overview of the change point estimator based on a pseudo-distance measure. Section 3 provides key results for consistency of the estimator. Section 4 provides an application of the change point estimator to the shape and scale parameters of the generalized Pareto distribution. Section 5 gives an application of the estimator and consistency is shown through simulations. Finally 6 provides concluding remarks.
2. Change Point Estimator
The change point problem is addressed by using a “distance” function between distributions to describe the change. Given a distance function, a test statistic is constructed to guarantee a distance
between any two distributions based on a sample size n. Consider a given parametric model
where Θ is the parameter space defined on a data set of size n. Let
be random variables and have probability densities
with respect to σ-finite measure µ with
generating distinct measures if
Definition 2.1 (
-divergence). Let
and
be two probability distributions. Define the
-divergence between the two distributions as
The broader family of
-divergences that take the general form
(5)
where
is the class of all convex functions
satisfying
.
Assumption 1. The function
is convex and continuous. The restriction on
is finite, twice continuously differentiable with
.
At any point t = 0, to avoid indeterminate expressions [12] gives the following assumptions in relation to the functions
involved in the general definition of
-divergence statistics,
(6)
These assumptions ensure the existence of the integrals. Different choices of φ result in many divergences that play important roles in statistics including the Kullback-Leibler
, total variation
among others.
hence divergence measures are not distance measures but give some difference between two probability measures hence the term “pseudo-distance”. More generally a divergence measure is a function of two probability density (or distribution) functions, which has non-negative values and takes the value zero only when the two arguments (distributions) are the same. A divergence measure grows larger as two distributions are further apart. Hence, a large divergence implies departure from the null hypothesis.
Generally, a change point problem’s objective would be to propose an estimator for the possible change-point τ given a set of random variables.
Based on the divergence in 5 then a change point estimator can be constructed as;
(7)
where
and
are the maximum likelihood estimates of the parameters before and after the change point.
To test for the possibility of having a change in distribution of
it is natural to compare the distribution function of the first τ observations to that of the last (n − τ) since the location of the change time is unknown. When τ is near the boundary points, say near 1 or near n then we are required to compare an estimation calculated on a correct large number of observations (n − τ) to an estimation from a small number of observations τ. This may result to an erratic behavior of the test statistic [7] due to instability of the estimators of the parameters. If λ is not bounded away from zero and one, then the test statistic does not converge in distribution i.e. the critical values for the test statistic diverge to infinity as n → ∞ to obtain a sequence of level α tests [13]. However, fixed critical values can be obtained for increasing sample sizes when λ is bounded away from zero and one and yields significant power gains if the change point is in Λ.
Let ε > 0 be small enough such that
Suppose that λ maximizes the test statistic over [0, 1] then under the null hypothesis,
(8)
[13]. By this result and for
then the test statistic becomes,
(9)
The change-point estimator
of a change point τ is the point at which there is maximal sample evidence for a change in distributional parameters characterized by maximum divergence. It is estimated by the least value of τ that maximizes the test statistic 9.
(10)
3. Consistency of the Change Point Estimator
A minimal requirement for a good statistical decision rule is its increasing reliability with increasing sample sizes [14].
Let
be a sample of fixed size n with the density function
for
and
be the likelihood function. It can be shown that by Taylor’s theorem under the null hypothesis, the
, divergence based estimator can be reduced to a two-sample Wald-type test statistic of the form
(11)
Suppose
are iid random variables of size n with probability density function
with
being the vector of parameters governing the pdf. The likelihood function can be expressed as
(12)
It is more convenient to work with the logarithm of the likelihood function given by
(13)
Since the logarithm is a monotone increasing function, maximizing the likelihood function is equivalent to maximizing the log-likelihood function. Introduce the following notations:
(14)
(15)
(16)
(17)
The following equalities hold as
.
(18)
On assumption that
for
, then
(19)
Theorem 3.1. Let
(20)
Theorem 3.2. Let
for
small enough. Then as
(21)
For the proof of theorems 3.1 and 3.2 see [15].
Theorem 3.3. Let
and
For
(22)
Proof
(23)
The third term on the RHS is
[14]. By definition of MLE
.
(24)
From Equation (24) we obtain
Hence
(25)
But by Equation (18)
By theorem 3.1
is bounded in probability. Hence the proof.
Theorem 3.4. Let
for
small enough. Then
(26)
Proof
(27)
Considering the term on the RHS, by theorem 3.3. For
Hence the proof.
Assume that within a finite set of data a change point τ exists and
such that
Define,
Consider the following two sample homogeneity test
(28)
[15] defined a consistent estimate of 28 as
(29)
By the principles of maximum likelihood estimation,
since
,
since
.
Consider
. By Taylor’s theorem,
(30)
Since by the principle of maximum likelihood estimation
.
(31)
(32)
By the CLT,
and thus
has squared Mahalanobis norm
(33)
Hence
(34)
implying that
is approximately equal to the Mahalanobis norm of
. The Mahalanobis norm can be used to detect change points within a given finite time series data [11]. Since the test statistic 33 can quantify the difference between
and
then
can similarly be used to quantify the deviation between the two parameter estimates. The value of
ideally grows larger in evidence of the alternative hypothesis and tends towards zero when the null hypothesis is true. Suppose we define a maximal type test statistic
such that
(35)
then we can obtain a measure of the largest difference between
and
. Consider the divergence based estimator which was reduced to a two sample test statistic in Equation (11).
Definition 3.1. A matrix M is called positive definite if
, with equality if and only if
. The following inequality holds,
(36)
Consider the following result
(37)
By inequality 36
(38)
Consider the last term on the RHS. By the result of theorem 3.4
(39)
And hence
(40)
Considering the second term on the RHS. By the results in theorem 3.2,
(41)
From these results as
(42)
Definition 3.2. (Asymptotic consistency). A change point detection algorithm is said to be asymptotically consistent if the estimated segmentation is such that
(43)
The change point fractions are consistent, and not the indexes themselves. Consistency results in the literature only deal with change point fractions since the distances
and their estimated counter parts do not converge to zero [11].
4. Change Point Analysis in the Generalized Pareto Distribution
Definition 4.1. The Generalized Pareto distribution function is defined by;
(44)
where,
σ is referred to as the scale parameter characterizes the spread of the distribution and ξ referred to as the tail index/shape parameter determines the tail thickness. More specifically, given that
then the probability density function is;
(45)
For any given finite set of data, at least one of the following is likely at any given change point
: ξ changes by a non-zero quantity; σ changes by a non-zero quantity; both ξ and σ change by non-zero quantities. A simple change point problem can be formulated in one of the following ways;
(46)
(47)
(48)
Since change points are unknown in advance, then either of the three hypothesis formulations is likely. Without knowledge on the types of changes contained in the time series, the question arises on which testing procedure to use. In most instances hypotheses 46 is tested since it is assumed that both distributional parameters change.
Figure 1 shows different GP density plots with a constant scale parameter but varying shape parameters. On the other hand, Figure 2 shows different GP density plots with a both scale and shape parameters varying. If any of the parameters were to change at any given point in time, then the thickness of the general tail distribution would change and this would in turn have an effect of the intensity of extreme values observed.
Assume that X is independently and identically distributed random variables drawn for the generalized Pareto distribution and consider a sample data set
of fixed size n(n ≥ 3). Say
is governed by the parameter space
and
is governed by the parameter space
where
. The data set is assumed to contain an unknown change point τ where the distribution parameters ξ and σ abruptly change. Then
Then the density function 49 governs the first τ observations and 50 governs the last
observations.
![]()
Figure 1. Density plot with constant scale.
![]()
Figure 2. Density plot with varying scale and shape.
(49)
(50)
We will restrict to the case where
i.e. heavy tailed distributions thereby only considering the first part of the density function with support
.
From the divergence in Equation (5), let
(51)
An application of properties of the generalized Pareto distribution [16], numerical computations and methods of integration the divergence between two generalized Pareto distributions becomes
(52)
The divergence is a function of the parameters of the two densities.
5. Simulation Study
The performance of the estimator is examined by considering the effects of the change in sample size. The single change-point estimation problem is considered where the change-point τ is fixed at n/2 for n = 200, 500, 1000. Figures 3-5 display the plots for the location of the change-point estimator as estimated by the proposed estimator 10 with the divergence measure as in 52 for the various sample sizes. The hypothesis considered here is
(53)
![]()
Figure 3. Sample size= 200,
,
.
![]()
Figure 4. Sample size= 500,
,
.
![]()
Figure 5. Sample size= 1000,
,
.
To check consistency of the estimator, we consider the following: first, we consider data simulated from the GP density with parameters
and
for the scale and shape respectively before and after the change point. 1000 simulations are carried out to estimate the change point and the results are given in Table 1 and Table 2.
6. Conclusion
In this paper, a divergence (pseudo-distance) based estimator is used to detect change points within a parametric framework focusing on the generalized Pareto
![]()
Table 1. Effect of the sample size with varying scale and varying shape (
).
![]()
Table 2. Effect of the sample size with varying scale and varying shape (
).
distribution. Change points are attributed to the change in model parameters at unknown points in time with the parameter estimates before and after the change point unknown. The estimator is shown to be consistent theoretically. Simulation studies also show that the change point estimator is consistent.
Acknowledgements
The first author thanks the Pan-African University Institute of Basic Sciences, Technology and Innovation (PAUSTI) for funding this research.
Appendix
Derivation of the change point estimator
Consider a second order Taylor expansion of
about the true parameter values
For
(54)
Under the assumption of the null hypothesis,
(55)
This is by assumption 1 and that interchanges of derivatives and integrals are valid.
(56)
By the standard regularity assumptions (theorem 5.2.1) [14], then
(57)
Using the arguments in (55)-(57) Equation (54) reduces to
(58)
Further,
(59)
Assuming that a change point τ divides the data into two heterogeneous parts with the parameters
before and after the change point respectively with sample sizes τ, (n − τ) respectively, then by the regularity conditions the mles’s are such that
(60)
For 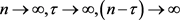
Let 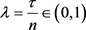 then,
then,
(61)
By the assumption of the null hypothesis
,
(62)
under the assumption that the parameter estimates are consistent.
Suppose that under the maximum likelihood estimation for a sample of fixed size n,
as
. By the law of large numbers, the observed information matrix is such that,
(63)
If we substitute
for
(64)
which is defined as a consistent estimator of the information matrix.
The elements of
are continuous in
and it holds that
(65)
From Equation (59) we obtain
(66)
From Equation (9) and Equations (56)-(66) then the test statistic can be expressed as
(67)
Let
(68)
But
Since the second and third terms of 67 are
then the distribution of
is similar to that of
.