Journal of Intelligent Learning Systems and Applications
Vol.4 No.2(2012), Article ID:19264,5 pages DOI:10.4236/jilsa.2012.42015
Aggregating Edge Weights in Social Networks on the Web Extracted from Multiple Sources with Different Importance Degrees
![]()
Institute of Information Technology, Azerbaijan National Academy of Sciences, Baku, Azerbaijan.
Email: rasim@science.az, r.alguliyev@gmail.com, *fadaig@yahoo.com
Received November 16th, 2011; revised January 30th, 2012; accepted February 7th, 2012
Keywords: OWA Operator; Orness; Data Source
ABSTRACT
Information on a given set of entities can be derived from multiple sources on the Web. Social networks built from these sources, using these entities as nodes, will have different edge weight values, although the entities will be the same. If these sources are different, one will not normally trust each of them equally. One source will be considered more or less importance than the other. Completely ignoring sources with little importance may yield unexpected results. In this paper, we propose a method for aggregating weight values for social networks built from the Web using different sources. First, multiple social networks are built from different data sources. Then the received edge weights are aggregated, with the importance of a data source taken into account.
1. Introduction
Presently there is a great deal of research being conducted on social network data extraction from the Web. Referral Web is considered the first such data-extraction system [1]. Y. Matsuo et al. developed a system called Polyphonet, which is used for extracting and analyzing social networks of academic figures [2]. The authors of [3] demonstrated how social network data can be extracted from email communication. There also exists a system that extracts social network information from a user’s email inbox [4]. The authors of [5] proposed an approach to resolve the problem of searching for people who share similar interests by using a person’s website content to represent that person. Some studies have extracted networks from friend-of-a-friend (FOAF) documents [6-8]. Academic researchers’ network extraction on the Web is also addressed [9,10]. Social networks on the Web have also been extracted by retrieving relationships between entities automatically derived from multilingual news [11], from log files of online shared workspaces [12], and from multiple unstructured sources on the Web [13]. Extraction of social networks has also been conducted via Internet and Networked Sensing [14]. The authors of [15] developed a model that helps estimate the strength of relationships by analyzing user interactions in online social networks.
The Web provides a rich set of data on virtually everything. For any given topic, one may obtain information from a variety of different sources. For example, one can extract information about a famous scientist from the scientist’s own website, from a social networking site, or from a digital library with scientific papers. Each data source will almost certainly provide different information about this scientist’s research activities. In other words, we need to rank these data sources and clearly identify how much we value each of these sources.
A social network is defined as a set of entities and the relationships among them. Edge weight in a social network is calculated based on information extracted from different sources. For example, say we need to compute the strength of the relationship between two scientists. Two data sources are used: co-authored papers and collaboration on a social networking site. We know that information about scientists’ research relationship from co-authored papers should be more reliable than from a social networking site. However, we cannot ignore information about their collaboration on the social networking site. Hence, we assign more rank to the co-authored papers but still consider the networking site.
Most of the research done on social networks on the Web involves working with one data source only. In this case, the network is single-relational, i.e., the weight value is of one type because it is extracted from a single data source. If we have multiple sources we can compute multiple edge weights. These weights are combined into a single weight, creating a multi-relational edge weight, and the resultant social network will be multi-relational. We assume multiple social networks are given, each with a single but constructed from a different data source (singlerelational). For each pair of nodes, we aggregate weight values to obtain a single resultant weight value, creating a multi-relational network. The aggregation method allows us to control the “weight piece” in the resultant weight based on the original weights. The next sections provide a detailed description of the method.
2. Aggregating Weights
Suppose multiple single-relational networks given. To aggregate edge weights for the networks, we used an approach that we proposed previously [16]. The single-relational social networks are merged into a single multirelational one. The edge weight between any two entities in the resultant network is the sum of the corresponding weights of the same nodes in the individual networks. Moreover, each weight in the sum is multiplied by a coefficient. The sum of these coefficients equals the unit. In other words, a single weight is made using the sum of weights from multiple networks; this single weight will be an edge weight of the resultant network. Formula 1 shows the process:
 ,
, (1)
(1)
where n is the number of networks,  is the weight of an edge between the actors i and j of the resultant heterogeneous network,
is the weight of an edge between the actors i and j of the resultant heterogeneous network,  is a coefficient that shows the degree of importance of the corresponding data source k (it shows how much we value and hence rank the source), and
is a coefficient that shows the degree of importance of the corresponding data source k (it shows how much we value and hence rank the source), and  is an edge weight between actors i and j from source k. Moreover,
is an edge weight between actors i and j from source k. Moreover,  .
.
Stated differently, the above formula represents an operator. Unknown variables are the weights of the single-relational networks, and the value of the operator is the weight assigned to the corresponding edge of the resultant network.
As an aggregation operator we use the ordered weighted averaging operator (OWA). OWA operators were first introduced by R. Yager [17] are defined as follows:
 which has an associated weighting vector
which has an associated weighting vector , such that
, such that ,
, and
and . Furthermore,
. Furthermore,
 , (2)
, (2)
where  is the largest element in the ordered bag
is the largest element in the ordered bag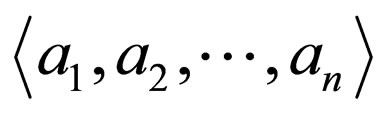 . This ordered bag is called an ordered collection vector.
. This ordered bag is called an ordered collection vector.
A fundamental aspect of this operator is the re-ordering step. An aggregate  is not associated with a particular weight
is not associated with a particular weight  but rather a weight is associated with a particular ordered position in the aggregate. Depending on the position in the sum, the same aggregate may have different weights.
but rather a weight is associated with a particular ordered position in the aggregate. Depending on the position in the sum, the same aggregate may have different weights.
Yager pointed out three important special cases of OWA aggregations:
•  : For this case,
: For this case,  and
and ;
;
•  : For this case,
: For this case, 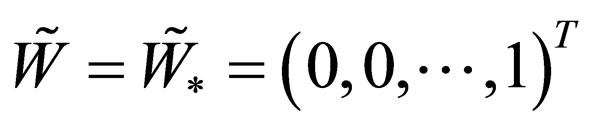 and
and ;
;
•  : For this case,
: For this case,  and
and .
.
From the above it becomes clear that for any OWA operator F,

To classify OWA operators in regard to their location between “and” and “or,” a measure of orness, associated with any vector , was introduced by Yager as follows:
, was introduced by Yager as follows:
 .
.
It is easy to see that, for any , the
, the  is always in the interval
is always in the interval . Furthermore, note that the nearer
. Furthermore, note that the nearer  is to an “or,” the closer its value is to one; while the nearer it is to an “and,” the closer it is to zero. Also note that for the vectors
is to an “or,” the closer its value is to one; while the nearer it is to an “and,” the closer it is to zero. Also note that for the vectors ,
,  and
and , orness equals 1, 0, and 0.5, respectively.
, orness equals 1, 0, and 0.5, respectively.
Making analogues of formula (1) with formula (2), we find that  is the edge weight
is the edge weight  and the importance coefficient
and the importance coefficient  in (1) is the corresponding weight vector value
in (1) is the corresponding weight vector value  in formula (2).
in formula (2).
3. Finding Importance Coefficients
At this point, the edge weights of the resultant network could be calculated, except the values for the unknown coefficients in formula (2) have to be found. Several approaches have been proposed to identify weight vectors for OWA operators. We use the one presented in [18]. The authors present an analytical approach to determine the weight vector, achieved by transforming the following mathematical programming problem into a polynomial equation using the Lagrange multipliers method:
 ,
,
 ,
,  ,
,  ,
,  ,
,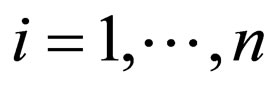 .
.
Solving this, the following formulas are used to obtain the optimal values of the weight vectors:

and
 .
.
Note that in the case of , we see that
, we see that .
.
4. Experiments
Note that the purpose of this paper is not to compute edge strength but to aggregate already-computed weights. Rather than considering the methods for building a social network from a given data source, we assume that the necessary networks have already been constructed. This can be accomplished in multiple ways, for example, using a general search engine. To verify the outcome of the presented method experimentally we suppose that three social networks are constructed from different sources for given five actors, as shown in Figures 1-3. In each source, we possess information about one relationship only.
Table 1 shows the edge weights that we assigned to each of the networks.
Suppose now that . In this case, we obtain a fourth-degree equation for finding the value of
. In this case, we obtain a fourth-degree equation for finding the value of . Solving this equation, we receive four roots, of which three are negative and one is positive. As a value for
. Solving this equation, we receive four roots, of which three are negative and one is positive. As a value for , we pick
, we pick

Figure 1. Social network from the first data source.

Figure 2. Social network from the second data source.
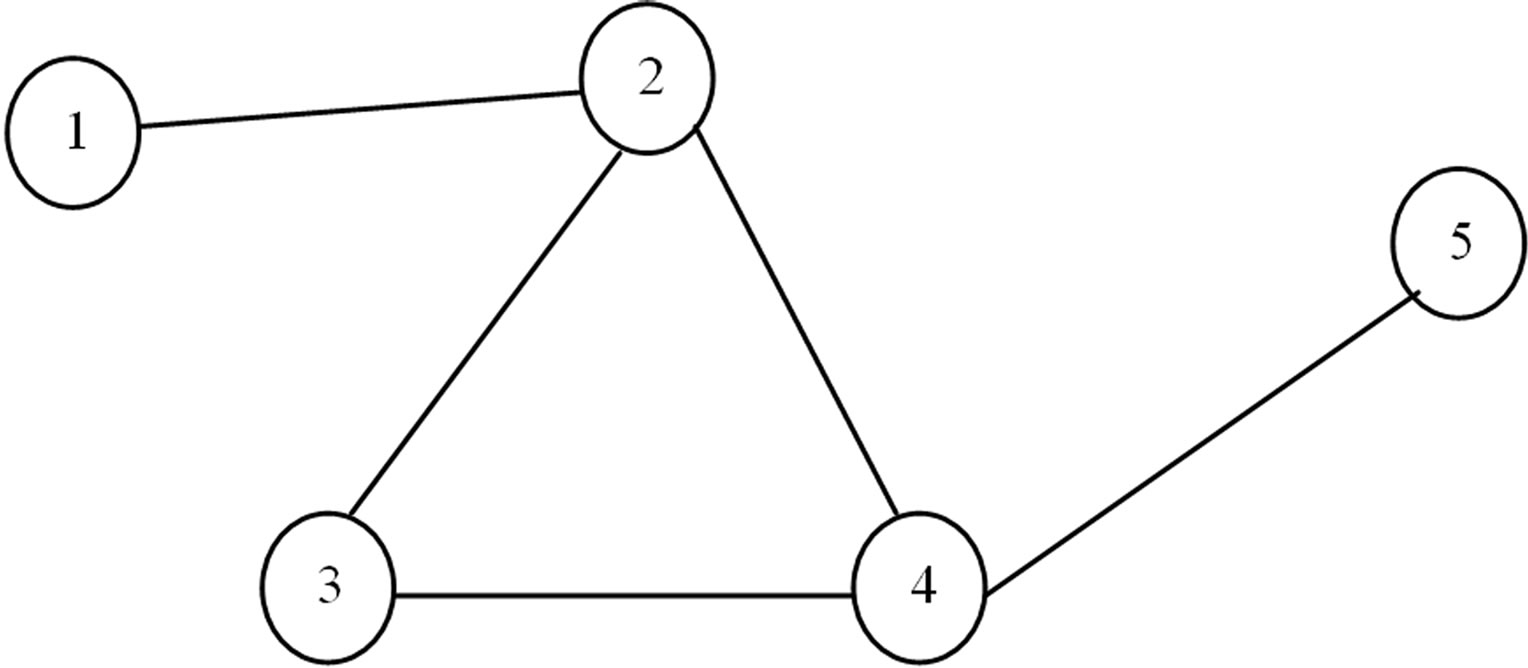
Figure 3. Social network from the third data source.

Table 1. Weight values for the social networks derived from the three data sources.
up the positive root of 0.08. From the last equation for , we find that
, we find that  = 0.68. Finally, from
= 0.68. Finally, from , we determine that
, we determine that . At this point, the corresponding edge weights for the resultant network can be found. For example, for
. At this point, the corresponding edge weights for the resultant network can be found. For example, for  the ordered collection vector is
the ordered collection vector is . Hence,
. Hence,

Proceeding in this way, we can calculate all of the edge weights for the resultant network. For comparison purposes, we find these values for both  and
and .
.
For each value of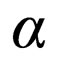 , we derive a separate network. In each of these cases, edge weight will be an aggregate of corresponding edge weights from the single-relational networks, and thus the resultant network will be multirelational. A previous study demonstrated a method for building a multi-relational network when multiple single-relational networks are given [10]. We used the same network data from [10] in this study to compare the results. Table 2 compares the results of this study to those of [10] (the rightmost column).
, we derive a separate network. In each of these cases, edge weight will be an aggregate of corresponding edge weights from the single-relational networks, and thus the resultant network will be multirelational. A previous study demonstrated a method for building a multi-relational network when multiple single-relational networks are given [10]. We used the same network data from [10] in this study to compare the results. Table 2 compares the results of this study to those of [10] (the rightmost column).

Table 2. Resultant network edge weights.
An interesting observation is that formula (1) guarantees that we will never lose information about the existence of a relationship. For both methods, the resultant weight value of an edge equals zero if there is no relationship between the edge nodes in all of the sources. The resultant weight value,  from the table is closer to
from the table is closer to  when
when  compared to the other cases.
compared to the other cases.
There is no point in computing weight values for the resultant network for  and
and . In the first case, the weight values of the resultant network will match the values of the network in Figure 3. In the second case
. In the first case, the weight values of the resultant network will match the values of the network in Figure 3. In the second case  will coincide with Figure 1. When
will coincide with Figure 1. When , each value of the single-relational network is equal, i.e.
, each value of the single-relational network is equal, i.e. . In this case, the weight values of the original networks do not necessarily matter because each of the weights will be multiplied by the same coefficient.
. In this case, the weight values of the original networks do not necessarily matter because each of the weights will be multiplied by the same coefficient.
In other cases, a comparative analysis needs to be conducted. In these cases, it is normal for an edge weight of the resultant network to be less than that of any of the original networks. This occurs because, for different cases of orness, we assign more or less rank ( ) to a data source. It is the value of orness that determines the importance of each data source. By manipulating the value of orness, different versions of the resultant multi-relational network are obtained. Each of them, to some degree, will be what the decision-maker expects. Choice of orness depends entirely on the decision-maker. From Table 2 it can be seen that, although single-relational networks are the same in both methods, the resultant multirelational network edge weights may be different. There is no direct relationship between the methods. The only relationship is the objective: to merge multiple networks into a single one.
) to a data source. It is the value of orness that determines the importance of each data source. By manipulating the value of orness, different versions of the resultant multi-relational network are obtained. Each of them, to some degree, will be what the decision-maker expects. Choice of orness depends entirely on the decision-maker. From Table 2 it can be seen that, although single-relational networks are the same in both methods, the resultant multirelational network edge weights may be different. There is no direct relationship between the methods. The only relationship is the objective: to merge multiple networks into a single one.
5. Conclusion
The relationship strength for a given set of entities can be extracted from various sources on the Web. Due to the large volume of information available, data received will rarely be the same. To evaluate these data, there needs to be a way to rank these sources. Omitting information from any of the sources may lead to incorrect results when computing overall relationship strength between entities. In this study, we have provided a new way to aggregate edge weights received from multiple networks; these networks, in turn, are built from different sources. Using the concept of OWA operators, we have demonstrated how aggregation can be achieved for social networks. In addition, we compared our results to an alternative method. Currently, we do not possess software that would allow us to calculate weight values for networks with a large number of nodes. Thus, we are unable to apply the above formulas to huge networks. In the future, we hope to use real data in these formulas to demonstrate real-world applications.
REFERENCES
- H. Kautz, B. Selman and M. Shah, “The Hidden Web,” AI Magazine, Vol. 18, No. 2, 1997, pp. 27-36.
- Y. Matsuo, J. Mori and M. Hamasaki, “Polyphonet: An Advanced Social Network Extraction System from the Web,” Proceedings of the 15th International Conference on World Wide Web, Edinburgh, 22-26 May 2006, pp. 397-406. doi:10.1145/1135777.1135837
- R. Rome, G. Creamer, S. Hershkop and S. Stolfo, “Automated Social Hierarchy Detection through Email Network Analysis,” Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 Workshop on Web Mining and Social Network Analysis, California, 12-15 August, 2007, pp. 109-117.
- A. Culotta, R. Bekkerman and A. McCallum, “Extracting Social Networks and Contact Information from Email and the Web,” Proceedings on the 1st Conference on Email and Anti-Spam, California, 30-31 July, 2004.
- Q. Li and Y. B. Wu, “People Search: Searching People Sharing Similar Interests from the Web,” Journal of the American Society for Information Science and Technology, Vol. 59, No. 1, 2008, pp. 111-125. doi:10.1002/asi.20736
- T. Finin, L. Ding and L. Zou, “Social Networking on the Semantic Web,” The Learning Organization, Vol. 12, No. 5, 2005, pp. 418-435. doi:10.1108/09696470510611384
- J. Goldbeck and M. Rothstein, “Linking Social Networks on the Web with FOAF,” Proceedings of the 23rd National Conference on Artificial Intelligence, Chicago, July 13-17, 2008, pp. 1138-1143.
- B. Aleman-Meza, M. Nagarajan, C. Ramakrishnan, et al., “Semantic Analytics on Social Networks: Experiences in Addressing the Problem of Conflict of Interest Detection,” Proceedings of the 15th International World Wide Web Conference, Edinburgh, 22-26 May 2006, pp. 407- 416. doi:10.1145/1135777.1135838
- J. Tang, D. Zang and L. Yao, “Social Network Extraction of Academic Researchers,” Proceedings of the 7th IEEE International Conference on Data Mining, Omaha, 28-31 October 2007, pp. 292-301.
- R. Alguliev, R. Aliguliyev and F. Ganjaliyev, “Extracting a Heterogeneous Social Network of Academic Researchers on the Web Based on Information Retrieved from Multiple Sources,” American Journal of Operations Research, Vol. 1, No. 2, 2011; pp. 33-38. doi:10.4236/ajor.2011.12005
- B. Poliqean, H. Tanev and M. Atkinson, “Extracting and Learning Social Networks out of Multilingual News,” Proceedings of the Social Networks and Application Tools Workshop (SocNet-08), Skalica, 19-21 September 2008, pp. 13-16.
- P. Nasirifard, V. Peristeras, C. Hayes and S. Decker, “Extracting and Utilizing Social Networks from Log Files of Shared Workspaces,” 10th IFIP Working Conference on Virtual Enterprises, Thessaloniki, 7-9 October 2009, pp. 643-650.
- G. Geleijnse and J. Korst, “Creating a Dead Poets Society: Extracting a Social Network of Historical Persons from the Web,” Proceedings of the 6th International and 2nd Asian Conference on Asian Semantic Web Conference, Busan, 11-15 November 2007, pp. 155-168.
- T. Nishimura and Y. Matsuo, “A Method of Social Network Extraction via Internet and Networked Sensing,” Proceedings of the 3rd International Conference on Networked Sensing Systems, Chicago, 31 May-2 June 2006, pp. 123-127.
- R. Xiang, J. Neville and M. Rogati, “Modeling Relationship Strength in Online Social Networks,” Proceedings of the 19th International World Wide Web Conference, New York, 26-30 April 2010, pp. 981-990. doi:10.1145/1772690.1772790
- F. Ganjaliyev, “Building a Heterogeneous Social Network of Academic Researchers,” Proceedings of the 3rd International Conference of Problems of Cybernetics and Informatics, Baku, 6-8 September 2010, pp. 179-182.
- R. R. Yager, “On Ordered Weighted Averaging Aggregation Operators in Multicriteria Decision Making,” IEEE Transactions on Systems, Man and Cybernetics, Vol. 18, No. 1, 1988, pp. 183-190. doi:10.1109/21.87068
- R. Fuller and P. Majlende, “An Analytic Approach for Obtaining Maximal Entropy OWA Operator Weights,” Fuzzy Sets and Systems, Vol. 124, No. 1, 2001, pp. 53-57. doi:10.1016/S0165-0114(01)00007-0
NOTES
*Corresponding author.