Short Term Electric Load Prediction by Incorporation of Kernel into Features Extraction Regression Technique ()
1. Introduction
Short term electric load prediction is used to forecast future load ranging from few hours to few days. In order to get an efficient smart grid, load forecasting is an essential condition for the operation of power system, and the key for whole power distribution system. The applications of short electric load prediction are to maintain the load quantity for generation scheduling, and storage resources regarding to economic purposes, so accurate load forecasting is very important for proper operation of all phases on power system. Inaccurate load forecasting leads to dysfunction of power system as a big economic headache. Underestimation of forecasting breeds load scheduling problems to end users. Over-estima- tion constructs unnecessary generation units which lead to increase operation costs. The central part of developing an accurate load forecasting model is to deeply understand the attribute of load that’s supposed to be modeled. This sensibility of load behavior is obtained along with statistical analysis of past load data.
Load can be classified into standard or daily load, residual load, and climate dependent load which relies on temperature, humidity, wind speed, and illumination [1] . Several approaches have been proposed for short term prediction to deal with the increment of the load demanding. Some models used exogenous variables as mentioned to forecast the load, whereas others only used historical data. Models in this paper used historical data in addition to weekends plus holidays as common predictor features for all models. According to climate change temperature is used too for only one datum as a comparative study to show its effect.
In earlier times, statistical methods such as linear regression [2] , and time series models [3] were expansively applied, but were not fit models perfectly as required. Artificial intelligence techniques such as Artificial Neural Network (ANN) [4] [5] have been applied to handle such drawback. Recently Support Vector Machine (SVM) and kernel methods [4] [6] [7] are drawing attention with remarkable results. In advance, several hybrid prediction models have been combined to take advantages of each technique. Hence, two different features’ extractions techniques have been used in this paper. The first technique was Kernel Partial Least Square Regression (KPLSR) introduced by [8] . To compare with the second technique: Kernel Principal Component Regression (KPCR) which is proposed by [9] , both techniques are to extract the most powerful features that are more effective than the original features because of their ability to handle the covariance between predictor features. KPLSR offers additional qualities which are exploring the covariance between predictor features and response vector (works on both sides’ predictors and response). In fact this quality is the most valuable feature when evolving a prediction model. The second quality is its ability to regress multiple response vectors as required. On the other hand, Principal Component Analysis (PCA) [10] and Kernel Principal Component Analysis (KPCA) [7] features extractions (scores) are trained and regressed by Support Vector machine Regression (SVR) tools for comparative purposes.
The main goal of this paper is to achieve a reasonable model for electric load prediction, which is proposed by Gaussian Kernel Partial Least Square Regression (GKPLSR) to compare with Polynomial Kernel Partial Least Square Regression (PKPLSR), Polynomial Kernel Principal Component Regression (PKPCR), Gaussian Kernel Principal Component Regression (GKPCR), Principal Component Analysis Polynomial Support Vector Regression, (PCA-PSVR), Principal Component Analysis Gaussian Support Vector Regression, (PCA-QSVR), Polynomial Kernel Principal Component Analysis Support Vector Regression (PKPCA-SVR), and Gaussian Kernel Principal Component Analysis Support Vector Regression (GKPCA-SVR).
2. Models Demonstration
2.1. Kernel Transfiguring
In order to clarify the proposed models; supposed to start from mapping the original features to high dimension features space by applying Gaussian kernel (κG) and polynomial kernel (κPOLY) respectively. Let assume there is a data set 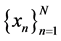 of observations, where
of observations, where 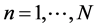 Samples of p dimensions feature space. Gaussian kernel formula written as:
Samples of p dimensions feature space. Gaussian kernel formula written as:
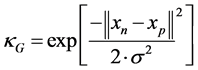 (1)
(1)
And polynomial kernel
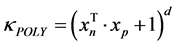 (2)
(2)
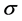 : The width of Gaussian kernel;
: The width of Gaussian kernel;
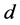 : Degree of polynomial.
: Degree of polynomial.
2.2. Support Vector Regression (SVR)
The basic idea of SVR is to ignore the residual values those are smaller than a determined threshold ε > 0, Therefore the band around the target vector drawn as a tube. SVR formula demonstrated as [6] [7] [11] :
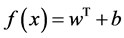 (3)
(3)
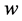 : Weigh vector;
: Weigh vector;
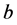 : Bias term.
: Bias term.
Introducing the optimization problem to solve 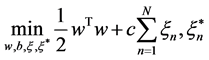
 (4)
(4)
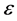 : Maximum value of tolerable residual;
: Maximum value of tolerable residual;
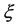 ,
,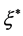 : Distance between the target values and
: Distance between the target values and 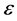 -tube;
-tube;
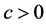 : Regularization constrains.
: Regularization constrains.
2.3. Kernel principal Component Regression (KPCR)
The idea of KPCR came from merging Kernel principal component analysis (KPCA) and PCR (principal component regression) which are method for extracting features (scores and loadings component), both are used to decrease multiple dimensions input vectors to fewer uncorrelated vectors as required. Because of PCR has a linear attribute, since the most real problems are nonlinear, the PCR has difficulties on its application. Hence KPCR developed to overcome such drawback by applying KPCA first through projecting the predictors into a high-dimensional features space. KPCR formula [12] [13] given as:
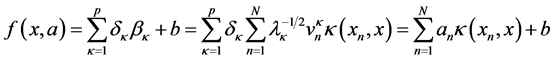 (5)
(5)
where  represents the predictor variables of N observations P dimensions, the term
represents the predictor variables of N observations P dimensions, the term ![]() is a kernel function which points to the data that have been transformed to high dimension features space by applying the above kernels Equation (1) & Equation (2). Eigenvalues and eigenvectors are respectively denoted by:
is a kernel function which points to the data that have been transformed to high dimension features space by applying the above kernels Equation (1) & Equation (2). Eigenvalues and eigenvectors are respectively denoted by:![]() ,
,![]() ;
; ![]() is the projection of transformed data
is the projection of transformed data ![]() onto
onto ![]() nonlinear principal components;
nonlinear principal components; ![]() projection of all predictors onto principal components;
projection of all predictors onto principal components; ![]() is the bias term and the variable
is the bias term and the variable ![]() is drawn by:
is drawn by:
![]()
2.4. Kernel Partial Least Square Regression (KPLSR)
KPLSR is similar to KPCR, while KPCR draws components to constructs new predictor variables without taking the response vector into account, in contrast KPLSR does take the response vector in its consideration and determines the covariance between the predictors and response, KPLSR start first from kernelling the predictors ![]() (where each
(where each![]() ) to high dimension nonlinear feature space;
) to high dimension nonlinear feature space;![]() , second is to center those transformed features
, second is to center those transformed features ![]() and response
and response ![]() (where
(where![]() ) by subtracting off column means to create uncorrelated latent variables (scores & loadings to obtain a sensible weight. The object now is to solve the regression problem in the span of the observations
) by subtracting off column means to create uncorrelated latent variables (scores & loadings to obtain a sensible weight. The object now is to solve the regression problem in the span of the observations![]() and
and ![]() dimensions feature space.
dimensions feature space.
There are two famous algorithms for implementing KPLSR; NIPALS which is improved by [8] [14] [15] [16] to fit the nonlinear problems, and SIMPLS which is modified version of NIPALS proposed in [17] ; applied by [18] . In order to get direct computation of the scores and loadings coefficients, and avoiding the deflation steps of each iteration of NIPALS algorithm [14] ; SIMPLS algorithm is chosen to carry out this work.
The cross product matrix drawn as: ![]()
![]()
The computation of singular value decomposition (SVD) is lead to get weight vectors![]() , by computing the scores
, by computing the scores ![]()
![]() (6)
(6)
Can obtain loadings ![]() by:
by:
![]() (7)
(7)
Storing![]() ,
, ![]() and
and ![]() into R, Γ, P respectively, regression Coefficient
into R, Γ, P respectively, regression Coefficient ![]() can compute as:
can compute as:
![]() (8)
(8)
The response ![]() for new data after kernelling process
for new data after kernelling process ![]() is obtained by:
is obtained by:
![]() (9)
(9)
For more clarification of SIMPLS algorithm:
Inputs: ![]() L = 1 which is load target vector here
L = 1 which is load target vector here
![]() Centering
Centering ![]()
![]() Centering
Centering ![]()
![]()
![]()
![]() factor weights
factor weights
![]()
![]() factor weights
factor weights
![]()
![]() score vectors
score vectors
![]() Computing the norm
Computing the norm
![]() Normalizing the score vectors
Normalizing the score vectors
![]()
![]() loading components
loading components
![]()
![]() loading components
loading components
![]()
![]() score vectors
score vectors
![]() Initializing orthogonal loadings
Initializing orthogonal loadings
![]()
![]() Making
Making ![]() previous loadings
previous loadings
![]() Making
Making ![]() previous
previous ![]() values
values
end
![]() Normalizing orthogonal loadings
Normalizing orthogonal loadings
![]() Deflating cov with respect to current loadings
Deflating cov with respect to current loadings
Storing![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() into R, Γ, P, Q, U respectively
into R, Γ, P, Q, U respectively
End
3. Experiments and Evaluation
Eight models have been implemented to predict the hourly and half hourly electric load in different three cities which create four cases and evaluated by three statistic measurements. The load prediction is carried out by the following eight models:
PKPCR & GKPCR: Kernel principal component regression (KPCR) extracted the high dimensional features; those are created by polynomial, Gaussian kernels respectively and applied the uncorrelated extracted features on their regression tool.
PCA-PSVR& PCA-GSVR: New variance features are extracted by Principal component Analysis (PCA) and integrated into Support vector Regression (SVR) tool for training purposes by polynomial and Gaussian kernels respectively to forecast the electric load.
PKPCA-SVR& GKPCA-SVR: SVM regression entered to enhance the training and regressing process for those extracted features by polynomial and Gaussian kernels principal component analysis respectively; which means the regression process carried out by linear support vector regression tools.
PKPLSR: Kernel partial least square regression (KPLSR) used its technique to extract the most variance features those are drawn by polynomial kernel, while jointly maintaining the covariance between predictors and predictive response for obtaining a sensible weight to predict the require load.
GKPLSR: Applied same techniques as PKPLSR, the difference that is GKPLSR has proposed Gaussian kernel rather than polynomial kernel.
KPCR and KPLSR have two important parameters supposed to set; Gaussian kernel parameter and the number of components that should let them rich to optimization point; which is tuned by minimum mean absolute percentage error (MAPE).
Models are evaluated by three error statistic measurements: mean absolute percentage error (MAPE), root mean square error (RMSE) and normalized mean squared error (NMSE).
![]() (10)
(10)
![]() (11)
(11)
![]() (12)
(12)
![]() : No of observations
: No of observations
![]() : Actual load
: Actual load
![]() : Predicted load
: Predicted load
![]() : Determined point of data observation
: Determined point of data observation
![]() : Variance of training observations
: Variance of training observations
Case 1: EUNITE competition data set [19] selected as a first case because are the most famous data through load forecasting field, the strategy is to select the daily peak load for January, February, March, October, November and December in 1997 & 1998 as a training set, in addition to working days, weekend days, and holidays, moreover to electric load for previous seven days to forecast the daily maximum load of January 1999 which presented the testing set. The data compose from 367 samples and 16 attributes, which are considered as small data comparatively. Results are shown in Table 1. Notice that obtaining a best MAPE value does not always mean better performance has been obtained because definitely should consider the time factor as one of the important things supposed to respect it when selecting an identified method. In this case GKPCR has a better MAPE value but with 41 components; authors here would like to reflect that GKPCR can be a reasonable method for load prediction but with only small data because it is always need much component to obtain a better result which lead to consume much time, while GKPLSR can obtain a reasonable prediction result with less component less time and better performance in total. Figure 1 illustrated clearly the absolute error of each load has been predicted by all models; PKPCR, GKPCR and GKPLSR lie almost in a same median absolute error, PCA-PSVR and PCA-GSVR have bigger median and absolute error values, PKPCA-SVR, GKPCA-SVR were reasonable models, while PKPLSR has the smaller median. Although GKPCR lied in best quartile range but it’s powerless in time factor. Therefore GKPLSR has the best performance despite its MAPE value slightly higher than GKPCR. Figure 2 displayed MAPE values of each day of January 1999 of all models.
Case 2: For this case, EUNITE data are reused with a different way, once half hourly load data are available, hence, authors used the daily half hourly load of January, February, and December in 1997 & 1998 plus the days from first to
![]()
Table 1. Evaluation performance of case 1.
twenty fourth of January 1999 as training set which considered the same half an hour for previous seven days as data attributes, in addition to working days, weekend days and holidays to predict half hourly load for last week of January 1999. Results are tabled in Table 2 illustrated that’s GKPLSR is significantly improved the prediction than other models. It is clear that the good prediction result and fastness are most important factors to create a reasonable model, so is found that GKPLSR has a best performance among all other models. In addition the fastness to reach the optimization point. Figure 3 showed models median, minimum, maximum and quartile range and GKPLSR was better than other models. Figure 4 is a comparative art between GKPLSR & GKPCR to reflect the
![]()
Table 2. Evaluation performance of case 2.
![]()
Figure 4. Components Comparative via MAPE in case 2.
consuming of component number via absolute percentage error (MAPE), while GKPCR got a lesser MAPE by consuming 19 components QKPLSR achieved a lesser MAPE only by consuming 10 components. Figure 5 drew the half hourly actual test load behavior of each day and how far QKPLSR predicted the half hourly load for each day separately, in addition to calculate the average MAPE for each half an hour for predicted week, hence can notice that the MAPE is higher only in un stable actual load behavior.
Case 3: ISO England data [20] applied in this case; the training set was from first of June 2007 to fourteenth of May 2008 to predict the days from fifteenth to twenty ones of May 2005. The attributes for this case are constructed from hourly load of the same hour in previous eight days, with working days, weekend days and holidays. For this case authors wanted to see how far the weather can effect positively or negatively through load forecasting, therefore this case composed from two cases, the first one is carried out by ignoring the dry bulb and dew point, whereas the second has taken the dry bulb and dew point into
![]()
Figure 5. Daily half hourly of actual, predicted load and average MAPE respectively in case 2.
consideration. The results are shown that QKPLSR has a best prediction compare to other presented models which are written in Table 3. Figure 6 has compared the goodness of each model; unfortunately PKPCR & QKPCR are clearly excluded from building reasonable forecasting, although are successfully performed when added into art of SVR (PCA-PSVR, PCA-QSVR, PKPCA-SVR and GKPCA-SVR), on the other hand PKPLSR was acceptable, whereas QKPLSR obtained the best performance with the minimum, maximum, median and quartile range absolute error. Figure 7 clarified the hourly actual test load behavior of each day, QKPLSR predicted hourly load for each day separately, in addition to calculate the average MAPE for each an hour for predicted week with taking weather factors into account and the average MAPE for each an hour for predicted week without taking the weather factors into consideration, hence can notice that the figure has captured clearly the noisy of data either in load which changed suddenly on Friday & Saturday or in the dry bulb and dew point from two to five o’clock that lead to get a higher average MAPE (2.1) compare to (1.99) without using the dry bulb and dew point by applying QKPLSR.
Case 4: Victoria Island data set [21] utilized for this case which are collected from Australian Energy Market Operator (AEMO), the training set is gathered from the first of April 2015 to twenty third of September 2015, and the testing set was the rest of September which is last week. Half hourly load for previous eight days is used as historical load attribute, in addition to working days, weekend days and holidays. Table 4 presented the results for all of models which clarify that QKPLSR has a better achievement. Figure 8 illustrated that QKPLSR
![]()
Table 3. Evaluation performance of case 3.
![]()
Figure 6. Daily half hourly of actual, predicted load and average MAPE respectively in case 3.
![]()
Table 4. Evaluation performance of case 4.
has an acceptable minimum, maximum, median and quartile range absolute error followed by PCA-GSVR, PCA-PSVR, PKPSR, GKPCA-SVR, PKPCA-SVR, while pure PKPCR and QKPCR got unacceptable absolute error. Figure 9 visualized the half hourly actual load behavior, predicted load separately of each day
![]()
Figure 9. Daily half hourly of actual, predicted load and average MAPE respectively in case 4.
and average MAPE of QKPLSR which captured unstable noisy load on Friday, Monday and Tuesday which is lead to slight increasing of MAPE value.
4. Conclusion
In this paper, two kernels: polynomial and Gaussian kernel are incorporated into extraction features regression techniques―principal component regression & partial least square regression to get an accurate target for short term electric load prediction. In order to increase the degree of comparison, authors have provided those extracted features from principal component analysis and Gaussian kernel principal component analysis to integrate it into art of support vector regression. Three data sets have been implemented to measure the effectiveness of applied models; EUNITE competition data sets are supplied by Eastern Slovakian Electricity Corporation; ISO New England data sets are used by two cases; the first one is by ignoring the weather factors that have obtained better load prediction than taking the weather factors into account because some noisy data are included. Hence cleaning data technique is required to handle such cases, noticing that according to recently global climate change, weather factors are not so efficient to predict the electric load. Moreover, Victoria Island data sets which are collected from Australian Energy Market Operator (AEMO) have implemented in the last case. Among all of the applied models & implemented cases, results proved that Gaussian kernel partial least square regression has achieved the best load prediction. In order to obtain more improvement, cleaning & filtering data technique is proposed for future studies. In fact this model can be matching to predict various targets, and hence can add the electric pricing as a second required target.