1. Introduction
Evidence has been accumulating from long-term and short-term studies linking ambient air pollution to health outcomes. Fine particulate matter has demonstrated fairly consistent links to cardiovascular and respiratory health [1] - [9] . As a consequence, effort continues to be made to improve large-scale estimation of air pollutants for intra-urban environments and sparsely monitored areas using different methods. Generalized additive models (GAM), which capture spatiotemporal trends, have been used to predict monthly PM10, PM2.5, and coarse fraction PM, across the north-eastern US [10] - [12] , and nationally [13] . Using Bayesian maximum entropy (BME) one study estimated average PM2.5 for the year 2003 [14] , and another study used BME in a hybrid approach to estimate national monthly PM2.5 [15] . A geographically weighted regression was used to estimate PM2.5 in the southeastern US for the year 2003 [16] . In western Europe, land-use regression (LUR) models were developed to predict PM10 and NO2 that included satellite data for the years 2005-2007 [17] .
Our goal in this study was to evaluate how spatial GAMs perform and to create national monthly predictions of PM2.5 in order to evaluate the effect of aggregating on the monthly, 1-year, and 5-year time metrics for the years 2000 to 2009, to assess different exposure windows. It is also of interest to compare the effect of using a non-reference method (NRM) in contrast to the Federal Reference Method (FRM) alone [18] . Finally, nearest monitor and inverse distance weighted (IDW) methods were used to contrast suggested approaches. The results of these analyses are useful for national epidemiologic investigations of long-term exposure to air pollution that require a moving exposure window with different exposure intervals such as is the case for cardiovascular disease [7] .
2. Methods
Spatial monthly generalized additive models (GAM) were developed to predict PM2.5 for the contiguous US for the period 2000-2009. These models are a sum of smooth functions of predictor variables that allow for flexible non-linear relationships with the outcome variable [19] . In this research the outcome variable is PM2.5 monitoring data from the US Environmental Protection Agency’s (EPA) national ambient air quality monitoring network. Meteorological and GIS-derived variables were used as potential predictors. The resulting models makes it possible to predict ambient PM2.5 levels at any specified spatial resolution used to represent subject locations, such as street-level residential addresses.
2.1. PM2.5 Monitoring Data
Daily and hourly PM2.5 data were downloaded from the US EPA’s Air Quality System (AQS) online database for the period 2000-2009 [18] . Parameter code 88101 was used for the FRM. The NRM used parameter code 88502 which is comparable to FRM with less than 10% bias [20] . The NRM included the Interagency Monitoring of Protected Visual Environments (IMPROVE) network which monitors national parks and captures PM2.5 data in rural settings [21] . There were three inclusion criteria applied to the air pollution data. First, for hourly PM2.5 data, at least 75% of the hourly values during a day must be available to consider them valid for aggregation to daily amounts. Second, only months could be included where observed counts of valid daily values per month, divided by expected counts of daily values per month, were at least 75%. Last, there must be at least three valid observations in a given month for that monthly average to be included. A square root transformation was applied to the PM2.5 data and these were back transformed once predictions were made. Performance evaluation was done on back transformed data.
2.2. Potential Predictors
Candidate predictors were either GIS derived or meteorological. The following variables were GIS derived: Land use maps from the Multi-Resolution Land Characteristics Consortium allowed calculations of the proportion of imperviousness (2006 data) and tree canopy (2001 data) within 1 km, 2 km, 4 km, and 8 km buffers [22] . The proportion of land use (2006 data) was also calculated for high, medium, and low intensities, and cultivated crops within 1 km, 2 km, and 4 km buffers. US census databases for the year 2000 were used to determine block group population density within 1 km, 2 km, 4 km, and 8 km buffers (Environmental Sciences Research Institute-(ESRI), Redlands, CA). Elevation was extracted from the US Geological Survey (USGS) National Elevation Dataset [23] . US EPA National Emissions Inventory was used for point- source emissions of PM2.5 within 1 km, 2 km, 4 km, 8 km, and 12 km buffers (2005 data) [24] . Distance to nearest road by 4 road classes was measured using ESRI’s Street Map database (2011 data). Indicator variables were created for the South Coast and San Joaquin Valley air basins in California because of the unique characteristics of the regions and the high number of extreme values [25] . All of the above GIS determined variables were created in Arc Map 10.0 (ESRI), and except for elevation, all of the continuous GIS variables were log transformed.
National meteorological data including average temperature, maximum temperature, dew point temperature, relative humidity, barometric pressure, air stagnation, and wind speed, were downloaded from the National Climate Data Center for the study time period [26] .
2.3. Subgroups
Six US regions were defined in this research to evaluate model performance in geog- raphic subgroups (see Figure 1). They were the northwest (NW = OR, WA, ID), south- west (SW = CA, NV, UT, AZ), north central (NC = MT, WY, ND, SD,NE, MN, IA), south central (SC = CO, NW, KS, OK, TX, MO, AR, LA), northeast (NE = WI, MI, IL, IN, OH, KY, WV,VA, PA, NY, VT, NH, ME, MA, CT, RI, MD, DE, NJ, and DC), and southeast (SE = TN, MS, AL, NC, SC, GA, and FL).
2.4. Generalized Additive Models
Separate spatial only models were created for each of the 120 months during the 10
![]()
Figure 1. PM2.5 monitoring locations and the six regions of the US defined in this study.
year study period (1/2000 to 12/2009). The model was defined as:
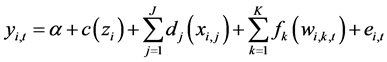 (1)
(1)
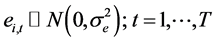
where yi,t is the square-root transformation of PM2.5 for monitoring site i and month t. The function c () is a bivariate thin plate regression spline for the spatial coordinates zi for each monitoring location. The functions d () and f () are a single cubic regression spline for j = 1 … J time invariant predictors xj, and for k = 1 … K time varying predictors wk, respectively. GAM procedures used the gam () function from the mgcv package from R [19] . When modeling GAMs, the maximum degree of flexibility of the spline functions can be set by the user by choosing the basis dimension. For the spatial coordinates function the basis dimension was set at 300, and for time invariant and time varying predictors the basis dimension was set at 10. These models were compared to the traditional methods IDW and the nearest monitor approach.
2.5. Model Building
The data were divided into 10 random sets. Cross-validation was used to select covariates and assess model predictive ability within data sets 1 - 9 by taking each out in turn and predicting to the held out set. The computed squared correlation (regression based R2) between the observed and predicted values helped determined covariate and model choice along with root-mean-squared prediction error (RMSPE). Because selecting variables by cross-validation could bias the performance of the cross-validated statistics, the 10th set was not used for variable selection, but was held out until after the final model was selected to evaluate evidence of over-fitting of this final model [10] [11] . Performance was further evaluated by: 1) the average mean prediction error (MPE), 2) the regression slope where observed is the dependent variable and the predicted value is the independent variable, and 3) by a mean squared error based R2 (MSE-R2) which is a measure of fit to the 1-1 line, defined as MSE-R2 = 1-RMSPE2/var (obs) [27] .
The first step in model building was to force spatial coordinates of monitoring location into the model (assumed a-priori to be the most important predictor of PM2.5). The second step added additional covariates that gave the highest cross-validated R2 and lowest RMSPE in datasets 1 - 9. In the last step covariates were retained only if they improved the R2 by approximately 1% or more [28] . Cross-validated performance stati- stics were reported on a monthly basis (calculating statistics for each month and then averaging statistics across 120 months), a 1 year aggregation (averaging statistics across 10 years), a 5 year aggregation (averaging statistics across 2 time periods: 2000-2004, 2005-2009), and no aggregation (e.g. reporting a single R2 for datasets 1 - 9). Once a final model was selected then performance statistics from datasets 1 - 9 were compared to the holdout dataset 10 to see if there was any evidence of over fitting.
3. Results
3.1. Descriptive Statistics
During the study period all of the monitors (including non-reference) located on the east coast had on average the highest levels of PM2.5 (NE = 12.7 and SE = 12.4 µg/m3) and the northwest had the lowest (7.4 µg/m3) as seen in Table 1. The highest peak was in the north central region (88.0 µg/m3). It is however more instructive to look at the
![]()
Table 1. Descriptive statistics of mean monthly PM2.5 (μg/m3) by region and season for combined monitors and federal reference method only.
aFederal reference method only; bOR, WA, & ID; cCA, NV, UT, & AZ; dMT, WY, ND, SD, NE, MN, & IA; eCO, NM, KS, OK, TX, MO, AR, & LA; fWI, MI, IL, IN, OH, KY, WV, VA, PA, NY, VT, NH, ME, MA, CT, RI, MD, DE, NJ, & DC; gTN, MS, AL, NC, SC, GA, & FL.
95th percentile where the north central region had the lowest value (15.0 µg/m3) and the southwest had the highest value (23.2 µg/m3). Non-reference monitors had a much lower overall mean (6.8 µg/m3) when compared to the reference method (11.8 µg/m3) (Table 2). The non-reference monitoring locations tend to be in rural areas and the largest number of these (n = 133), were found in the northwest which may help explain the lowest average levels observed for this area (Table 2).
Temporal trends for combined monitors and FRM show a steady decline in average PM2.5 and the 95th percentile over the study period (see Figure 2). Non-reference moni- tors show an increase through 2007 followed by a decline. Seasonally, it appears that PM2.5 has highs in the summer months and in the winter months, with July and August having the highest peaks followed by January. April has the lowest valley with a dramatic drop for the 95th percentile (see Figure 3). The number of active monitors was not very different for the different seasons (Table 1).
3.2. Prediction
The final model contained only variables that improved the cross-validation R2 among data sets 1 - 9 by approximately 1% or more. The retained variables were monitoring spatial coordinates and two GIS predictors; population block group density at a 4-km buffer and elevation.
When reporting overall performance results, we chose to report performance statistics four ways to reflect different time aggregations. For the spatial GAMs, that included all monitors, performance was strong with an R2 = 0.80, 0.76, 0.81 and 0.82 for categories None, Month, 1-Year, and 5-Year time aggregations, respectively (Table 3). The first
![]()
Table 2. Descriptive statistics of mean monthly NRMa PM2.5 (μg/m3) by region and season.
aNon-federal reference method; bOR, WA, & ID; cCA, NV, UT, & AZ; dMT, WY, ND, SD, NE, MN, & IA; eCO, NM, KS, OK, TX, MO, AR, & LA; fWI, MI, IL, IN, OH, KY, WV, VA, PA, NY, VT, NH, ME, MA, CT, RI, MD, DE, NJ, & DC; gTN, MS, AL, NC, SC, GA, & FL.
![]()
Figure 2. Average and upper 95th percentile Yearly trends for PM2.5 including all monitors, federal reference method (FRM), non-reference method (NRM), and regression lines, for monitoring locations during the period 2000 to 2009.
![]()
Figure 3. Average and upper 95th percentile Monthly seasonal trends for PM2.5 including all monitors, federal reference method (FRM), and non-reference method (NRM), for monitoring locations during the period 2000 to 2009.
category None (for no aggregation) is a single R2 for all the data of observed and predicted values during the 10 year period (see Table 3). Although a convenient number to report, this number does not accurately represent the way the data are used in health effects models, hence the presentation of other time aggregations. The MSE-R2s were very close to the regression based R2s showing little bias, i.e. deviation from the 1-1 line. The regression slopes similarly were close to 1.0 also indicating little bias from the 1-1 line. The GAMs were significantly better than the IDW methods by 7% - 10% in absolute differences and even more so than the nearest monitors. The nearest monitors showed a distinctive drop in MSE-R2s when compared to regression based R2s and a deviation of the slopes from 1.0. RMSPE decreased when the time aggregation was increased and had the smallest values for the GAM method. FRM monitors alone had a 2% - 5% absolute drop in R2s values compared to all monitors.
For Table 4, results are shown for the 10th hold out set. When compared to Table 3, there is little evidence that there was over-fitting due to model selection in datasets 1 - 9.
When graphically comparing observed versus predicted values for all monitors in datasets 1 - 9, the model is a good fit except for a small number of extreme observations that under predicted (see Figure 4). Eight observations had observed values over 55 μg/m3 which should be considered exceptional events (e.g. fires) since each one of these moni-
![]()
Table 3. Cross-validated statistics on datasets 1 - 9 predicting PM2.5 (μg/m3) for NMa, IDWb, and spatial GAMc, by four aggregations of time from 2000-2009.
aNearest monitor; binverse distance weighting; cgeneralized additive model; dregression based R2; emean squared error based R2; fmean prediction error; groot mean squared prediction error; hfederal reference method only.
![]()
Figure 4. Observed PM2.5 vs. predicted PM2.5 for data sets 1 - 9.
![]()
Table 4. Evaluating model over-fit on dataset 10 for spatial GAMc, by three aggregations of time from 2000-2009.
cgeneralized additive model; dregression based R2; emean squared error based R2; fmean prediction error; groot mean squared prediction error; hfederal reference method only.
tors did not have similar values (over 55 μg/m3) at other times during the study period.
In Figure 5, a map of the US is shown of surface predictions for PM2.5 for the year 2005. The impact of population density is readily seen with the increases in PM2.5 in the population centers of the US. The effect of elevation is also easily seen in the mount- ainous regions of the nation.
3.3. Subgroup Analysis
The northwest had much poorer model performance judged by a monthly R2 = 0.37 and a 1 year R2 = 0.46 (Table 5). The regression slopes were also lower than 1.0. Furthermore, without use of the non-reference monitors, the performance was noticeably worse with an R2 = 0.23 and 0.29, MSE-R2 = 0.06 and 0.02, and a regression slope of 0.59 and 0.69 for monthly and 1-year aggregations, respectively. It is interesting to note that the north central region had a similar number of monitors compared with the northwest over a larger geographic area and yet it performed well like the other regions.
![]()
Figure 5. Surface predictions of PM2.5 (µg/m3) across the contiguous US for the year 2005.
![]()
Table 5. Cross-validated performance measures of GAMa for predicting two sets of PM2.5 monitors, by three aggregations of time and by regions, on datasets 1 - 9 during 2000-2009.
ageneralized additive model; ball monitors; cfederal reference method only; dregression based R2; emean squared error based R2; fmean prediction error; groot mean squared prediction error; hOR, WA, & ID; iCA, NV, UT, & AZ; jMT, WY, ND, SD, NE, MN, & IA; kCO, NM, KS, OK, TX, MO, AR, & LA; lWI, MI, IL, IN, OH, KY, WV, VA, PA, NY, VT, NH, ME, MA, CT, RI, MD, DE, NJ, & DC; mTN, MS, AL, NC, SC, GA, & FL.
However there was a drop in the 5-year aggregation R2 (0.66), probably related to the effect of aggregation on a reduced sample size and range. For a 1-year aggregation the southeastern part of the US had the best model performance (R2 = 0.81; RMSPE = 1.00). Consistently, December through February had the lowest R2 and the largest RMSPE, and June through August had the highest R2 and the lowest RMSPE (Table 6).
4. Discussion
We created spatial GAMs that are simple and effective in modeling PM2.5 across large areas like the US with R2 = 0.80, 0.76, 0.81 and 0.82 for categories None, Month, 1 Year, and 5 Year time aggregations, respectively. There have been a few attempts at modeling PM2.5 over the contiguous US. Beckerman et al. used a hybrid approach to model national monthly PM2.5 estimates using Federal Reference Method only with an R2 = 0.79. They created a spatiotemporal model by combining LUR models as a first stage and Bayesian maximum entropy interpolation of the LUR residuals as a second stage [15] . Our analysis including only the federal reference method monitors with no time aggregation had a similar value (R2 = 0.78, No aggregation). Another analysis, using the Bayesian maximum entropy framework with a moving window, estimated PM2.5 across the US for the year 2003 with a Pearson’s correlation of 0.90 (R2 = 0.81) [14] . Using combined monitors our analysis had an R2 = 0.81 for a comparable 1-year aggregation. Considering only FRM monitors, the R2 dropped to 0.78. It was not clear from the description which set of monitors was used in the previously mentioned moving window approach. A study using spatiotemporal GAMs for the northeastern US had an R2 =
![]()
Table 6. Cross-validated performance measures of GAMa for predicting two sets of PM2.5 monitors, by three aggregations of time and by seasons, on datasets 1 - 9 during 2000-2009.
ageneralized additive model; ball monitors; cfederal reference method only; dregression based R2; emean squared error based R2; fmean prediction error; groot mean squared prediction error.
0.77 for monthly estimations during a three-year period [12] and when extended to the contiguous US and for a longer time period (through 2007) had the same R2 value while including non-reference methods as well [13] .
The current research compares well to previous research by others. Although covering the contiguous US like the previously mentioned papers, there are some unique characteristics of this analysis. First, we showed the effects of time aggregation and the amount of improvement that is gained by longer time aggregations. This is useful when considering different time windows for long-term exposure for health effects like cardiovascular disease [7] . Second, we attempted to quantify the difference between using all available monitors, versus using the Federal Reference Method only. Because of the scarcity of monitors in particular areas like the northwest, using good quality, non-refe- rence method monitors may be an appropriate approach for these areas. It is not clear what the impact is on the exposure estimates and ultimately to the health effects models by introducing methods that potentially have more measurement error. Third, an analysis by region is helpful to understand where there are regional weaknesses in model performance. Knowing the number of monitors in a region doesn’t necessarily help with this prediction. The north central region had a similar number of monitors as the northwest and even though the network covered a larger geographic area, predictions were much better. This result suggests that special attention should be given to the northwest to find ways to improve the relatively poor results. Last, while comparing well with other methodologies, spatial GAMs are relatively simple models that are easier to set up than spatiotemporal models that have two stages. These results, although not perfectly comparable to other research (somewhat overlapping time periods), would seem to suggest that almost all of the predictive performance comes from spatial considerations alone.
Three predictors were retained for the final model: spatial coordinates, population density with 4-km buffer, and elevation. It should be noted that the results were not substantially different from a 1-km buffer or imperviousness with a 4-km buffer. It is possible that using a 1-km buffer is useful when evaluating inter-urban spatial heterogeneity.
Further analysis should look for ways to improve the modeling of fine particulates in the northwest. Possibly different predictors are important for this region. It would seem that using non-reference monitors for this region is particularly important. Another possible way to improve these models is using daily predictions. Last, using spatial GAMs may be a good input for a second stage using spatiotemporal residuals for time trend effects.
5. Conclusion
There are a number of appropriate methods that can be used to predict national PM2.5. The method advocated in this paper (i.e. spatial GAM) is useful in that while it had strong model performance, similar to other recently described methods, its implementation is relatively simple. We feel that spatial GAMs have an important contribution to the discussion of and research for the modeling of PM2.5 across large-scale areas for chronic exposure.
Acknowledgements
DJS thanks Ed Santos and Ben Becerra for their assistance with creating maps.