An Analysis and Validation of Effectiveness on Demand Forecasting Considering the Planned Order Effect* ()
1. Introduction
Product differentiation is one of the business strategies of companies to increase competitiveness by emphasizing that their products are superior to their competitors. However, securing competitiveness through product differentiation or price differentiation has reached its limit. And now service level is the main issue for securing a competitive advantage in the market as technology and price competitiveness enter the leveling stage. In particular, post-sales service management is the face of a company because it occurs at the point of contact with customers. Therefore, companies are placing more weight on consumers’ loyalty to companies and products, and companies that cannot respond to this cannot survive. In fact, there are a lot of companies around the world that fail due to their excellent product competitiveness but lack of after-sales ability, and in the case of the United States and some European countries, if the after sale service are delayed by more than two days, the penalty is aggravated, which is deepening the concerns of companies.
Service parts in the manufacturing industry have various characteristics, and as many as tens of thousands of parts are required for the final product. Demand forecasting is almost impossible to meet the demand since demand for most parts is unspecified demand caused by accidents or breakdowns. However, prompt service to customers and customer expectations are continuously increasing, and the product storage period is continuously increasing due to the service warranty period. For this reason, excess inventory and shortage of inventory occur frequently, and enormous logistics expenses are wasted in order to cope with urgent demand. Therefore, it is becoming an issue of efficient service parts management in most companies because it is necessary to consider the two goals of reducing inventory cost as well as improving customer service level. Although the level of awareness of the importance of demand forecasting is increasing, few companies invest in developing their own demand forecasting models and training forecasting experts to enhance demand forecasting accuracy.
Demand forecasting has an important meaning in that it provides the basis for various decision making in the process of creating value added. First, if the company’s management policies including planned production can be properly implemented according to changes in the environment, the material supply and demand plan is regularly implemented and it is possible to respond to changes in customer demand (Riezebos & Zhu, 2014) (Farhangmehr & Brito, 1997). Second, it is possible to efficiently manage the excess inventory cost. Third, planned production is possible, so budgeting can be established well, production costs can be reduced. In addition to product related matters, product price, which is the value that a company provides to customers, has been used most frequently and widely as a means to induce consumer reaction due to its ability to change in a relatively short period of time. Manufacturing companies are implementing a PO (Planned Order) system for giving price discount to customer for the purpose of customer service and increasing sales (Kolter, 2003). In other words, it is a system that supplies service parts at low prices for a certain period of time, creates consumer purchasing power, and increases sales. The reason for implementing the PO system positively is that first, it can reduce the increase in purchase avoidance due to the economic recession, and second, it can prevent the decrease in demand due to seasonal factors and insufficient demand by new products. Recently, regardless of the external environment, the PO system is being adopted throughout the year in terms of sales strategy. As consumers perceive various reasons or motives for a price discount, consumers’ reactions also change (Lichtenstein, Burton, & O’Hara, 1989). Subsequent research has expanded the research area to see what kind of discriminatory responses consumers show when discount reasons such as bulk purchases and inventory disposal are presented in addition to price discounts (Sheng, Parker, & Nakamoto, 2007) (Bobinski, Cox, & Cox, 1996). However, although studies related to consumer response to price discounts are active, studies related to the future order quantity due to the PO system are not considered. The time series data on the order demand for parts is based on four variables, such as trend, cycle, seasonal and irregular, and has data made up of two or more combinations. Under the PO system, the quantity of orders increases in demand, causing statistically outliers intentionally. If demand forecasting is performed with data containing these outliers, the forecast is distorted and the accuracy is lowered. This is because the existing method has a drawback in that the outlier cannot reflected be properly. However, a new method that reflects the effect of PO on outliers is needed, since the inclusion of outliers due to the PO system is a strategy to create planned demand. The inventory management and the opportunity cost management would be easy since the accuracy of forecasting is guaranteed by the demand forecasting method considering the effect of the PO. As a result, it increases the availability of parts and customer service satisfaction. In this study, alternatives are suggested and analyzed by comparing the accuracy of demand forecasting by the PO effect with the accuracy of the ARIMA model. To the best of my knowledge, these kinds of model have not as yet been studied in the open literature.
The paper is organized as follows. We review related work briefly in Section 2. The demand forecasting model related to service parts is presented in Section 3. Section 4 introduces the PO effect model considering the PO effect. In Section 5, the validity and comparison of the model is examined against the model without PO. Finally, Section 6 gives concluding remarks.
2. Related Studies
Time series data analysis is a dynamic analysis method that attempts to predict the future by analyzing changes in data from the past to the present using time as an independent variable. The characteristics of time series data are divided into four components, such as trend, cycle, season, and irregularity. Letting Zt be the observed time series data at time t, Zt is generally expressed as data in multiplicative model or additive model involving the four components. If seasonality exists before implementing time series analysis, time series decomposition, winters model, and ARIMA can be used for demand forecasting. On the other hand, seasonality or trend does not exist, demand forecasting can be made with a simple exponential smoothing method or a moving average method. If there is no seasonality but a trend exists, trend analysis, double exponential smoothing, or ARIMA is used. As one of quantity indices for determining the existence seasonality and of a trend, it is possible to calculate the auto correlation coefficient, which is a correlation coefficient between the average deviations of all possible pairs of data. The estimated auto correlation coefficient means the degree of correlation between time series data, and it can be said to be a statistical relationship expressing a direction and intensity between a pair of observation.  and
and 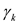 mean the observation at time t and the auto correlation coefficient between observations separated by k time lags in the time series respectively, and is expressed as follows.
mean the observation at time t and the auto correlation coefficient between observations separated by k time lags in the time series respectively, and is expressed as follows.
 (1)
(1)
In (1), k means a time differences separated by k, and is mainly used to calculate a pair of autocorrelation coefficients.
2.1. Box-Jenkins Model (Box & Jenkins, 1976)
The study on time series analysis started under the assumption that the decomposition method can decompose each of the 4 components of the time series data. However, the reality is that these 4 components can be easily decomposed by the decomposition method. Accordingly, a new approach to time series analysis was devised, and a statistical theoretic system based on ARIMA model is established by generalizing this method. The Box-Jenkins method implements three steps: Model Identification, Parameter Estimation, and Model Diagnostic Checking to find out which probabilistic properties the time series data have and which model is appropriate. Model identification is to find the most appropriate model by statistical comparison after selecting several models that are considered appropriate for the observed time series data. The principle of parsimony should be adhered to in selecting a model. This is to express the observed data as simply as possible by selecting the model with the smallest number of parameters while appropriately expressing the observed data. The parameter estimation and the fitness of good test of the model are performed through statistical procedures, and if assumptions and conditions are not satisfied, return to the model identification step and repeat the above three steps until an appropriate model is found. The assumption of stationarity in stochastic processes and an understanding of various types of autocorrelation functions help to extend the Box-Jenkins model.
Letting the time series data at an arbitrary time point t is expressed as , it can be regarded as a random variable obtained from the population. In general,
, it can be regarded as a random variable obtained from the population. In general, 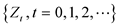 which is a set of random variables, is called a stochastic process, and is also called a time series process. In statistical estimation and testing for time series models, one of the crucial assumptions for simplifying analysis is stationarity. In a stationary time series, the mean, (
which is a set of random variables, is called a stochastic process, and is also called a time series process. In statistical estimation and testing for time series models, one of the crucial assumptions for simplifying analysis is stationarity. In a stationary time series, the mean, ( ) and variance, (
) and variance, (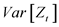 ) of time series data generated in a stochastic process are constant over time. And auto covariance and auto correlation functions are time-dependent on time lag k, not dependent on time t.
) of time series data generated in a stochastic process are constant over time. And auto covariance and auto correlation functions are time-dependent on time lag k, not dependent on time t.
Correlation functions used in the model diagnosis step include ACF (autocorrelation function), PACF (part autocorrelation function), and SACF (sample autocorrelation function). When two time points with a time difference k are t and t + k, the expected value of the product of the sample values of the stochastic process 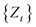 is called the autocorrelation function of
is called the autocorrelation function of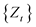 .
.
If the covariance of 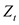 and
and 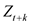 is expressed as
is expressed as .
. 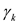 is called an auto-covariance function since
is called an auto-covariance function since 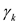 is a function of k. Therefore, ACF,
is a function of k. Therefore, ACF,  is expressed as (2), where
is expressed as (2), where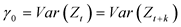 .
.
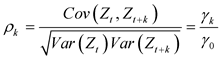 (2)
(2)
The PACF (partial autocorrelation function) is an autocorrelation function just only for 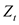 and
and![]() , and is expressed as a conditional auto-correlation function as shown in (3), after removing the mutual linear dependence of
, and is expressed as a conditional auto-correlation function as shown in (3), after removing the mutual linear dependence of![]() , the random variables of
, the random variables of ![]() from time
from time ![]() to time t +k − 1.
to time t +k − 1.
![]() (3)
(3)
As another approach, the PACF, ![]() is a function of time differencek and can be obtained by considering the regression model. That is, if the dependent variable
is a function of time differencek and can be obtained by considering the regression model. That is, if the dependent variable ![]() is regression-analyzed against k random variables,
is regression-analyzed against k random variables, ![]() , n a normal process with a mean of 0,
, n a normal process with a mean of 0, ![]() , and
, and ![]() is the PACF. If
is the PACF. If ![]() is given for the stationary time series
is given for the stationary time series![]() ,
, ![]() becomes the value of the PACF in the solution of the equation with the time difference k.
becomes the value of the PACF in the solution of the equation with the time difference k.
The SACF (sample autocorrelation function) can be used by substituting ![]() instead of
instead of ![]() to estimate
to estimate![]() . The estimated SACF is applied by a reduced model using an algorithm instead of a complex determinant as in (4).
. The estimated SACF is applied by a reduced model using an algorithm instead of a complex determinant as in (4).
![]() (4)
(4)
where ![]()
2.2. ARIMA Model
The ARIMA model is a generalization of the ARMA (autoregressive moving average) and predicts a given time series based on its own past values. It can be used for any non-seasonal series of numbers that exhibits patterns and is not a series of random events. The ARIMA model is suitable for short-term demand forecasting since it gives more weight to observations close to the most recent time. The ARMA model is a combined model that has both the parameters of the AR (autoregressive) model and the MA (moving average) model.
The basic model applied to time series analysis is the AR model, and the AR(1) model with 1 autoregressive parameter is defined as ![]() where
where ![]() is a random variable in the stationary time series,
is a random variable in the stationary time series, ![]() is autoregressive parameter of an order 1, and
is autoregressive parameter of an order 1, and ![]() is the probability error in time series data at timet. The AR(2) model has 2 parameters of order 1 and order 2 such as
is the probability error in time series data at timet. The AR(2) model has 2 parameters of order 1 and order 2 such as ![]() and
and![]() , expressed as
, expressed as ![]() by generalizing this concept, an AR(p) model with p parameters can be expressed as (5).
by generalizing this concept, an AR(p) model with p parameters can be expressed as (5).
![]() (5)
(5)
The second type of Box-Jenkins model is the MA (moving average) model. The basic MA(1) model with 1 parameter is expressed as![]() . Here,
. Here, ![]() is the fitted value fitted to the series value
is the fitted value fitted to the series value![]() , and
, and ![]() is called the MA parameter of an order 1. The MA model is almost identical to the AR model in appearance, but the meaning is completely different. In other words, the MA parameter is related only to the probability errors,
is called the MA parameter of an order 1. The MA model is almost identical to the AR model in appearance, but the meaning is completely different. In other words, the MA parameter is related only to the probability errors, ![]() , that the series values occurred before time t. The MA model is also generalized like the AR model, and the general MA(p) model with p parameters is expressed as
, that the series values occurred before time t. The MA model is also generalized like the AR model, and the general MA(p) model with p parameters is expressed as![]() . The time series value
. The time series value ![]() in the general MA model is expressed as the sum of the p probability errors at the previous p time period and the probability errors at the current time. Therefore, the p-order MA(p) model can be represented as (6).
in the general MA model is expressed as the sum of the p probability errors at the previous p time period and the probability errors at the current time. Therefore, the p-order MA(p) model can be represented as (6).
![]() (6)
(6)
Since it is represented as a model of order q with only one MA parameter of order q, it has fewer than q MA parameters and order terms lower than q are excluded. The MA model is derived simply as a weighted average of the probability errors of the previous shifted time as time t increases.
The ARMA (p, q) (autoregressive moving average) model has both p AR parameters and q MA parameters, and its equation is expressed as (7).
![]() (7)
(7)
When a stationary time series is given, the criteria for determining whether the time series data to be analyzed are suitable for an AR model or a MA model depends on the value of the ACF and the value of the PACF mentioned in section 2.1. The relationships between ACF and PACF of each AR process, MA process, and ARMA process as follows; the ACF value is exponentially decreases as the time difference k increases in the AR (p) process. And the ACF value remains 0 at time difference q + 1 in the MA (q) process. On the other hand, The PACF value is exponentially decreases as the time difference k increases in the MA (q) process. And the PACF value remains 0 at time difference p + 1 in the AR (p) process. Therefore, in the ARMA (p, q) process, both the ACF value and the PACF value decrease as the time difference k increases. Since the Box-Jenkins identification method does not identify the orders of the ARMA model, it is possible by applying a statistical estimation method.
The ARIMA (p, d, q) model is a model in which the concept of differencing is inserted into the ARMA (p, q) model, where differencing refers to calculating the difference between consecutively measured observations. The nth differencing order calculates the difference between every nth observation. Determination of the differencing order, d helps to make non-stationary time series into a stationary time series. When the order of auto-regression is p, the order of the moving average is q, and the differencing order is d, the ARIMA (p, d, q) model can be expressed as (8).
![]() (8)
(8)
where ![]() and
and ![]()
In (8), B is a backshift operator and is defined as![]() . In the ARIMA (p, d, q) model, if p = 0, d = 1, q = 0, it is called a random walk, and it becomes
. In the ARIMA (p, d, q) model, if p = 0, d = 1, q = 0, it is called a random walk, and it becomes ![]() or
or![]() .
.
In the analysis of time series data having seasonality, if only the term corresponding to seasonality is required for the model, a model is constructed using a partial model. When AR operator or MA operator is expressed in the form of product of non-seasonal operator and seasonal operator, multiplicative model (ARIMA (p, d, q) × (P, D, Q) 12) is used. If the order of the time series model is (p, d, q), the seasonal period is s, and the order of the seasonal time series model is (P, D, Q), the multiplicative seasonal ARIMA model is expressed as (9).
![]() (9)
(9)
In (9), ![]() and
and ![]() represent seasonal auto-regression and seasonal moving average polynomials respectively. Accordingly, autoregressive and moving average polynomials are expressed as
represent seasonal auto-regression and seasonal moving average polynomials respectively. Accordingly, autoregressive and moving average polynomials are expressed as ![]() and
and![]() .
.
3. Demand Forecasting Using ARIMA Model
The PO system has been mainly applied as a marketing strategy for price discounts as customer service and sales increase by manufacturers. It cannot be viewed as a time series data because the demand increases abnormally since the PO system is a strategy to create customer orders at a specific point in time.
In this study, the demand is forecasted by applying the actual service parts orders for 6 years of Daedong Engineering in Daegu as a time series data. Thousands of service parts are forecasted per month, and demand forecasting is simply based on experience in consideration of past demand data, seasonal characteristics, and PO implementation. By grouping tens of thousands of parts, five representative parts are selected and applied to demand forecasting analysis. The monthly data of service parts for 70 months from January 2013 to October 2018 are used for the demand forecasting. The order quantity of filter parts including PO is shown in Figure 1.
In addition to the Filter part shown as an example, the rest of the parts also show similar demand trends. In Figure 1, it can be inferred that outliers and slope changes may exist in time series data. The first step in model identification to find an appropriate model is to determine the differencing order of ARIMA (p, d, q). Characteristics of time series data can be identified through ACF estimation and PACF estimation and PACF is used to determine the differencing order of the AR model, and ACF is used to determine the differencing order of the MA model.
The autocorrelation function and the partial autocorrelation function of time series data for the Filter part are shown in Figure 2. In order to determine the
presence of seasonality, a sharp slope change such as the cut shape of the ACF cannot be found at the periodic time difference is 12, and there is no appearance where the signs are all positive and the peaks are repeated. From these observations, it can be said that there is no seasonal effect in Filter part. As shown in Figure 2, the estimation of the correlation function is set at the 5% significant level, it can be seen that the time difference is 3 at the point outside the confidence limit line indicated by the dotted line. Therefore, the first attempts to identify the model are AR (3) and MA (3). The general formula of the AR (3) model is![]() .
.
Table 1 shows the estimation results of parameters on AR (3). It satisfies the stationary condition since the absolute values of the estimated autocorrelation coefficients are![]() ,
, ![]() , and
, and![]() . The auto-regression coefficient,
. The auto-regression coefficient, ![]() should be included in this model.
should be included in this model.
After identifying the model, the residual ACF and the residual PACF are used to diagnose the model. Model selection criteria include![]() , residual autocorrelation function test statistic, Ljung-Box test statistic, and residual chart. The residual autocorrelation function is calculated based on the residuals obtained by estimating the AR (1) model. In this case,
, residual autocorrelation function test statistic, Ljung-Box test statistic, and residual chart. The residual autocorrelation function is calculated based on the residuals obtained by estimating the AR (1) model. In this case, ![]() is an estimate of the
is an estimate of the![]() , unobservable white noise. These white noises are assumed to be statistically independent.
, unobservable white noise. These white noises are assumed to be statistically independent.
As seen in Figure 3, none of the values of the residual ACF protrudes outside the confidence limit with a 5% significant level. The absence of a residual PACF value protruding outside the confidence interval indicates that the addition of an autoregressive factor is no longer necessary.
4. Demand Forecasting with PO Effect
The research for demand forecasting is to find a way to reduce the difference between the actual value and the forecast value, and forecasting accuracy depends on how the forecasting effect is set and reflected in the model. Since the PO system is a policy in which a manufacturer strategically creates a customer’s order quantity at a specific point in time, the application of the existing normal
![]()
Table 1. AR (3) parameter estimation.
![]()
Figure 3. Residual ACF and Residual PACF.
demand forecasting method raises questions about the accuracy of demand forecasting. In this study, the demand forecasting method that reflects the PO effect is proposed by modifying the time series analysis method under the PO system. In other words, if PO occurs at![]() , the PO effect is calculated at each time and reflected in the forecasting amount calculation. By doing so, it is expected that the accuracy of demand forecasting will be improved by the PO effect.
, the PO effect is calculated at each time and reflected in the forecasting amount calculation. By doing so, it is expected that the accuracy of demand forecasting will be improved by the PO effect.
In this study, although the outlier limit is usually defined as the inter-quartile range, the average monthly order quantity ![]() and the standard deviation
and the standard deviation ![]() for a certain period(window) of n months are obtained to set the outlier limit using the time series data
for a certain period(window) of n months are obtained to set the outlier limit using the time series data![]() . For simplicity, the values outside of
. For simplicity, the values outside of ![]() are considered as outliers. The average
are considered as outliers. The average ![]() of the remaining data in the period is calculated after removing the data identified as outliers. And as shown in (10), the value obtained by dividing the difference between the actual value
of the remaining data in the period is calculated after removing the data identified as outliers. And as shown in (10), the value obtained by dividing the difference between the actual value ![]() and the average monthly order quantity by
and the average monthly order quantity by ![]() is defined as the PO effect.
is defined as the PO effect.
![]() (10)
(10)
As shown in (10), the PO effect can take various modifications, such as a conservative approach and a sensitive approach, considering the characteristics of time series data. In other words, various alternatives can be suggested by adjusting the outlier limit or by changing the time period n. The adjusted demand forecast ![]() reflecting the PO effect is shown as (11), where
reflecting the PO effect is shown as (11), where ![]() represents the demand forecast at time t.
represents the demand forecast at time t.
![]() (11)
(11)
For the example given in Section 3, the process of finding outliers is carried out by setting the PO period n to be 12-month (1 yr.) and 60-month (5 yrs.). In Figure 4, the time series data for two cases of 1 year (upper) and 5 years (lower) is shown, the outliers are the values outside of ![]() and are indicated by circles.
and are indicated by circles.
In order to apply the PO effect proposed in (10) and (11) to time series data, the 12-month average and the correction value replacing the PO effect are applied after removing the order quantity at the time of PO. The time series data to which the PO effect is applied is shown in Figure 5.
As seen in Figure 5, the monthly time series order quantity has a different scale and trend compared to Figure 1, which shows the time series data before the revision. In the next step, ACF and PACF for model identification are examined. (2) and (3) were used to calculate ACF and PACF for each time difference, and Figure 6 shows ACF and PACF in relation to the time difference.
As seen in Figure 6, ACF and PACF for each time difference are indicated by a bar chart, and the confidence limit applied with a 5% significant level is indicated by a dotted line. It can be said that there is no seasonal effect since ACF is not beyond the confidence limit at time difference 12. Therefore, the forecasting order quantity is obtained using AR (1) and MA (1) according to the principle of parsimony. And the modified forecasting amount is obtained by applying the PO effect.
In this study, from the perspective of a conservative approach, the PO effect reflecting the average of 60-month is performed with the same procedures as the one presented before. After removing the order quantity at the time of PO, the 60-month average and the correction value substituted for the PO effect are applied. The time series data to which the PO effect is applied is shown in Figure 7.
Comparing Figure 5 and Figure 7, even if the period for reflecting the PO effect in the demand is different, the overall ordering quantity trend is similar, but a slight difference can be found.
ACF and PACF were examined for the purpose of model identification. As shown in Figure 8, since the time difference 12 does not deviate from the confidence limit, it can be said that there is no trend and seasonal effect as in the
![]()
Figure 5. Ordering quantity with 12-month PO period.
![]()
Figure 7. Ordering quantity with 60-month PO period.
![]()
Figure 8. ACF and PACF with 60-month PO period.
original time series data. The result is the same as the result in Figure 6. However, a closer look reveals a difference between the two figures. There is a difference in the PACF value at each time difference, which can be said to have different influences in determining the order of the AR model.
5. Comparisons and Validations
After comparative analysis of various suggested models, model selection criteria include![]() , residual autocorrelation function test statistic, and residual chart. After selecting the model, the accuracy of forecasting is performed based on the error between the estimated value and the actual value. Among the various scales for accuracy comparison, in this study, well known RMSE (root mean square error) and MAPE (mean absolute percentage error) are applied. RMSE is a frequently used measure of the differences between an estimator and the values observed.
, residual autocorrelation function test statistic, and residual chart. After selecting the model, the accuracy of forecasting is performed based on the error between the estimated value and the actual value. Among the various scales for accuracy comparison, in this study, well known RMSE (root mean square error) and MAPE (mean absolute percentage error) are applied. RMSE is a frequently used measure of the differences between an estimator and the values observed.
Letting k be the time difference, ![]() be the order quantity, and
be the order quantity, and ![]() be the demand forecast quantity, RMSE is expressed as
be the demand forecast quantity, RMSE is expressed as![]() , and MAPE as
, and MAPE as![]() .
.
In this study, the accuracy of demand forecasting is reviewed for disk, gasket, cable and other general items in addition to the filter. As shown in Table 2, the forecasts obtained with PO show better results than those without PO by examining RMSE and MAPE, which are indicators of the accuracy of the forecasts. In addition, although the policy is normally implemented as a PO period of 12-month, a policy with 60-month PO period was proposed and compared with the results of 12-month PO period. In comparisons of the forecasting accuracy results by 12-month PO period and the results of 60-month PO period, the superiority of the policy could not be decided. This is because the characteristic of ARIMA is that the more the data goes into the past, the less influence to the forecast. The fact that the results of the 12-month PO period are somewhat superior can be a result of reflecting this. As forecasting accuracy indicators, there are MAE, MSE, and MPE and etc. in addition to RMSE and MAPE, but they were not investigated in this study. However, it is expected that the analysis results for other forecasting accuracy indicators would be similar.
![]()
Table 2. RMSE and MAPE (%) comparison.
6. Conclusion
Customer service, inventory costs, and company credit are interrelated and demand forecasting is at the center of them. The purpose of this study is to propose a method to improve the accuracy of demand forecasting in the presence of a PO system. The demand can be forecasted by applying ARIMA, but a relatively large error occurs in the forecast amount when PO occurs. Therefore, these shortcomings make it inconvenient to apply ARIMA directly to time series data with planned uncertainty.
In this study, the demand forecasting method reflecting the PO effect was proposed as one of the methods to improve the forecasting accuracy under the PO system. The time at which the outlier occurred was regarded as the time at which the PO occurred, and the criterion for the outlier was set as![]() . It is believed that the PO effect can be further enhanced by lowering the threshold for outliers, and the accuracy of the forecasting can also be improved. On the other hand, the PO effect can vary with the PO period. Although 12 months is mainly applied as a PO period, a 60-month PO period is also considered with a conservative approach in this paper. The comparison of the results by these two PO periods cannot be definitive because it depends on the characteristics of the data, but the short-term PO effect seems better. This is because the characteristics of ARIMA have less effect on forecasting as the data goes into the past. The extension of this study can be possible in two directions: lowering the criteria for outliers and adjusting the PO period.
. It is believed that the PO effect can be further enhanced by lowering the threshold for outliers, and the accuracy of the forecasting can also be improved. On the other hand, the PO effect can vary with the PO period. Although 12 months is mainly applied as a PO period, a 60-month PO period is also considered with a conservative approach in this paper. The comparison of the results by these two PO periods cannot be definitive because it depends on the characteristics of the data, but the short-term PO effect seems better. This is because the characteristics of ARIMA have less effect on forecasting as the data goes into the past. The extension of this study can be possible in two directions: lowering the criteria for outliers and adjusting the PO period.
NOTES
*The present research has been conducted by the Sabbatical Research of Keimyung University in 2016.