An Advanced Approach of Local Counter Synchronization to Timestamp Ordering Algorithm in Distributed Concurrency Control ()

Subject Areas: Distributed Computing, Information and Communication Theory and Algorithms
1. Introduction
Concurrency control ensures the consistence and reliability attribute of transaction. Before discussing the main topic, we should glance over some importance definitions. Note that the research is a proposed approach for improving a well-known algorithm. So, definitions and methods are mentioned in short; please see [1] for more details about distributed concurrency control. The schedule S is the set of transactions: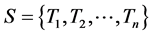 ; each transaction Ti has data operations Oij (read or write). Two operations accessing the same data item x are in conflict if one of them is a write.
; each transaction Ti has data operations Oij (read or write). Two operations accessing the same data item x are in conflict if one of them is a write.
A complete schedule 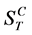 is defined as a partial order
is defined as a partial order 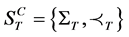 where [1] :
where [1] :
1) The set 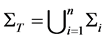 with note that
with note that 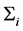 is the set of data operations Oij in transaction Ti.
is the set of data operations Oij in transaction Ti.
2) The relationship 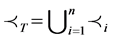 with note that
with note that 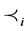 denotes the partial order relationship between two arbitrary operations Oij(x) and Okl(x) in transaction Ti.
denotes the partial order relationship between two arbitrary operations Oij(x) and Okl(x) in transaction Ti.
3) Two arbitrary operations Oij(x) và Okl(x) in 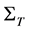 are conflicting if either
are conflicting if either 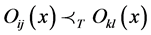 or
or 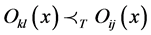 .
.
All concurrency control algorithms are based on serializability theory [1] . First, serial scheduler is the scheduler in which transactions are executed step-by-step, meaning that all operations of a transaction must be completed before starting a new transaction. Schedules S1 and S2 defined over the same set of transactions are conflict-equivalent [1] if for any pair of conflicting operations Oij(x) and Okl(x), 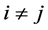 , whenever
, whenever , and then
, and then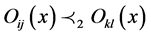 .
.
A schedule is serializable if it is conflict-equivalent to a serial schedule and the serial execution is called serialization order [1] . All concurrency control algorithms focus on generating the serializable schedule to archive two goals:
・ The order of executing transactions is a serialization order which ensures the sound result of transactions execution.
・ Taking advantage of parallel processing.
There are two basic methods of concurrency control such as locking-based and timestamp-based. Both of them have strong and weak points but timestamp-based method is the key in this paper because this method does not meet deadlock problem and it is more effective than locking-based method in some situations. Now some main aspects about concurrency control methods are already introduced but it is very difficult to “move” such methods from non-distributed database to distributed database. Of course, locking-based method is modified to be conformable to distributed environment but I propose some advancement for timestamp-based method in distributed environment. Timestamp-based algorithm is discussed in Section 2 and its improvement is proposed in Section 3. Section 4 is the conclusion.
2. Timestamp Ordering Algorithm
Unlike locking-based approach which maintains serializability by mutual exclusion, timestamp-based concurrency control algorithm tries to uphold serializability by [1] :
・ Assigning a unique timestamp to each transaction.
・ Ordering transactions upon their timestamps. Consequently, there is a serializable order of transactions.
・ Performing transactions according to this order.
Timestamp is an identifier of every transaction and used to permit ordering. Timestamp has two essential attributes: uniqueness and monotonicity. Monotonicity refers that timestamps generated by the same transaction manager (TM) are monotonically increased in values. This attribute permits to distinguish timestamp and transaction identifier.
There are two ways to generate timestamp:
・ Using a monotonically increasing global counter, but it is very difficult to maintain global counter in distributed environment.
・ Every site is free to assign timestamps by itself, upon the local counter. To keep the uniqueness, each site attaches its identifier to the local counter. Therefore, timestamp is in the two-part forms
or
[1] . Site identifier is put in the least significant position to avoid the situation that one timestamp from a site will be always larger or smaller than from another site.
When transactions have already been assigned timestamp, ordering the operations (read, write) of transactions must obey the timestamp ordering (TO) rule “Given two conflicting operations Oij(x) and Okl(x) belonging to transactions Ti and Tk respectively, Oij(x) is executed before Okl(x) if timestamp of Ti is smaller than timestamp of Tk” [1] . It means that the older transaction is executed first.
In general, TO algorithm through two main steps is described briefly below [1] :
1) The TM receives transactions coming from application and assigns timestamp values to them. After that, TM deliver operations (read, write) Oij of these transactions to the scheduler (SC).
2) SC schedules data operations by TO rules. It checks each new operation against conflicting operations that have been scheduled. If the new operation belongs to a younger (later) transaction than all conflicting ones, then accept it; otherwise reject it and restart the entire transaction with a new timestamp.
It can be asserted that TO algorithm maintains the execution order according to the timestamps order.
3. An Advanced Approach of Local Counter Synchronization
Suppose that timestamp is generated upon local counter at each site, there is a problem of local counter synchronization. Note that SC will restart transaction if there is another younger transaction scheduled. Such situation occurs many times if there are sites which are not active or not receives any transaction in regular period. In this case, the local counters of such sites are so smaller than other sites and most transactions coming to these sites will be restarted many times until their counters are approximate to local counters of other sites. Hereafter, Figure 1 [1] depicts an example about how to maintain timestamps among sites.
Transaction T at site 2 try to read the data item x which exists at site 1 and has read and write timestamps: rts(x) and wts(x). If timestamp of T denoted ts(T) is smaller than wts(x), the read is rejected and T is restarted and gets a new larger timestamp from counter at site 2. When counter at site 2 is too small, T has no chance to be executed.
It is necessary to synchronize local counter at all sites. Whenever TM at one site increases its own counter due to accepting transaction, it broadcasts a message about updating counter over all TM (s) at other sites. After that, other TM (s) will compare their local counters to coming counter and adjust themselves their counter one more than coming counter (= coming counter + 1). This is the mechanism of broadcasting information about updating local counters. It ensures that there is no local counter which runs too fast or too slowly. Two improvements of counter synchronization are proposed as follows:
・ Improving the way of broadcasting message of updating local counters.
・ Reducing expense of data transmission in broadcasting message of updating local counter
3.1. Improving the Way of Broadcasting Message of Updating Local Counters
To broadcast message of updating local counter on distributed network is the most considered problem in counter synchronization. Given transaction manager TMi at site i increases its own counter when receiving a new transaction. So TMi has the new counter counter (TMi) = 200 and it sends three messages namely m1, m2 and m3 to TM1, TM2 and TM3, respectively.
・ TM1 has old local counter counter (TM1) = 1.
・ TM2 has old local counter counter (TM2) = 150.
・ TM3 has old local counter counter (TM3) = 170.
Because counter (TMi) is so larger than counter (TM1), counter (TM1) get the new value 201 = counter (TMi) + 1. In usual way, both remaining counter (TM2), counter (TM3) are also re-assigned new value 201. At that time, counter (TMi) is considered as the “milestone”. Yet, in situation that TM2 and TM3 are active with note that the term “active” implicates that TM received more transactions. If we choose counter (Ti) as the “milestone” to increase counters of TM2 and TM3 then the frequency of rejecting transactions at other sites become high because TM2 and TM3 receive more and more transactions and their locks increase faster and faster. In consequences, the
![]()
Figure 1. Maintain timestamps among sites [1] .
timestamps of new transactions at site 2, 3 get so high values and so rts(xk) and wts(xk) of data item xk at site 2, 3 raises suddenly. Transactions (with low timestamps at other sites) accessing xk will be rejected more constantly. Of course the performance of distributed database management system is decreased significantly. However, it is nearly impossible to ignore the role “milestone” of counter (TMi) because this will lead to miss results in other situations in which TM2 and TM3 are not active. What is the solution in this situation?
I propose that the timestamp is represented in three-part form
. The positions of parts are corresponding to their importance, e.g. local-counter in the second position is more significant than active-number in the third position. Thus, each TM
i at site i has the new active-number which is responsible for measuring the degree of activeness at site i. The more transactions site i is received, the higher the active-number is and so the active-number of given site can be updated by frequency of transactions coming to such site. Suppose sites namely TM
1, TM
2 and TM
3 update their own local counters in situation that TM
i has the new counter (TM
i) and sends three messagesm
1, m
2, m
3 to TM
1, TM
2, TM
3 respectively, my proposal has two following steps given two integer parameters α > 0 and β > 0:
1)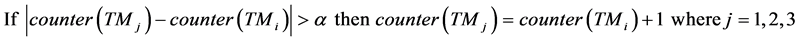 .
.
2)  then active-number (TMj) is considered. If active-number (TMj) < β then counter (TMj) = counter (TMi) + 1. Otherwise, counter (TMj) is kept in original (not changed).
then active-number (TMj) is considered. If active-number (TMj) < β then counter (TMj) = counter (TMi) + 1. Otherwise, counter (TMj) is kept in original (not changed).
For example, we have counter (TMi) = 200, counter (TM1) = 1, counter (TM2) = 150, counter (TM3) = 170, active-number (TM1) = 10, active-number (TM2) = 60, active-number (TM3) = 100, α = 50 and β = 80. Applying above algorithm, we have:
・ The counter (TM1) = counter (TMi) + 1 = 201 because .
.
・ The counter (TM2) = counter (TMi) + 1 = 201 because active-number (TM2) = 60 < β.
・ The counter (TM3) = 170 (not changed) because ![]() and active-number (TM3) = 100 > β.
and active-number (TM3) = 100 > β.
Finally, the increasing rate of local counter at a site will be reduced if that site is active. In other words, that lock at active site is increased is delayed. It is easy to infer that the purpose of using active number is to harmonize an increase in local counters. In the case that the active-number of given site is lost, it is reset to be zero. Note that the triplet for timestamp
is identified by only local-counter and site-identifier. Active-number is an auxiliary part. When transaction restarts, active-number is also reset to be zero.
3.2. Reducing Expense of Data Transmission in Broadcasting Message
Suppose all sites in distributed database compose the network including nodes which are respective to TM (s). Whenever one node adjusts its own counter, it issues the message all over the network. So this consumes much system resource. How to reduce the expense of message transmission but ensure that the message has to coming to every node?
We consider TM network as the graph in which every node is a TM and every edge is attached to the weight which represents the expense of the transmission from source TM node to destination TM node. It is not difficult to find the most minimum spanning tree [2] of such graph by applying some algorithms such as PRIM and Krussal [2] . Finally, message is broadcasted over this tree. So, all TM nodes are received message with lowest transmission expense. Figure 2 depicts TM graph and minimum spanning tree drawn as bold line.
4. Conclusions
Local counter synchronization is the essence of timestamp-based method in concurrency control. In this paper, two improvements on this synchronization are proposed as follows:
・ The timestamp is represented in three-part form
. Whether local counters are updated depends on active numbers and two other parameters α and β. The ideology is to delay the increase of local counters in sites until the condition composed of active numbers, α and β, is met fully so that the increasing rate of local counter at a site will be reduced if that site is active.
・ Reducing expense of message transmission by considering TM network as the graph and broadcasting the message over the minimum spanning tree of such graph.
Of course, my technique doesn’t provide the thorough solution to the drawback of low performance when
![]()
Figure 2. TM graph and minimum spanning tree (bold line).
broadcasting message over network. It only improves timestamp-based method. In general, this article is a work- in-progress research for improving well-known timestamp ordering algorithm. If compared with existing approaches, it requires a lot of evaluations which go beyond a proposal.