Open Journal of Statistics
Vol.10 No.01(2020), Article ID:97987,10 pages
10.4236/ojs.2020.101005
Binary Logistic Models of Home Ownership in Wukari Nigeria
Joseph Uchenna Okeke1*, Evelyn Nkiruka Okeke2, Yeshak Victor Dakhin2
1Department of Mathematical Sciences, Taraba State University, Jalingo, Nigeria
2Department of Mathematics & Statistics, Federal University, Wukari, Nigeria

Copyright © 2020 by author(s) and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: October 23, 2019; Accepted: January 16, 2020; Published: January 19, 2020
ABSTRACT
The study is on the Binary logistic models of home ownership among civil servants in Wukari, Nigeria. The data used is of primary source using questionnaires. The multicollinear data, as well as the reduced data using the Principal component analysis and the stepwise regression methods to determine the factors that chiefly account for home ownership, were x-rayed. Four components were selected out of six namely grade level of respondent, cadre of institution of service of respondent, family size of respondent and age of respondent. The four components selected accounted for 87.78 percent of the variation and four variables were selected from them. The logit model for home ownership status is obtained from the selected variables. Test for the adequacy of the model was carried out using the count R2 which indicates how useful the explanatory variables are in predicting the response variables and can be referred to as measures of effect size. In testing the significance of each of the factors only Age of respondent is significant in determining variability in the home Ownership Model.
Keywords:
Binary, Logistic Model, Multicollinear Data, Principal Component Analysis, Stepwise Regression, Logit Model, Home Ownership

1. Introduction
Logistic model is a probability model generated from a process that is characterized by qualitative response variable which could be binary (dichotomous), ordinal or nominal Gujarati [1].
The binary response variable can also be modeled using the linear probability approach such that given
(1)
Then
(2)
So that is the probability of possessing the desired attribute and with the restriction that: the error term is non normally distributed but can be assumed to be normally distributed in large samples, though not a necessity if interest is in point estimation; and but which is heteroscedastic from a Bernoulli process and; is not usually sustained such that the coefficient of determination, , is generally low making it a useless tool for goodness of fit test.
Weighted least squares had been advanced as a remedy to solving the problem of heteroscedasticity of the model where the weight is calculated as:
(3)
which is applied as
(4)
thereby creating a problem for interpolation and extrapolation since may be unknown for a new outcome.
Given that Y is the realization from N individual outcome that is independently distributed with and , for , which is a Bernoulli distribution with the probability mass function
(5)
(6)
where is the odds ratio which indicates the odds in favour of the response variable possessing the required attribute ( ), and the natural parameter
(7)
is called the logit link as in Gujarati [1], Festschrift et al. [2] and Menart [3] so that
(8)
(8) is the logit model.
and α’s have a linear relationship with in (8) such that for data on individual levels:
if ,, which is undefined; if ,, which is also undefined. As a remedy, we introduce a correction logit defined by as in Rao and Toutenburg [4] and/or consider the group data, so that for Y = 1 in out of population in group j. so that . If is slightly large and is distributed as a binomial variable, we have that
and in the account of Cox [5]. Also, software programs such as Stata, Eviews, Minitab etc. have been developed to obtain the logit model for data on individual levels after a certain number of iterations.
If it is now given that is a function of so that
and (9)
and
(10)
Such that
(11)
Then , which has while can take values between −∞ and +∞. Hence, the model
can be valid at specific values of x within a given range and is a function of x and hence heteroscedastic, thereby making the ordinary least squares (OLS) estimate not to be optimal as remarked by Gujarati [1]. Hence the maximum likelihood method of estimation (MLE) for can be applied to obtain which maximizes
(12)
(13)
The MLE can, generally, be obtained using iterative algorithms such as Newton Raphson (NR) method or iteratively re-weighted least squares (IRWLS) which have been enshrined in some software packages listed above.
The effect of x in the logit model in (8) above is monotone rather than nonlinear, hence the need for a logistic regression which ensures a monotone outline (S-curve) of the probability of so that is proffered for the logit model such that
(14)
The logit link made the logistic regression to be a generalized linear model Rodriguez [6] and Gujarati [1], so that for
(15)
we then have
(16)
and
(17)
(17) is the cumulative logistic regression which is required to determine the probability of obtaining the effect of interest such as or given the effects of some independent variables say .
So that from (17)
(18)
where is linear in X as well as linear in parameters.
It is pertinent to point out that: the logit, , may be linear in X but the probabilities are not; the logit are not bounded since goes from as goes from ; negative implies that the odds in favour of Y = 1 decreases as X increases if and only if a single X is considered and; the effects of more than one explanatory variables can be studied as outlined by Gujarati [1], Greene [7] and Gareth et al. [8].
The logistic model is also a good classification model and can serve as an alternative to the Fisher’s linear discriminant analysis, however, the logistic model does not require the multivariate normal assumptions of the discriminant analysis asserted Rodriguez [6].
In the presence of more than one explanatory variable, the effect of multicollinearity may result. Home ownership models exhibit some form of multicollinearity among the explanatory variables Gujarati [1]. The multicollinearity is perfect if the condition whereby is satisfied for being constants that are not simultaneously equal to zero but for which the coefficient of the explanatory variables could be indeterminate Cox (1970). Thus, given that
(19)
the normal equations are:
(20)
(21)
(22)
Then from (20)
(23)
Also, solving (20), (21) and (22) simultaneously, we have
(24)
(25)
where y and x are in deviation forms such that and .
In the presence of perfect multicollinearity, for , a non zero constant. Substituting for in (24), we have
(26)
However, for non-perfect but high multicollinearity such as ,,
Then
(27)
where , is finite but where , is undefined as in (26).
Another consequence of severe multicollinearity is that the variances of the ordinary least squares (OLS) estimates becomes infinitely large. From the normal equations we can obtain
(28)
(29)
(30)
here and , k = number of parameters in the model. is the variance inflation factor (VIF) and . If then .
Also, .
Application of the binary logistic model to home ownership in wukari
Wukari is a town in Wukari Local Government Area of Taraba State in Nigeria
Based on the 2006 National census figure, Wukari has a population of 234,546 and the town is divided into three wards Avyi, Puje and Hospital [9]. A lot of agricultural produce such as yam and fish can be found in Wukari town because the people of Taraba are predominantly farmers. Wukari, presently, houses: Wukari local government secretariat; Taraba state office of Land and Survey; Federal University Wukari established in 2012; National Open University and Kwararafa University (a privately/community owned university). This makes it ideal for the Wukari to be selected for the study because of the attendant expected meteoric growth in population and the corresponding anticipated growth in housing development especially on owner occupier basis due to pressure on existing structures and the exorbitant rent charged on them. Moreso, Wukari is one of the melting points in terms of ethno-religious and political conflicts in Nigeria. Conflict could constitute a risk factor in housing development and could be a determinant of location in home ownership decision.
Conflicts have adverse effect on economic growth through the destruction of human and physical capital, shifts in public spending and private investment, as well as the disruption of economic activities and social life as asserted by Okeke et al. [10]. The specific impacts depend on each conflict’s singular characteristics. It is not just the type of conflict, but also its intensity, duration and geo-graphical spread that shapes its economic consequences.
Housing is not luxury as asserted by Geoffrey [11]. Housing represents one of the most basic human needs. As a unit of the environment, it has a profound influence on the health, efficiency, social behavior, satisfaction and general welfare of the community such that to most groups, housing means shelter but to others it means more, as it serves as one of the best indicators of a person’s standard of living and his or her place in society [12]. It is a pre-requisite to the attainment of living standard and it is important to all individual be they in rural or urban areas.
According to Hood [13], the factors in home ownership decision include: race, gender, educational attainment, age, marital status and family size, some factors such as net family income and parental home ownership affect both benefits and cost.
Also, integrated households are more likely to own a house than separated or marginalized ones. Hence, the probable determinants of home ownership may include employment status, income, education, marital status, family composition, access to home financing and discrimination Lauridsen and Skak [14].
It is pertinent to point out that these expositions did not take into cognizance the influence of the risk factor, notably, conflict, in home ownership decision. However, this study will take that into perspective in explaining the result of the logistic model.
2. Methodology
Data Collection
The data used for the study is a primary data obtained from sample questionnaires administered to three hundred (300) respondents (civil servants) working in various cadres of government institutions, namely: local government, state and federal, in Wukari.
In the questionnaire, a total of twenty-three questions were asked from which the responses were extracted for the purpose of this study. The questions were simple and clear to understand to avoid ambiguity and they bothered on: monthly income of respondent ( ), grade level of respondent ( ), years in service ( ), cadre of institution of service of respondent ( ) (i.e. federal, state or local government establishments), family size ( ), age of respondent ( ), and home ownership status of respondent i ( ). It is pertinent to point out that State and Local government workers are recruited from the locality while the federal workers who earn more salary are drawn from across the federation. We also have to bear in mind that monthly income is more all-encompassing than monthly salary which is determined by the grade level.
A pilot survey was conducted to determine the content validity of the questionnaires, to enable adjustment to the questions for the research and to fine tune the content to make them clear, precise and unambiguous for the respondents to give meaningful responses in line with Okafor [15].
A total of 300 questionnaires were issued out to civil servants in federal, state and local government agencies. we were able to retrieve 250 questionnaires out of which 200 were valid and put into use. The retrieved questionnaires were used to extract the data used for the analysis.
Data Analysis
Data extracted were arranged for analysis. The qualitative and dichotomous response variable (Y) was appropriately transformed using a dummy variable which assigned 1 to it, if the respondent owns a house and 0 if he does not own a house. Some of the explanatory variables i.e. factors of home ownership were quantitative while others were qualitative and were assigned appropriate dummy variables.
The data was analyzed using the binary logistic regression model. The data was also reduced using the principal component analysis as an inAbdiput tool as in and Williams [16] and Okeke et al. [17]. In like manner the stepwise regression was applied and comparison conducted using the probability of misclassification. The Statistical package for social science (SPSS) version 21 was employed for the analysis
Adequacy of the models
The maximum likelihood estimates are asymptotically normal under general condition and the significance of the effects of
on
tantamount to the significance of
(the regression coefficient) or α’s (the partial regression coefficients) as the case may be Gujarati [1]. Therefore in testing the hypothesis 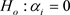 against
against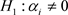 , we use the Wald test statistic:
, we use the Wald test statistic: 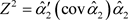 which has
which has 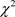 distribution.
distribution.
We use the simple count R2 to determine the adequacy of the logistic model in the presence of violation of the ols assumptions under which the ols estimates are still unbiased but inefficient.
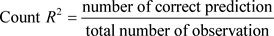
and
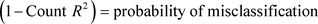 .
.
Other tests for the adequacy of the logistic (logit) model are the Mcfadden R2, Pseudo R2, Cox and Snell and Nagelkerke R etc. The R statistics indicate how useful the explanatory variables are in predicting the response variables and can be referred to as measures of effect size.
However, the count R2 is simple and a more reliable tool in showing the predictive power of the model Gujarati [1].
3. Results and Discussion
Using the principal component analysis (pca) by correlation matrix approach we selected X2 (grade level of respondent), X4 (cadre of institution of service of respondent), X5 (family size) and X6 (age of respondent) variables while the stepwise regression approach selected X1 (monthly income of respondent) and X6 (age of respondent) variables.
The result of the analysis using the multicollinear data, pca and the stepwise regression, respectively, yields the logit models (31), (32) and (33) below:
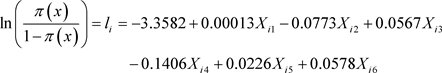 (31)
(31)
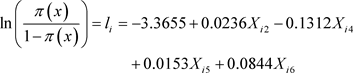 (32)
(32)
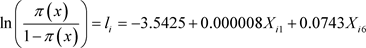 (33)
(33)
The odds in favour of owning a home in Wukari by a civil servant in the presence of the intervening variables, 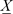 , is obtained from the respective logit models as:
, is obtained from the respective logit models as:
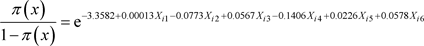 (34)
(34)
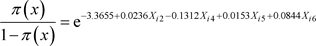 (35)
(35)
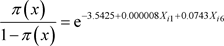 (36)
(36)
The logistic models for determining the probabilities 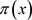 of owning a home by civil servants in Wukari are obtained from the respective logit models as:
of owning a home by civil servants in Wukari are obtained from the respective logit models as:
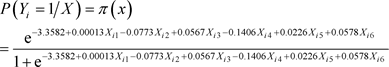 (37)
(37)
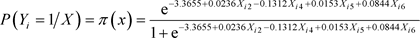 (38)
(38)
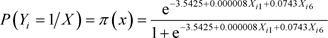 (39)
(39)
The wald test for the significance of the model coefficients showed that in (31) and (33), X1 (monthly income of respondent) and X6 (age of respondent) are significant while in (32), though X2, X4, X5 and X6 account for 87.78% variation in Y, only X6 (age of respondent) is significant as shown in Table 1.
The binary logistic model of pca is more adequate than the ones involving a multicollinear data and stepwise regression in their predictive power with a count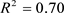 , followed by the logistic model of stepwise regression with a count
, followed by the logistic model of stepwise regression with a count  while the logistic model of a multicollinear data has a count
while the logistic model of a multicollinear data has a count .
.
An interesting feature of the three models is that income (X1) and age (X6) of respondents have a positive effect on home ownership while cadre of institution of service (X4) of respondent has a negative effect. The negative effect of cadre of institution of service (i.e. federal, state or local government establishments) could be attributed to the risk factor associated with building in conflict area for

Table 1. Standard error and p-value of Wald test of significance of model coefficents.
which Wukari is one of the most volatiles in Taraba State of Nigeria. The preferred model is the binary logistic model of pca.
Conflicts of Interest
The authors declare no conflicts of interest regarding the publication of this paper.
Cite this paper
Okeke, J.U., Okeke, E.N. and Dakhin, Y.V. (2020) Binary Logistic Models of Home Ownership in Wukari Nigeria. Open Journal of Statistics, 10, 64-73. https://doi.org/10.4236/ojs.2020.101005
References
- 1. Gujarati, D.N. (2003) Basic Econometrics. 4th Edition, McGraw-Hill Co Inc., New York, 595-607.
- 2. Festschrift, J.N., Hosmer, D. and Lemeshow, S. (2000) Applied Logistic Regression. 2nd Edition, John Wiley & Sons, Inc., New York.
- 3. Menart, S.W. (2002) Applied Logistic Regression. 2nd Edition, SAGE, New York.
- 4. Rao, C.R. and Toutenburg, H. (1995) Linear Models: Least Squares and Alternatives. 2nd Edition, Springer-Verlage Inc., New York.
- 5. Cox, D.R. (1970) Analysis of Binary Data. Methuen, London, 33.
- 6. Rodrigues, G. (2007) Lecture Notes on Generalized Linear Models. 45.
- 7. Greene, W.N. (2003) Econometric Analysis. 5th Edition, Prentice Hall, New York.
- 8. Gareth, J., Daniel, W., Trevor, H. and Robert, T. (2013) An Introduction to Statistical Learning. Springer, New York, 6.
- 9. Ishaku, T.H., et al. (2010) Planning for Sustainable Water Supply through Partnershi Approach in Wukari Town, Taraba State of Nigeria. Journal of Water Resource and Protection, 2, 916-922. https://doi.org/10.4236/jwarp.2010.210109
- 10. Okeke, J.U., Okeke, E.N., Onoja, P.N. and Yawe, A. (2018) Peace and Conflict Resolution: A Contingency Table Analysis of Jos-Plateau Crisis. Global Journal of Engineering Science and Research Management, 5, 43-49.
- 11. Geoffrey, N. (2005) The Urban Informal Sector in Nigeria. Towards Economic Development, Environmental Health and Social Harmony. Global Urban Development Magazine, 1, 1.
- 12. Nubi, O.T. (2008) Affordable Housing Delivery in Nigeria. The South African Foundation International Conference and Exhibition, Cape Town.
- 13. Hood, J.K. (2014) The Determinant of Home Ownership: An Application of Human Capital Investment Theory to the Home Ownership Decision. The Park Place Economics, 3, 40-50.
- 14. Lauridsen, J. and Skak, M. (2007) Determinant of Home Ownership in Denmark. Institute of Business Economics, University of Southern Denmark, Odense.
- 15. Okafor, F.C. (2002) Sample Survey Theory and Application. Afro-Orbis Publications Ltd., Nigeria.
- 16. Abdi, H. and Williams, L.J. (2010) Principal Component Analysis. Wiley Interdisciplinary Reviews: Computational Statistics, 2, 433-459. https://doi.org/10.1002/wics.101
- 17. Okeke, E.N. and Okeke, J.U. (2015) Clustering Using Principal Component Analysis as an Input Tool. Journal of Multidisciplinary Engineering Science and Technology, 2, 2694-2699.